Optimizing sort queries in Elasticsearch for faster results


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
It is very common in Elasticsearch to request results to be sorted by a certain field. We have invested a great deal of time and effort to optimize sort queries to make them faster for our users. This blog will describe some of the sort optimizations for numeric and date fields.
How sorted queries work
When you want to find documents matching a filter and request results to be sorted by a certain field, Elasticsearch would examine this field’s doc values for all documents matched by the filter and choose the top K documents with the top values. In the worst case of a very broad filter (e.g. match_all query), we have to examine and compare doc values for all documents in an index. For big indices, this may take a substantial amount of time.
One way to optimize sort queries on a particular field is to use index sorting and sort the whole index in this field. If the index is sorted by a field, its doc values are also sorted. So to get top K documents sorted by a field, we simply need to take the first K documents, and don’t even need to examine the rest, which makes sorted queries super fast.
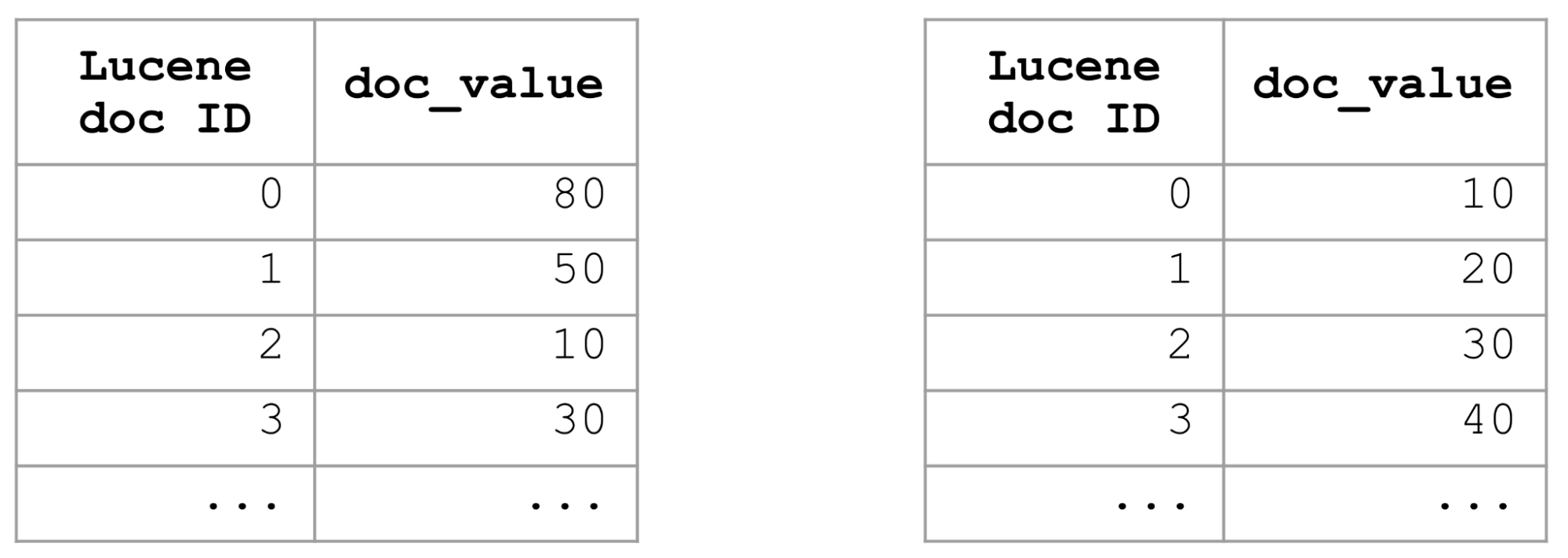
Index sorting is a great solution, but you can do index sorting only in a single way. Index sorting is not useful for sort queries that use different sort criteria, such as descending vs. ascending, different fields, or different combinations from the ones defined in an index sorting definition. So other more flexible approaches to speed up sort queries were needed.
Optimizing numeric sort queries with distance_feature query
In the past, we made significant speedups in term-based queries sorted by _score by storing for each block of documents its maximum impact – a combination of term frequency and document length. During query time we can quickly judge if a block of documents is competitive by looking at its maximum impact. If a block is not competitive, we can skip this whole block of documents, which makes queries significantly faster.
We thought we could apply a similar approach to speed up sort queries on numeric or date fields. It turned out to be possible by substituting sort with a distance_feature query. distance_feature query is an interesting query that returns top K documents closest to a given origin. If we use the minimum value for the field as the origin, we get top K documents sorted by the ascending order. Using the maximum value as the origin will yield us top K documents in the descending order.
The most interesting property of the distance_feature query for us was that it can efficiently skip non-competitive blocks of documents. It does this by relying on the properties of BKD trees which are used in Elasticsearch for indexing numeric and date fields. Similar to how a postings index for a text field is divided into blocks of documents, a BKD index is divided into cells with each cell knowing its min and max values. Thus, a distance_feature query just by examining cells’ min and max values can efficiently skip non-competitive cells of documents. For this sort optimization to work, a numeric or date field needs to be both indexed and have doc values.
By substituting sorting on doc values with a distance_feature query we could achieve great speedups (on some datasets up to 35x gains). We introduced this sort optimization on date and long fields in Elasticsearch 7.6.
Optimizing sort queries with search_after
We were happy to see these speedups, but we still did not have a good solution for sorting with a search_after parameter. Sorting with search_after is very common, as users are often interested not only in the first page of results, but also in subsequent pages. We have decided that instead of our current approach of rewriting sort queries in Elasticsearch, a better solution would be to make comparators and collectors within Lucene do this sort optimization and skip non-competitive documents. As comparators and collectors in Lucene already deal with search_after, this would allow us to have a solution for this problem as well. The same Elasticsearch code that distance_feature query was using to skip blocks of non-competitive documents was added to Lucene’s numeric comparators.
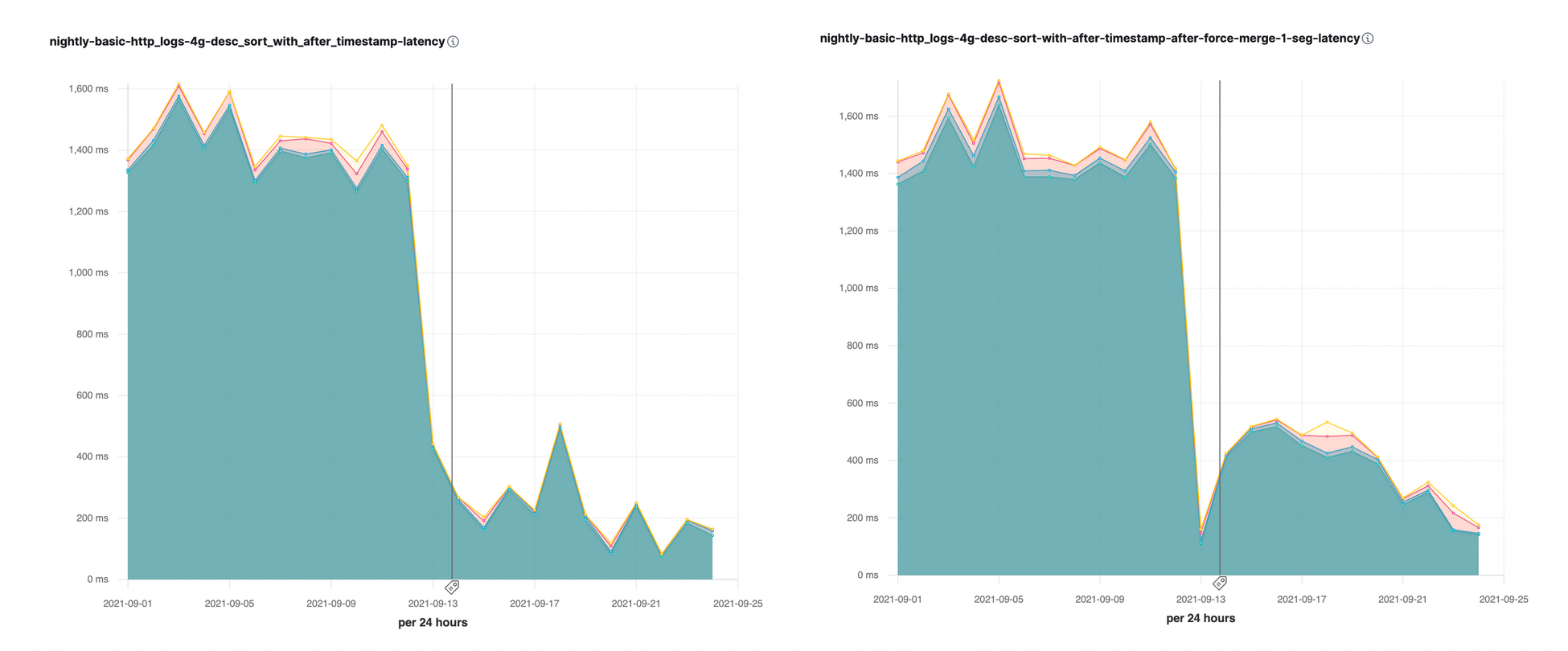
We have introduced this sort optimization with search_after parameter in Elasticsearch 7.16. We immediately saw great speedups (up to 10x) on some of our nightly performance benchmarks:
Optimizing sort across multiple segments
A shard consists of multiple segments. As Elasticsearch examines segments sequentially at search time, it would be very beneficial to start processing with the segment that is the best candidate for containing documents with top K values. Once we collect documents with top K values we can very fast skip other segments that only contain worse values.
Which segments to start processing with depends very much on the use case. For time series indices, the most common request is to sort results on the timestamp field descending, as the latest events are the most interesting to look at. To optimize this kind of sort for time series indices, we started to sort segments on @timestamp field descending, so we can start processing with a segment containing latest data, ideally collect in the first segment the top most recent by timestamp documents, and skip over all other segments. This resulted in quite good speedups for sort queries on the timestamp field descending.
As smaller segments are merged away into bigger segments, we don’t want to end up with new segments where the most recent documents are at the end. To have more balanced merged segments, we introduced a new merge policy that interleaves old and new segments, that is documents from old and new segments are arranged in the mixed order in a new combined segment. This allows us to efficiently find the most recent documents too.
Optimizing sort across multiple shards
The power of Elasticsearch is in its distributed search, and any optimizations would be incomplete without thinking about a distributed aspect. As some searches can span hundreds of shards (e.g. searches on time series indices), it would be very beneficial to start with “right” sets of shards and shortcut shards that should not contain competitive hits. And we have implemented exactly this approach. From Elasticsearch 7.6 we pre-sort shards based on the max/min value of the primary sort field, which allows us to start a distributed search with a set of shards that are the best candidates for containing top values. From Elasticsearch 7.7 we shortcut query phase using the results of other shards, that is once we collect top values from the first set of shards, we can completely skip the rest of shards as all their possible values are worse than the bottom sort values computed in prior shards. In many machine generated time series indices, the documents follow an index lifecycle policy, starting in performance optimized hardware and ending in cost optimized hardware before they are deleted. This shard skipping mechanism often means that the users can send a broad query and enjoy query performance defined by their performance optimized hardware, because the shards on the slower and more economic hardware are skipped (making the use of searchable snapshots particularly efficient).
Implications for users
How can you as a user of Elasticsearch take advantage of these sort optimizations? These sort optimizations only work if you don’t need to track the exact number of total hits for a request and the request doesn’t contain aggregations. If you need to know the exact number of total hits, we can’t do any skipping as we need to count all documents matching a filter. The default value of track_total_hits is set to 10,000, which means that the sort optimization only starts to kick off once we collect 10,000 documents. If you set this value to a lesser number or to “false”, Elasticsearch starts sort optimization much earlier, which means faster responses for you.
Recently Kibana also started to send requests where track_total_hits is disabled, so sort queries in Kibana should be faster as well.
Try it out
Existing Elastic Cloud customers can access many of these features directly from the Elastic Cloud console. If you’re new to Elastic Cloud, take a look at our Quick Start guides (bite-sized training videos to get you started quickly) or our free fundamentals training courses. You can always get started for free with a free 14-day trial of Elastic Enterprise Search. Or download the self-managed version of the Elastic Stack for free.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print