When and How To Percolate - Part 2
In last week's blog "When and How To Percolate - Part 1" we discussed the key differences between Watcher and Percolation and how to determine which is applicable to your use case. We followed this with an overview of the scaling properties of Percolator. In this week's post, we'll discuss the tools available for improving and optimising Percolator performance.
Filters
Filters represent the initial and preferred mechanism for reducing the percolation query set and thus making linear execution acceptable. Filters work by attaching metadata to the percolator queries. When percolating a document, a normal Elasticsearch filter is also included. This identifies a reduced subset of queries which need to be evaluated using the process in last week's post. Although filtering incurs some overhead, this cost is comparable to the use of Elasticsearch filters in standard search use cases, which scales significantly better on large index sizes.
Candidates for filters are typically metadata fields, which exist on both the queries and percolator documents. Although not essential, these would ideally allow your queries to be grouped into approximately evenly distributed subsets. However, any metadata that allows subsets of queries to run should be considered for use in filtering.
Let's consider the use case discussed in last week's post, where a shard contains 1 million percolation queries. Evaluating each of these against a document takes around 4.2 seconds. However, suppose we modify our percolator queries such that our category id is attached as metadata. We, in turn, pass the categories associated with a product, as a filter, when percolating its document.
PUT /best_buy/.percolator/2
{
"query": {
//query
},
"category_id": "pcmcat209400050001",
"user": "0dc7a91b9efb4f91e2a454907aeb9596fcb43bc2"
}
Figure 1 - Percolator Query With Filter
POST /best_buy/.percolator/_percolate
{
"query": {
"bool": {
"filter": {
"terms": {
"category_id": [
"cat00000",
"abcat0300000",
"pcmcat165900050023"
]
}
}
}
},
"doc": {
//document
},
"size": 10
}
Figure 2 - Percolator Document. The above example utilises Elasticsearch 2.0 syntax. See https://www.elastic.co/guide/en/elasticsearch/refe... for further details.
Across a corpus of 1 million queries, the category id has a cardinality of approx. 1500. These are not uniformly distributed across our data, with users expressing more interest in some categories than others.
The following diagram illustrates the results of repeating the tests described in "When and How To Percolate - Part 1", with filtering applied using the category id.
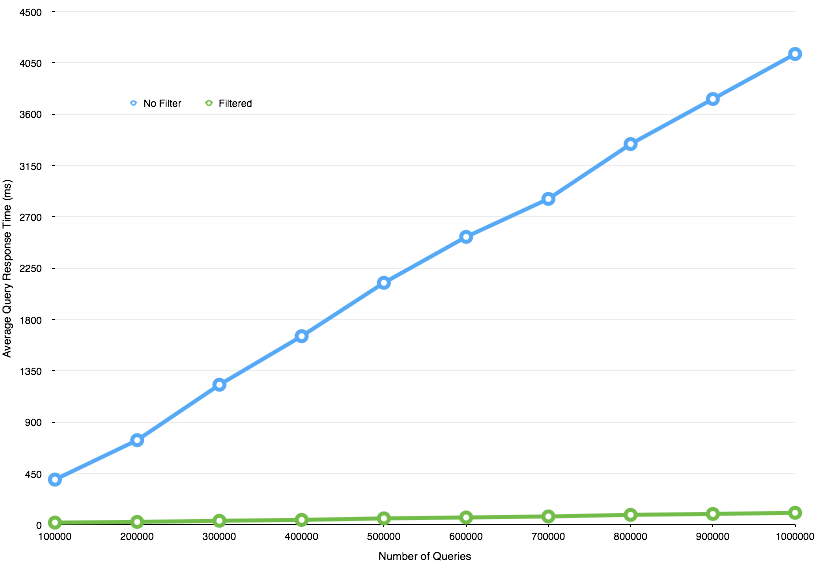
Figure 3 - Filtered Vs. Unfiltered Percolator
Adding the category id as a filter results in a significant performance increase. 1 million percolation queries now evaluate in around 100ms.
Filtering requires:
- Metadata fields with sufficient cardinality to reduce the percolate query set. Generally, a high cardinality field is preferred for filtering to exclude a high proportion of the queries prior to sequential evaluation; ideally with a uniform distribution for consistent query performance.
- Sometimes, values for filters have to be extracted from documents prior to percolation. This metadata can also be sourced externally. For example, consider the Best Buy queries are tagged selectively with "Premium" to indicate paying users. This filter could be added to percolate documents to prioritise alerting for these individuals.
We recognise that filtering is not always possible. For example, in some instances users have the requirement to always evaluate all queries against a document(e.g. for an admin-focused use case). Alternatively, there may just be an absence of appropriate metadata for filters.
Sharding and Routing
Sharding of percolator indexes provides a mechanism to take advantage of additional resources and thus improve performance. By splitting percolate queries across multiple shards, the number of percolator queries requiring evaluation in each is reduced. Given the document is percolated on each shard in parallel, the total latency experienced therefore becomes the performance on the slowest shard - thus increasing throughput through parallel execution of smaller tasks.
Once sharded, users can consider optimising further using routing. This techniques ensures documents are only percolated on the the shards which contain possible candidate queries for linear evaluation. To achieve this, percolator queries need to be partitioned by a custom routing value at index time. This same value is also used when passing a document to ensure it is only executed on the required shard - thus saving resources and increasing possible throughput. Multiple values can also be specified as a comma separated string, allowing a query and document to be indexed and executed on more than one shard.
Routing keys candidates have the same characteristics as those used for filters - metadata fields shared by documents and queries. While Elasticsearch manages the routing, it ensures that distribution is fairly uniform across all your shards. However, once you start implementing your own custom schemes, it is entirely possible that this uniformity is lost resulting in an uneven execution load across the cluster. We, therefore, recommend you consider a meta field which has a uniform distribution of values across your percolator queries.
Routing guarantees that all queries with the same key collocate on the same shard. The cardinality of your routing key is likely to be greater than the number of shards, resulting in multiple values hashing to the same shard. Where routing is used, the key should therefore always also be applied as a filter.
Multi-Percolate and Replicas
The multi-percolate API allows users to bundle multiple percolate requests into a single request, similar to what the multi-search API does to search request. For each request, the coordinating node will select one shard from the replication group (primary + replicas). How documents are distributed to these selected shards depends on whether routing is enabled. If not utilised, all documents will be sent to each of these shards in parallel. If routing is enabled, the documents will be batched according to their appropriate shard and each batch sent in parallel. Multi-percolate therefore allows you to execute percolations more efficiently but predominantly acts as a network optimisation. The selection of shards from a replica group is round-robin between requests, thus balancing resource utilisation across nodes.
As described above, provided your client takes advantage of their availability, replicas provide increased throughput provided you have sufficient nodes to spread the load. Consider that nodes are likely to hold multiple shards, and replicas. A node can be potentially evaluating as many percolator queries as shards at any time. Whilst replicas can be used to increase throughput, users should load test in a representative environment whilst monitoring resource utilisation closely. Replicas provide the usual benefit of high availability.
Resource Utilisation
The memory required for Percolator queries is heavily dependent on the operators utilised. Wildcard queries operators are particularly expensive when evaluated against documents due to the creation of an FST. The Percolator cache is held within heap space, which can easily reach 80% capacity on large/complex query volumes if allocated insufficient memory. This will in turn cause old generation garbage collector cycles which significantly impact query performance. Provided memory pressure is not an issue, users will see Percolation is CPU-bound with respect to performance and should see the linear scalability illustrated earlier. We encourage users index real queries and establish memory requirements per node. This may be a consideration, in addition to query latency, when deciding the number of queries to index per shard.
Finally, given the CPU intensive nature of Percolator, we encourage users to consider a dedicated index and possibly cluster - especially if you anticipate high throughput and require consistent performance.
Further details on the tests performed in both parts of this blog post, including the scripts and test environment utilised, can be found here [reference: https://github.com/gingerwizard/percolator_scaling].