Migrating to Elastic Common Schema (ECS) in Beats environments
In February 2019 we introduced the Elastic Common Schema (ECS) with a corresponding blog post and webinar. To briefly recap: by defining a common set of fields and data types, ECS enables uniform search, visualization, and analysis of disparate data sources. This is a major advantage for heterogeneous environments comprised of diverse vendor standards where simultaneous use of similar-but-different data sources is frequent.
We also discussed how implementing ECS isn’t a trivial task. The fact is that in order to produce ECS-compatible events, many of the fields emitted by event sources must be copied or renamed during the data ingestion process.
We closed our introduction to ECS by mentioning that if you’ve already configured an Elasticsearch index template and written a few transform functions with Logstash or Elasticsearch ingest pipelines, you’d have a pretty good sense for what this entails. Depending on how you’ve designed your Elastic Stack data ingestion pipelines, the amount of work required to migrate your environment to ECS will vary. At one end of the spectrum, Beats and Beats modules will enable a curated migration to ECS. Beats 7 events are already in ECS format, and the only work remaining is bridging between existing analysis content and new ECS data. At the other end of the spectrum are all manners of custom pipelines that have been built by users.
In June we also hosted a webinar discussing how to migrate to ECS. This blog post builds on the discussion we had in this webinar, and explores in more detail the migration to ECS within Beats environments. Migrating custom data ingestion pipelines to ECS will be covered in a future blog post.
Here's a look at what's covered in this blog post:
- Migration to ECS with Elastic Stack 7
- Conceptual overview of a migration to ECS
- Overview of migrating a Beats environment to ECS
- Build your own migration strategy
- Example migration
- Conclusion
- References
Migration to ECS with Elastic Stack 7
Realizing that changing the names of many event fields used by Beats would be a breaking change for users, we introduced ECS field names in our latest major release, the Elastic Stack version 7.
This post starts with a high-level overview of migrating to ECS with Beats in the context of an upgrade from Elastic Stack 6.8 to 7.2. We will then follow up with a step-by-step migration example of one Beats event source.
It’s important to note that this blog post will only cover one part of a migration to version 7. As our stack upgrade guidelines suggest, Beats should be upgraded after Elasticsearch and Kibana. The migration example in this blog post will therefore only cover upgrading Beats, and will assume Elasticsearch and Kibana are already upgraded to version 7. This will let us focus on the specifics of upgrading Beats from the pre-ECS schema to ECS.
When you plan your Elastic Stack 7 migration, make sure to review the aforementioned guidelines, look at the Kibana upgrade assistant, and, of course, carefully review the upgrade notes and breaking changes for any part of the stack you’re using.
Note: if you’re considering adopting Beats and have no data from Beats 6, you don’t need to worry about migration. You can simply start using Beats version 7.0 or later, which produce ECS-formatted events right out of the box.
Conceptual overview of a migration to ECS
Any migration to ECS will involve the following steps:
- Translate your data sources to ECS
- Resolve differences and conflicts between the pre-ECS event format and ECS events
- Adjust analysis content, pipelines, and applications to consume ECS events
- Make pre-ECS events compatible with ECS to smooth the transition
- Remove field aliases once all sources have been migrated to ECS
In this blog post, we will discuss each of these steps specifically in the context of migrating a Beats environment to ECS.
After the overview below, we will go through a step-by-step example of upgrading one Filebeat module from 6.8 to 7.2. This example migration is designed to make it easy for you to follow along on your workstation, perform each part of the migration, and experiment along the way.
Overview of migrating a Beats environment to ECS
There are many ways to address each part of the migration outlined above. Let’s go over each in the context of migrating your Beats events to ECS.
Translate data sources to ECS
Beats comes with many curated event sources. Starting with Beats 7.0, each of them have been converted to ECS format for you already. The Beats processors that add metadata to your events (like add_host_metadata) are also converted to ECS.
However it’s important to understand that Beats sometimes acts as a simple transport for your events. Examples of this are events collected by Winlogbeat and Journalbeat, as well as any Filebeat inputs through which you consume custom logs and events (other than Filebeat modules themselves). You will need to map each custom event source you are currently collecting and parsing on your own to ECS.
Resolve schema differences and conflicts
The nature of this migration to ECS is to standardize field names across many data sources. This means many fields are being renamed.
Field renames and field aliases
There's a few ways to work with pre-ECS and ECS events during the transition between the two formats. Here are the main options:
- Use Elasticsearch field aliases so the new indices recognize the old field names
- Duplicate data in the same event (populating both old fields and ECS fields)
- Do nothing: old content works only on old data, new content works only on new data
The simplest and most cost-efficient approach is to use Elasticsearch field aliases. This is the migration path that was chosen for the Beats upgrade procedure.
Field aliases have some limitations and are not a perfect solution, however. Let's discuss what they do for us, as well as their limitations.
Field aliases are simply additional fields in the Elasticsearch mapping of new indices. They allow the new indices to respond to queries using the old field names. Let's look at an example, simplified to display only one field:
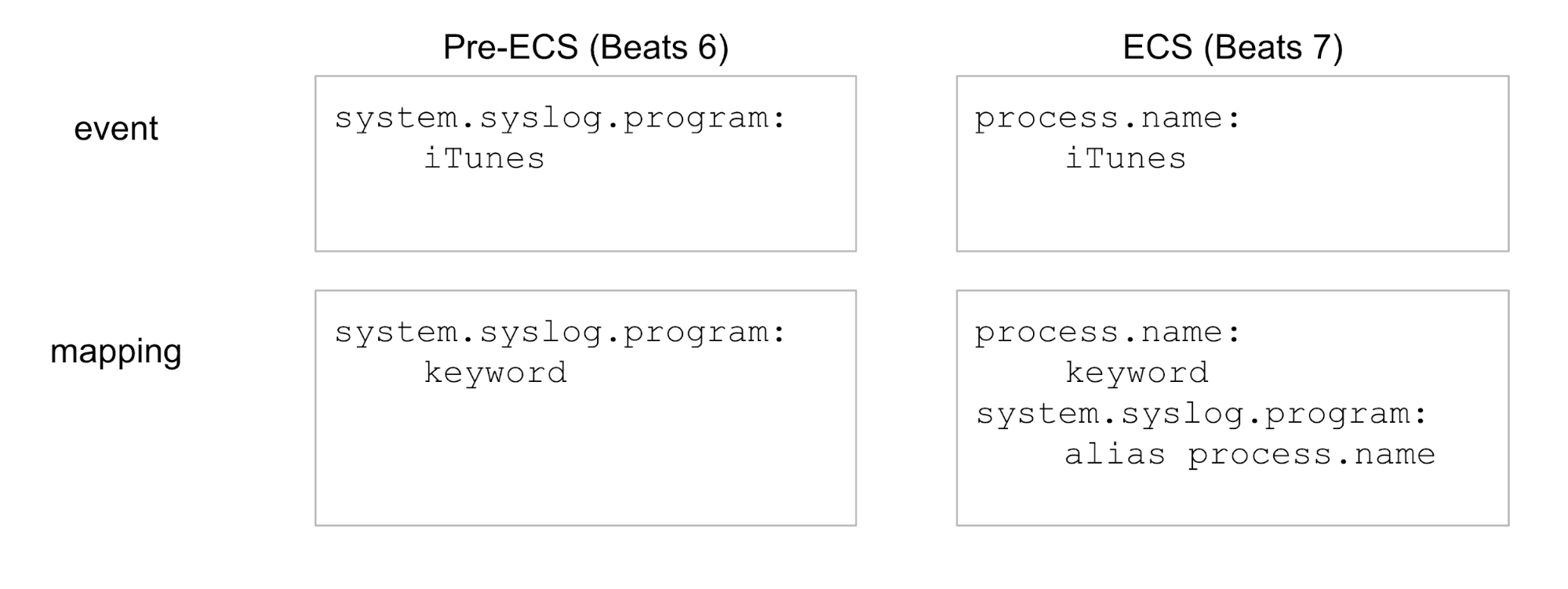
More precisely, field aliases will help with:
- Aggregations and visualizations on the alias field
- Filtering and searching on the alias field
- Auto-complete on the alias field
Here are the caveats of field aliases:
- Field aliases are purely a feature of Elasticsearch mappings (the search index). As such, they don’t modify the document source or its field names. The document is either comprised of the old field names or the new ones. To illustrate, here are some places where aliases do not help, because fields are accessed directly on the document:
- Columns displayed in saved searches
- Additional processing in your data ingestion pipeline
- Any application consuming your Beats events (e.g., via the Elasticsearch API)
- Since field aliases are field entries themselves, we cannot create aliases when there’s a new ECS field of the same name
- Field aliases only work with leaf fields — they cannot alias complex fields such as
objectfields, which contain other nested fields
These field aliases are not created by default in your Beats 7 indices. They must be enabled by setting migration.6_to_7.enabled: true in each Beat's YAML configuration file prior to running the Beats' setup step. This option and the corresponding aliases will be available for the lifetime of Elastic Stack 7.x, and will be removed in 8.0.
Conflicts
When migrating to ECS, you may also encounter field conflicts, depending on which sources you're using.
It's important to note that some types of conflicts are only detected for fields you're actually using. This means any changes or conflicts in sources you're not using will not affect you. But it also means that when planning your migration, you should ingest event samples from each of your data sources in both formats (Beats 6 and 7) within your test environment in order to uncover all the conflicts you will need to address.
Conflicts will come in two flavors:
- A field's data type is changing to a more appropriate type
- A field name in use prior to ECS is also defined in ECS, but has a different meaning; we'll call those incompatible fields
The exact consequences of each type of conflict will vary. But in general, when a field is changing data type or if an incompatible field is also changing with regards to nesting (e.g., keyword field becoming an object field), you will not be able to query the field across pre-ECS and ECS sources at the same time.
With data coming into your Beats 6 and 7 indices, refreshing your Kibana index patterns will reveal these conflicts. If after refreshing your index pattern you don't see a conflict warning, you have no conflicts left to resolve. If you get a warning, you can set the data type selector to display only the conflicts:

The way to handle these conflicts will be to reindex past data to make it more compatible with the new schema. Conflicts caused by type changes are pretty straightforward to resolve. You can simply overwrite your Beats 6 index patterns to use the more appropriate data type, reindex to a new index (for the updated mapping to take effect), then delete the old index.
If you have incompatible fields, you'll have to decide whether to delete or rename them. If you rename the field, make sure to define it in your index pattern first.
Adjust your environment to consume ECS events
With so many field names changing, the sample analysis content (e.g., dashboards) provided with Beats were all modified to use the new ECS field names. The new content will work only on ECS data produced by Beats 7.0 and later. Given this fact, Beats setup will not overwrite your existing Beats 6 content, but will instead create a second copy of each Kibana visualization. Each new Kibana visualization has the same name as previously, with “ECS” added at the end.
Beats 6 sample content and your custom content based on this old schema will mostly continue to work on Beats 6 and 7 data thanks to the field aliases. As we've previously discussed, however, field aliases are only a partial and temporary solution to help with migrating to ECS. Therefore, part of your migration should also include updating or duplicating your custom dashboards to start making use of the new field names.
Let's illustrate this with a table:
|
Pre-ECS (Beats 6, your custom dashboards) |
ECS (Beats 7) |
| [Filebeat System] Syslog dashboard | [Filebeat System] Syslog dashboard ECS |
|
|
In addition to reviewing and modifying analysis content in Kibana, you will also need to review any custom part of your event pipeline as well as applications accessing Beats events via the Elasticsearch API.
Make pre-ECS events compatible with ECS
We've already discussed using reindexing to address data type conflicts and incompatible fields. Reindexing to address these two types of changes is optional, but pretty straightforward to implement and therefore likely to be worth doing in most cases. Ignoring conflicts can be a viable solution as well for simple use cases, but please be aware that potential field conflicts will affect you from the moment you start ingesting Beats 7 data to the moment Beats 6 ages out of your cluster.
Reindexing
If the support provided by field aliases is not enough for your situation, you can also reindex past data to backfill ECS field names in your Beats 6 data. This ensures all new analysis content that depends on ECS fields (new Beats 7 content and your updated custom content) will be able to query over your old data in addition to the Beats 7 data.
Modifying events during data ingestion
If you're expecting a long rollout period for the Beats 7 agents, you can go beyond simply reindexing past indices. You can also modify incoming Beats 6 events during data ingestion.
There are a few ways to reindex and perform document manipulations such as copying, deleting, or renaming fields. The most straightforward way is to use Elasticsearch ingest pipelines. Here are a few advantages:
- They are easy to test with the _simulate API
- You can use the pipeline to reindex past indices
- You can use the pipeline to modify Beats 6 events still coming in
To modify events as they’re coming in, in most cases you simply need to configure your Elasticsearch output’s “pipeline” setting to send to your pipeline. This is true for Logstash and Beats.
Note that Filebeat modules use ingest pipelines already to perform their parsing. It’s possible to modify these as well, you only need to overwrite the Filebeat 6 pipelines and add a callout to your adjustment pipeline.
Remove field aliases
Once you no longer need the field aliases, you should consider removing them. We've already mentioned they are more lightweight than duplicating all data. However, they still consume memory in your cluster state — a critical resource. They also appear in Kibana auto-complete, busying things up unnecessarily.
To remove your old field aliases, simply remove (or set to false) the migration.6_to_7.enabled setting from your Beats config (e.g. filebeat.yml), perform the "setup" operation again, and overwrite the template.
Note that once the templates have been overwritten to no longer include aliases, you still have to wait for your indices to rollover before your index mappings stop containing the aliases. Then, when indices have rolled over, you need to wait for your Beats 7 data that contained the aliases to age out of your cluster before they are completely gone.
Build your own migration strategy
We've reviewed what Beats provides to help with the migration of your Beats data to ECS. We've also discussed additional steps you can take to make your migration more seamless.
You should evaluate the work required for each of your data sources independently. You may have the option to do less for your least critical data sources.
Here are a few criteria you can consider when looking at each data source:
- What is your retention period, and is it mandated externally? Do you have the option of dropping data earlier during this migration?
- Do you require continuity in your data? Or can you have a cutover? This will help inform whether you need to backfill, as described above
- How long will your Beats 7 rollout take? Do you need to modify Beats 6 events as they come in?
If you plan on backfilling many fields, you should take a look at dev-tools/ecs-migration.yml in the Beats repository. This file lists all field changes for the Beats 6 to 7 migration.
Example migration
In the remainder of this blog post, we will show step by step how you can migrate to ECS by upgrading a Beat from 6.8 to 7.2, how aliases help and their limitations, how to resolve conflicts, how to reindex recent past data to help with the transition, and also how to modify Beats 6 events still coming in. In this example, we will use Filebeat’s Syslog module.
As we’ve already mentioned, this example will not cover a full upgrade of the Elastic Stack. We will assume Elasticsearch and Kibana are already upgraded to version 7, and thus be able to focus on how to work through the upgrade of the data schema to ECS.
If you want to follow along, please use the most recent version of Elasticsearch 7 and Kibana 7. You can either use a free trial Elastic Cloud account or run them locally by following install instructions for Elasticsearch and Kibana.
Running Beats 6.8
In this demo, we’ll be running Filebeat 6.8 and 7.2 at the same time on the same machine. It is therefore important to install both with an archive installation (using the .zip or .tar.gz). Archive installations are self-contained to their directory and will make the process easy.
With Elasticsearch and Kibana 7 running, install Filebeat 6.8. If you’re on Windows, you can experiment by installing Winlogbeat instead.
On most systems, Syslog uses the local time for its timestamps without specifying the timezone. We’ll configure Filebeat to add the timezone to each event via the add_locale processor, then we’ll configure the system module’s pipeline to interpret the timestamp accordingly. This will ensure we can validate our ECS migration later when we look at events received recently.
In filebeat.yml, find the “processors” section and add the add_locale processor. Below the processors section, add the following module configuration:
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_locale: ~
filebeat.modules:
- module: system
syslog:
var.convert_timezone: true
If you’re running Elasticsearch and Kibana locally, the above should be enough. If you’re using Elastic Cloud, you’ll also need to add your cloud credentials to filebeat.yml — both can be found in Elastic Cloud when creating a cluster:
cloud.id: 'my-cluster-name:a-very-long-string....' cloud.auth: 'username:password'
Now let’s get Filebeat 6.8 ready to capture system logs:
./filebeat setup -e ./filebeat -e
Let’s confirm data is coming in by looking at the dashboard called [Filebeat System] Syslog dashboard. We should see the most recent Syslog events generated on the system on which filebeat was installed.
This dashboard is interesting because it includes visualizations and a saved search. This will be useful in demonstrating what field aliases can do for us and what they can't.
Running Beats 7 (ECS)
Let’s face it: not all environments can do an instantaneous cutover from one version of Beats to another. Events will likely be coming in from Filebeat 6 and 7 simultaneously for a period of time. So let’s do exactly the same in this example.
To accomplish this, we can simply run Filebeat 7.2 alongside 6.8 on the same system. We’ll extract Filebeat 7.2 in a different directory, and apply the same configuration changes we applied on 6.8.
But don’t run setup yet! For Beats 7, we also need to enable the migration setting, which creates field aliases. Uncomment this line at the very end of filebeat.yml:
migration.6_to_7.enabled: true
Our 7.2 configuration file should now contain this additional migration attribute, the add_locale processor, the config for the system module, and, if needed, our cloud credentials.
Let’s get Filebeat 7.2 going from a different terminal:
./filebeat setup -e ./filebeat -e
Conflicts
Before looking at the dashboards, let’s go straightaway to Kibana index management to confirm that the new index was created and that data is coming in. You should see something like this:
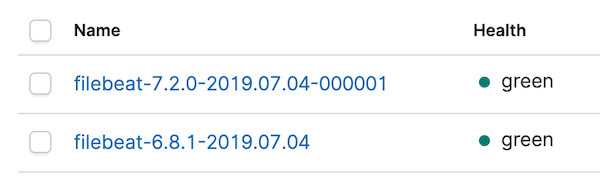
Let’s also go to index patterns and refresh the filebeat-* index pattern. With the index pattern refreshed for 6.8 and 7.2 data, there should be a few conflicts. We can focus on the conflicts by changing the data type selector on the right from All field types to conflict:
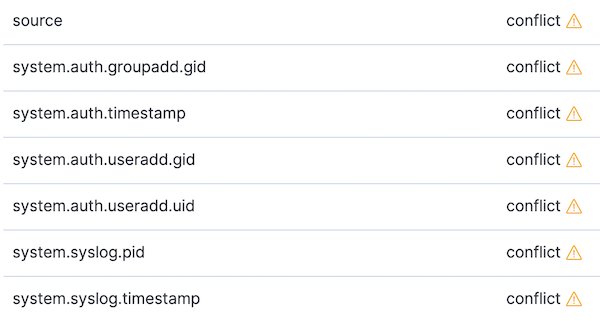
Let’s take a look at two of the conflicts above, and explore how they can be addressed.
First, let’s look at a syslog-specific conflict: system.syslog.pid. Going to the index management page and looking at the mapping for 6.8, we can see the field is indexed as keyword. If we look at the 7.2 index mapping, we can see system.syslog.pid is an alias to process.pid. This is fine; it isn’t the cause of the conflict. However, following the alias and looking at the datatype for process.pid, we can see its datatype is now long. The move from keyword to long has caused our data type conflict.
Second, let’s look at a conflict caused by an incompatible field. This one will be common to all Filebeat migrations: the source field. In Filebeat 6, source is a keyword field that usually contains a file path (or sometimes a syslog source address). In ECS and thus Filebeat 7 field mappings, source becomes an object with nested fields used to describe the source of a network event (source.ip, source.port, etc.). Since a field named source still exists in Beats 7, we can’t create an alias field there.
We’ve identified two fields we can work on as part of our migration procedure. We’ll get back to them in a moment.
Aliases
Let’s keep our Beats 6 [Filebeat System] Syslog dashboard open. Since the filebeat-* index pattern has changed since first loading this dashboard, let’s do a full page reload with Command-R or F5.
From a new tab, let’s open the new dashboard [Filebeat System] Syslog dashboard ECS.
Looking at the saved search at the bottom of the 6.8 dashboard, we can see gaps in data. Some events have values for system.syslog.program and system.syslog.message, and some don’t. Opening up those with empty values, we can see that they are the same Syslog events being picked up by 7.2, but with different field names. Looking at the same period in the tab with the ECS dashboard, we can see the same behavior in reverse. ECS fields process.name and message are filled out for 7.2 events, but not for 6.8 events.
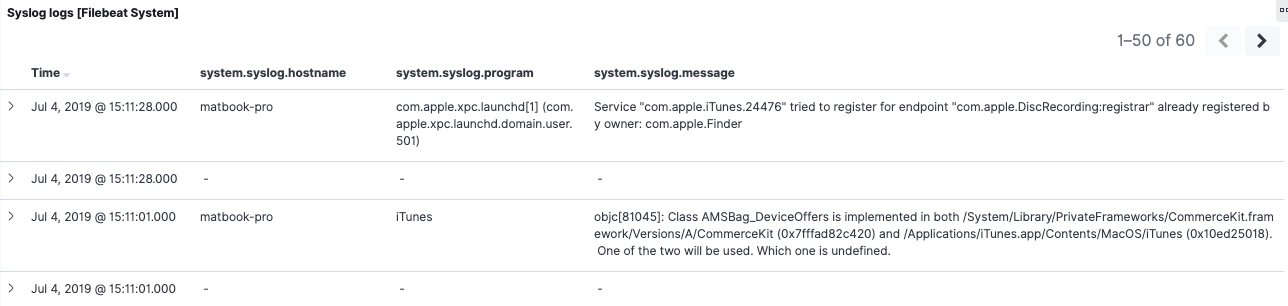
This is one concrete way in which field aliases do not help us. Saved searches rely on the content of the document — not on the index mapping. As we’ve already mentioned in the overview, if you need continuity, reindexing to backfill (and changing events as they come in) will address this. We will be doing that shortly.
Now let’s see where field aliases do help us. Look at the donut visualization in the 6.8 dashboard and hover over the outer ring, which displays the values for system.syslog.program:
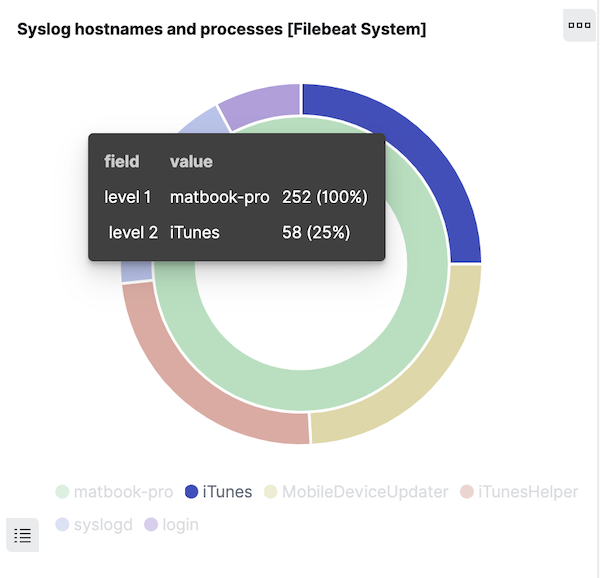
Click on a section of the ring to filter for the messages generated by one program. Let’s only select the filter on the program name:
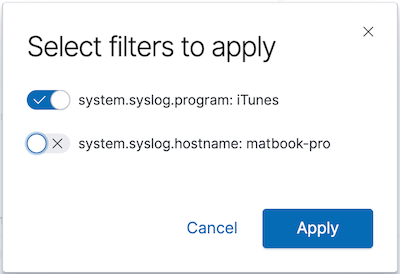
We’ve just added a filter on a field that’s no longer present in 7.2 — system.syslog.program. Yet we can still see both sets of messages in the saved search:
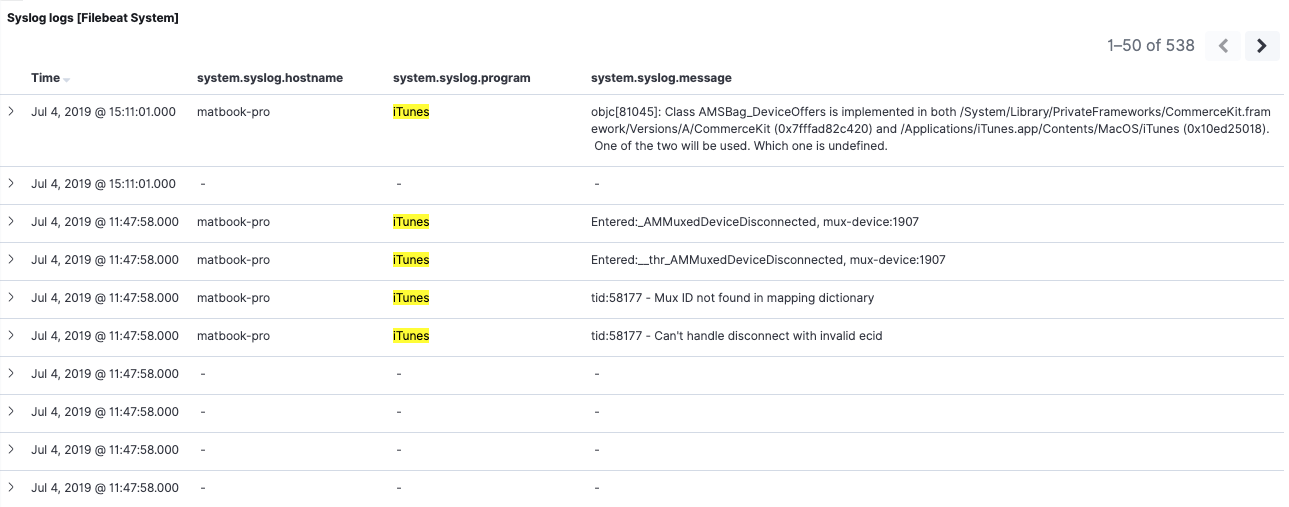
If we inspect the 7.2 elements, we can see that the filter was applied successfully to those as well. This confirms that our filter on system.syslog.program works with our 7.2 data, thanks to the system.syslog.program alias.
Note that the visualization — backed by an Elasticsearch aggregation — is also correctly displaying results for both 6.8 and 7.2 on the migrated system.syslog.program field.
Going back to the 7.2 dashboard, with no filters active, we can see both 6.8 and 7.2 data. If we apply the same filter as we did on 6.8, however, we’ll see a different behavior. Filtering for process.name:iTunes now only returns 7.2 events. The reason is that the 6.8 indices don’t have a field named process.name, nor an alias of that name.
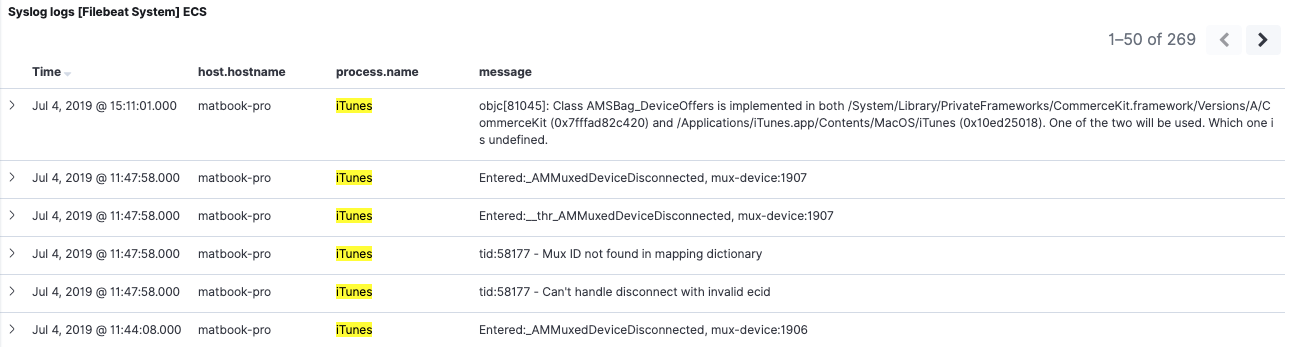
Reindexing for a smooth migration
We’ve discussed how reindexing can help address 3 different aspects of the migration: resolving data type conflicts, resolving incompatible fields, and backfilling ECS fields to preserve continuity. Let’s now go through one example of each.
Here’s how we will modify our Beats 6 data:
- Data type conflict: change the data type for system.syslog.pid from keyword to long
- Incompatible field: Delete Filebeat’s source field after copying its content to log.file.path. This will eliminate the conflict with ECS’ source field set. Note that Beats 6.6 and higher already populates log.file.path with the same value … but that’s not the case for earlier versions of Beats 6, so we will conditionally copy it.
- Backfill the ECS field process.name with the value of system.syslog.process.
Here’s how we will perform these changes:
- We will modify the Filebeat 6.8 index template to use the new data types, and add and remove field definitions
- We will create a new ingest pipeline that modifies 6.8 events by removing or copying fields
- We will test the pipeline with the _simulate API
- We will use the pipeline to reindex past data
- We will also append a call to this new pipeline at the end of the Filebeat 6.8 ingest pipeline in order to modify events as they come in
Index template changes
Datatype improvements need to be performed in the index template, and will take effect when the index rolls over. By default, it rolls over the next day. If you’re using Index Lifecycle Management (ILM) in 6.8, you can force a rollover with the rollover API.
Display the current index template from Kibana Dev Tools:
GET _template/filebeat-6.8.1
Index templates can’t be modified — they have to be overwritten completely (documentation). Prepare a PUT API call with the entire index template while adjusting a few things in it:
- Remove the definition for source (all lines that start with
-below) - Add a field definition for program.name
- Change the type of the field system.syslog.pid to long
PUT _template/filebeat-6.8.1
{
"order" : 1,
"index_patterns" : [
"filebeat-6.8.1-*"
]
...
"mappings": {
"properties" : {
- "source" : {
- "ignore_above" : 1024,
- "type" : "keyword"
- },
"program" : {
"properties" : {
"name": {
"type": "keyword",
"ignore_above": 1024
}
}
},
"system" : {
"properties" : {
"syslog": {
"properties" : {
"pid" : {
"type" : "long"
}
...
}
Once the body of the API call is ready, execute it to overwrite the index template. If you plan to backfill a lot of ECS fields, check out the sample ECS Elasticsearch templates in the ECS git repository.
Reindexing
The next step is writing a new ingest pipeline to modify our Beats 6.8 events. For our example, we will copy system.syslog.program to process.name, copy source to log.file.path (unless it’s already populated), and remove the source field:
PUT _ingest/pipeline/filebeat-system-6-to-7
{ "description": "Pipeline to modify Filebeat 6 system module documents to better match ECS",
"processors": [
{ "set": {
"field": "process.name",
"value": "{{system.syslog.program}}",
"if": "ctx.system?.syslog?.program != null"
}},
{ "set": {
"field": "log.file.path",
"value": "{{source}}",
"if": "ctx.containsKey('source') && ctx.log?.file?.path == null"
}},
{ "remove": {
"field": "source"
}}
],
"on_failure": [
{ "set": {
"field": "error.message",
"value": "{{ _ingest.on_failure_message }}"
}}
]
}
Learn more about ingest pipelines, and the Painless language (used in the if clauses).
We can test out this pipeline with the _simulate API using fully populated events, but here’s a more minimalistic test that fits better in a blog post. You’ll notice one event has log.file.path filled already (Beats 6.6 and later) and one that doesn’t (6.5 and before):
POST _ingest/pipeline/filebeat-system-6-to-7/_simulate
{ "docs":
[ { "_source": {
"log": { "file": { "path": "/var/log/system.log" } },
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}},
{ "_source": {
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}}
]
}
The API call’s response contains the two modified events. We can confirm our pipeline worked because the source field is gone, and both events have its value stored at log.file.path.
We can now perform our reindex on indices that are no longer receiving writes (e.g., yesterday’s index and before) using this ingest pipeline for every Filebeat index we’re migrating. Make sure to read the _reindex docs to understand how to reindex in the background, throttle your reindexing operation, etc. Here’s a simple reindex that will do for the few events we have:
POST _reindex
{ "source": { "index": "filebeat-6.8.1-2019.07.04" },
"dest": {
"index": "filebeat-6.8.1-2019.07.04-migrated",
"pipeline": "filebeat-system-6-to-7"
}}
If you’re following along and only have today’s index, feel free to try the API call anyway and inspect the migrated index’ mapping. But don’t delete today’s index afterwards, it will just get re-created because Filebeat 6.8 is still sending data.
Otherwise, once inactive indices have been reindexed, we can confirm the new indices have all the fixes we want, then delete the old indices.
Modifying incoming events
Most Beats can be configured to send directly to an ingest pipeline in their Elasticsearch output (same is true for Logstash’s Elasticsearch output). Since we’re playing with a Filebeat module in this demo — which already uses ingest pipelines — we’ll have to modify the module’s pipeline instead.
The ingest pipeline installed by Filebeat 6.8’s setup to process is called filebeat-6.8.1-system-syslog-pipeline. All we need to do here is add a callout to our own pipeline at the end of the Filebeat Syslog pipeline.
We’ll display the pipeline we’re about to modify:
GET _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
Next, we’ll prepare the API call to overwrite the pipeline by pasting the full pipeline below the PUT API call. Then we will add a “pipeline” processor at the end, to call our new pipeline:
PUT _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
{ "description" : "Pipeline for parsing Syslog messages.",
"processors" :
[
{ "grok" : { ... }
...
{ "pipeline": { "name": "filebeat-system-6-to-7" } }
],
"on_failure" : [
{ ... }
]
}
After executing this API call, all events coming in will be modified to better match ECS, prior to being indexed.
Finally, we can use _update_by_query to modify documents in the live index from just before we modified the pipeline. We can confirm documents that still need updating by looking for those that still have the source field:
GET filebeat-6.8.1-*/_search
{ "query": { "exists": { "field": "source" }}}
And we reindex only those:
POST filebeat-6.8.1-*/_update_by_query?pipeline=filebeat-system-6-to-7
{ "query": { "exists": { "field": "source" }}}
Verifying conflicts
Once all indices with conflicts are deleted, only the reindexed ones are left. We can refresh the index pattern to confirm that the conflicts are gone. We can go back to our Filebeat 7 dashboard and see that our 6.8 data within is now more usable thanks to our backfilling of the process.name field:
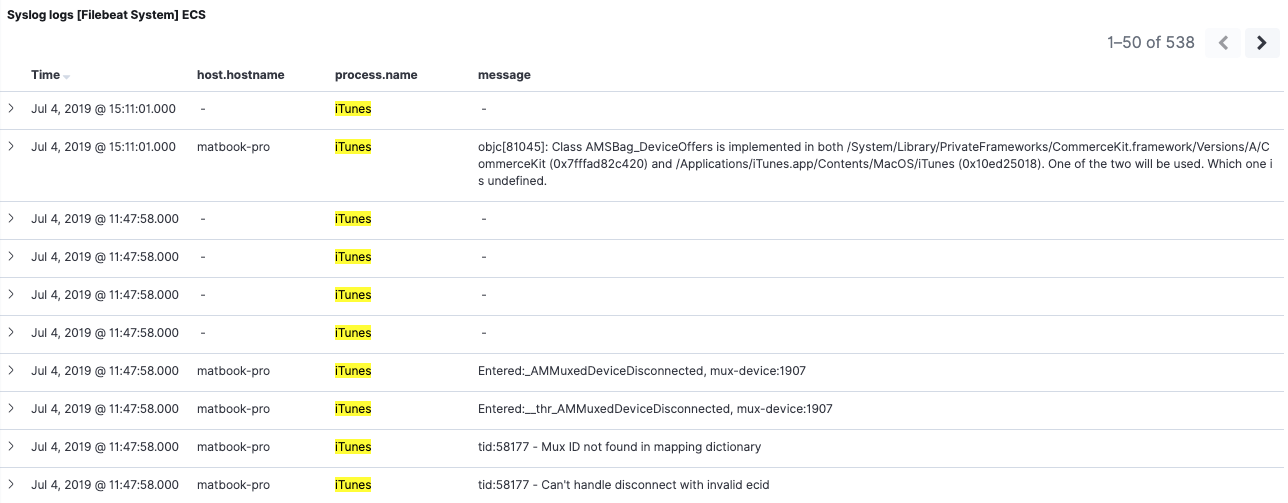
In our example we only backfilled one field. Of course you’re free to backfill as many fields as you need.
Cleanup after the migration
Your migration will likely involve modifying your custom dashboards and applications that are consuming Beats events via the API to use the new ECS field names.
Once you’re fully migrated to Beats 7 and field aliases are no longer being used, we can remove them to reap the memory-saving benefits discussed earlier. To remove the aliases, let’s remove the migration.6_to_7.enabled attribute from filebeat.yml to then overwrite the Filebeat 7.2 template with:
./filebeat setup --template -e -E 'setup.template.overwrite=true'
Just like the changes to the Filebeat 6.8 template earlier, the new template without aliases will take effect the next time the Filebeat 7.2 index rolls over.
Conclusion
In this article, we discussed the steps necessary to migrate your data to ECS in a Beats environment. We explored the benefits of the upgrade procedure, as well as its limitations. These limitations can be addressed by reindexing past data and even modifying current incoming Beats 6 data during the ingestion process.
After discussing the migration at a high-level, we performed a step-by-step example of upgrading Filebeat’s System module from 6.8 to 7.2. We looked at the differences between events from Filebeat 6.8 and 7.2, then walked through all the steps users can take to reindex past data — and modify it as it’s still coming in.
Introducing a schema inevitably has a big impact on existing installations, but we strongly believe this migration will be worth it. You can read why in Introducing the Elastic Common Schema and in Why Observability loves the Elastic Common Schema.
If your environment uses data ingestion pipelines other than Beats, stay tuned. We have another blog post planned where we will discuss how to migrate a custom ingestion pipeline to ECS.
If you have questions about ECS or need help with your Beats upgrade, head to the Discuss forums and tag your question with elastic-common-schema. You can learn more about ECS in our documentation and contribute to ECS on GitHub.
References
Documentation
- Upgrade Assistant
- Upgrading the Elastic Stack
- Breaking changes in 7.0
- Reindex
- Ingest pipeline
- Ingest pipeline’s simulate API
- Painless language
- Mappings and index templates
- File documenting all field changes: ecs-migration.yml
- Sample ECS Elasticsearch index templates
Blogs and videos
- Introducing ECS (blog)
- Introducing ECS (webinar)
- ECS: How to migrate your data (webinar)
- Why observability loves the Elastic Common Schema (blog)
- Upgrading the Elastic Stack with the 7.x Upgrade Assistant (blog)
General
- Ask questions about ECS in the Discuss forums and tag your question “elastic-common-schema”
- Official ECS documentation
- ECS Github repository