Elastic Enterprise Search API clients for Ruby and Python
From the team that develops the popular Elasticsearch language clients, we're proud to announce the beta release of Ruby and Python API clients for Elastic Enterprise Search 7.10! 🎉 🎉 🎉 With these clients, you’ll be able to control and communicate with your Elastic Workplace Search and Elastic App Search services in a whole new way.
The client packages are open source under the Apache 2.0 license and use the same battle-tested and resilient HTTP implementation used in the Ruby and Python Elasticsearch clients. Currently, these clients are beta, but hope to go GA soon. We appreciate any feedback from early adopters of these new clients, as your testing helps us get to GA faster. Let’s see what we can build with them!
Getting started with the Elastic Enterprise Search clients
All client source code for both enterprise-search-ruby and enterprise-search-python is available on GitHub along with guides on how to get started and API documentation. The first step for using any library is to install it with your package manager of choice:
To install with Ruby use gem to install the elastic-enterprise-search gem:
$ gem install elastic-enterprise-search --pre
To install with Python use pip to install the elastic-enterprise-search package:
$ python -m pip install --pre elastic-enterprise-search
Note that when installing either that the --pre flag is necessary to install beta versions of packages.
Now that you have your client installed, let's go through a short example of client functionality. Using Elastic App Search and Ruby, we’ll index and search documents. With Elastic Workplace Search and Python, we’ll be creating our own custom content source.
Deploying an Enterprise Search instance
The easiest way to get started with Enterprise Search is deploying to Elastic Cloud. With a 14-day free trial, you can spin up an Enterprise Search instance in minutes. You can also download and deploy locally, but for all our examples below we’ll be using an instance deployed in Elastic Cloud.
To get started, log into the Elastic Cloud console, and spin up a new deployment using the Enterprise Search template. After our Enterprise Search instance has been provisioned on Elastic Cloud, copy the password for the elastic user — we’ll need this later! We can find the Enterprise Search endpoint and copy it into our clipboard by selecting Copy Endpoint within the deployment:
Once we’ve copied the endpoint into our clipboard you can paste the URL. It should look something like this:
https://[CloudID].ent-search.us-central1.gcp.cloud.es.io/login
Notice the /login on the end of the URL. You must remove that from the URL and pass the remaining URL to client constructors:
https://[CloudID].ent-search.us-central1.gcp.cloud.es.io
After copying the endpoint, we can launch Enterprise Search in our browser by clicking the Launch link next to Copy endpoint. Enter elastic for the username and then the password you received once you created the deployment. You’ll see a screen that allows choosing either Elastic App Search or Elastic Workplace Search like the one below:
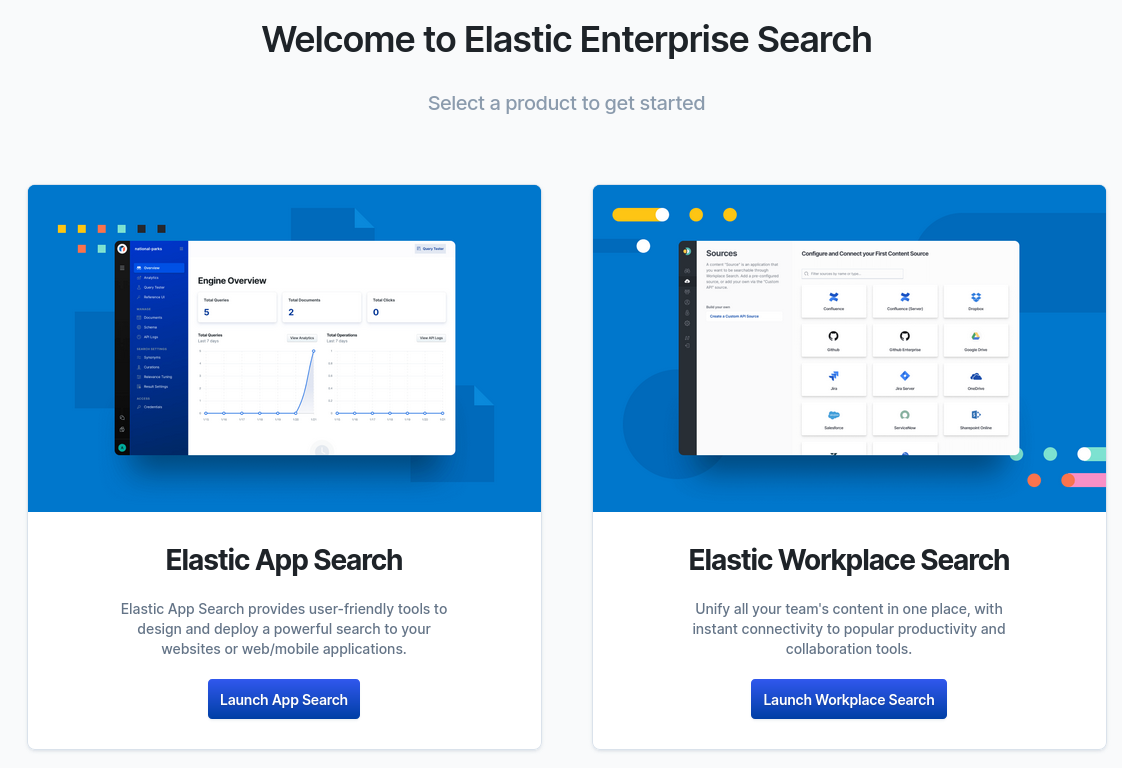
From here our guide diverges into either Elastic App Search with Ruby or Elastic Workplace Search with Python. You can follow along with the one you’re most interested in, but I'd recommend checking out both!
Indexing and searching documents in Elastic App Search with Ruby
Engines are a core concept in App Search. Usually you create a new engine in App Search, start indexing documents into it, and search for content in a given engine. So in this tutorial we’re going to use the Ruby Elastic Enterprise Search client to create an engine, index a few documents, and search for results in that engine.
Step 1: Credentials
In the App Search UI, you need to click on the Credentials link on the left menu. Here you can create a new key for the client. For this example, we’re going to use the default provided key, which gives us read/write access.
We need to copy the value of this key to our clipboard since we’ll use it when instantiating the client:
Step 2: Configure the Ruby client
Now we’re going to create a Ruby file where we instantiate and configure the Elastic Enterprise Search App Search client:
require ‘elastic-enterprise-search’ # paste here the api key you copied before: api_key = <your_api_key> host = "https://<deployment>.ent-search.us-central1.gcp.cloud.es.io" client = Elastic::EnterpriseSearch::AppSearch::Client.new(host: host, api_key: api_key)
Step 3: Create an engine
Now we’ll use the client to create our first engine. For this example, we want to index some book titles and authors. So we’ll create the “books” engine:
client.create_engine(name: 'books')
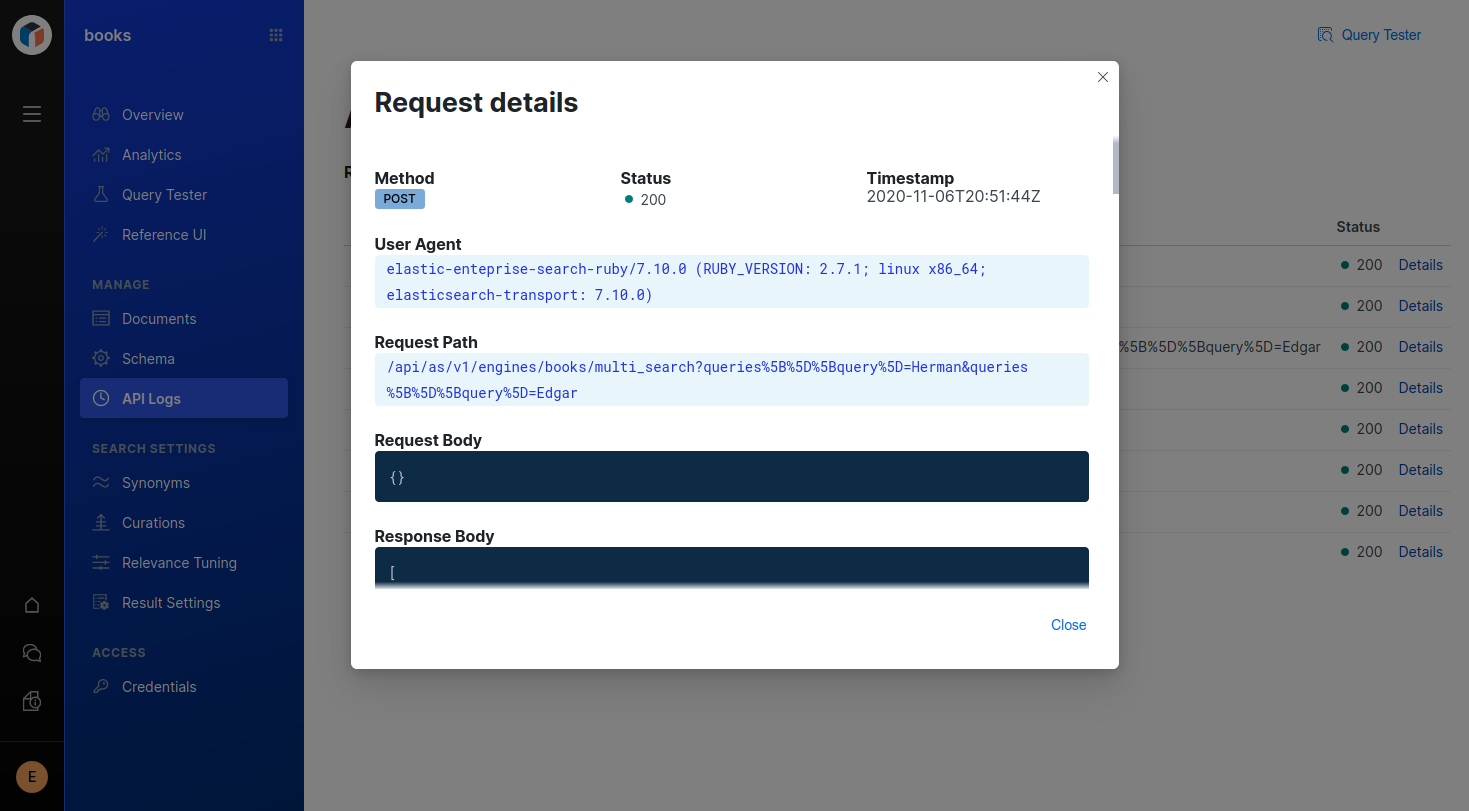
As mentioned at the beginning of this post, the Enterprise Search clients use the Elasticsearch client’s HTTP transport libraries. So the response is built by the ‘elasticsearch-transport’ gem. We can save the response object and check out the response details. Let’s try this with list_engines:
> response = client.list_engines
> response.headers
=> {"x-frame-options"=>"SAMEORIGIN", "x-xss-protection"=>"1; mode=block", "x-content-type-options"=>"nosniff", "x-app-search-version"=>"7.10.0", "content-type"=>"application/json;charset=utf-8", "vary"=>"Origin", "etag"=>"...", "cache-control"=>"max-age=0, private, must-revalidate", "x-request-id"=>"...", "x-runtime"=>"0.297253", "transfer-encoding"=>"chunked", "server"=>"Jetty(9.4.30.v20200611)"}
> response.status
=> 200
> response.body
=> {"meta"=>{"page"=>{"current"=>1, "total_pages"=>1, "total_results"=>1, "size"=>25}}, "results"=>[{"name"=>"books", "type"=>"default", "language"=>nil}]}
Step 4: Index some documents
Let’s index some documents to our engine:
> documents = [
{ title: 'Frankenstein; Or, The Modern Prometheus', author: 'Mary Wollstonecraft Shelley' },
{ title: 'Pride and Prejudice', author: 'Jane Austen' },
{ title: 'The Strange Case of Dr. Jekyll and Mr. Hyde', author: 'Robert Louis Stevenson' },
{ title: 'Beowulf: An Anglo-Saxon Epic Poem', author: 'J. Lesslie Hall' },
{ title: 'Metamorphosis', author: 'Franz Kafka' },
{ title: 'Moby Dick; Or, The Whale', author: 'Herman Melville' },
{ title: 'Siddhartha', author: 'Hermann Hesse' },
{ title: 'Leviathan', author: 'Thomas Hobbes' },
{ title: 'The Republic', author: 'Plato'},
{ title: 'The War of the Worlds', author: 'H. G. Wells'},
{ title: 'The Masque of the Red Death', author: 'Edgar Allan Poe' },
{ title: 'The Jungle Book', author: 'Rudyard Kipling'}
]
> response = client.index_documents('books', body: documents)
Unless we specify an id per document, a unique identifier will be generated. The response body will be an array of hashes with the keys id and errors, which is an array of error messages in case an error occurs.
Step 5: You know, for search
To perform a single search query, we need to specify the engine name and the query:
> response = client.search('books', body: { query: 'Franz' })
> response.body["results"]
=> [{"title"=>{"raw"=>"Metamorphosis"}, "_meta"=>{"id"=>"doc-...", "engine"=>"books", "score"=>1.7777123}, "id"=>{"raw"=>"doc-..."}, "author"=>{"raw"=>"Franz Kafka"}},...
We can also perform a multiple query search:
> queries = [{ query: 'Herman' }, { query: 'Edgar' }]
> response = client.multi_search('books', queries: queries)
Since we’re sending two different queries, the response body will be an array of two hashes with the respective results:
> response.body[0]["results"]
=> [{"title"=>{"raw"=>"Moby Dick; Or, The Whale"}, "_meta"=>{"id"=>"doc-...", "engine"=>"books", "score"=>2.2699733}, "id"=>{"raw"=>"doc-..."}, "author"=>{"raw"=>"Herman Melville"}}, {"title"=>{"raw"=>"Siddhartha"}, "_meta"=>{"id"=>"doc-...", "engine"=>"books", "score"=>0.26182064}, "id"=>{"raw"=>"doc-..."}, "author"=>{"raw"=>"Hermann Hesse"}}]
> response.body[1]["results"]
=> [{"title"=>{"raw"=>"The Masque of the Red Death"}, "_meta"=>{"id"=>"doc-...", "engine"=>"books", "score"=>1.4695505}, "id"=>{"raw"=>"doc-..."}, "author"=>{"raw"=>"Edgar Allan Poe"}}, {"title"=>{"raw"=>"The Masque of the Red Death"}, "_meta"=>{"id"=>"doc-...", "engine"=>"books", "score"=>1.4695505}, "id"=>{"raw"=>"doc-..."}, "author"=>{"raw"=>"Edgar Allan Poe"}}]
And now that you’ve indexed some documents, you can take advantage of the power of App Search’s UI and interact with the data you’ve ingested via the client.
App Search’s Documents view:
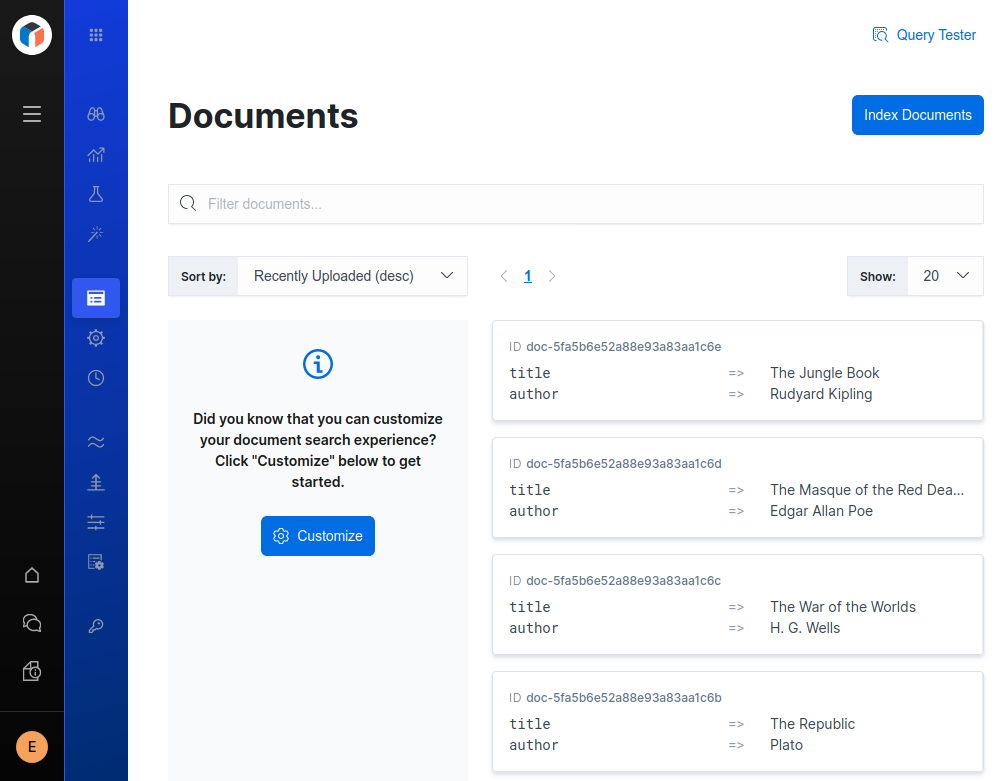
API Logs:
Create a custom source in Elastic Workplace Search with Python
This tutorial will show how to create a custom content source in Elastic Workplace Search using Python to programmatically index and update documents.
Step 1: Custom source
The first step towards writing a custom source is creating one in the Elastic Workplace Search UI. Select Add Sources and then Custom API Source. We’ll name our source “custom-source-python”.
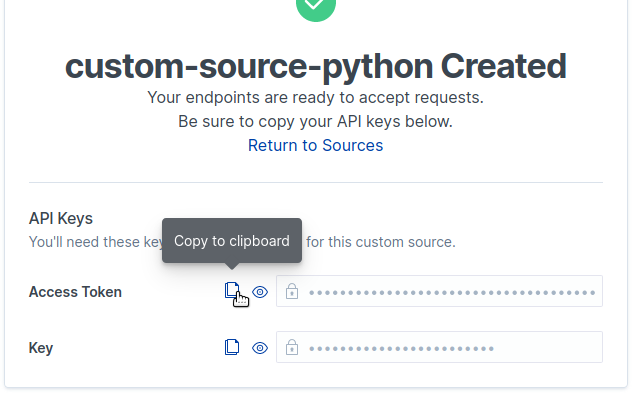
Step 2: Access token
Now that the custom source has been created, we can copy both the access token and content source key to be used by our Python client.
Step 3: Configure the Python client
With the access token and content source key in hand, we can start writing Python. Import the WorkplaceSearch client from the elastic_enterprise_search namespace and configure it like so:
from elastic_enterprise_search import WorkplaceSearch endpoint = "https://<deployment>.ent-search.us-central1.gcp.cloud.es.io" access_token = "<access token>" content_source_key = "<content source key>" client = WorkplaceSearch( hosts=endpoint, http_auth=access_token )
Let's give it a try!
Now that we have a client configured we can index some documents. Notice how we can create datetime objects and the client will handle serializing to JSON for us:
from datetime import datetime
from dateutil import tz
created_at = datetime(
year=2020,
month=10,
day=30,
hour=12,
tzinfo=tz.UTC
)
resp = client.index_documents(
content_source_key=content_source_key,
body=[
{
"id": 1234,
"title": "The Meaning of Time",
"body": "Not much. It is a made up thing.",
"url": "https://example.com/meaning/of/time",
"created_at": created_at,
"type": "list",
},
{
"id": 1235,
"title": "The Meaning of Sleep",
"body": "Rest, recharge, and connect to the Ether.",
"url": "https://example.com/meaning/of/sleep",
"created_at": created_at,
"type": "list",
},
],
)
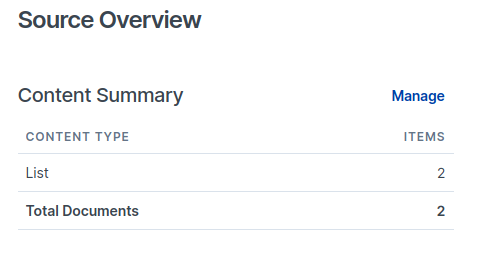
Now we can check out our content source in Elastic Workplace Search and see that two documents have been indexed successfully. 🎉
Legacy App Search and Workplace Search clients
There are currently API clients for App Search and Workplace Search packaged separately for both Python and Ruby. These clients still work but will be deprecated in favor of the new API clients once the new clients reach general availability in Elastic Enterprise Search in a future release. Migrating to the new API clients likely won’t require much effort due to similarities between the APIs.
Wrapping up
We plan on supporting additional languages with their own Enterprise Search clients soon. In the meantime, if you haven’t already, you can start up a free trial of Enterprise Search on Elastic Cloud to try out the new Ruby and Python clients.