What’s the difference? Elastic data tiers and Amazon OpenSearch Service tiers
Discover the key differences between Elastic and Amazon OpenSearch Service data tiers for smarter, cost-effective data management
_Blog_header_image-_Elastic_vs_AmazoN_OPT_2_V1.jpg)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In the realm of data management, terms like Hot, Warm, and Cold get tossed around frequently when discussing how data should be made available and/or retained given different performance requirements.
When comparing Elastic®’s data tiers to Amazon OpenSearch Service tiers, there’s yet another challenge — the same terms don't mean the same thing. Through this explanation, we seek to clear up any misconceptions around similar data tier terminology between Elastic and Amazon OpenSearch Service. With the insights provided here, you'll be in a prime position to strategically manage your data, maximizing performance while minimizing costs. This chart is a handy summary:
What are data tiers? At a fundamental level, data tiers are distinct storage levels that classify data based on criteria like access frequency, cost efficiency, and performance needs. They allow for optimized data organization and can help reduce costs by aligning storage expenses with the value of the information over time.
What a difference a tier makes
The concept of data tiers is present in most data platforms, especially in those that deal with observability and/or security tools. The volume of data collected by these tools is usually very high, with thousands/millions of events per second being processed and made available for searching, dashboarding, and alerting. Observability and security also have a shared characteristic: the most recent data is also the most valuable, as teams administering these tools rely on the signals being collected to take immediate action in case of problems.
So it makes sense for data to be ingested and stored with the fastest possible hardware and moved “down” to cheaper, less powerful hardware as time passes.
Data journey in Elastic
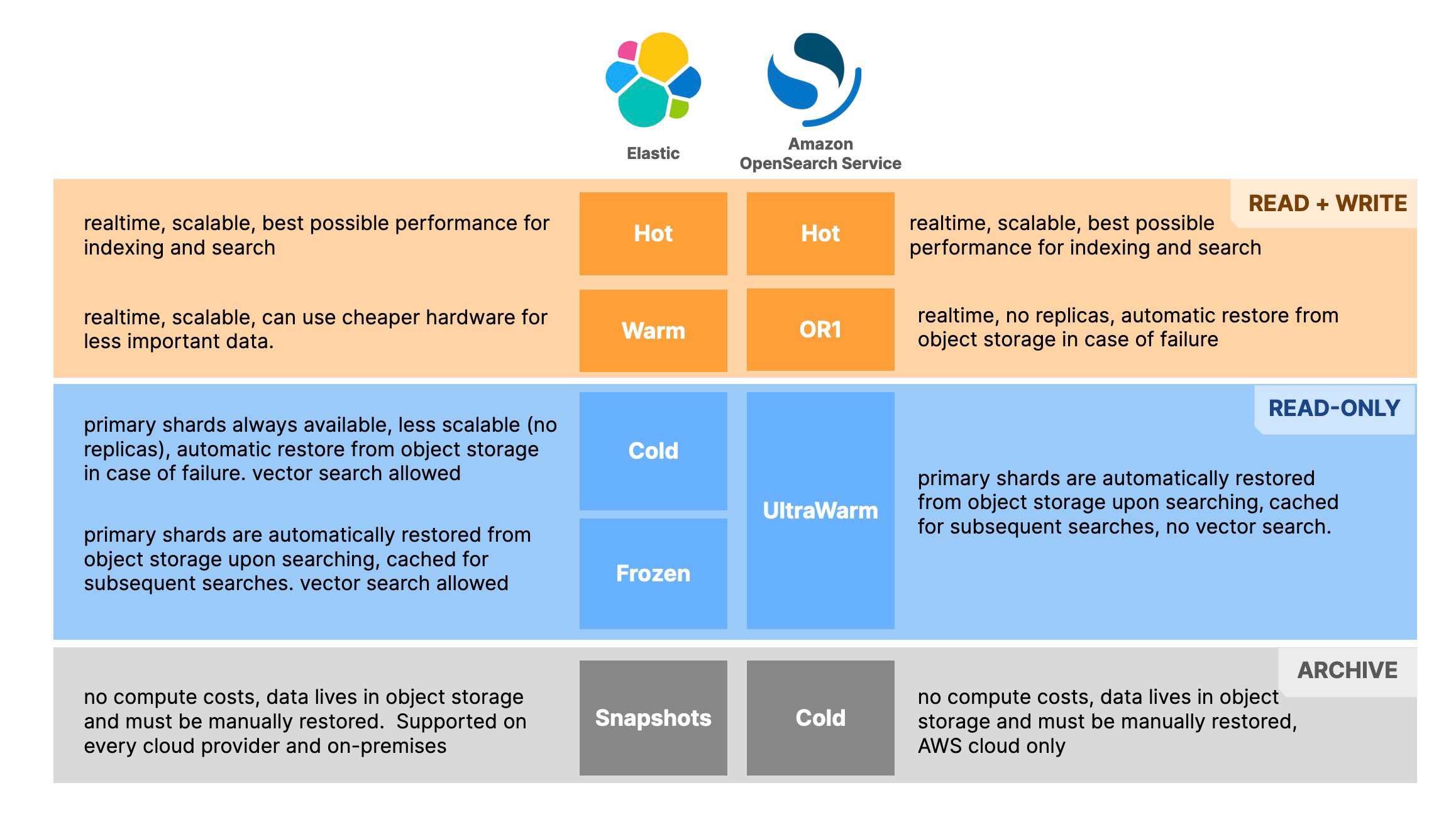
Elastic has five tiers, which can be independently or collectively utilized depending on your specific use case:
Hot: Your data always arrives here first, and it’s highly-available in real time, scalable, and offers the best possible performance (assuming best practices are adhered to). This is where you keep data that you need to access and manipulate frequently.
Warm: This tier allows for more cost-effective hardware utilization, where data that isn’t in immediate demand (but still relatively important) can reside. You can move data to this tier and optimize it (by force-merging the segments for instance), so searches are as fast as possible. Data in this tier is still scalable with replicas, just like in the Hot tier so as to meet search demands if needed.
Cold: Here it ensures at least one copy of the data will always be allocated to the node and searchable at any given moment. The Cold tier uses object storage to aid in data restoration should there be a failure or a need to alter the topology of the cluster.
Frozen: In this tier, data is less frequently accessed and allows for cost savings as it leverages the lowest cost storage and reduces compute resources. Data is searchable, but it must be restored back into a searchable state, which is done automatically and transparently with Elasticsearch®’s searchable snapshots.
Snapshots: Snapshots are essentially data backups — point-in-time copies of your indices. These can be used for various purposes, such as data recovery in case of a loss, creating clones of indices for testing or staging environments, or for migrating data between clusters. Snapshots are stored in a repository, which could be on different storage systems like a local filesystem or object storage (e.g., GCS, S3) and must be manually restored for data to be searchable.
Wait, what is a “shard”?
In Elasticsearch (and therefore also OpenSearch), a “shard” is essentially a self-contained index that holds a portion of your data, enabling the distribution of large data sets across multiple nodes (servers) for improved performance and scalability.
There are two types of shards: primary shards and replica shards. Primary shards are the main containers where data is first stored; each record is stored in only one primary shard. Replica shards are copies of the primary shards that provide redundancy in case of a failure and also allows the system to handle more read requests by load balancing search queries across the replicas. To a newcomer, you can think of shards as individual chapters of a book; while each chapter (shard) contains a different section of the story (data), multiple printed copies (replicas) ensure that even if one gets lost, the story can still be fully read.
Data journey in Amazon OpenSearch Service
Amazon OpenSearch Service has four tiers:
Hot: Your data always arrives here first, and it’s highly-available in real time, scalable, and offers the best possible performance, assuming best practices are adhered to.
OR1: Data is both readable and writable, as OR1 has compute power permanently attached to it, but there are no replicas. Data is restored from object storage in case of failure.
UltraWarm: This tier is designed for cost-effective storage and querying large data volumes that are accessed less frequently. UltraWarm nodes in Amazon OpenSearch Service provide a secondary storage tier that keeps data queryable.
Cold: Data in OpenSearch’s Cold tier typically incurs lower storage costs, but it’s not directly searchable. Accessing Cold data generally involves manually restoring the data to a warmer tier, which is then made searchable.
Side-by-side comparison
Now we can compare the tiers in terms of data access capabilities: can data be read and written or is it read-only? Does it need to be manually restored or is the “thawing” process automatic? Here’s what each “band” represents:
Read + Write
.png)
This band considers Hot in both Elastic and OpenSearch as their fastest tier. Since they are supposed to be equivalent, we compared their performance in this blog.
The next tier, Warm in Elastic and OR1 in Amazon OpenSearch Service both allow data to be updated but have differences in terms of scalability — while Elastic's Warm allows for replicas and lets you scale to meet search demands, OR1 does not, since only the primary shards are allowed to be used.
Read-Only
.png)
This band does not allow for data to be updated (written); it only allows for data to be migrated from other tiers. All tiers in this group have object storage backup and no replicas.
Both Frozen tier in Elastic and UltraWarm in Amazon OpenSearch Service store the data in object storage as snapshots and retrieve this data if a search is issued in any of the involved indices. Only then the data is made available and then cached for subsequent searches. However UltraWarm nodes come in only two configurations currently: either one that can address 1.5TB of snapshot data or another that can address 20TB of snapshot data. This means that if we wanted to store 100TB worth of data, we would need 5 UltraWarm nodes in Amazon OpenSearch Service but only 2 Frozen nodes in Elastic, which has different hardware profiles with different combinations of vCPU, RAM, and NVMe storage.
Furthermore in Elastic, both Cold and Frozen rely on the searchable snapshots feature, which allows snapshots as old as 5.0 (released way back in 2016!) to be searched without the need to be restored to an active cluster — this is very useful for governance and compliance, security investigations, and historical lookbacks regardless of what Elasticsearch version you are on.
Archive
.png)
Snapshots are stored in a repository, which could be on different storage systems like a local filesystem or object storage (e.g., GCS, S3) and must be manually restored for data to be searchable.
Hardware profiles
Another important aspect to consider is the instance types used in each tier. It’s also important to note Elastic Cloud supports three major cloud providers (AWS, Google Cloud, and Microsoft Azure) with different hardware profiles on each. Amazon OpenSearch Service’s approach designates specific instances (like OR1 and Im4gn) to its service with particular software version requirements and restrictions on EBS volume support.
Both Amazon OpenSearch Service and Elastic Cloud on AWS utilize Graviton2 based instances, indicating a shared preference for the performance gains and cost efficiencies of AWS’s ARM-based chipsets. Elastic Cloud on AWS is less prescriptive about the exact use-cases for its instances, providing a selection that includes high compute with fast storage (Graviton2 instances) and a variety of more traditional choices (like C5d, M5d, etc.).
Why does this matter?
Naming conventions can be misleading, causing understandable confusion when trying to align business needs to data storage options among providers. Having a grasp on the actual capabilities of these tiers can help you make more informed and cost-effective decisions regarding data management.
This breakdown is meant to dispel misconceptions brought about by the naming overlap in data tiers between Elastic and Amazon OpenSearch Service. With this description of data tiers, you’ll be better positioned to organize your data strategically for performance and cost benefits. It’s critical to move beyond the names and understand the underlying mechanics of each tier to ensure your data strategy is both robust and efficient.
Please also see the following studies: Elasticsearch surpasses OpenSearch in cost efficiency along with how Elasticsearch outperforms OpenSearch while using fewer resources.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print