Want to get Elastic certified? Find out when the next Elasticsearch Engineer training is running! You can start a free cloud trial or try Elastic on your local machine now.
2023 just came to an end, and it's been another active year for Apache Lucene development. Let's take some time to review highlights from last year.
Community
In 2023, there have been:
- 5 minor releases (9.5, 9.6, 9.7, 9.8 and 9.9),
- 1 patch release (9.9.1),
- 1 new committer,
- 4 new PMC members,
- 620 commits from 97 unique contributors.
Vector search
The promise of truly semantic search for retrieval and retrieval augmented generation appeals a lot to users, large and small. So it's no surprise that vector search has been a major theme for Apache Lucene in 2023. More specifically, many interesting features and optimizations have been added across several releases:
- Support for int8 vectors. (Lucene 9.5)
- Faster merging of HNSW graphs. (Lucene 9.6)
- Faster indexing, merging and querying through support for vectorization (Lucene 9.7) and FMA (Lucene 9.9).
- Support for combining vector search with block joins. (Lucene 9.8)
- Support for auto int8 scalar quantization of vectors at index time. (Lucene 9.9)
Radix sort everywhere
Indexing is about organizing data in such a way that it can be efficiently accessed at search time, which involves a lot of sorting in practice. And when it comes to sorting, radix sort is king (when applicable!). Lucene had already been using radix sort in a few performance-sensitive places for a while, such as sorting the terms dictionary of segments. But usage of radix sort further increased in 2023, and it began being used to optimize:
- applying deletes,
- sorting postings when index sorting is enabled,
TermInSetQueryconstruction,- index reordering.
Faster query evaluation
We already covered some performance improvements for vector search, but keyword search saw major speedups as well in 2023. Check out this blog, which covers major speedups that occurred across the 9.7, 9.8 and 9.9 releases. These improvements apply both to traditional keyword search and sparse vector search, such as created by learned sparse retrieval models.
Closer integration with the Java virtual machine
As a Java library, Lucene relies a lot on the Java virtual machine (JVM), and once in a while new features get released that are especially interesting for Lucene. Two features in particular have been integrated in such a way that if you run on a modern enough version of the JVM, then they will be used automatically:
- The Panama vector API is used to speed up vector comparisons, such as computing the cosine similarity or the square distance between two vectors.
- The Panama
MemorySegmentAPI is an improved API to mmap files into memory.
It's hard to draw a line, but I'll stop here as I struggle to find common themes for other good changes I'm looking at that happened in 2023. :) Stay tuned for a great year 2024 in Apache Lucene land!
Related Content

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.
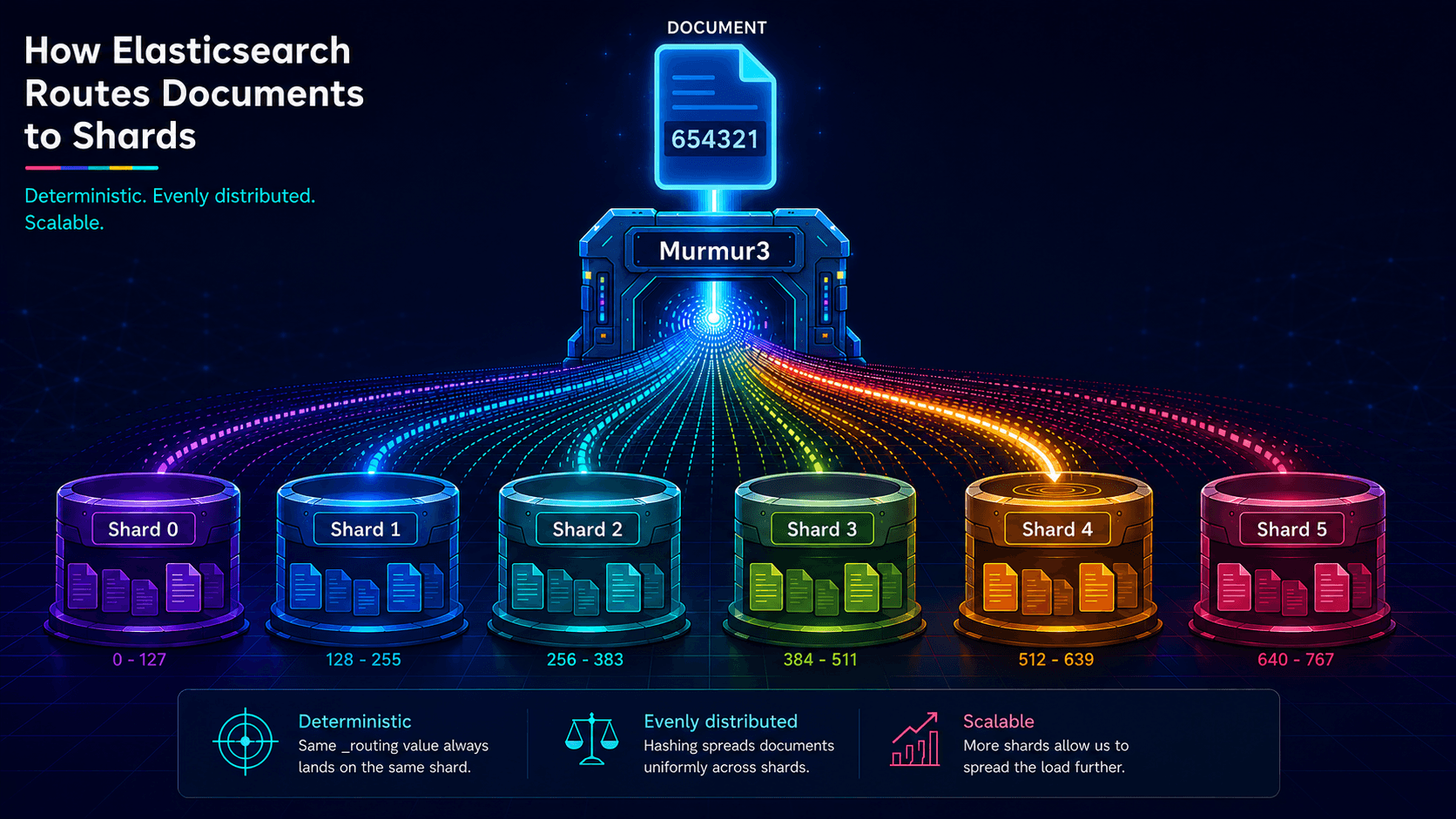
The hash() Elasticsearch won't name and the 12 bytes that prove it's Murmur3
Elasticsearch's routing formula uses MurmurHash3, but the docs never say so. This post names the function, walks through the full shard calculation, and shows you how to reproduce it externally.
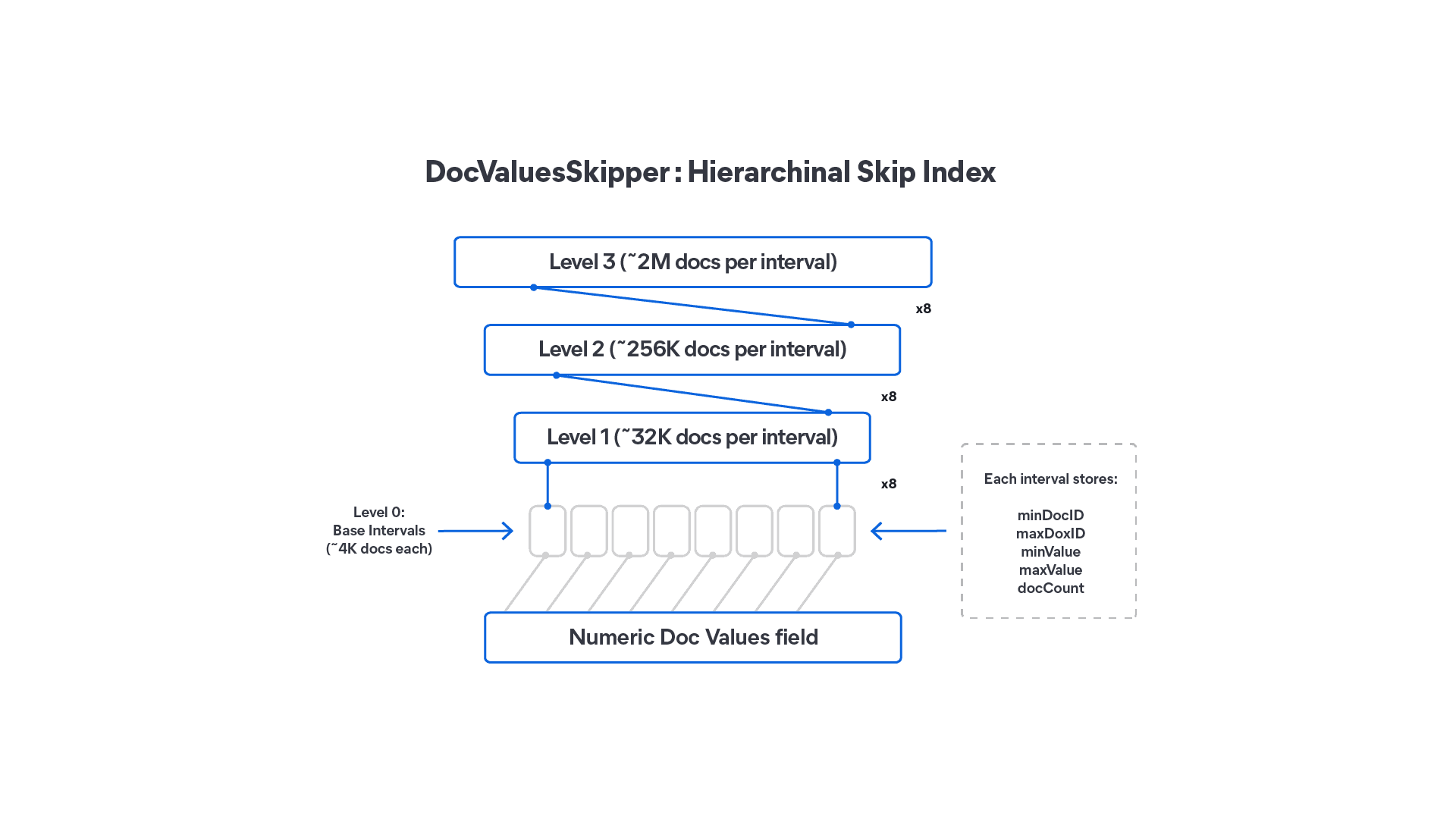
June 12, 2026
How DocValuesSkippers in Lucene 10 make range queries faster without doubling your storage
DocValuesSkippers add block-level skipping to Lucene DocValues fields, speeding up range queries on sorted or insert-ordered indexes with less than 0.1% storage overhead.

January 28, 2026
Apache Lucene 2025 wrap-up
2025 was a stellar year for Apache Lucene; here are our highlights.

September 3, 2025
Vector search filtering: Keep it relevant
Performing vector search to find the most similar results to a query is not enough. Filtering is often needed to narrow down search results. This article explains how filtering works for vector search in Elasticsearch and Apache Lucene.