Machine Learning 6.1.0 Released
Editor's Note (August 3, 2021): This post uses deprecated features. Please reference the map custom regions with reverse geocoding documentation for current instructions.
Today we excited to announce the 6.1.0 release of the Elastic Stack which includes some major new Machine Learning features.
On Demand Forecasting
Ever since we started working on time series analysis, customers have asked us if we can predict the value of a series at some future time. For example, if this chart represents the number of unique visitors to my website - can I predict the number of visitors in the next week?
.png)
To do this with 6.1.0 Machine Learning, you simply create a single metric (anomaly detection) job to analyse unique visitors and then go to the new ‘forecast’ button in the single metric viewer:

The results show our prediction for the number of unique visitors in the next week:
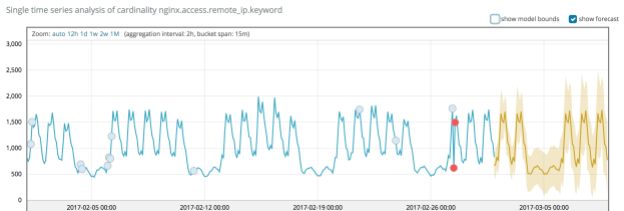
The yellow line shows the typical values we expect, and the shaded yellow band provide an indication of the confidence of our predictions.
As new data comes in we can then view the accuracy of the prediction with respect to the actual data:.png)
Under the hood we are reusing the complex time series models we created for anomaly detection for forecasting. These models are very expressive and incorporate periodic and long term trends and so capture features relevant to forecasting.
Another blog post will describe this feature in more detail, and it would be great to get user feedback on this first iteration!
Smarter Node Allocation for ML Jobs
Different ML jobs require different resources, for example a single metric job will generally require significantly less CPU and memory than a multi metric job analysing thousands of time series.
Prior to 6.1.0, an ML job was allocated to the node with fewest running jobs. This didn’t take into account the size of the job, and so it could lead to situations where the ML workload was unevenly distributed across the cluster.
Allocating ML jobs can be viewed as a packing problem, which is extremely complex as the set of items that needs to be packed is dynamic. More details will be provided in a further blog post, but in summary, 6.1.0 will take into account the memory requirements for a job when allocating it to a node.
This will now allow us to allocate the load more efficiently across all ML nodes. By doing this with respect to memory we are able to run many more single metric jobs on a single ML node, and more efficiently manage the requirements of larger jobs.
Automatic Job Creation for Known Data Types
As discussed in previous blog post (https://www.elastic.co/blog/machine-learning-for-n...) we are planning to curate best practise ML jobs for known data types.
In 6.1.0 we have introduced a new feature in the ML UI, which automatically recognises data types and suggests suitable jobs. This provides an alternative way to access curated jobs to installing jobs with filebeat setup (https://www.elastic.co/blog/beats-5-6-0-released). This is useful if you already have filebeat data in Elasticsearch and from an engineering standpoint, this will allow us to deliver curated use cases more easily.
Normally, when creating a job, you see the following page:
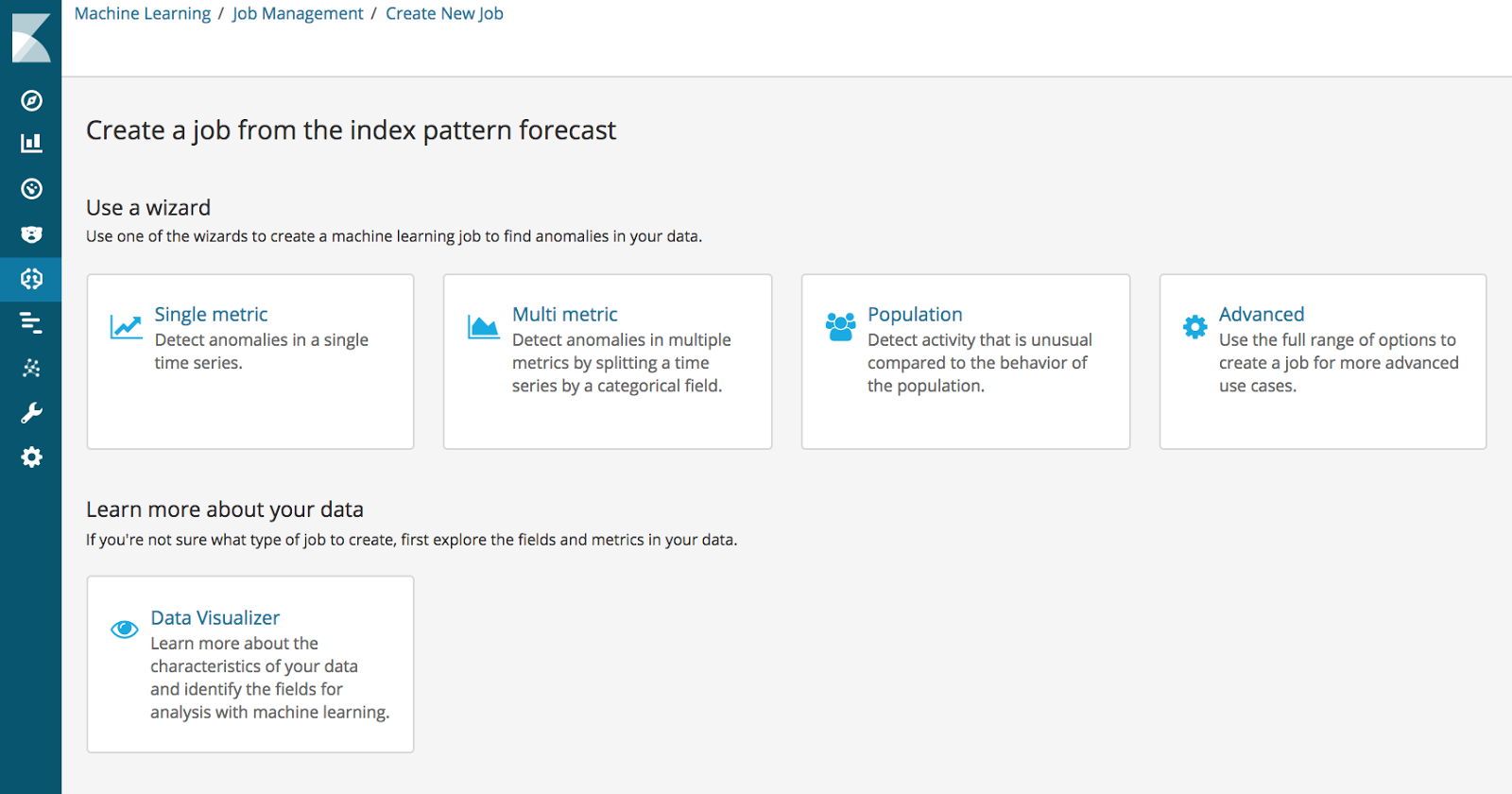
If the index pattern you choose matches a known type, you will now see the following:
.png)
Clicking on ‘Filebeat NGINX’ allows you to create curated ML jobs and dashboards:

Which creates the following:
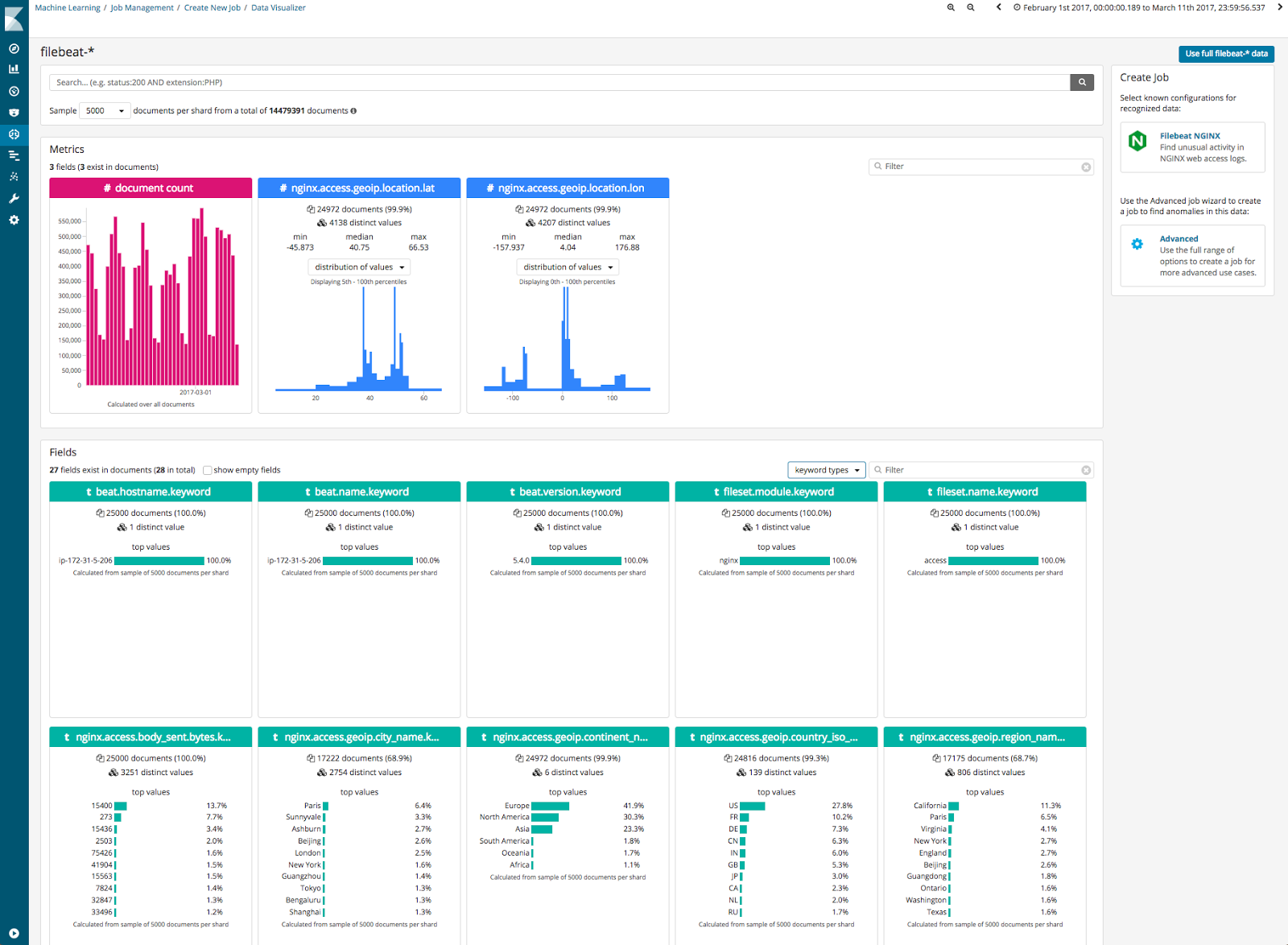
Data Visualizer
A key part of getting good results from ML jobs is selecting the most effective features to model. To assist the feature selection process, 6.1.0 will provide a data visualization tool to help you understand your data and which fields are suitable for ML analysis.
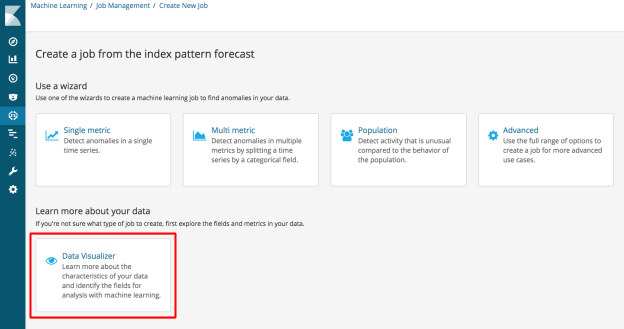
This tool summarizes the key features in the data, such as cardinality of fields, sparsity and counts of key values. Moving forward we will extend this view to help you create more effective analysis configurations for time series ML jobs:
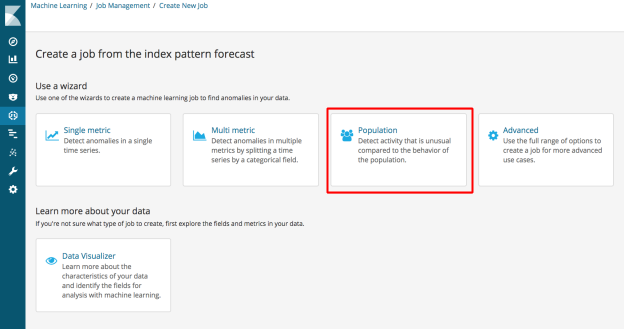
Population Analysis Job Wizard
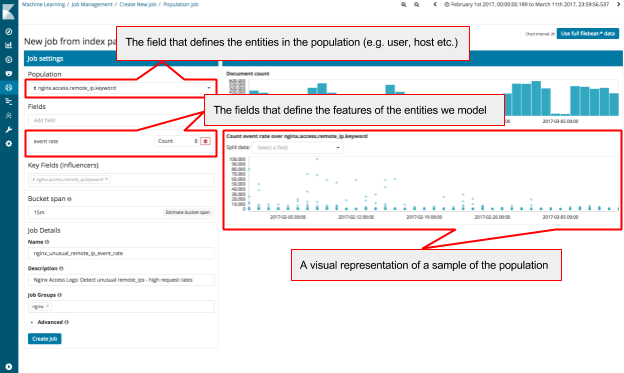
Population analysis jobs can be complex to define, and so we have now added a new ‘Population’ job creation wizard:
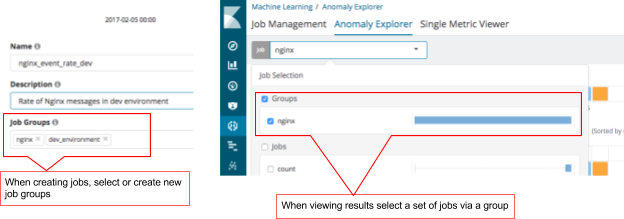
Job Groups
We are seeing users create more and more jobs as they become familiar with Machine Learning. To help users manage these jobs, we have added ‘Job Groups’. Users can add multiple tags to jobs so results can be viewed together more easily.
Overall Buckets
Leading on from job groups, we now allow users to create more effective alerts from multiple jobs. We have added a new API that combines and correlates anomalies from multiple jobs into an overall score.
For example, if I have 3 jobs that describe my application, and I want to be alerted if at least two of these jobs experience a significant anomaly, then I can configure Watcher to call this endpoint:
GET _xpack/ml/anomaly_detectors/job-1,job-2,job-3/results/overall_buckets
{
"overall_score": 75,
"start": "1403532000000",
"top_n": 2
}
which returns if the the overall score is greater than or equal to 75, calculated by taking the average of the top 2 jobs in the search:
{
"count": 1,
"overall_buckets": [
{
"timestamp" : 1403532000000,
"bucket_span" : 3600,
"overall_score" : 75.0,
"jobs" : [
{
"job_id" : "job-1",
"max_anomaly_score" : 80.0
},
{
"job_id" : "job-2",
"max_anomaly_score" : 70.0
},
{
"job_id" : "job-3",
"max_anomaly_score" : 14.0
}
],
"is_interim" : false,
"result_type" : "overall_bucket"
}
]
}
Overall buckets will also take into account if the bucket_span of the jobs are different. It will use the longest bucket_span from the selected jobs to ensure that jobs with smaller a bucket_span do not overtly impact results.
As you can see 6.1.0 contains a number of significant new ML features. More information on these different features will be published in our docs and in upcoming blogs. In the meantime, it would be great to get your feedback!