Vector database vs. graph database: Understanding the differences


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Big data management isn’t just about storing as much data as possible. It’s about being able to identify meaningful insights, discover hidden patterns, and make informed decisions. This quest for advanced analytics has been the driving force behind innovations in data modeling and storage solutions, way beyond traditional relational databases.
Two of these innovations are vector databases and graph databases. Both are significant advancements in managing data, providing unique data structures with their own distinct strengths. But you need to have an understanding of how they work and how they are different before you can effectively choose which one is best for your project or goals.
This blog post will be your guide — outlining how they work, how they’re similar, and how they’re also very different. We’ll explore the contrasting data structures, explore their ideal use cases, and help you to choose between the two of them. To make this easier, we’ve broken it down into a few sections:
Vector database definition and concepts
What are graph databases?
Comparing vector and graph databases
Vector and graph databases use cases
Choosing between vector and graph databases
By the end of this article, you’ll have all the information you need to make an informed decision, so you can get the most out of your data.
Vector database definition and concepts
Instead of rows and columns, a vector database organizes data as points in a vast, multi-dimensional space. Each point represents a piece of data, and the location reflects its characteristics relative to other pieces of data. Think of it like a universe where every planet is a piece of data, and they’re organized to be closer to similar planets and further away from planets with fewer similarities.
It achieves this by storing the data as high-dimensional vectors, which are numerical representations of the data features. These vectors capture the essence of the data they represent, which is how they can be encoded and organized within the multi-dimensional space. And the closer two points are in the multi-dimensional space, the more similar their underlying data is.
This is why vector databases excel at similarity search. Because the vectors are structured based on similarity, you can quickly identify data points that are closest to your query vector. This makes them ideal for a number of important applications:
Image and document retrieval: Find similar images based on content, not just keywords.
Personalized recommendations: Recommend products or content similar to what a user has interacted with before.
Anomaly detection: Identify unusual data points that deviate from the norm, potentially indicating fraud or system errors.
Machine learning: Efficiently process and analyze high-dimensional data for tasks like text analysis, image classification, and natural language processing.
Want a more detailed guide? Read What is a vector database? for a full walk-through.
What are graph databases?
Although they may look similar at a glance, graph databases organize data in an entirely different way. Instead of using rigid tables like a relational database, or organizing the data by similarity like vector databases, they store data in a graph structure. Entities are represented by nodes on the graph, and relationships are represented by edges. Think of it like a mindmap, where each node is a circle representing people, places, or things, and the lines between them (edges) show how they’re connected.
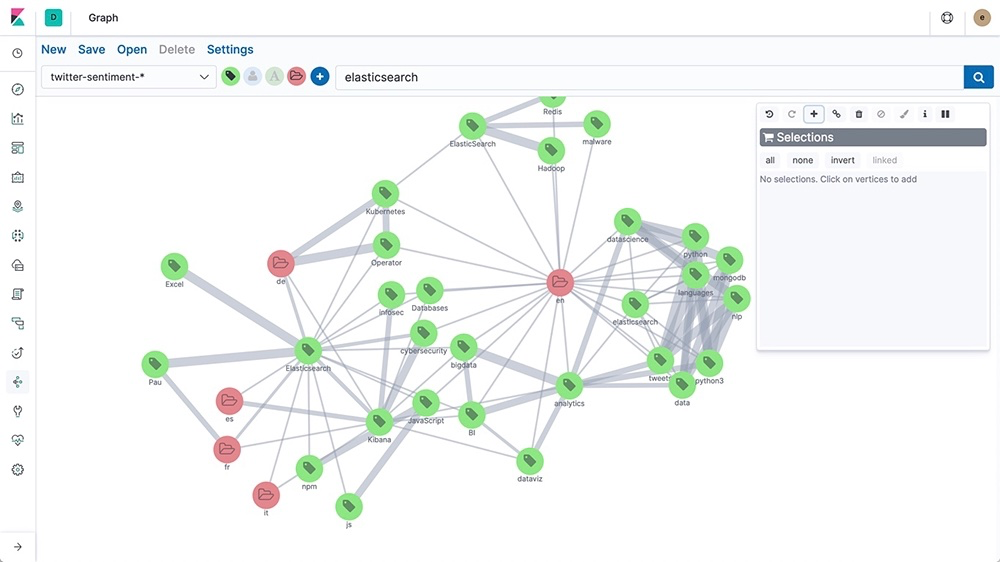
One of the advantages of this kind of structure is that it’s a more natural representation of complex relationships. This makes it easier to interpret the connections compared to other types of databases. The schema-less structure of graph databases also means you can easily add new nodes and edges as your data grows, making it both flexible and scalable. This makes graph databases ideal for many applications:
Real-time analytics: Analyze streaming data, predict future outcomes, and optimize dynamic systems in real time with graph databases.
Master data management: Create a unified view of entities, resolve ambiguity, and track entity evolution within a single interconnected graph.
Network discovery: Uncover hidden connections, identify anomalies, and predict cascading failures by analyzing relationships within networks.
Knowledge graph construction: Build intelligent knowledge bases, answer complex questions, and power intelligent applications through interconnected entities and concepts.
Comparing vector and graph databases
You should now understand what each type of database is and how it structures data. But it’s also crucial to understand the nuanced differences between vector and graph databases. The easiest way to do this is with a side-by-side comparison:
| Vector database | Graph database | |
| Data representation | Data is structured as points in a vast, multi-dimensional space. Points closer together represent similar content. Ideal for capturing inherent similarities within data itself, regardless of connections or relationships. | Data is structured as a web of interconnected nodes (entities) linked by edges (relationships). Focuses on representing the connections and hierarchies between data points, offering valuable insights into how entities relate to each other. |
| Querying and retrieval | Excel at similarity search, efficiently finding data points similar to a query vector. Ideal for tasks like image/document retrieval, where understanding content similarity is crucial. | Powerful for navigating relationships and connections. Enable efficient traversal of network structures, perfect for social network analysis, recommendation systems, and exploring knowledge graphs. |
| Performance and scalability | Generally scales well with large data sets due to optimized similarity search algorithms. However, schema changes might require data re-embeddings, impacting performance. | Highly flexible due to schema-less nature, allowing for easy data addition and modification. However, complex queries or large networks can strain performance, requiring careful optimization. |
Use cases
To better understand the differences between vector and graph databases, let’s compare how each one can be used within the same sector. This not only shows the contrasts but also how they could potentially be used together to achieve great results:
Fraud detection
Vector databases: Identify fraudulent transactions by analyzing transaction patterns and user information. Detect anomalies in spending habits, purchase locations, or device fingerprints based on learned similarity profiles.
- Graph databases: Uncover suspicious networks of connected individuals or transactions. Identify fraudulent activity by analyzing relationships between entities involved in potential fraud attempts.
Scientific research
Vector databases: Analyze complex data structures like protein sequences, gene expressions, or chemical compounds. Compare diverse data sets and identify similarities based on multi-dimensional features, leading to new scientific discoveries.
- Graph databases: Model biological pathways or molecular interactions. Explore intricate relationships between entities and visualize complex systems, leading to a deeper understanding of biological processes.
Ecommerce
Vector databases: Analyze product attributes like images, text descriptions, and technical specifications. Recommend similar products based on content similarity, leading to more relevant and engaging suggestions.
- Graph databases: Capture user-product interactions like purchases, browsing history, and wish lists. Recommend products based on users' similarities to others with similar taste, creating a more personalized shopping experience.
Media and entertainment
Vector databases: Analyze content features like music genres, article topics, or movie themes. Recommend similar songs, movies, or articles based on inherent content similarity, catering to individual preferences.
- Graph databases: Explore user-content relationships like watch history, reading lists, or social media shares. Recommend content based on connections between users with similar interests, fostering engagement and discovery.
Choosing between vector and graph databases
Even with the information we’ve been through in this article, selecting the right database can still be a daunting task. To make this process simpler, here’s a framework you can follow to help you make the best decision to achieve your goal.
Step 1. Understand your data
The first part of this process is to look at the complexity of your data. Is it primarily structured or unstructured? Does it involve intricate relationships or independent entities?
You also need to consider your data volume and how quickly you expect it to grow. Then you need to decide what specific features or attributes define your data points — and whether these are numerical or categorical.
Step 2. Identify your primary use cases
In simple terms, what insights are you hoping to glean from your data analysis? Are you trying to find similar data points based on content or explore intricate connections between entities? What kind of queries will you be performing frequently?
Step 3. Performance and scalability needs
The third step is to think about how important speed and scalability are to your goal. How critical are real-time responses for your application? How large are your data sets, and how complex are your anticipated queries? You also need to consider your budget constraints and resource limitations.
Step 4. Evaluate the specific advantages of each technology
Each of these database types has its own strengths and weaknesses. Vector databases are ideal for similarity search, are efficient with high-dimensional data, and handle large data sets well. Graph databases excel at navigating relationships, are powerful for complex network analysis, and have highly flexible schema.
Unlock the full potential of your data
Navigating the big data landscape demands powerful tools, and vector and graph databases stand as innovative players in this information space. But selecting the right model for your needs can be daunting.
Carefully evaluate the factors above and understand the distinct strengths of each technology. You’ll end up with a list of factors that will inform your decision, helping you choose the right database model to unlock the full potential of your data.
What you should do next
Whenever you're ready, here are four ways we can help you bring better search experiences to your business:
Start a free trial and see how Elastic can help your business.
Tour our solutions to see how the Elasticsearch Platform works and how our solutions will fit your needs.
Share this article with someone you know who'd enjoy reading it via email, LinkedIn, Twitter, or Facebook.
Explore more data analytics and database resources:
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print