大規模言語モデル(LLM)とは
大規模言語モデルの定義
大規模言語モデル(LLM)の中核となっているのは、ディープラーニングアルゴリズムを使用してトレーニングされたモデルであり、感情分析、会話型質問応答、テキスト翻訳、分類、生成などの幅広い自然言語処理(NLP)タスクが可能です。LLMはニューラルネットワーク(NN)の一種で、トランスフォーマーアーキテクチャを使用しています。このアーキテクチャは、データシーケンスの異なる部分間の依存関係を、距離に関係なく検出するように設計されているモデルです。これらのニューラルネットワークは、処理ユニットの層で構成されており、しばしば脳内のニューロンに例えられます。大規模言語モデルは多くのパラメータを持ちますが、それらはモデルが訓練により、学習するにつれて収集する記憶のようなものです。こういったパラメータは、モデルの知識バンクだと考えてください。
この処理能力により、LLMはソフトウェアコードの記述や言語生成などのタスクについてトレーニングを受けることができ、専門モデルはタンパク質の構造理解などのタスクを処理できます。1テキスト分類、質問応答、文書の要約、テキスト生成問題、およびその他のタスクを解決するには、大規模言語モデルを事前にトレーニングしてから微調整する必要があります。その問題解決能力は医療、金融、エンターテイメントなどの分野に適用でき、そこでは大規模言語モデルを翻訳、チャットボット、AIアシスタントなどの、さまざまなNLPアプリケーションに活用しています。
こちらの動画を視聴して、LLMについてさらに深く学びましょう。
LLMの仕組み
基本的に、大規模言語モデルは、入力を受け取り、それをエンコードし、デコードして、次の単語、文、特定の回答などの出力予測を生成することで機能します。すべての機械学習モデルと同様に、大規模言語モデルは、期待され、求められる出力結果を得る準備が整う前に、トレーニングと微調整を必要とします。プロセスは次のように改善されます。
- トレーニング:大規模言語モデルは、WikipediaやGitHubなどのサイトから得た大量のテキストデータセットを使って、事前にトレーニングされます。これらのデータセットは数兆の単語で構成されており、その品質は言語モデルのパフォーマンスに影響を与えるように設定されています。この段階では、大規模言語モデルは人の介入なしで学習を行います。つまりモデルに供給されるデータセットは具体的な指示なしで処理されます。このプロセス中に、アルゴリズムは単語とそのコンテキスト間の統計的な関係を認識することを学習します。たとえば「right」という単語が「正しい」という意味なのか、「右」という意味なのかを理解するように学習します。
- 微調整:大規模言語モデルが翻訳などの特定のタスクを実行するには、その特定のアクティビティに合わせて微調整する必要があります。微調整では、ラベル付けされた追加のデータでモデルをトレーニングすることにより、特定のタスクでのパフォーマンスに最適化されるようにモデルのパラメーターを調整します。
- プロンプト調整も微調整とよく似た機能を果たし、Few-ShotプロンプティングやZero-Shotプロンプティングによって、オペレーションを実行できるようにモデルを訓練します。Few-Shotプロンプティングは、次のような出力の予測をガイドする例をモデルに提供します。
| 顧客レビュー | 顧客センチメント |
|---|---|
| 「この植物はとても美しいです!」 | 肯定的 |
| 「この植物はとても醜いです!」 | 否定的 |
この場合、反対の例(美しい)が提供されたため、モデルは「醜い」の意味を理解します。
Zero-Shotプロンプティングでは、例を使用しません。代わりに、モデルに直接タスクを実行するように要求します。
「『この植物は醜い』という感情は...」
事前のトレーニングに基づいて、モデルは例を与えられずに感情を予測しなければなりません。大規模言語モデルの主要コンポーネント
大規模言語モデルは、複数のニューラルネットワーク層で構成されています。Embedding層、Attention層、Feedforward層の各層が連携して、インプットテキストを処理し、出力コンテンツを生成します。
- Embedding層は、入力テキスト、または入力された単語の数学的表現からベクトル埋め込みを作成します。モデルのこの部分では、入力の意味と構文上の意味を把握し、モデルが単語とその関係を文脈的に理解できるようにします。
- 注意機構により、モデルは現在のタスクとの関連性に基づいて入力テキストのすべての部分に焦点を合わせることができ、長距離の依存関係を捉えることができます。
- Feedforward層は、データに非線形変換を適用する複数の全結合層で構成されています。これらは、注意機構によってエンコードされた後に情報を処理します。
大規模言語モデルには主に3つのタイプがあります。
- GenericまたはRaw言語モデルは、訓練データ内にある言語を基に、次の単語を予測します。この種の言語モデルは、情報検索タスクに使用します。
- 指示チューニング型言語モデルは、入力で指定された指示に対する応答を予測するように訓練します。これにより、センチメント分析を実行したり、テキストやコードを生成できるようになります。
- 対話チューニング型言語モデルは、次の応答を予測して対話するように訓練されています。チャットボットや対話型AIがこれに該当します。
大規模言語モデルと生成AIの違い
生成AIは、コンテンツを作成できる人工知能モデルの総称です。こうしたモデルは、テキスト、コード、画像、動画、音楽を生成できます。また、テキスト生成(例:ChatGPT)や画像作成(例:DALL-E、MidJourney)など、さまざまなコンテンツタイプに特化することもできます。
大規模言語モデルは、大規模なテキストデータセットで特別にトレーニングされ、ChatGPTのようにテキストコンテンツを生成するように設計された生成AIの一種です。
すべてのLLMは生成AIですが、すべての生成AIモデルがLLMであるとは限りません。たとえば、DALL-EとMidJourneyはテキストではなく画像を生成します。
トランスフォーマーモデルとは何ですか?
トランスフォーマーモデルは、大規模言語モデルの最も一般的なアーキテクチャです。通常はエンコーダーとデコーダーの両方で構成されていますが、GPTのようにデコーダーのみを使用するモデルもあります。トランスフォーマーモデルは、入力をトークン化してデータを処理し、次に数学的方程式を同時に処理してトークン間の関係性を検出します。これにより、コンピュータは、人間が同じクエリを与えられた時に見るものと同じパターンを認識できます。
トランスフォーマーモデルは自己注意機構を使用しており、これによりモデルは、長・短期記憶モデルのような従来のモデルよりも迅速に学習できます。自己注意は、情報の並列処理を可能にすることで、トランスフォーマーモデルが文中で遠く離れた単語間の関係を、古いモデルよりも効果的に捉えることを可能にします。
大規模言語モデルの例とユースケース
大規模言語モデルの使用目的には以下のようなものがあります。
- 情報検索:BingやGoogleを想定してみましょう。LLMを検索エンジンに統合することで、クエリ対応を改善できます。従来の検索エンジンは主にインデキシングアルゴリズムに依存していますが、LLMはクエリに基づいて、より会話的またはコンテキストを意識した回答を生成する能力を強化します。
- 感情分析:自然言語処理の応用として、大規模言語モデルは企業がテキストデータの感情を分析することを可能にします。
- テキスト生成:ChatGPTのような大規模言語モデルは、生成AIシステムの基盤となり、与えられたプロンプトに基づいて、一貫性があり文脈に即したテキストを生成できます。たとえば、LLMに次のようなプロンプトを入力できます:「エミリー・ディキンソン風にヤシの木についての詩を書いてください。」
- コード生成:テキスト生成と同様に、LLMは生成AIの応用としてコードを生成できます。LLMは、さまざまな言語の膨大なプログラミングコードから学習し、入力プロンプトに基づいて構文的および論理的に正しいコードを生成できます。
- チャットボットと会話型AI:大規模言語モデルは、カスタマーサービスのチャットボットや会話型AIを支援します。顧客の問い合わせを解釈し、意図を理解し、人間のような会話をシミュレートした対応を生成するのに役立ちます。
関連記事:チャットボットの製作方法:開発者がすべきこと・すべきでないこと
こうしたユースケースに加えて、大規模言語モデルは文章を完成させ、質問に答え、テキストを要約できます。
多様な用途があるため、LLMはさまざまな分野で活用されています。
- 技術:大規模言語モデルは、検索エンジンのクエリ対応を強化したり、開発者のコーディングを支援したりするなど、さまざまな用途で使用されています。
- 医療と科学:大規模言語モデルは、タンパク質、分子、DNA、RNAに関連するテキストデータを分析し、研究、ワクチンの開発、病気の潜在的な治療法の特定、予防医療薬の改善を支援します。LLMは、患者の受付や基本的な診断のための医療用チャットボットとしても使用されていますが、通常は人間の監督が必要です。
- カスタマーサービス:LLMは、チャットボットや対話型AIなど、さまざまな業界でカスタマーサービスを目的として利用されています。
- マーケティング:マーケティングチームは、LLMを感情分析、コンテンツ生成、キャンペーンアイデアのブレインストーミングに活用し、提案書、広告、その他の資料のテキスト作成を支援できます。
- 法律:大規模な法律データセットの検索から法的文書の作成まで、大規模言語モデルは弁護士、パラリーガル、法務担当職員を支援できます。
- 銀行業務:LLMは、金融取引や顧客のコミュニケーションを分析して潜在的な不正を検出する際に役立ちます。多くの場合、これはより広範な不正検出システムの一部として行われます。
会社で生成AIを始めてみましょう。このウェビナーを視聴して、企業環境における生成AIの課題と機会についてご覧ください。
LLMの制限と課題
大規模言語モデルは我々に、意味を理解して正確に応答できるという印象を与えるかもしれません。しかし、それらは依然として人間の監督の恩恵を受けるツールであり、さまざまな課題に直面しています。
- ハルシネーション:ハルシネーション(幻覚)とは、LLMが誤った出力、またはユーザーの意図と一致しない出力を生成することを指します。たとえば、自分が人間であるとか、自分には感情があるとか、ユーザーと恋に落ちていると主張することがあります。大規模言語モデルは次に来る構文的に正しい単語や語句を予測しているだけで、人間的な意味を完全に解釈しているわけではなく、結果は時に「ハルシネーション」と呼ばれるものになります。
- セキュリティ:大規模言語モデルは、適切に管理または監視されていない場合、重大なセキュリティリスクをもたらします。トレーニングデータから、または対話中に意図せず個人情報を漏らし、フィッシングやスパムの生成などの悪意のある目的でエクスプロイトされる可能性があります。悪意のあるユーザーがLLMを悪用して、偏った思想、誤った情報、または有害なコンテンツを広める可能性もあります。
- バイアス:言語モデルのトレーニングに使用されるデータは、特定のモデルが生成する出力に影響を与えます。訓練データに多様性が欠けていたり、特定の人口統計に偏っていたりすると、モデルはこれらのバイアスを再現し、偏った(おそらくは狭い)視点を反映した出力を生成する可能性があります。多様で代表的なデータセットを確保することは、モデル出力のバイアスを減らすための鍵となります。
- 同意:大規模言語モデルは、膨大なデータセットを用いて訓練されています。その一部は、明示的な同意や著作権契約の遵守なしに収集されたものである可能性があります。適切な帰属や許可なくコンテンツが複製されると、知的財産権の侵害につながる可能性があります。さらに、これらのモデルは個人データをスクレイピングする可能性があり、プライバシー上の懸念が生じます。2Getty Images3などの企業による著作権侵害に関する訴訟など、LLMが法的問題に直面した事例があります。
- スケーリング:LLMのスケーリングは非常にリソース集約的で、多大な演算能力を必要とします。このようなモデルの保守には、継続的な更新、最適化、および監視が必要であり、これは時間とコストのかかるプロセスです。これらのモデルをサポートするために必要なインフラも、相当な規模になります。
- 導入:大規模言語モデルを導入するには、ディープラーニングとトランスフォーマーアーキテクチャの専門知識に加えて、特殊なハードウェアと分散型のソフトウェアシステムが必要です。
LLMのメリット
幅広い用途を持つ大規模言語モデルは、問題解決において圧倒的なメリットがあります。LLMは情報を明確な会話形式で提供するため、ユーザーが簡単に理解できるからです。
- 幅広い用途:言語翻訳、文章補完、感情分析、質問応答、数式などに使用できます。
- 常に改善:大規模言語モデルの性能は、追加のデータやパラメータが統合されるにつれて、継続的に向上しています。この改善は、モデルのアーキテクチャや追加された訓練データの品質などの要因にも左右されます。つまり、モデルが学習すればするほど、性能は向上します。さらに、大規模言語モデルは、追加の訓練やパラメータを必要とせずに、プロンプトで提供された例に基づいてタスクを実行できる、いわゆる「文脈内学習」を行うことができます。これにより、モデルは、わずか数個の例(少数ショット学習)から、または事前に例を与えなくても(ゼロショット学習)一般化を行いさまざまなタスクに適応できるようになります。こうしてモデルは継続的に学習を続けます。
- 学習が速い:文脈内学習により、LLMは最小限の例で新しいタスクに適応できます。追加のトレーニングやパラメータを必要とせず、プロンプトのコンテキストにすばやく応答できるため、例が少ないシナリオでも効率的です。
人気の高い大規模言語モデルの例
人気の高い大規模言語モデルは世界中で一世を風靡しており、その多くが、さまざまな業界の人々に採用されています。生成AIチャットボットの1種であるChatGPTのことは、すでにご存じでしょう。
その他の人気の高いLLMモデルを、以下に挙げます。
- PaLM:GoogleのPathways言語モデル(PaLM)は、常識的および算術的な推論、ジョークの説明、コード生成、翻訳が可能なトランスフォーマー言語モデルです。
- BERT:Bidirectional Encoder Representations from Transformers(BERT)言語モデルもGoogleで開発されました。トランスフォーマーベースのモデルで、自然言語が理解でき、質問に答えられます。
- XLNet:順列言語モデルのXLNetは、入力トークンの考えられるすべての順列を学習しますが、推論中は標準的なLeft-to-Rightの方法で予測を生成します。
- GPT:Generative Pre-trained Transformerは、おそらく最もよく知られている大規模言語モデルです。OpenAIが開発したGPTは、人気のある基礎的モデルで、GPT-3、GPT-4といったバージョン番号が、先行モデルの改良を表しています。GPTモデルは、特定のタスクに合わせて微調整できます。それとは別に、CRMアプリケーション用のSalesforce社によるEinsteinGPTや、金融データ用のBloombergGPTなど、基礎的なLLMにヒントを得た業界固有のモデルを開発している組織もあります。
大規模言語モデルの今後の発展
ChatGPTの到来により、大規模言語モデルが脚光を浴び、推測が飛び交い、未来はどうなるのかという議論が白熱しました。
大規模言語モデルが成長し、自然言語を自由に扱える能力を改善し続けるにつれて、その進歩が雇用状況に与える影響に関する懸念が沸き起こってきました。
大規模言語モデルは、適切な使用方法で使用すれば、生産性とプロセス効率を向上させることができますが、その使用は人間社会において倫理的な問題を引き起こしています。
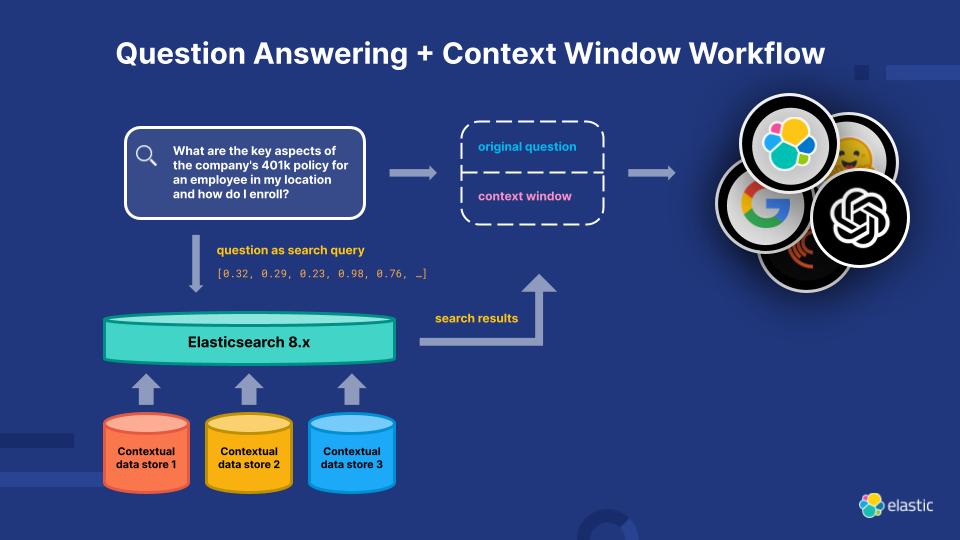
Elasticsearch Relevance Engineについて知る
Elasticsearch Relevance Engine(ESRE) は、LLMが現状抱える制限に対処するため、人工知能による検索アプリケーション用に構築された関連性エンジンです。ESREの力を活用すれば、開発者は独自のセマンティック検索アプリケーションを構築し、自分自身のトランスフォーマーモデルを活用し、NLPと生成AIを組み合わせて顧客の検索体験を向上させることができます。
Elasticsearch Relevance Engineを活用して、関連性を飛躍的に高めましょう
大規模言語モデルのリソースをさらに探る
- LLMオブザーバビリティ
- Elasticの生成AIツールと機能
- ベクトルデータベースの選び方
- チャットボットの作り方:開発者がすべきこと・すべきでないこと
- LLMの選択:オープンソースLLM入門ガイド
- Elasticsearchでの言語モデル
- 2025年の技術トレンド:選択の時代を活かし、生成AIを本番環境に導入
- Elastic Stackにおける自然言語処理(NLP)の概要
- Elastic Stack互換のサードパーティーモデル
- Elastic Stackにおける訓練済みモデルガイド
- LLM安全性評価
脚注
- Sarumi, Oluwafemi A., and Dominik Heider. "Large Language Models and Their Applications in Bioinformatics." Computational and Structural Biotechnology Journal, vol. 23、2024年4月、pp. 3498–3505.
https://www.csbj.org/article/S2001-0370(24)00320-9/fulltext. - Sheng, Ellen. "In generative AI legal Wild West, the courtroom battles are just getting started," CNBC、2023年4月3日、https://www.cnbc.com/2023/04/03/in-generative-ai-legal-wild-west-lawsuits-are-just-getting-started.html(2023年6月29日にアクセス)
- Getty Imagesの声明、Getty Images、2023年1月17日https://newsroom.gettyimages.com/en/getty-images/getty-images-statement(2023年6月29日にアクセス)