生成AIエクスペリエンスを加速
スピードとスケールのために構築された、検索のパワーを活かすAIと開発者ツール


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
大規模言語モデル(LLM)と生成AIの進歩は日々続いており、開発者をその変化の最前線に立たせるとともに、変化の方向性と可能性に影響を与えています。このブログでは、Elasticの検索を利用するユーザーが、Elasticのベクトルデータベースと、検索を活かすAIや開発者ツール用のオープンプラットフォームをどのように使用して、生成AIエクスペリエンスを加速および拡張し、成長のための新たな道を開いているかについてご紹介します。
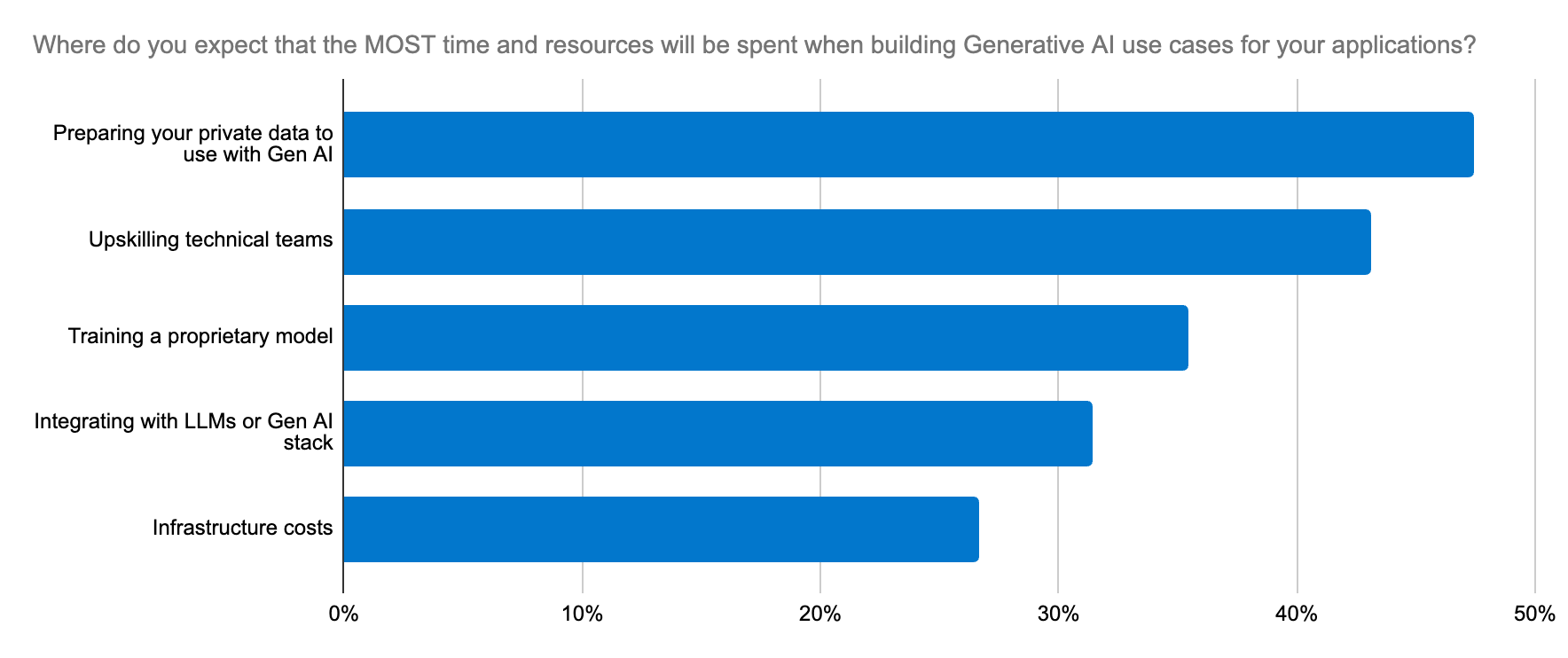
Dimensional Researchが最近実施し、Elasticが支援した開発者調査の結果によると、開発者の87%がすでに生成AIを活用していました。ユースケースは、データ分析、カスタマーサポート、社内コンテンツ検索チャットボットなどです。しかし、これらのユースケースを正常に本番環境に実装できた開発者は11%にとどまりました。
これには、いくつかの要因があります。
モデルのデプロイと管理:適切なモデルを選択するには、実験とスピーディな反復が必要です。生成AIアプリケーションのためのLLMのデプロイは、多くの組織にとって複雑で時間のかかることであり、技術の習得も容易ではありません。
法令順守に関する懸念:これらの懸念は、機密データを扱う際に特に重要であり、モデル導入の際の障壁となる可能性があります。
- スケーリング:LLMにコンテクストを理解させて正確な出力を生成させるには、ドメイン固有のデータが不可欠です。スケーリングされたデータの検索に対応するには、ベクトル埋め込みを生成するワークロードに対しても同様のスケーラブルなサポートが必要となるため、メモリーと計算リソースの需要が急速に増加します。データセットの量が膨大だと、コンテクストウィンドウが大きくなるのでLLMに渡す際にコストがかかるようになり、コンテクスト自体は豊富でも関連性が高まるとは限らなくなります。ここで堅牢なツールプラットフォームがあれば、コンテクストを形成し、トレードオフ関係にある関連性と規模のバランスを取り、将来を見据えたアーキテクチャーによるイノベーションを実現させることができます。
開発者は、生成AIアプリケーションと、実装およびLLM選択プロセスを簡素化するプラットフォームを構築するための、信頼性が高く、スケーラブルで、コスト効率に優れた方法を求めています。
Elasticは迅速なイノベーションにより、開発者が抱くこのような懸念に対するソリューションを一貫して提供し、生成AIのユースケースをサポートしています。
生成AIエクスペリエンスを迅速かつ大規模に展開
Elasticsearchは市場で最もダウンロードされているベクトルデータベースであり、ElasticとLuceneコミュニティとの深い協力関係により、検索イノベーションをより迅速に設計してお客様に提供しています。現在、ElasticsearchはLucene 9.10を使用して、お客様が目的とする速度とスケールを生成AIで達成できるように支援しています。9.10の速度面では、特にマルチセグメントインデックスでのクエリのレイテンシーが大幅に改善されました。これはまだ始まりに過ぎず、速度は今度さらに向上します。
Elasticをベクトルデータベースとして使用しているのは、柔軟性、拡張性、信頼性に優れているためです。機械学習や生成AIをサポートする新機能が迅速に提供されるので、当社にとっての利便性は継続的に高まっています。
Stack Overflowのプラットフォームエンジニアリング担当エンジニアリングマネージャー、ピーター・オコナー氏
RAGワークロードを迅速に実装して拡張するなら、一般提供が開始されたElastic Learned Sparse EncodeR(ELSER)が良いでしょう。デプロイが簡単で、最適化されており、セマンティック検索に適したレイトインタラクション型の機械学習(ML)モデルです。ELSERは、微調整を必要とせずに、コンテクスト上の関連性のある検索結果を提供しており、信頼できる開発者向けソリューションも搭載しているため、モデルの選択、デプロイ、管理にかかる時間を節約し、複雑さを軽減することができます。
ELSERは、速度を犠牲にすることなく検索の関連性を高めます。ConsensusがElasticを利用した学術研究プラットフォームをアップグレードした際は、ELSERを使用することで検索のレイテンシーを75%軽減し精度も向上させました。
ELSERをE5埋め込みモデルと組み合わせると、多言語ベクトル検索も簡単に適用できるようになります。E5のアーティファクトは最適化されており、Elasticsearch環境向けに特別に調整されています。多言語検索は、多言語モデルをアップロードするか、Elasticの推論APIと統合しても利用できます(例:Cohereの多言語モデルの埋め込み)。このような進歩によって、検索拡張生成(RAG)の利用はさらに促進され、Elasticは貴社が構築する革新的な生成AIエクスペリエンスの拡張のための重要なインフラストラクチャーとなってゆくでしょう。
Elasticは、これらのエクスペリエンスの効率的な拡張も重視しています。8.12リリースで登場したスカラー量子化はベクトルストレージのゲームチェンジャーです。ベクトルを大規模に展開すると、検索が遅くなることがあります。しかし、この圧縮技術を利用すればメモリ要件が4倍も削減されるため、より多くのベクトルをまとめるのに役立ち、スケーリングしても再現率にほとんど影響がありません。精度を犠牲にすることなく、RAGで使用されるベクトル検索の速度が2倍になります。その結果、インフラストラクチャーのコストを大幅に削減できる、より効率的かつ高速なシステムが実現します。
Elasticの精度と速度にGoogle Cloudのパワーが組み合わさって、安定性とコスト効率性の両方に優れた検索プラットフォームが構築され、ユーザーにとって快適なエクスペリエンスが実現しました。
Cisco Systemsのエンタープライズサーチ兼クラウドアーキテクト担当プリンシパル、スジス・ジョセフ氏
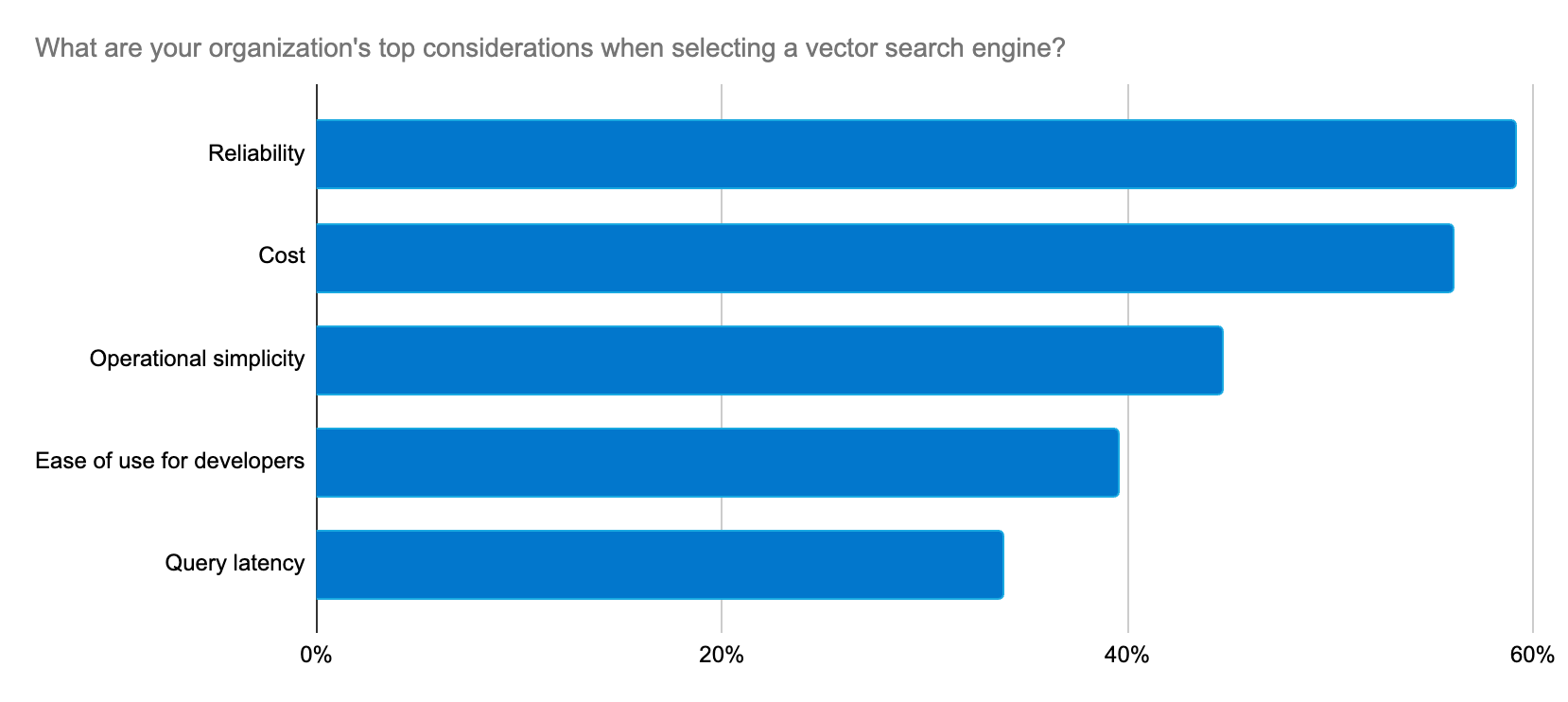
RAG向けの最も関連性の高い検索エンジン
関連性は、優れた生成AIエクスペリエンスに到達するための鍵です。セマンティック検索にELSERを使用し、テキスト検索にBM25を使用することは、LLMのコンテクストとして関連ドキュメントを取得する際の良き第一歩となります。コンテクストウィンドウが大きい場合は、Elastic Stackに組み込まれたリランキングツールを使用してさらに絞り込むことができます。リランカーはパワフルなMLモデルを適用して検索結果を調整し、ユーザーの好みやシグナルに基づいて最も関連性の高い結果を上位に表示します。Learning to Rank(LTR)機能も、Elasticsearchプラットフォームに対してネイティブになりました。これは、最も関連性の高い結果をコンテクストとしてLLMにフィードする必要のあるRAGユースケースで非常に役立ちます。
実装は、推論APIやCohereなどのサードパーティプロバイダーによってさらに簡素化されています。最新のリリースにアップグレードして、リランカーが関連性に与える影響をお試しください。
これらのアプローチは、検索精度の向上(Consensusの場合は30%)だけでなく、検索結果が得られるまでの時間の短縮、RAGとの関連性の向上、MLワークストリームの効率的な管理にも役立ちます。
モデルの選択と交換を簡素化
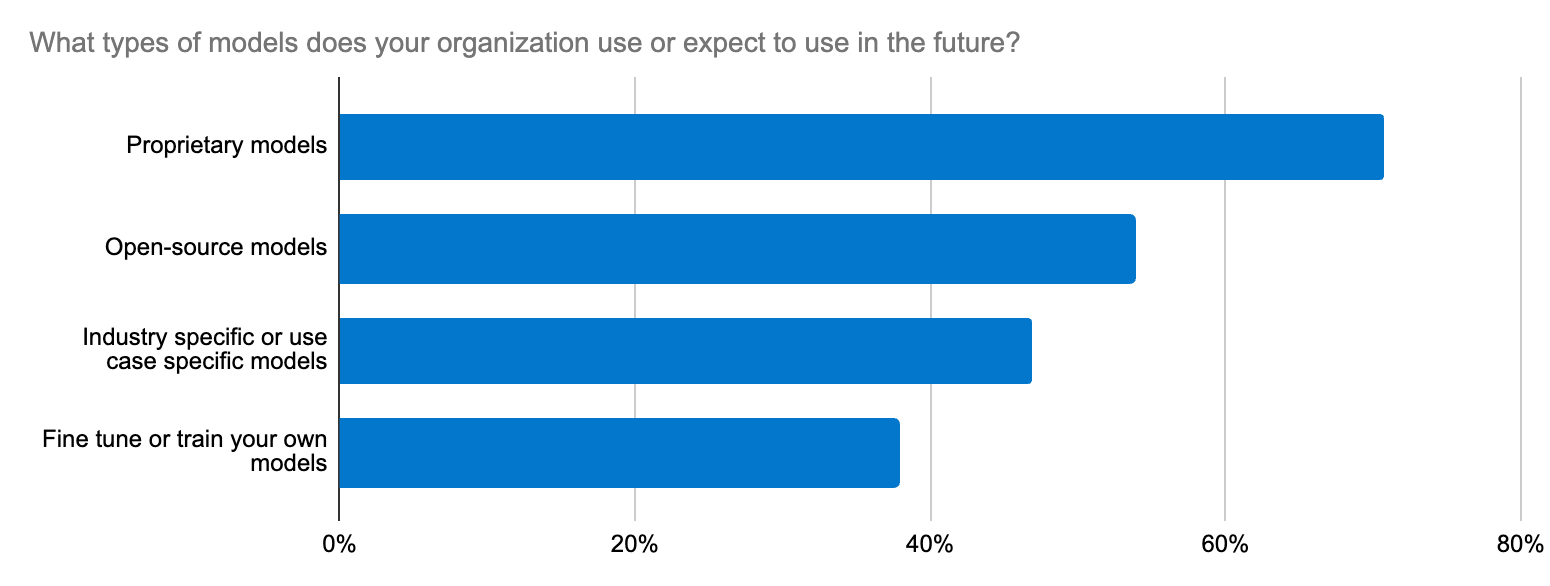
モデルの選択は、ときに気の遠くなるような作業になることがあります。事実、Elasticが実施した開発者調査によると、生成AIに関して組織全体で苦労する業務トップ5のひとつがLLMとの統合作業であることが判明しました。ここでのジレンマは、ユースケースに応じてオープンソースLLMとクローズドソースLLMのどちらを選択するかというだけではなく、精度、データセキュリティ、ドメイン固有性、変化するLLMエコシステムへの迅速な適応などにまで及びます。開発者には、新しいモデルを試したり入れ替えたりするための、わかりやすいワークフローが必要です。
Elasticは、オープンプラットフォーム、ベクトルデータベース、検索エンジンという方法で、変換器モデルと基礎的モデルをサポートしています。Elastic Learned Sparse EncodeR(ELSER)は、RAGの実装を加速するための信頼できる出発点となります。
また、Elasticの推論APIを使用して、コードとマルチクラウド推論の管理を開発者向けに合理化できます。RAGワークロードにELSERを使用する場合でも、OpenAI(開発者間で最も評価と使用が進んでいる)、Hugging Face、Cohereなどの埋め込みを使用する場合でも、APIコールは1つで済むため、クリーンなコードでハイブリッド推論デプロイを管理できます。推論APIがあると幅広いモデルに簡単にアクセスできるようになるため、適切なモデルを探しやすくなります。ドメイン固有の自然言語処理(NLP)と生成AIモデルとの簡単な統合により、モデル管理が簡素化され、AIを利用したイノベーションに集中的に時間を割けるようになります。
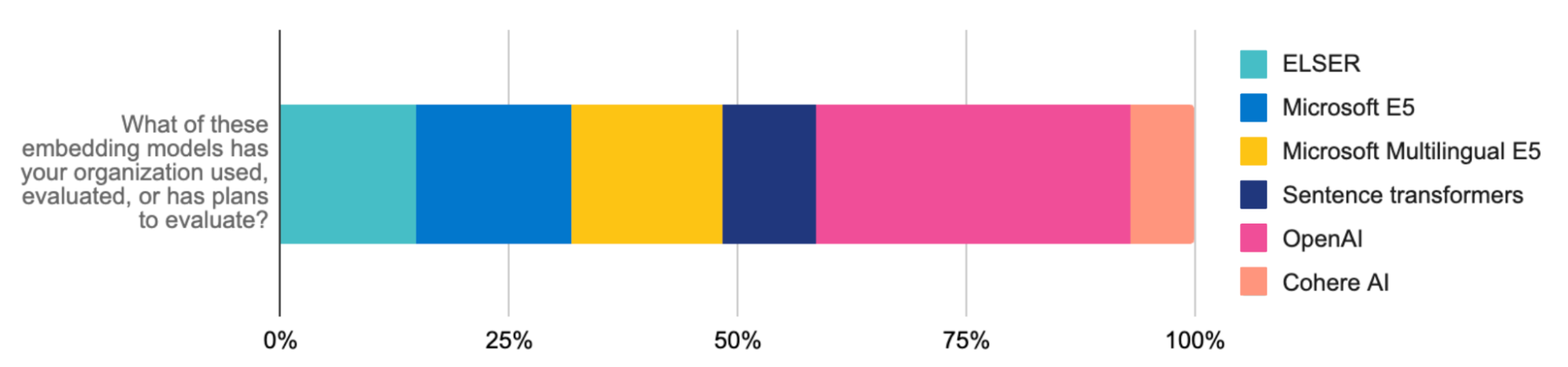
補強し合う関係:統合による素晴らしいエクスペリエンス
開発者は、パブリックおよびプライベートのHugging Faceモデルを含むさまざまな変換器モデルをホストすることもできるようになります。Elasticsearchはエコシステム全体で使用できる汎用的なベクトルデータベースとして機能しますが、LangChainやLlamaIndexなどのツールの方が好みであれば、Elasticの統合とLangChain Templatesを利用して、本番環境で使用可能な生成AIアプリを迅速に立ち上げることができます。Elasticのオープンプラットフォームなら、生成AIプロジェクトを迅速に適応させ、実験し、利用を促進することができます。さらに、最近Elasticは、会話型コパイロットの構築用の新しいサービスであるOn Your Dataにサードパーティベクトルデータベースとして追加されました。また、もうひとつのユースケースの好例として、ElasticはCohereチームと連携し、Elasticを良質なCohere埋め込み向けベクトルデータベースとするために取り組んでいます。
生成AIがあらゆる組織を再形成する今、Elasticがその変革をサポートします。開発者にとって、生成AIの実装を成功させるための鍵は、継続的な学習(Elastic Search Labsをぜひご確認ください)と、変化を続けるAI環境への迅速な適応です。
試してみる
- ご紹介した機能について詳しくは、Elastic Searchリリースノートをご覧ください。
- Elastic Cloudをご利用中のお客様はElastic Cloudコンソールから直接、本記事でご紹介した機能にアクセスできます。Elastic Cloudをまだお使いでない方は、無料トライアルでお試しください。
- AI検索アプリを構築するための開発者向けツールスイート、Elasticsearch Relevance Engineをお試しください。
本記事に記述されているあらゆる機能ないし性能のリリースおよびタイミングは、Elasticの単独裁量に委ねられます。現時点で提供されていないあらゆる機能ないし性能は、すみやかに提供されない可能性、または一切の提供が行われない可能性があります。
このブログ記事では、それぞれのオーナーが所有・運用するサードパーティの生成AIツールを使用したり、参照したりしている可能性があります。Elasticはこれらのサードパーティのツールについていかなる権限も持たず、これらのコンテンツ、運用、使用、またはこれらのツールの使用により生じた損失や損害について、一切の責任も義務も負いません。個人情報または秘密/機密情報についてAIツールを使用する場合は、十分に注意してください。提供したあらゆるデータはAIの訓練やその他の目的に使用される可能性があります。提供した情報の安全や機密性が確保される保証はありません。生成AIツールを使用する前に、プライバシー取り扱い方針や利用条件を十分に理解しておく必要があります。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine、および関連するマークは、米国およびその他の国におけるElasticsearch N.V.の商標、ロゴ、または登録商標です。他のすべての会社名および製品名は、各所有者の商標、ロゴ、登録商標である場合があります。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷