Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running! You can start a free cloud trial or try Elastic on your local machine now.
This blog explores multi-graph vector search in Lucene and how sharing information among segment searches in multi-graph vector search allowed us to achieve significant search speedups.
The previous state of multi-graph vector search in Lucene
As we have described before Lucene's and hence Elasticsearch's approximate kNN search is based on searching an HNSW graph for each index segment and combining results from all segments to find the global k nearest neighbors. When it was first introduced a multi-graph search was done sequentially in a single thread, searching one segment after another. This comes with some performance penalty because searching a single graph is sublinear in its size. In Elasticsearch 8.10 we parallelized vector search, allocating up to a thread per segment in kNN vector searches, if there are sufficient available threads in the threadpool. Thanks to this change, we saw query latency drop to half its previous value in our nightly benchmark.
Even though we were searching segment graphs in parallel, they were still independent searches, each collecting its own top k results unaware of progress made by other segment searches. We knew from our experience with the lexical search that we could achieve significant search speedups by exchanging information about best results collected so far among segment searches and we thought we could apply the same sort of idea for vector search.
Speeding up multi-graph vector search by sharing information between segment searches
When graph based indexes such as HNSW search for nearest neighbors to a query vector one can think of their strategy as a combination of exploration and exploitation. In the case of HNSW this is managed by gathering a larger top-n match set than the top-k which it will eventually return. The search traverses every edge whose end vector is competitive with the worst match found so far in the expanded set. This means it explores parts of the graph which it already knows are not competitive and will never be returned. However, it also allows the search to escape local minima and ultimately achieve better recall. By contrast a pure exploitation approach simply seeks to decrease the distance to the kth best match at every iteration and will only traverse edges whose end vectors will be added to the current top-k set.
So the size of the expanded match set is a hyperparameter which allows one to trade run time for recall by increasing or decreasing exploration in the proximity graph.
As we discussed already, Lucene builds multiple graphs for different partitions of the data. Furthermore, at large scale, data must be partitioned and separate graphs built if one wants to scale retrieval horizontally over several machines. Therefore, a generally interesting question is "how should one adapt this strategy in the case that several graphs are being searched simultaneously for nearest neighbors?"
Recall is significantly higher when one searches graphs independently and combines the top-k sets from each. This makes sense through the lens of exploration vs exploitation: the multi-graph search is exploring many more vectors and so is much less likely to get trapped in local minima for the similarity function. However, it pays a cost to do this in increased run time. Ideally, we would like recall to be more independent of the sharding strategy and search to be faster.
There are two factors which impact the efficiency of search on multiple graphs vs a single graph: the edges which are present in the single graph and having multiple independent top-n sets. In general, unless the vectors are partitioned into disjoint regions the neighbors of a vector in each partition graph will only comprise a subset of the true nearest neighbors in the single graph. This means one pays a cost in exploring non-competitive neighbors when searching multiple graphs. Since graphs are built independently, one necessarily has to pay a “structural” cost from having several graphs. However, as we shall see we can mitigate the second cost by intelligently sharing state between searches.
Given a shared global top-n set it is natural to ask how we should search portions of graphs that are uncompetitive, specifically, edges whose end vertices that are further than the nth worst global match. If we were searching a single graph these edges would not be traversed. However, we have to bear in mind that the different searches have different entry points and progress at different rates, so if we apply the same condition to multi-graph search it is possible that the search will stop altogether before we visit its closest neighbors to the query. We illustrate this in the figure below.

Figure 1 Two graph fragments showing a snapshot of a simultaneous search gathering the top-2 set. In this case if we were to prune edges whose unvisited end vertices are not globally competitive we would never traverse the red dashed edge and fail to find the best matches which are all in Graph 2.
To avoid this issue we devised a simple approach that effectively switches between different parameterizations of each local search based on whether it is globally competitive or not. To achieve this, as well as the global queue which is synchronized periodically, we maintain two local queues of the distances to the closest vectors to the query found for the local graph. One has size n and the other has size . Here, controls the greediness of non-competitive search and is some number less than 1. In effect, is a free parameter we can use to control recall vs the speed up.
As the search progresses we check two conditions when deciding whether to traverse an edge: i) would we traverse the edge if we were searching the graph alone, ii) is the end vertex globally competitive or is it locally competitive with the "greedy" best match set. Formally, if we denote the query vector , the end vector of the candidate edge , the local best match , the local best match and the global best match then this amounts to adding to the search set if
Here, denotes the index distance metric. Note that this strategy ensures we always continue searching each graph to any local minimum and depending on the choice of we still escape some local minima.
Modulo some details around synchronization, initialization and so on, this describes the change to the search. As we show this simple approach yields very significant improvements in search latency together with recall which is closer, but still better, than single graph search.
Impact on performance
Our nightly benchmarks showed up to 60% faster vector search queries that run concurrent with indexing (average query latencies dropped from 54 ms to 32 ms).
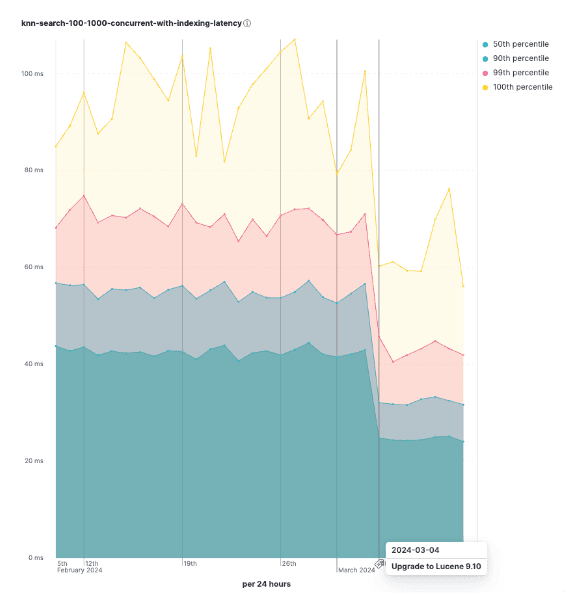
Figure 2 Query latencies that run concurrently with indexing dropped significantly after upgrading to Lucene 9.10, which contains the new changes.
On queries that run outside of indexing we observed modest speedups, mostly because the dataset is not that big, containing 2 million vectors of 96 dims across 2 shards (Figure 3). But still for those benchmarks, we could see a significant decrease in the number of visited vertices in the graph and hence the number of vector operations (Figure 4).
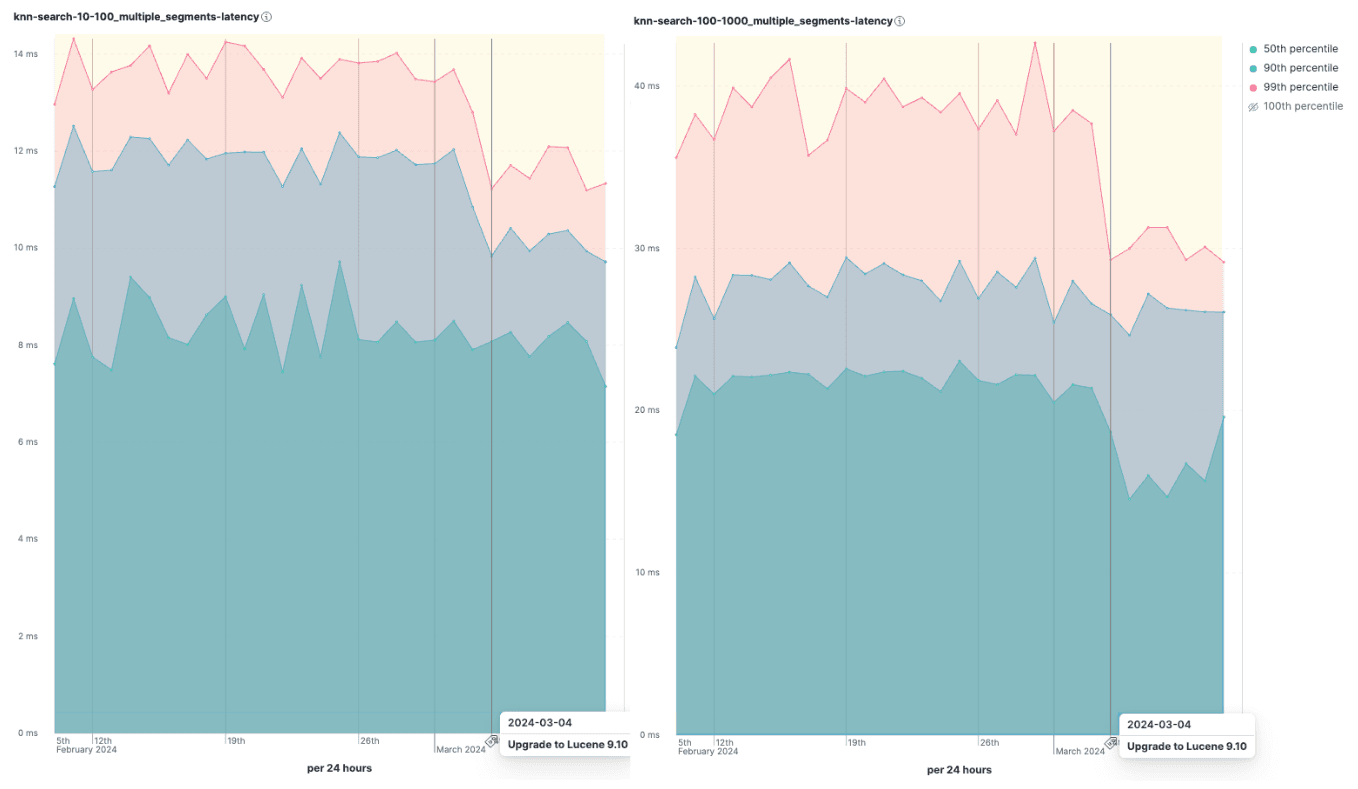
Figure 3 Whilst we see small drops in the latencies after the change for queries that run without concurrent indexing, particularly for retrieving the top-100 matches, the number of vector operations (Figure 4) is dramatically reduced.
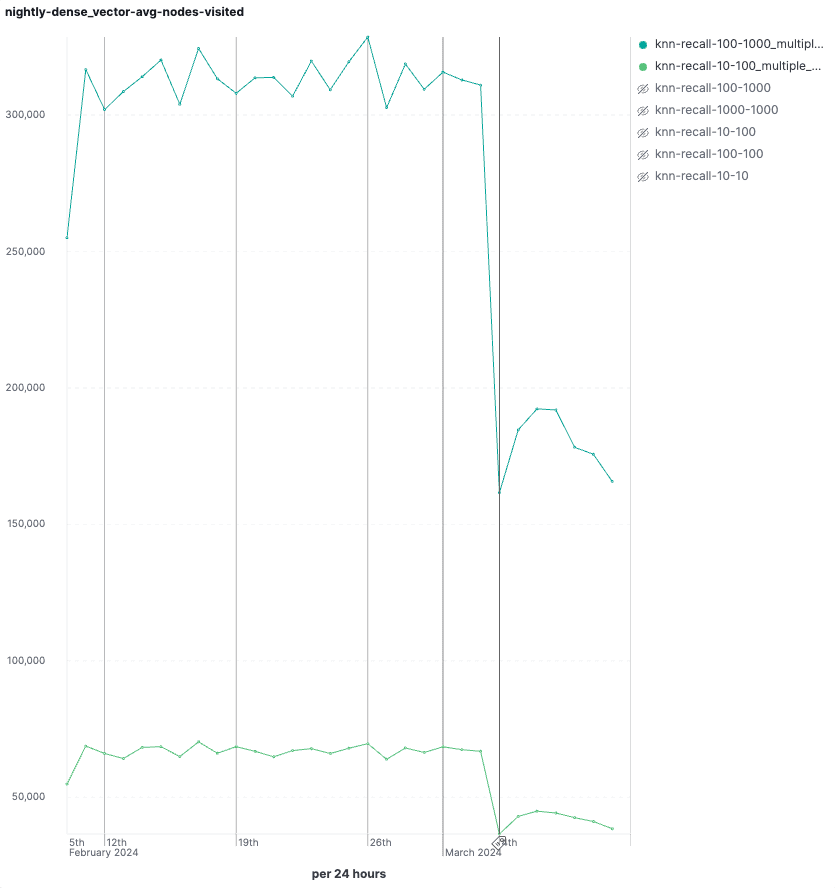
Figure 4 We see very significant decreases in the number of vector operations used to retrieve the top-10 and top-100 matches.
The speedups should be clearer for larger indexes with higher dimension vectors: in testing we typically saw between to , which is also consistent with the reduction in the number of vector comparisons we see above. For example, we show below the speedup in vector search operations on the Lucene nightly benchmarks. These use vectors of 768 dimensions. It is worth noting that in the Lucene benchmarks the vector search runs in a single thread sequentially processing one graph after another, but the change positively affects this case as well. This happens because the global top-n set collected after first graph searches sets up the threshold for subsequent graph searches and allows them to finish earlier if they don't contain competitive candidates.

Figure 5 The graph shows that with the change committed on Feb 7th, the number queries per second increased from 104 queries/sec to 219 queries/sec.
Impact on recall
The multi-graph search speedups come at the expense of slightly reduced recall. This happens because we may stop exploration of a graph that may still have good matches based on the global matches from other graphs. Two notes on the reduced recall: i) From our experimental results we saw that the recall is still higher than the recall of a single graph search, as if all segments were merged together into a single graph (Figure 6). ii) Our new approach achieves better performance for the same recall: it Pareto dominates our old multi-graph search strategy (Figure 7).
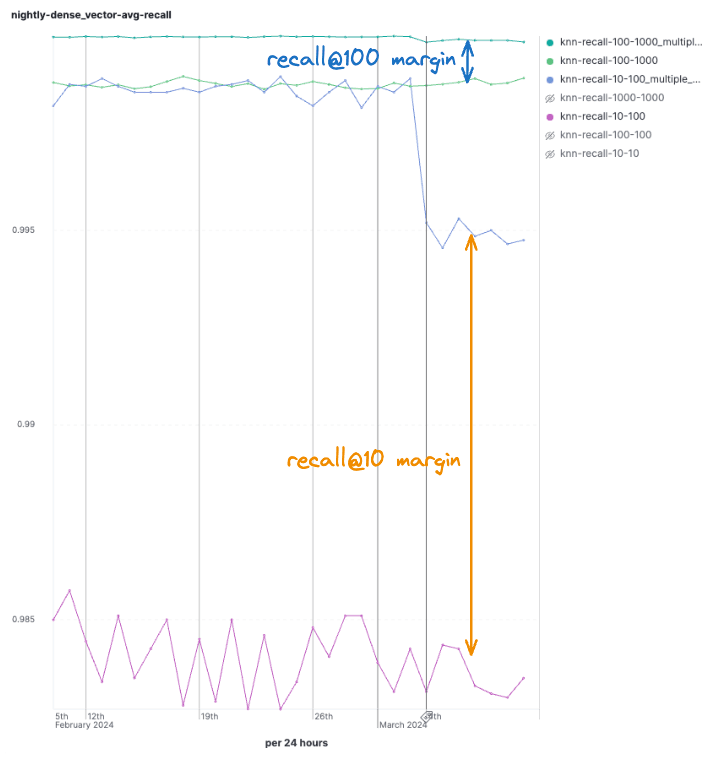
Figure 6 We can see the recall of kNN search on multiple segments slightly dropped for both top-10 and top-100 matches, but in both cases it is still higher than the recall of kNN search on a single merged segment.

Figure 7 The Queries Per Second is better in the candidate (with the current changes) than the baseline (old multi-graph search strategy) for the 10 million documents of the Cohere/wikipedia-22-12-en-embeddings dataset for each equivalent recall.
Conclusion
In this blog we showed how we achieved significant improvements in Lucene vector search performance while still achieving excellent recall by intelligently sharing information between the different graph searches. The improvement is a part of the Lucene 9.10 release and is a part of the Elasticsearch 8.13 release.
We're not done yet with improvements to our handling of multiple graphs in Lucene. As well as further improvements to search, we believe we've found a path to achieve dramatically faster merge times. So stay tuned!
Related Content

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.
The hash() Elasticsearch won't name and the 12 bytes that prove it's Murmur3
Elasticsearch's routing formula uses MurmurHash3, but the docs never say so. This post names the function, walks through the full shard calculation, and shows you how to reproduce it externally.
June 12, 2026
How DocValuesSkippers in Lucene 10 make range queries faster without doubling your storage
DocValuesSkippers add block-level skipping to Lucene DocValues fields, speeding up range queries on sorted or insert-ordered indexes with less than 0.1% storage overhead.

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

September 3, 2025
Vector search filtering: Keep it relevant
Performing vector search to find the most similar results to a query is not enough. Filtering is often needed to narrow down search results. This article explains how filtering works for vector search in Elasticsearch and Apache Lucene.