Elastic Security opens public detection rules repo
At Elastic, we believe in the power of open source and understand the importance of community. By putting the community first, we ensure that we create the best possible product for our users. With Elastic Security, two of our core objectives are to stop threats at scale and arm every analyst. Today, we’re opening up a new GitHub repository, elastic/detection-rules, to work alongside the security community, stopping threats at a greater scale.
The release of the detection engine in Elastic Security brought automated threat detection to the Elastic Stack. Since the initial launch of the detection engine, the Elastic Security Intelligence & Analytics team has added 50+ additional rules, increasing the visibility of attacker techniques on Linux, macOS, and Windows operating systems. As we continue to expand coverage, you’ll see increased breadth in detections, covering new domains such as cloud services and user behavior.
Over the past few releases, we used an internal repository to manage rules for the detection engine. We’ve iteratively improved our testing procedures by adding automated tests for new contributions that validate Kibana Query Language (KQL) syntax, schema usage, and other metadata. Our rule development has matured, so we can move fast without breaking things.
By opening up our elastic/detection-rules GitHub repository, Elastic Security will develop rules in the open alongside the community, and we’re welcoming your community-driven detections. This is an opportunity for all of us to share our collective knowledge, learn from each other, and make an impact by working together.
What’s in this new repository?
In the elastic/detection-rules GitHub repository, you can find rules written for Elastic Security, with coverage for many MITRE ATT&CK® techniques. Our current rule logic is primarily written in KQL, and by leveraging the Elastic Common Schema (ECS), we only need to write rules once. By using the defined fields and categories in ECS, rules automatically work with Beats logs and other data sources that map properly to ECS.
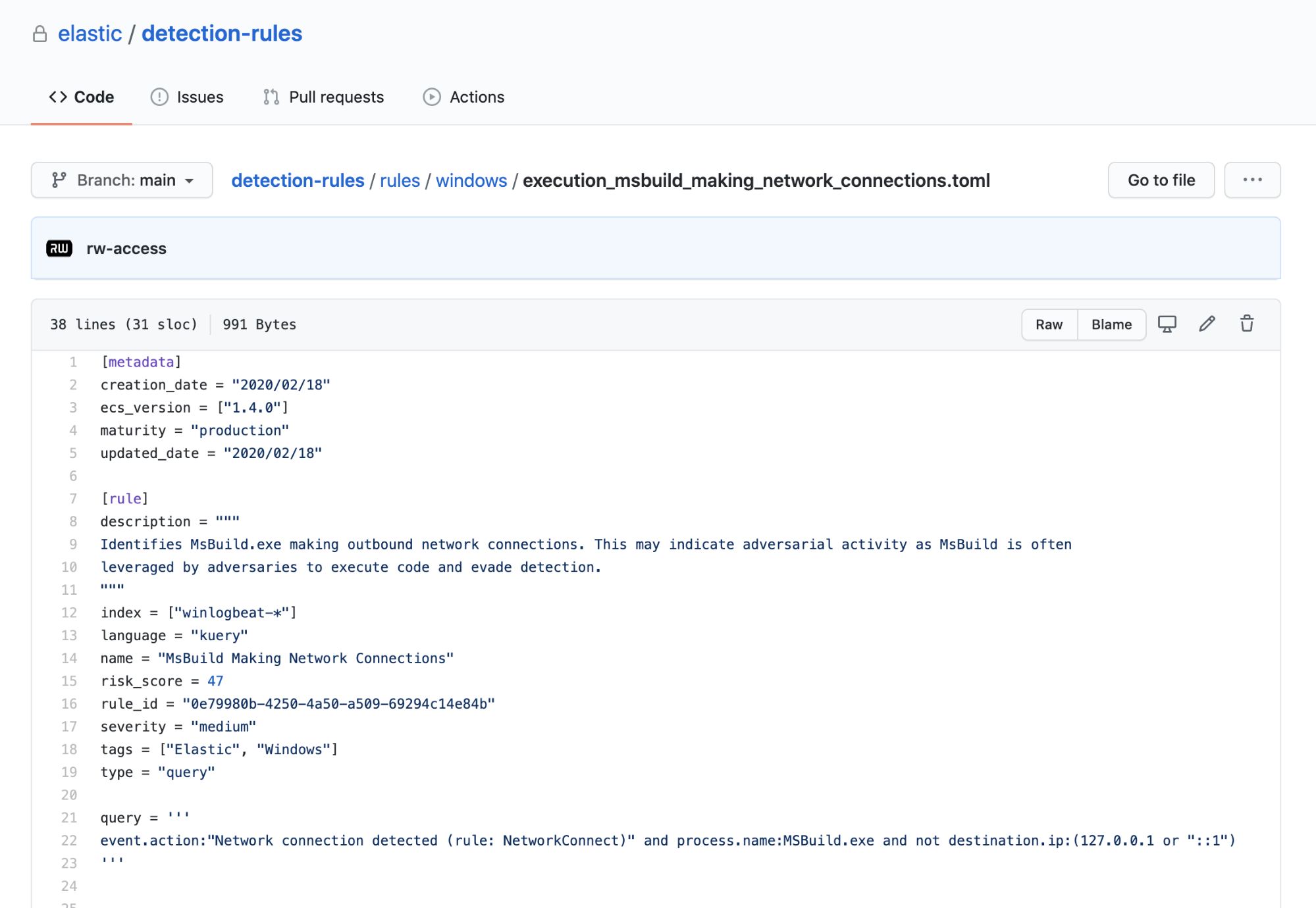
Within the rules/ folder, rules are stored in TOML files and are grouped by platform. We tried to keep it simple with a flat hierarchy so that it’s easier to find and add new rules. If you’re looking for Windows-only rules, navigate to rules/windows. If you’re still struggling to find a rule or want to search across rules, you can use our CLI by running the command python -m detection_rules rule-search, which will show the files that have matching metadata.
Every rule contains several fields of metadata in addition to the query itself. This captures information like the title, description, noise level, ATT&CK mappings, tags, and the scheduling interval. We have a few additional fields to aid analysts performing triage, describing known false positives or helpful steps for an investigation. For more information on the metadata that pertains to rules, see the Kibana rule creation guide or our summary of rule metadata in the contribution guide.
How do these rules get to my detection engine?
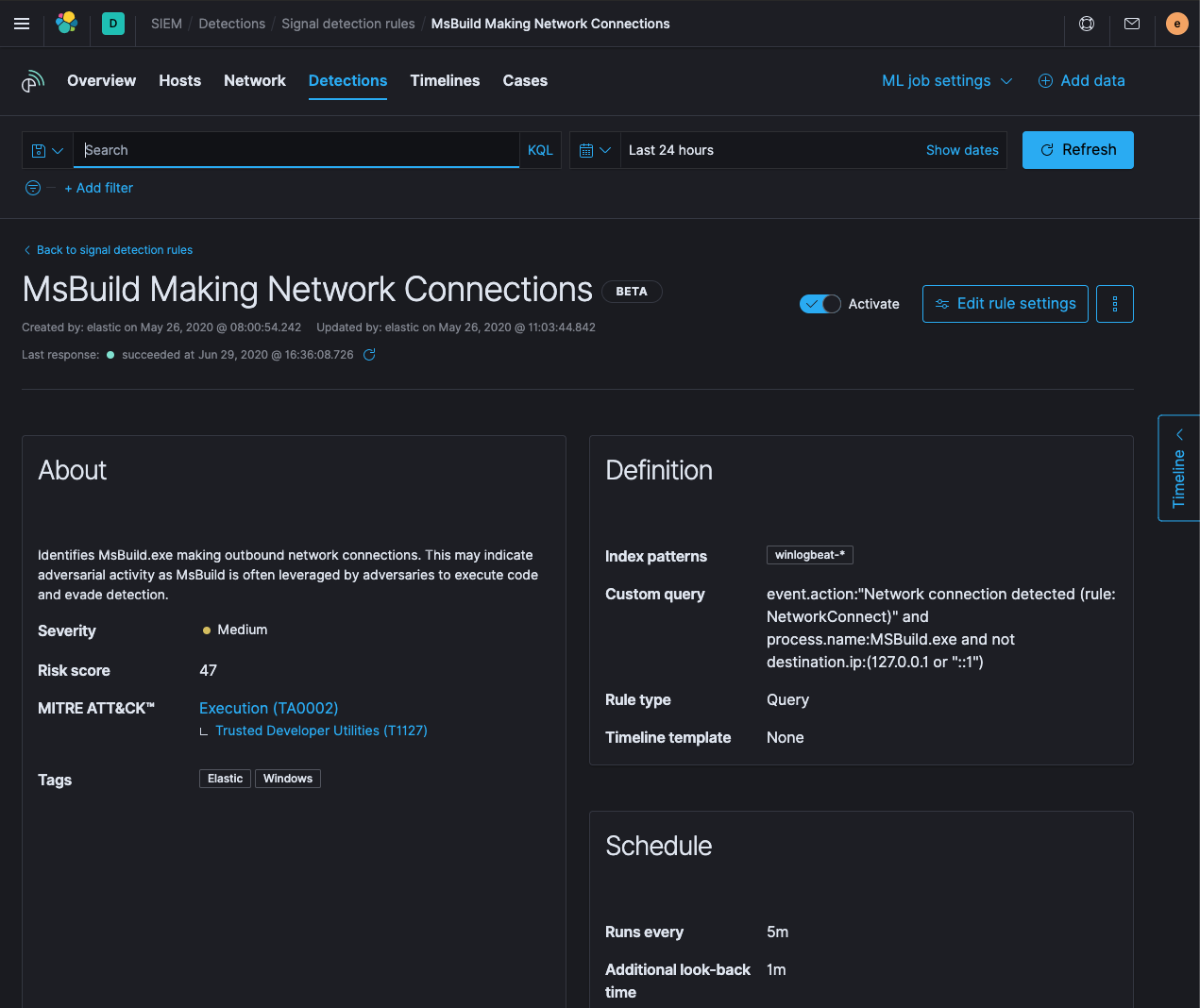
If you’re using our Elastic Cloud managed service or the default distribution of the Elastic Stack software that includes the full set of free features, you’ll get the latest rules the first time you navigate to the detection engine. When you upgrade, the detection engine recognizes that rules were added or changed and prompts you to decide whether you want those rules upgraded. Follow the steps after upgrading and you’ll get the latest copy of the rules.
Who will use this repository?
This repository is where the Elastic Security Intelligence & Analytics team will develop rules, create issues, manage pull requests, and target releases. By making the repo public, we’re inviting all external contributors into this workflow. This will give contributors visibility into our development process and a clear path for rules to be released with the detection engine.
When you’re ready to contribute, please sign Elastic's contributor license agreement (CLA). This is standard for all Elastic GitHub repositories, and it means that we freely can distribute your code to Elastic users.
How do we approach threat detection?
In general, we tend to prefer detections that focus on adversary behaviors. This usually means that we focus on ATT&CK techniques. This might mean more research and effort is needed to figure out how a technique works before creating a rule. But by taking this approach, we do a better job detecting and stopping the attacks of today and tomorrow, instead of just the attacks of yesterday.
Taking a behavioral approach also means we need various types of rules. Some might detect atomic events, others may require aggregating multiple events or looking for deviances above a threshold. With Event Query Language (EQL), we will be able to write rules that look for sequences of behavior that span multiple events.
Of course, we understand that sometimes a technique can be hard for all users to detect behaviorally. In that case, by all means, feel free to add a rule that is more signature-like in nature and written towards a specific behavior or tool.
For a longer discussion on what makes a mature detection, read about the philosophy of the detection rules repository.
Why do we need a new repository?
If you’ve shared public rules before, you’re probably aware of other well-known GitHub repositories, like the Cyber Analytics Repository (CAR) by MITRE, Sigma, or even the EQL Analytics Library based on Elastic’s EQL. You might be wondering: Why do we need another repository? Why not use the ones that already exist?
Unsurprisingly, the best answer to this question starts with another question: Why do the other repositories exist? Both CAR and Sigma are purposefully agnostic of language or platform, and sometimes data source. On the other hand, the EQL Analytics Library was written with a specific language in mind.
With our new detection rules repository, we’re trying to serve a slightly different purpose. Our goal is to give users of Elastic Security the best possible detections that work across various data sources. We use ECS as the great equalizer of schemas, making it possible to write a rule once that applies to multiple data sources.
Since the Elastic Stack supports multiple languages, our rules should reflect that. Query languages are typically developed to solve different types of problems, and we shouldn’t constrain rule developers to a single language if another does the job better. We currently have KQL and Lucene rules, along with rules that use machine learning anomaly detection jobs in the repository. We’re working hard to bring EQL to the Elastic Stack and into our repository.
We can also ensure best practices are being followed for optimal Elasticsearch performance. For example, searching for process.path:*\\cmd.exe requires performing a wildcard check, which is more costly than a simple keyword check. Instead of searches containing leading wildcards, we can recommend using process.name:cmd.exe, which will result in better performance and the most accurate results. On a similar note, ECS also contains the field process.args, which is a parsed version of process.command_line. We recommend using the parsed field instead, because it gives us better performance and means that we are much less prone to trivial whitespace or quotation-based evasions. Win-win.
Can I add rules from another repository?
Within your own environment, you’re welcome to add rules to your own detection engine as long as your Kibana role has the right permissions. If you want to add rules to the elastic/detection-rules repository, the answer is an unsurprising: It depends.... As long as a rule can be sublicensed under the Elastic License, this is fair game. Most of the time, the requirements are fairly straightforward — retain the original authors in the rule.author array, and update the NOTICE.txt file accordingly to give attribution to the original authors. We don’t want to take credit for someone else’s work, so please help us be thorough!
For more information on how we approach licensing in the repository, check the Licensing section of the README.
How do I contribute?
Eager to share your rule logic? Hop on over to elastic/detection-rules on GitHub. We have detailed instructions there for navigating the repository, forking and cloning, and creating a rule. We include a command line tool for bulk editing the files and to make creating new rules easier. When you’re ready to add a new rule to the repository, run python -m detection_rules create-rule, and you’ll be prompted for the required metadata. We recommend using the CLI when possible, because it reduces copy-and-paste errors that happen when reusing contents from a TOML file from another rule or template.
When your rule is in a good state, you can run the command python -m detection_rules test to locally perform unit tests, which validate syntax, schema usage, etc. Then, create the pull request and someone on the Intelligence & Analytics team will review the contribution. If we request any changes, we’ll work with you to make the recommended changes.
If you have a good idea for a rule, but want to collaborate with us on the idea or get feedback, feel free to create a New Rule issue. We look forward to helping and brainstorming with you!
For more information, check out the contribution guide.
What’s next?
Welcome to our new rules repository and workflow! Your contributions are encouraged, and we look forward to seeing your name in the rule.author field. The detection rules repository will continue to evolve along with the rest of Elastic Security, and we’re excited for what’s next.
If you want to track the development of EQL in the stack, subscribe to this GitHub issue. Or take a peek at the ongoing documentation to watch what the Elasticsearch team is up to.
If you have any feedback or questions writing rules or navigating our new detection rules GitHub repository, please create an issue in GitHub, reach out on the discussion forum with the detection-rules tag, or find us in the #detection-rules channel of the Elastic Slack Community.