Migrating from Splunk to the Elastic Stack: Data migration
When Splunk was first released almost 20 years ago, it helped many organizations realize the power of logs to gain business insights with pricing based on the volume of data ingested per day. Over the last two decades, the volume, variety, and velocity of data generated by systems and users have grown exponentially. The demands of business and operations have quickly moved beyond compliance and basic reporting. Development methodologies and monitoring requirements have rapidly evolved, and the increased demands of machine learning to provide insights into data require the ability to search in real time.
Organizations are reaching data limits (a.k.a. “peak Splunk”)
Today, organizations need to be able to search petabytes of data in milliseconds to gain real-time insights into operations, power machine learning systems, and scale at the speed of business. The data ingest-based pricing system has rendered Splunk cost prohibitive. Combined with challenges to scaling the technology, many organizations have hit what they term “peak Splunk,” where they can no longer afford to add more data into their systems. These organizations are often dropping valuable data for security and observability use cases. To make things more complex, Splunk’s premium applications have different pricing model, and some are built on completely different platforms and architectures, making it difficult to predict costs as well as manage infrastructure for these disparate tools. Splunk’s recent deprecation of perpetual licensing has also driven many companies to search out a new solution.
Elastic was created with search as its initial use case, so it’s built for speed and scalability from the ground up. That speed and scalability also drives a growing family of solution offerings, all built on a single stack. With a flexible, open source licensing model as well as fair, resource-based pricing for premium offerings, more and more organizations are choosing to migrate from Splunk to Elastic.
A key feature of Elastic is its open source licensing model, which allows new users to get started without having to purchase a license. The license is quite permissive and even allows for developers to integrate Elasticsearch in their own offering. When developers are ready to leverage premium features such as machine learning, APM, cross-cluster replication, endpoint security, or orchestration tools, it’s as simple as upgrading their license. There’s no need to deploy additional tools, separate architectures, or additional hardware. The open source model also helps by keeping costs associated with managing multiple environments for development, staging, and production under control.
Migrating Splunk data to Elastic in four steps
Because of its unique advantages over Splunk, many organizations are making the switch to Elastic. Many of these organizations have asked us for best practices as they complete the migration. Although there is never an easy button to migrate from one data platform to another, there are some simple techniques organizations can follow.
Phase 1: Identify data sources not being ingested into Splunk
An easy first step is to review data sources that have not been brought into Splunk either due to cost (licensing) or technical constraints. These are often high-volume data sources such as DNS, DHCP, endpoint, and application logs. Beginning to ingest these previously untapped data sources into Elastic allows the organization to build out new use cases while also getting started with the Elastic Stack. And you can get started quickly by either downloading the free, Basic distribution of the Elastic Stack, or by spinning up a free trial of Elasticsearch Service on Elastic Cloud.
Phase 2: Inventory data sources to migrate from Splunk to Elastic
To adequately plan for a migration to Elastic, it’s important to take an inventory of what data sources are currently being ingested into Splunk. One easy way to do this is via a SPL query:
| eventcount summarize=false index=* index=_* | dedup index | fields index | map maxsearches=100 search="|metadata type=sourcetypes index=\"$index$\" | eval index=\"$index$\"" | fields index sourcetype
Once you run the query in the Splunk Search application, you have the option to export the list of data sources into various formats.
Phase 3: Migrate existing data flows from Splunk to Elastic
Beats is our family of data shippers that can be used to send data from thousands of systems to Elastic. However, many Splunk users may already have Splunk’s Universal Forwarder deployed to systems. You can bifurcate the data to the Elastic Stack using the Splunk Universal Forwarder as you begin your migration. Unfortunately, Splunk imposes technical and licensing constraints on how you can send data to third-party systems with their Universal Forwarder, so it is good to review documentation and licensing for the best method. Over time you should replace the Universal Forwarders with Beats modules for more flexibility, security, and reliability. The Elastic Consulting team has extensive experience working with difficult and custom data sources and can assist with your migration process.
Phase 4: Migrate old data from Splunk to Elastic
Although most organizations will want to start with fresh data, there are often use cases that require the migration of old data in Splunk over to Elastic. There are a number of methods for doing this depending on the volume of data. The easiest method is to export the data from the Splunk interface, as per Splunk’s documentation.
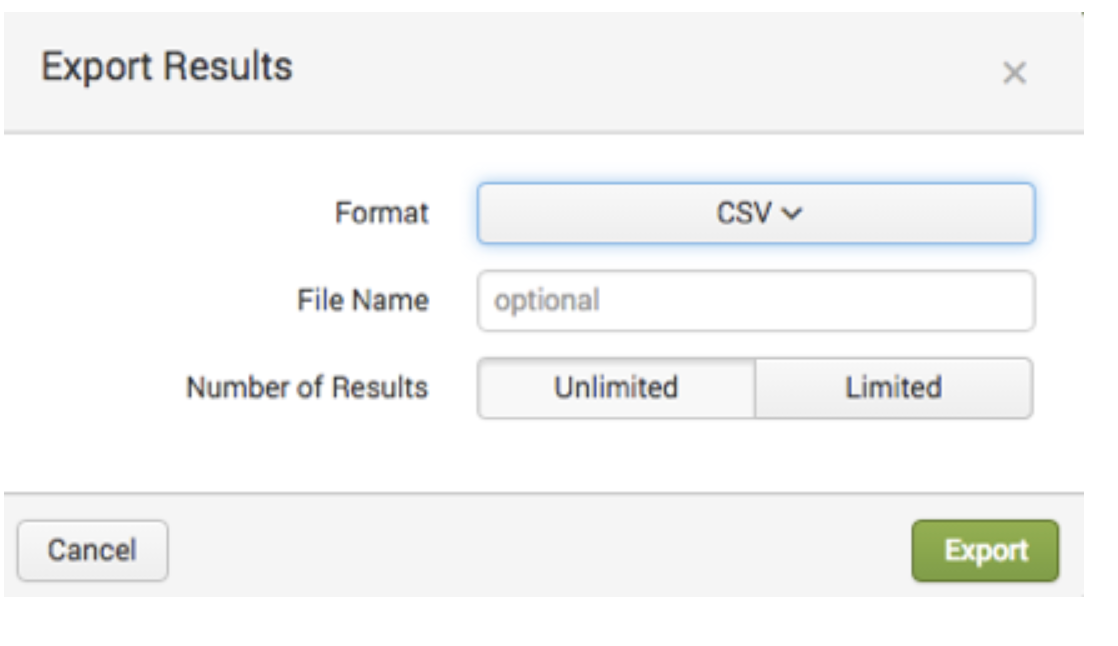
You can also use the Splunk API to export data, or you can connect via ODBC. The approach you use will depend on the use case, volume of data, and type of data you are working with.
Good migrations
While these four steps will help your organization plan for and migrate data from Splunk to Elastic, you will also need to train your team. Our Kibana for Splunk SPL Users training course is designed to help your team with this transition. We also offer consulting services to help with the migration process. If you want to see how other companies have successfully switched from Splunk to Elastic for better ROI, faster speed, and enhanced scalability, check out user stories from storage provider Box and ridesharing company Lyft. In the meantime, you can read more on our Splunk alternative page and reach out to us if you have specific queries.