Kubernetesオブザーバビリティチュートリアル:ログの監視と分析編
近年Kubernetesはコンテナーオーケストレーションのデファクトスタンダードの地位を獲得し、クラウドネイティブのムーブメントに必須のテクノロジーとなりました。 クラウドネイティブなアプローチはソフトウェア開発にスピードと弾力性、アジリティをもたらします。その反面、ソフトウェアは複雑化し、何千(あるいは何百万)ものコンテナー上に構築された数百ものマイクロサービスが短命な使い捨てpod内で稼働するようになりました。このように複雑で分散された一過性のシステムの監視は簡単ではありませんが、重要であり、不可欠なタスクです。嬉しいニュースもあります。Elasticはお使いのKubernetes環境にオブザーバビリティを簡単に確立できるテクノロジーを提供しています。
Kubernetesのオブザーバビリティを取り上げるこのチュートリアル記事シリーズは、Kubernetesで実行されるアプリケーションをあらゆる側面から監視する方法をご紹介します。具体的には、次の内容を取り上げます。
このチュートリアル記事を読了いただくと、監視と分析のため、すべてのオブザーバビリティデータをElastic Stackにシッピングするアプリケーションの動作事例を理解できます。
KubernetesにElasticオブザーバビリティを使う理由
オブザーバビリティは、ログとメトリック、およびアプリケーションパフォーマンス監視(APM)という、データの3つの“柱”により成り立っています。巷には異なるツールやベンダーを組み合わせて“ベストオブブリード”のKubernetes監視を実践するための記事があふれており、3つ、あるいは6つの異なるツールやベンダー、テクノロジーをつぎはぎで使うというフランケンシュタイン的な手法が紹介されています。
大丈夫、この記事は怪談ではありません。Elasticオブザーバビリティなら、1つのツールだけでログとメトリック、APMデータを組み合わせ、一元的な可視性と分析を確立することができます。たとえばAPMデータを分析し、ユーザー側に生じたレイテンシーの異常を機械学習で検知したことをきっかけにトラブルシューティングを開始した場合、特定のKubernetes podのメトリックを変換して、そのpodが生成したログを調べたり、ホストやネットワークで生じたイベントを説明するメトリックやログと相関付けしたりする作業もすべて1つのユーザーインターフェース上で完結します。これが、Elasticの考える“適切なオブザーバビリティ”です。
Elasticオブザーバビリティはシンプルに操作できるよう設計されていますが、内部では多数の処理が行われています。もちろん、それには理由があります。
Kubernetesのログは“移動する標的”である
Kubernetesはコンテナーを利用可能なホストにデプロイすることにより、オーケストレーションを実行します。つまり、アプリケーションのコンポーネントはネイティブに異なるホストにわたって分散されており、コンポーネントがどこに着地するか事前に把握することは不可能です。
Kubernetes pod内で稼働するコンテナーは、stdoutまたはstderr形式でログを生成します。これらのログはkubeletと呼ばれる場所に書き込まれ、podのIDを含むファイル名がつきます。Kubernetesのログと、そのログを生成したコンポーネントやpodをリンクさせるには、現在のホストで稼働しているコンポーネントpodとそのIDを把握しなければなりません。
さらに複雑なことに、Kubernetesはアプリケーションをスケールイン、またはスケールアウトさせることがあり、結果としてアプリケーションコンポーネントに含まれるpodの数が変化することもあります。
ラッキーなことに、Filebeatは“移動する標的”を得意としています。
つまり、podのログを収集するために必要な作業はFilebeatをKubernetesクラスター内のDaemonSetとして実行させることだけです。Filebeatをローカルのkubelet APIと通信させ、現在のホストで実行中のpodのリストを取得したり、そのpodが生成するログを収集したりするよう設定できるからです。収集されたログには、pod idやコンテナー名、コンテナーラベル、注釈など、関連するすべてのKubernetesメタデータによる注釈が含まれます。
Filebeatはこのような注釈データを使ってpod内で稼働するコンポーネントの種類を特定し、処理対象のログに、どのロギングモジュールを適用するかを自動で判断します。「ママこれ見て!手を離してるんだよ!」と叫ぶ必要はありませんが、Filebeatを使ったKubernetesログのインジェストは驚異的に簡単です。さっそくKubernetes監視向けにFilebeatを導入する手順の説明をはじめたいところですが、その前に1つ簡単な(ちょっと長めです)留意点を確認しましょう。
| はじめるまえに:このチュートリアル記事は、セットアップ済みのKubernetes環境が用意されていることを前提としています。以降のアクティビティを実行できるように、デモ用アプリケーションを入れたシングルノードのMinikube環境をセットアップする手順を解説したブログ記事もありますので、併せてご活用ください。 |
FilebeatでKubernetesのログを収集する
この記事は、Elastic CloudのElasticsearch Serviceを使う手順を解説します。しかし以下に記述するすべての手順は、セルフマネージドか、Elastic Cloud Enterprise(ECE)やElastic Cloud on Kubernetes(ECK)などのオーケストレーションシステムを使用しているかを問わず、自前のインフラにデプロイしたElasticクラスターでも動作します。また、このチュートリアルでご紹介するコードは、GitHubレポhttp://github.com/michaelhyatt/k8s-o11y-workshopにも掲載されています。
FilebeatをDaemonSetとしてデプロイする
Filebeatのインスタンスは、Kubernetesホスト1つにつき1つだけデプロイします。デプロイしたFilebeatは、the kubelet APIを経由してホストと通信し、稼働中のpodやメタデータの注釈のほか、ログファイルの場所などの情報を取得します。
このDaemonSetのデプロイ設定はファイル$HOME/k8s-o11y-workshop/filebeat/filebeat.ymlに定義されています。 Filebeatの設定を示すデプロイ記述子の部分を詳しく見てみましょう。
この部分は、可能なフィールドの総数をデフォルトの1,000から5,000に増やします。Kubernetesのデプロイは、多数のラベルと注釈を取り込むことができ、スキーマフィールドがデフォルトの1,000を超えることがあります。
setup.template.settings:
index.mapping.total_fields.limit:5000
Filebeatに自動検知メカニズムを設定して、Kubernetes自動検知を使用し、注釈上で動作するヒント主導の自動検知に依拠するよう指示することができます。
filebeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
続くセッションで、このFilebeatインスタンスが捕捉したすべてのログに適用されるプロセスチェーンを定義します。Filebeatインスタンスははじめに、イベントをDockerやKubernetes、ホスト、クラウドプロバイダーからくるメタデータでエンリッチします。次にdrop_eventというセクションがあり、ここで内容や、先行するプロセッサーが作成したメタデータフィールドによってメッセージがフィルターアウトされます。この仕様は、ログに影響を与えるノイズの多いイベントタイプに便利です。条件一致を構築するための、andとorのロジックの使い方に注目してください。
processors:
- add_cloud_metadata:
- add_host_metadata:
- add_docker_metadata:
- add_kubernetes_metadata:
- drop_event:
when:
or:
- contains:
message:"OpenAPI AggregationController:Processing item k8s_internal_local_delegation_chain"
- and:
- equals:
kubernetes.container.name: "metricbeat"
- contains:
message:"INFO"
- contains:
message:"Non-zero metrics in the last"
- and:
- equals:
kubernetes.container.name: "packetbeat"
- contains:
message:"INFO"
- contains:
message:"Non-zero metrics in the last"
- contains:
message: "get services heapster"
- contains:
kubernetes.container.name: "kube-addon-manager"
- contains:
kubernetes.container.name: "dashboard-metrics-scraper"
Filebeatモジュールと注釈を使用した自動検知
上のセクションで、自動検知がstdout/stderrに適用される適切なモジュールを取得し、モジュール固有の形式にパースする仕組みを確認しました。自動検知については、Filebeatドキュメントに詳しい説明があります。
ここからは、Kubernetesヒントベースの自動検知を動作させるために、サンプルアプリケーションの様々なコンポーネントを設定する方法について説明します。
NGINXの設定例
以下は、$HOME/k8s-o11y-workshop/nginx/nginx.ymlからのスニペットです。このファイルは、このpodからくるログをNGINXログとして扱うようFilebeatに指示します。NGINXログで、stdoutはアクセスログ、stderrはエラーログを示します。
annotations:
co.elastic.logs/module: nginx
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
複数行にわたるアプリケーションログの処理
ヒントベースの自動検知の別の例として、petclinicの複数行のログエントリを単一のログイベントとして扱うようFilebeatを設定するやり方があります。この設定はたとえば、単一のイベントを示すJavaスタックトレースなのに、行末で区切られたため、デフォルトに従って1行ごとに単一のイベントとして扱われてしまう場合に便利です。
以下は$HOME/k8s-o11y-workshop/petclinic/petclinic.ymlからのスニペットです。この記述は、ヒントベースの自動検知を使用するFilebeatに対して、複数行にわたるイベントの処理設定方法を指定しています。
annotations:
co.elastic.logs/multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
co.elastic.logs/multiline.negate: "true"
co.elastic.logs/multiline.match: "after"
複数行にわたるイベントの処理については、Filebeatドキュメントに詳しい説明があります。
Elastic StackでKubernetesログを分析する
これでログのElasticsearchへのインジェストが完了しました。次に、ログの活用方法を考えましょう。
KibanaのLogsアプリを使う
KibanaのLogsアプリを使うと、Elastic Stackに収集したすべてのログの検索、絞り込み、tailを実行できます。さまざまなサーバーにSSHで接続するのではなく、ディレクトリにcdを適用して個別のファイルをtailすることで、Logsアプリという単一のツールですべてのログを扱う仕組みになっています。
- キーワードやプレーンなテキスト検索を使用して、ログのフィルタリング機能を活用する。
- サイドメニューのタイムピッカーやタイムラインビューを使って時系列内を自由に移動する。
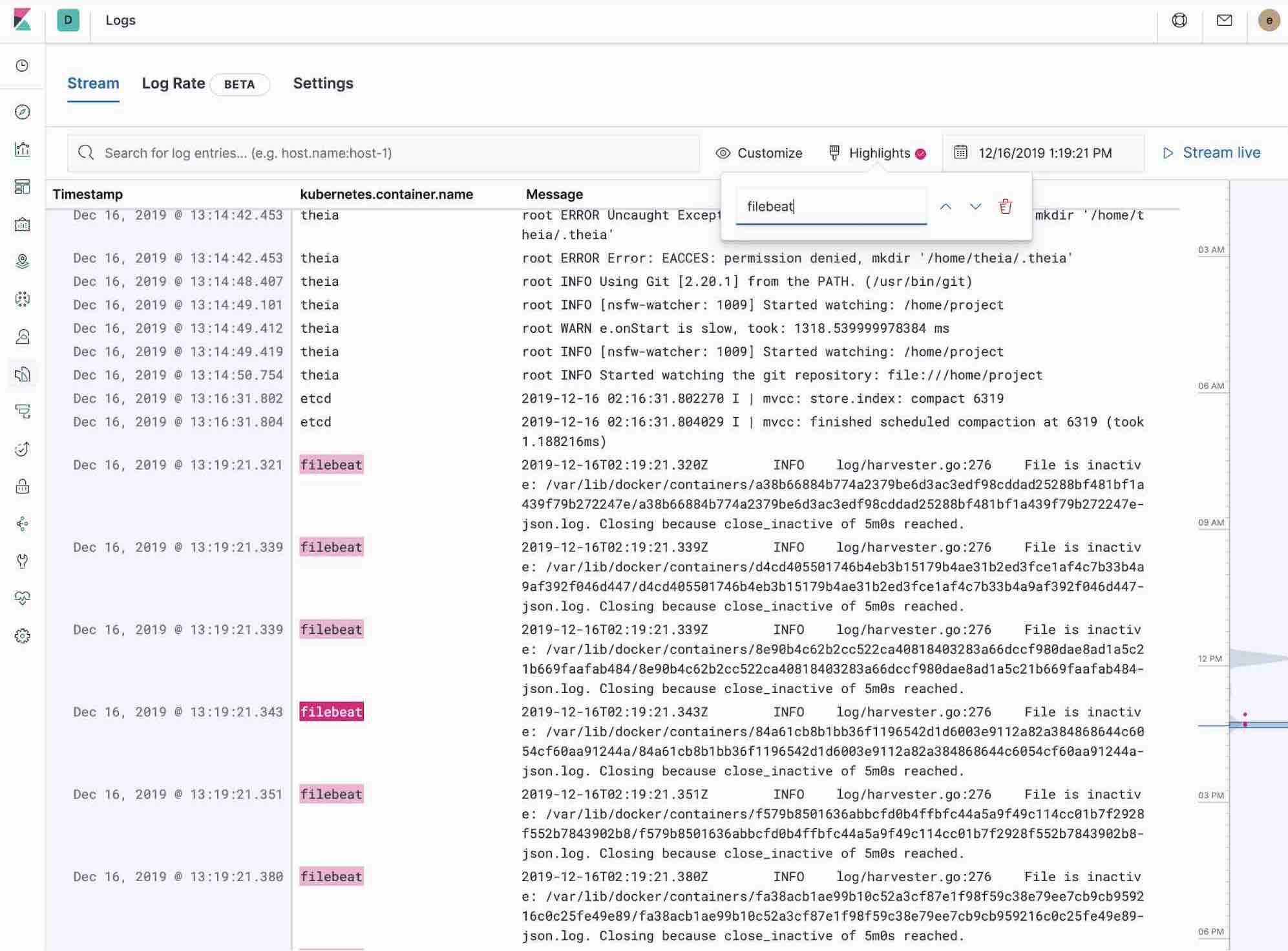
- tail -fのスタイルで刻々とアップデートされるログを表示させるには、[Streaming](ストリーミング)ボタンをクリックし、ハイライト機能で探している重要情報を目立たせる。
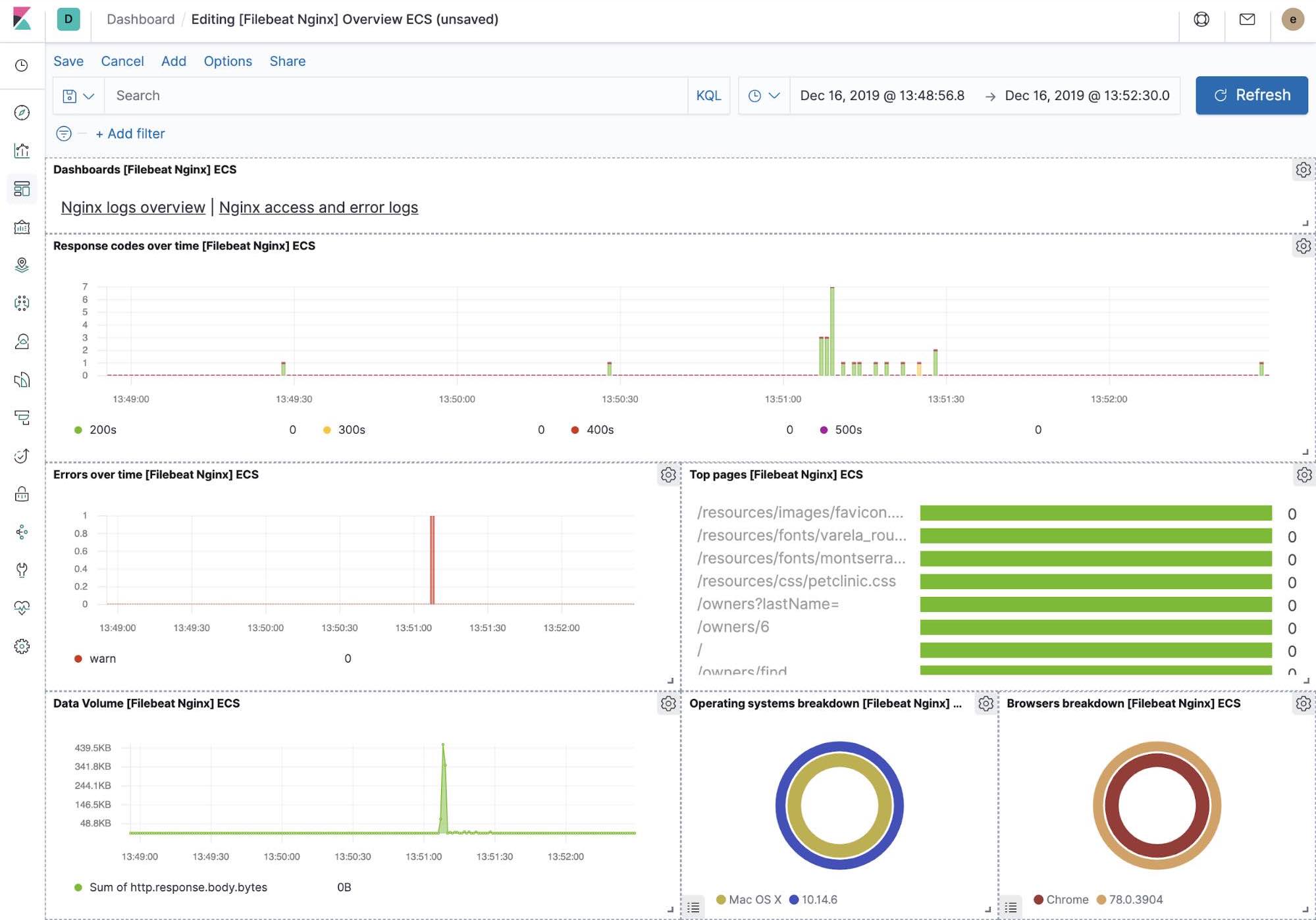
すぐに使えるKibanaの可視化機能
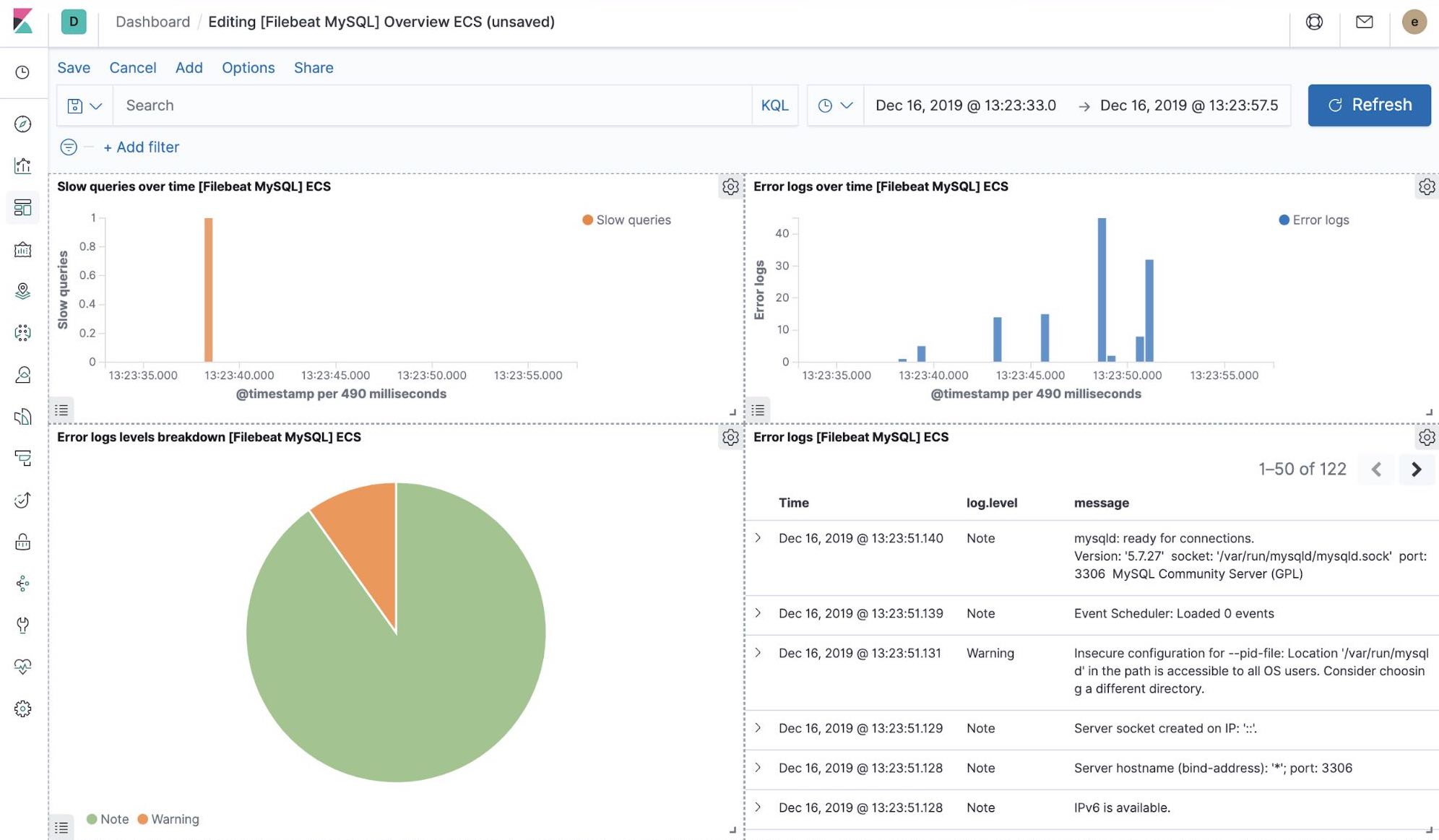
filebeat-setupのジョブを実行すると、一連のすぐに使えるKibanaダッシュボードの事前作成も行われます。今回サンプルとして設定したpetclinicアプリケーションのデプロイが完了すると、特別な設定をしなくてもFilebeatダッシュボードを操作してMySQLやNGINXを表示できます。また、設定したFilebeatモジュールがログだけでなく、ログを構成するメトリックも捕捉していることを確認できます。このような可視化を有効化するには、サンプルアプリケーションで稼働するMySQLやNGINXのコンポーネントが必要です。
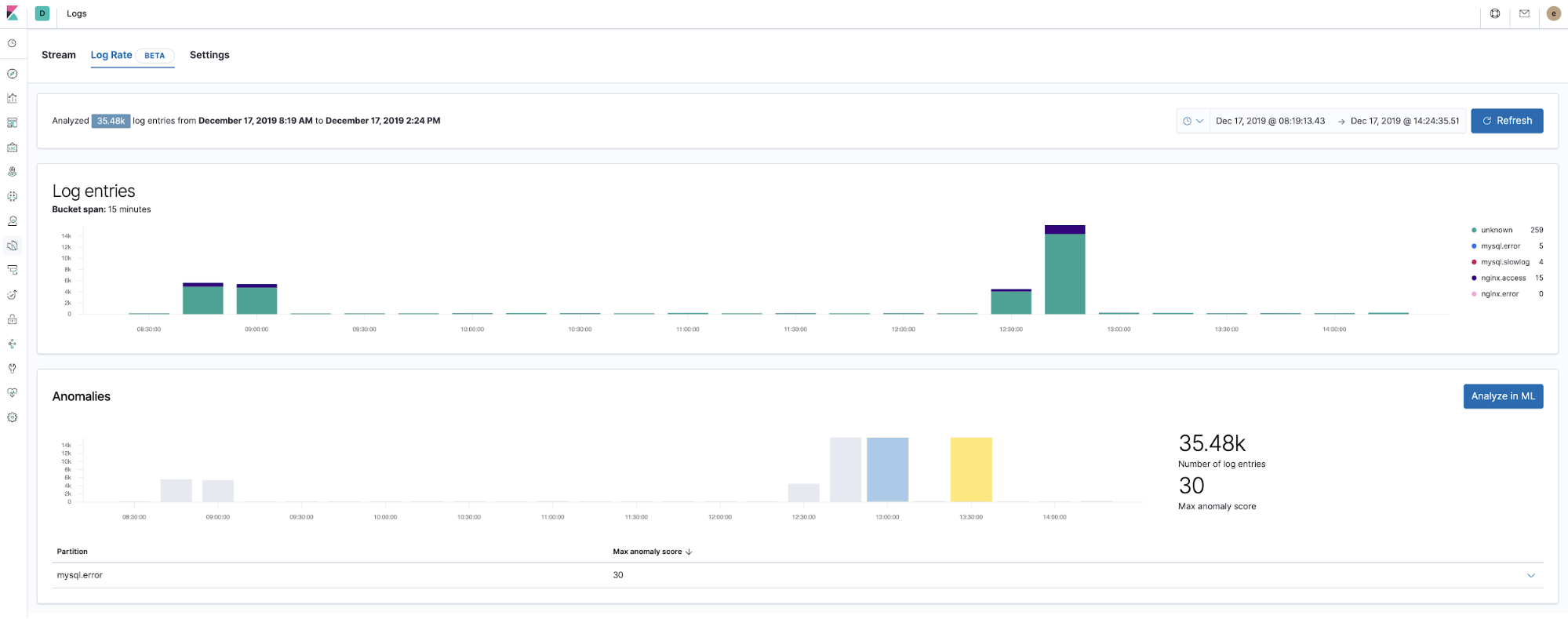
機械学習とロギング異常検知
バージョン7.5より、Elastic Stackはアプリケーションコンポーネントのログレート異常を検知できるようになっています。この機能を使って、以下のような事象を検知できます。
- 新しいアプリケーションまたはログソースが追加された
- 広告展開(あるいは攻撃)によって、ロギングアクティビティが急に活発化した
- ログのシッピングが突然停止しており、原因はエージェントまたはインジェストパイプラインの不具合である可能性がある
このログレート異常検知機能はLogsアプリにも導入されており、オペレーターは上記のような疑問の答えを瞬時に把握することができます。この機能は、Logsアプリで1回クリックを実行するだけで有効化することができます。
ログエントリ分類で未知の異常を検知する
ログ関連で役立つ別の機械学習の適用パターンとして、以前は観測されていなかった新しいタイプのログエントリを検知するというものがあります。機械学習はタイムスタンプや数値など、ログエントリに含まれる数値や変数部分を高次で除去して抽象化し、ログエントリにおいて固定された部分のカテゴリ化を実行します。次に、ログエントリをグループ化してバケットに入れ、以前は見られなかったログエントリが現れたことで“異常”と判断できる新規のバケットにフラグを付ける処理を続けてゆきます。

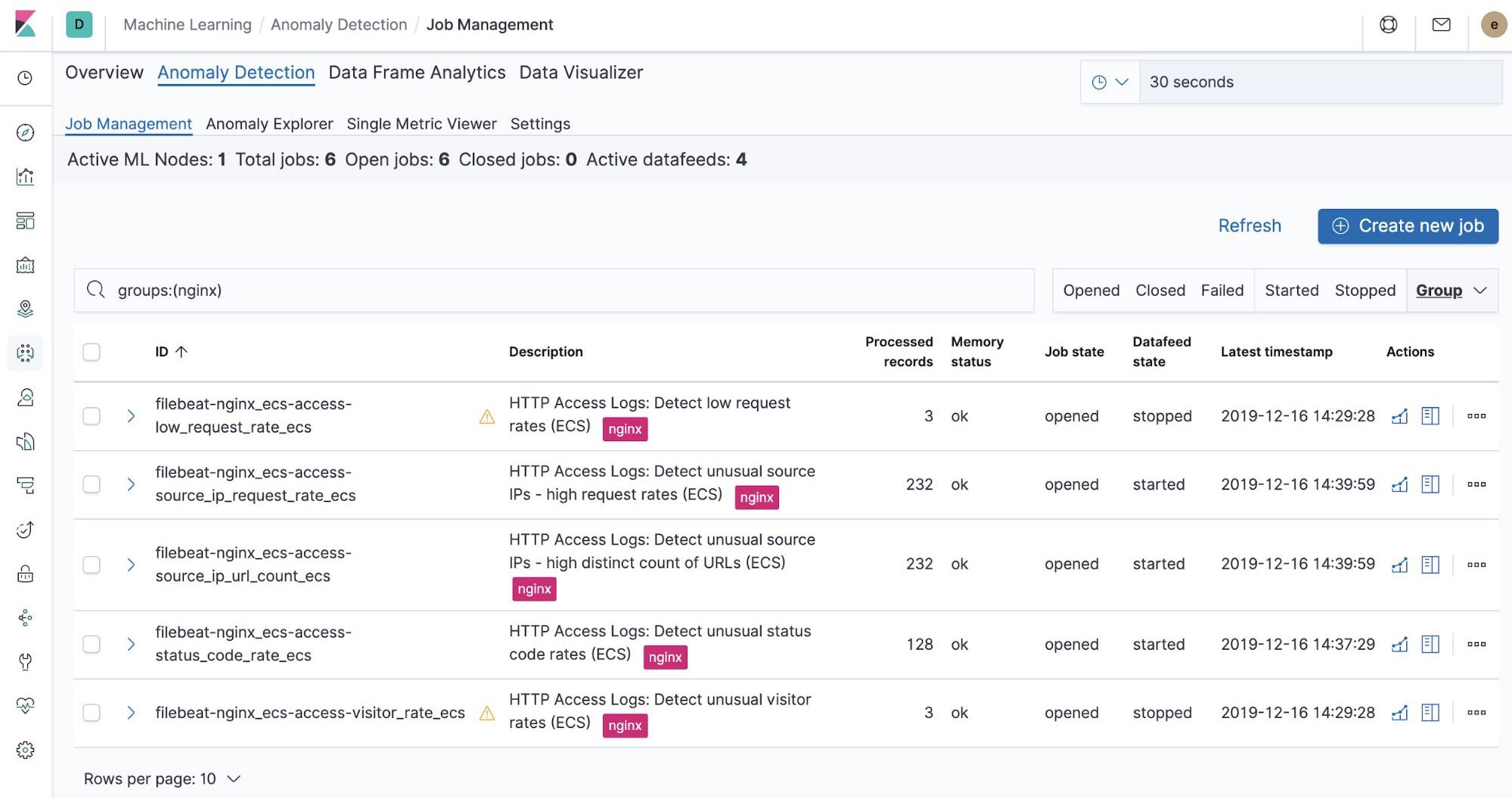
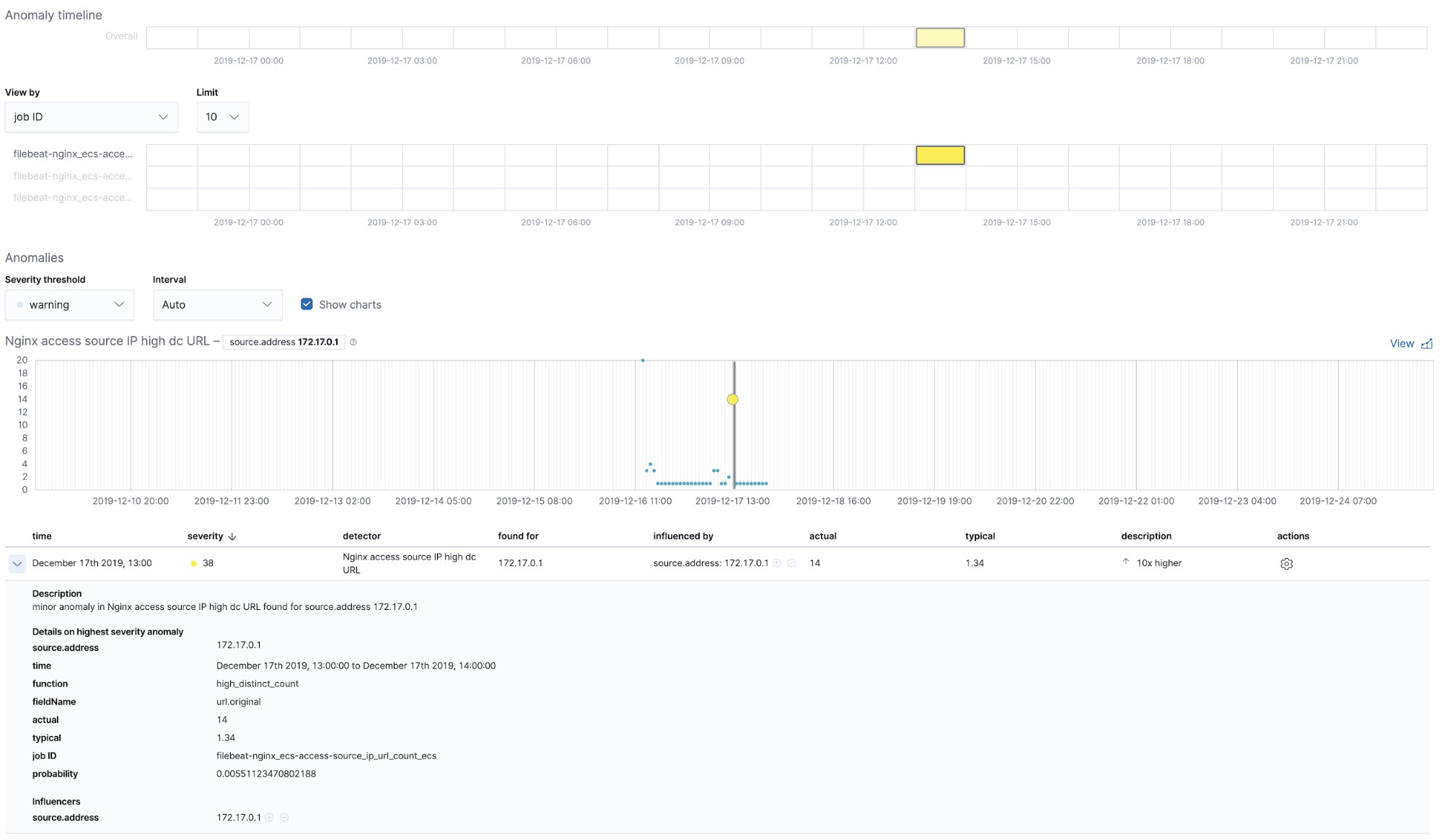
NGINX向けの、設定不要の機械学習ジョブ
filebeat-setupジョブを実行すると、すぐに使える機械学習ジョブの事前作成も行われます。機械学習ジョブを有効化している場合、Filebeatから取り込まれたNGINX stdoutおよびstderrデータ内の異常検知を開始できます。
まとめ
FilebeatとFilebeatモジュールを使ってElastic StackにKubernetesログをインジェストする方法をご紹介しました。Elastic CloudのElasticsearch Service無料トライアルに登録したり、自前の環境にElastic Stackをダウンロードすれば、今日からお使いのシステムやインフラの監視をはじめることができます。セットアップを完了したら、Elastic Uptimeでホストのアベイラビリティを監視したり、Elastic APMを使ってホストで稼働するアプリケーションのインストルメンテーションを行うことができます。新たにメトリックのクラスターを完全統合して、包括的なオブザーバビリティを備えたシステムの確立を目指してみましょう。お困りのことや、ご質問がおありの場合はディスカッションフォーラムをご活用ください。活発なコミュニティが待っています。
次回のテーマは、パフォーマンスとヘルスに関するメトリックの収集です。