Introducing the Elastic Common Schema
Introducing the Elastic Common Schema (ECS), a new specification that provides a consistent and customizable way to structure your data in Elasticsearch, facilitating the analysis of data from diverse sources. With ECS, analytics content such as dashboards and machine learning jobs can be applied more broadly, searches can be crafted more narrowly, and field names are easier to remember.
Why a Common Schema?
Whether you’re performing interactive analysis (e.g., search, drill-down and pivoting, visualization) or automated analysis (e.g., alerting, machine learning-driven anomaly detection), you need to be able to uniformly examine your data. But unless your data originates from only one source, you face formatting inconsistencies resulting from:
- Disparate data types (e.g., logs, metrics, APM, flows, contextual data)
- Heterogeneous environments with diverse vendor standards
- Similar-but-different data sources (e.g., multiple sources of endpoint data, like Auditbeat, Cylance, and Tanium)
Imagine searching for a specific user within data originating from multiple sources. Just to search for this one field, you would likely need to account for multiple field names, such as user, username, nginx.access.user_name, and login. Drilling into and pivoting around that data would present an even greater challenge. Now imagine developing analytics content, such as a visualization, alert, or machine learning job — each new data source would add either complexity or duplication.
What is the Elastic Common Schema?
ECS is an open source specification that defines a common set of document fields for data ingested into Elasticsearch. ECS is designed to support uniform data modeling, enabling you to centrally analyze data from diverse sources with both interactive and automated techniques.
ECS offers both the predictability of a purpose-built taxonomy and the versatility of an inclusive spec that adapts for custom use cases. ECS’s taxonomy distributes data elements across fields that are organized into the following three levels:
| Level | Description | Recommendation |
| ECS Core Fields | Fully defined set of field names that exists under a defined set of ECS top-level objects | These fields are common across most use cases, so work should begin here |
| ECS Extended Fields | Partially defined set of field names that exists under the same set of ECS top-level objects | Extended fields may apply to narrower use cases or be more open to interpretation depending on the use case |
| Custom Fields | Undefined and unnamed set of fields that exists under a user-supplied set of non-ECS top-level objects that must not conflict with ECS fields or objects | This is where you can add fields for which ECS does not have a corresponding field; you can also keep a copy of original event fields here, such as when transitioning your data to ECS |
Elastic Common Schema in Action
Example 1: Parsing
Let’s put ECS to work on the following Apache log:
10.42.42.42 - - [07/Dec/2018:11:05:07 +0100] "GET /blog HTTP/1.1" 200 2571 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
Mapping this message to ECS organizes the log’s fields in the following manner:
| Field Name | Value | Notes |
| @timestamp | 2018-12-07T11:05:07.000Z | |
| ecs.version | 1.0.0 | |
| event.dataset | apache.access | |
| event.original | 10.42.42.42 - - [07/Dec ... | Full, unmodified log for auditing |
| http.request.method | get | |
| http.response.body.bytes | 2571 | |
| http.response.status_code | 200 | |
| http.version | 1.1 | |
| host.hostname | webserver-blog-prod | |
| message | "GET /blog HTTP/1.1" 200 2571 | Text representation of the significant information from the event for succinct display in a log viewer |
| service.name | Company blog | Your custom name for this service |
| service.type | apache | |
| source.geo.* | Fields for geolocation | |
| source.ip | 10.42.42.42 | |
| url.original | /blog | |
| user.name | - | |
| user_agent.* | Fields describing the user agent |
As shown above, the raw log is preserved in ECS’s event.original field to support auditing use cases. Please also note that for simplicity’s sake, this example omits details about the monitoring agent (under agent.*), some details about the host (under host.*), and a few more fields. For a more complete representation, review this example event in JSON.
Example 2: Search
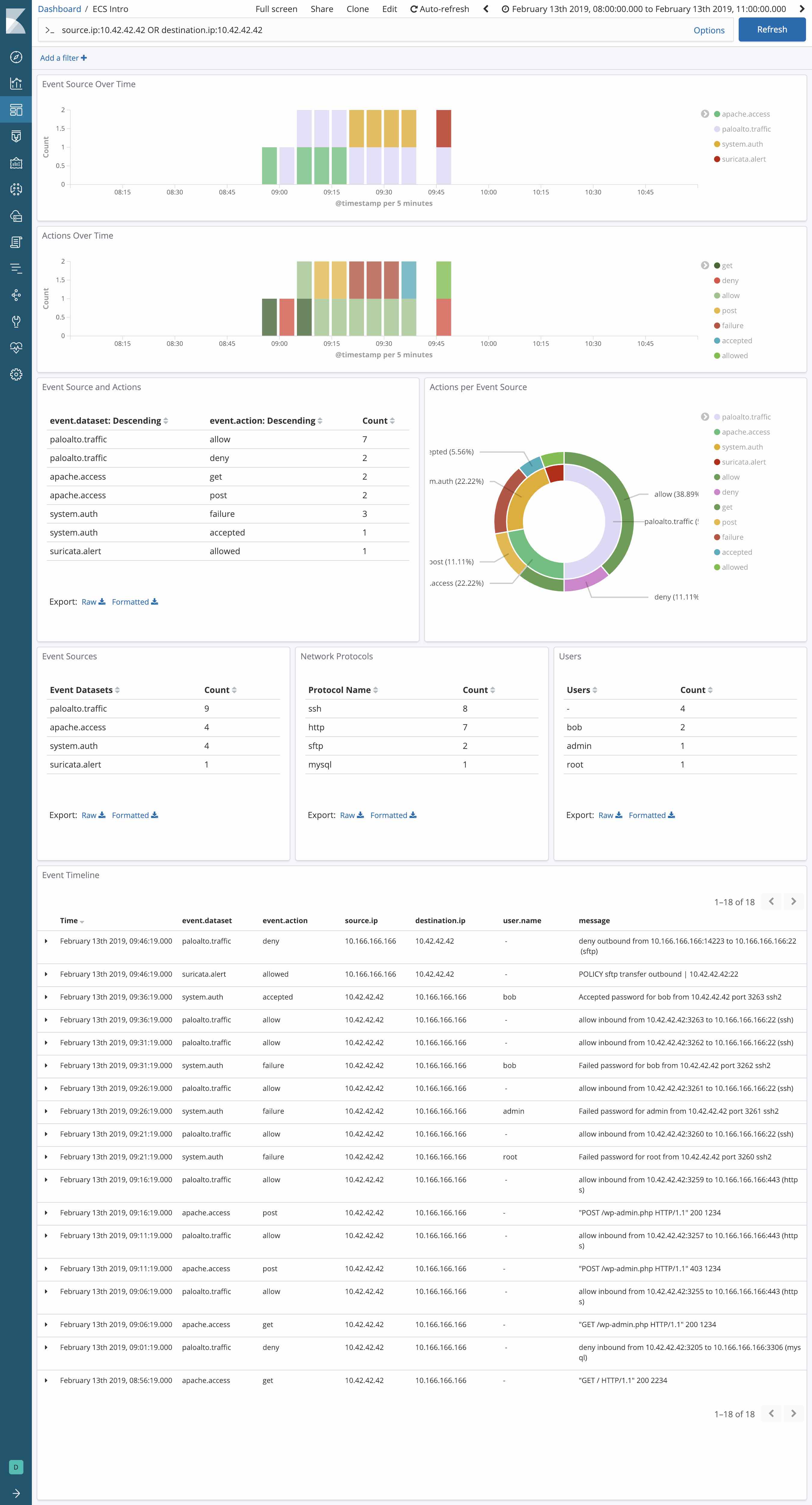
Consider an investigation into the activity of a specific IP across a complete web stack: Palo Alto Networks Firewall, HAProxy (as processed by Logstash), Apache (using the Beats module), Elastic APM, and for good measure, the Suricata IDS (custom, using their EVE JSON format).
Prior to ECS, your search for this IP may have looked something like this:
src:10.42.42.42 OR client_ip:10.42.42.42 OR apache2.access.remote_ip:10.42.42.42 OR context.user.ip:10.42.42.42 OR src_ip:10.42.42.42
But if you’ve mapped all your sources to ECS, your query is much simpler:
source.ip:10.42.42.42
Example 3: Visualization
The power of ECS is more readily revealed by seeing how it can be applied to uniformly normalized data from several different data sources. Perhaps you’re monitoring your web stack for threats with several sources of network data: a Palo Alto Next-Gen Firewall on the perimeter, and the Suricata IDS generating events and alerts. How do you extract the source.ip and network.direction fields from each message in a way that enables centralized visualization in Kibana and vendor-agnostic drill-down and pivoting? With ECS, of course, allowing you to perform centralized monitoring more easily than was previously possible.
Benefits of the Elastic Common Schema
Implementing ECS unifies all modes of analysis available in the Elastic Stack, including search, drill-down and pivoting, data visualization, machine learning-based anomaly detection, and alerting. When fully adopted, users can search with the power of both unstructured and structured query parameters. ECS also streamlines your ability to automatically correlate data from different data sources, whether just different devices from a single vendor or entirely different data source types.
ECS also reduces the amount of time your team spends developing analytics content. Instead of creating new searches and dashboards each time your organization adds a new data source, you’ll be able to continue leveraging your existing searches and dashboards. ECS will also make it far easier for your environment to adopt analytics content directly from other parties that use ECS, whether Elastic, a partner, or an open source project.
When performing interactive analysis, ECS makes it easier to remember commonly used field names because there is only one set, not a different set for each data source. Deducing forgotten field names is also easier with ECS because (with only a few exceptions) the specification follows a simple and standard naming convention.
Don’t want to begin adopting ECS? No problem — it’s here when you need it but not required when you don’t.
Getting Started with the Elastic Common Schema
ECS is available for your review via a public GitHub repo. The specification is currently in Beta2 and is slated to move into General Availability soon. It is published under the Apache 2.0 open source license, enabling universal adoption by the broader Elastic community.
Sounds automagical, right? Well, as with any schema, implementing ECS isn’t a trivial task. But if you’ve already configured an Elasticsearch index template and written a few transform functions with Logstash or Elasticsearch ingest node, you’ll have sense for what this entails. Future versions of Elastic Beats modules will produce ECS-formatted events by default, streamlining this part of the transition. The new system module for Auditbeat is the first of many.
You can learn more about ECS by viewing our Elastic Common Schema (ECS) webinar. In later blog posts, we’ll cover how to map your data to ECS (including fields that aren’t defined in the schema) and strategies to migrate to ECS.
Whatever your feedback on ECS, we hope to hear from you. You’re welcome to share your thoughts via a GitHub issue or to suggest code updates via the protocol outlined in the ECS Contribution Guide.
What’s Next for the Elastic Common Schema?
Over time, we expect alignment with ECS to become a best practice for many (if not all) logging, metrics, and APM use cases. We plan to continue investing in its ongoing development, including adding support for more use cases.
We are grateful to everyone who has contributed to the development of ECS — thank you for your help in ensuring its relevance to the diverse use cases of the broader Elastic community.