How to Optimize Elasticsearch Machine Learning Job Configurations using Job Validation
The machine learning capabilities in Elasticsearch focus on identifying anomalies in time series data, and they support a vast amount of use cases from identifying suspicious login attempts to taxi route planning. This flexibility comes with a little catch, though. While we do our best to make machine learning easy to use by having all the options at hand, it can be overwhelming to deep dive into all the features (and learn about them) to find out what the best possible machine learning job configuration is for your particular scenario.
To help you out with that, we introduced automated job validation for machine learning in Elastic Stack 6.3. For 6.4, we plan to update the validation results with even more detailed messages and specific links to documentation. Job validation is available as an option on the jobs list page and in the job creation wizards to validate your settings before you create the job. Once you configured your job, you just click the “Validate Job” button and get back an analysis of the configuration and underlying data.
The job validation report is able to identify issues with your configuration and may come up with certain suggestions about how to modify the configuration to get more valuable insights. For example, you might be advised to reconsider your bucket span or choice of influencers. Where applicable, the report includes specific links to documentation.
Here’s a rundown on some of the checks that job validation is performing:
- Aggregatable Fields: This combines looking at your job configuration and the underlying index mappings and reports if there’s an issue with an non-aggregatable field, for example non-existing fields or text fields.
- Bucket Span and Time Range: Choosing an appropriate bucket span can be tricky. Job validation is able to give you some feedback about whether the bucket span you chose is fine to use given the frequency and time range of the underlying data.
- Cardinality: Depending on the resources available for machine learning and the type of analysis to be performed, some fields might be more or less suited to be used. For example, low cardinality fields might be less useful for population analysis and fields with very high cardinality may take up to many resources.
- Influencers: Using influencers offers a great way to learn more about the context of detected anomalies, and it’s highly recommended to use them. Job validation is able to come up with suggestions for influencers to pick based on the given job configuration.
Job Validation Example
Job validation is especially useful when used in combination with the advanced job wizard. Let’s have a look at an example. The data we’re trying to analyse are metrics of docker instances in several data centers. Once we edited some settings like the job name and detector, we hit the “Validate Job” button and have a look at the results:
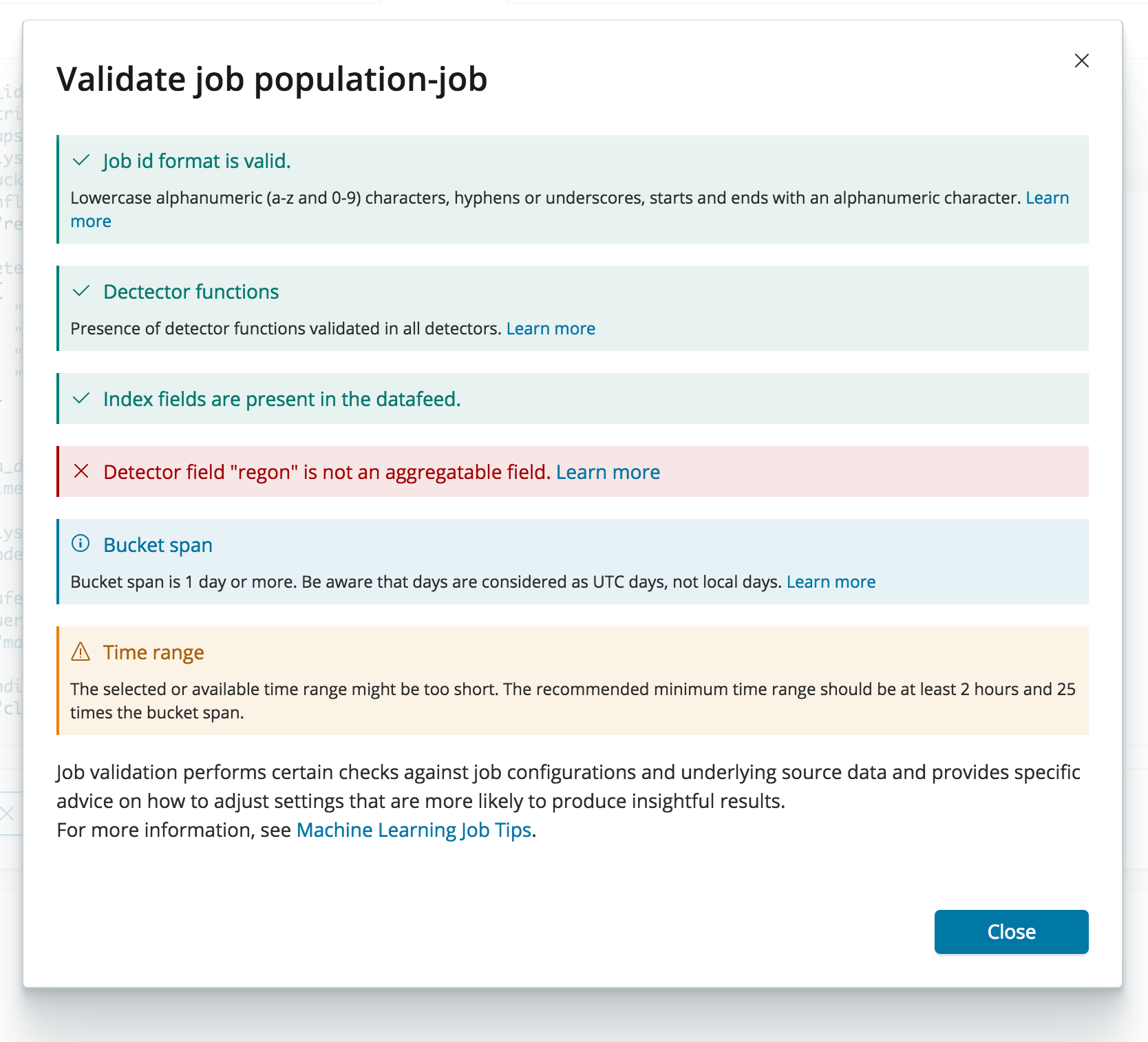
The report shows a mix of messages for successful checks, errors, warnings and recommendations with links to documentation. In this case, job validation was able to spot a typo after we manually edited the raw JSON based job configuration and identified that “regon” is not a field suitable for aggregating data for the datafeed. Let’s fix that to “region” and run job validation again.

The message changed now to a warning about the cardinality of the field. Since we used “region” (which refers to a data center in this particular source data) as an over_field, we might get unsatisfactory results when running a population analysis. High cardinality fields like IP addresses or usernames work much better for this. However, it might still be useful to add “region” as an influencer. Let’s change the over_field to a suitable field with higher cardinality:

Finally, we get a confirmation message that cardinality checks passed job validation! This is just one example how job validation can help you in coming up with better job configurations.
To summarize, in combination with the job creation wizards, job validation allows you to iterate on your job configuration before creating a job and catch common pitfalls, helping you to create more meaningful analysis configurations when experimenting with new use cases.