Improving the event queue in Elastic Agent and Beats
How internal improvements reduced memory use in Elastic 8.13


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In version 8.12, we introduced performance presets — a simpler way to tune Elastic Agent and Beats for a variety of scenarios. This improved performance for common environments without the fine-tuning that was often required in the past.
Starting with version 8.13, we focused on improving our internal libraries to better support these presets. The result was a rewrite of our internal event queue that brings reduced memory usage to all Beats.
In our internal benchmark suite, Filebeat 8.13 showed memory reductions of about 20% on all presets. In this post we'll look at how we achieved that.
The Beats event queue
Events received by Elastic Agent and Beats are stored in a queue while they’re being sent to the output. The queue’s configuration makes a big difference in how much memory is needed to store those events. Prior to 8.13, this configuration involved some easily misunderstood parameters that were a frequent source of misconfigurations.
Let's review some of those tuning parameters and their roles.
bulk_max_size and flush.min_events
When an output worker is ready to send data, it requests a batch of events from the internal queue. The size of this request is controlled by bulk_max_size, an important output tuning parameter. If bulk_max_size is 100, then the queue will try to provide 100 events for the output worker to send.
The queue also has a flush.timeout parameter. When this is zero, the queue will return the events immediately, even if it doesn't have enough. In our example, if 100 events are requested but there are only 50 in the queue, then the output worker will get 50 events. But when the flush timeout is positive, the queue will instead wait for up to the specified timeout to collect more events.
But hold on: let's say we set a flush timeout of 5 seconds and request 100 events. You might expect that the queue will return 100 events immediately if it has them or else it will delay for up to 5 seconds trying to get to 100. And starting in version 8.13, you'd be right. But that isn't how the old queue behaved! The queue didn’t wait to fill an output request — it waited to fill an internal queue buffer, which could be a completely different size.
The size of the internal queue buffers was controlled by flush.min_events, a parameter that looks very similar to bulk_max_size and is often confused for it but can have very different effects.
What problems can this cause?
Here are some performance problems in the old queue that are fixed by the changes in 8.13.
Example 1: Increased memory use
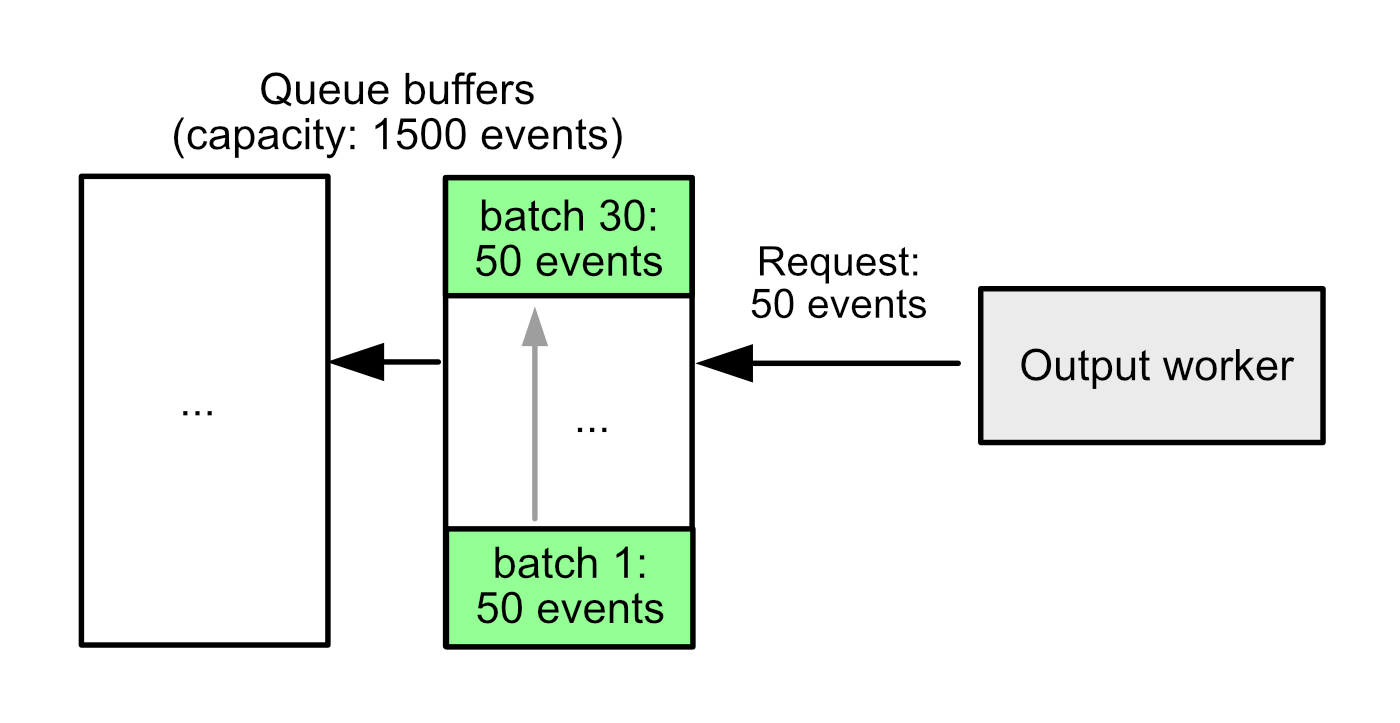
bulk_max_size: 50
flush.timeout: 10s
flush.min_events: 1500
The biggest problem is memory use. Before 8.13, the queue managed its memory a full buffer at a time. In this example configuration, a full buffer of events can provide 30 output batches of 50 events each. This means that we need to fully ingest 30 batches before we can free the memory from the very first one!
Example 2: Increased latency
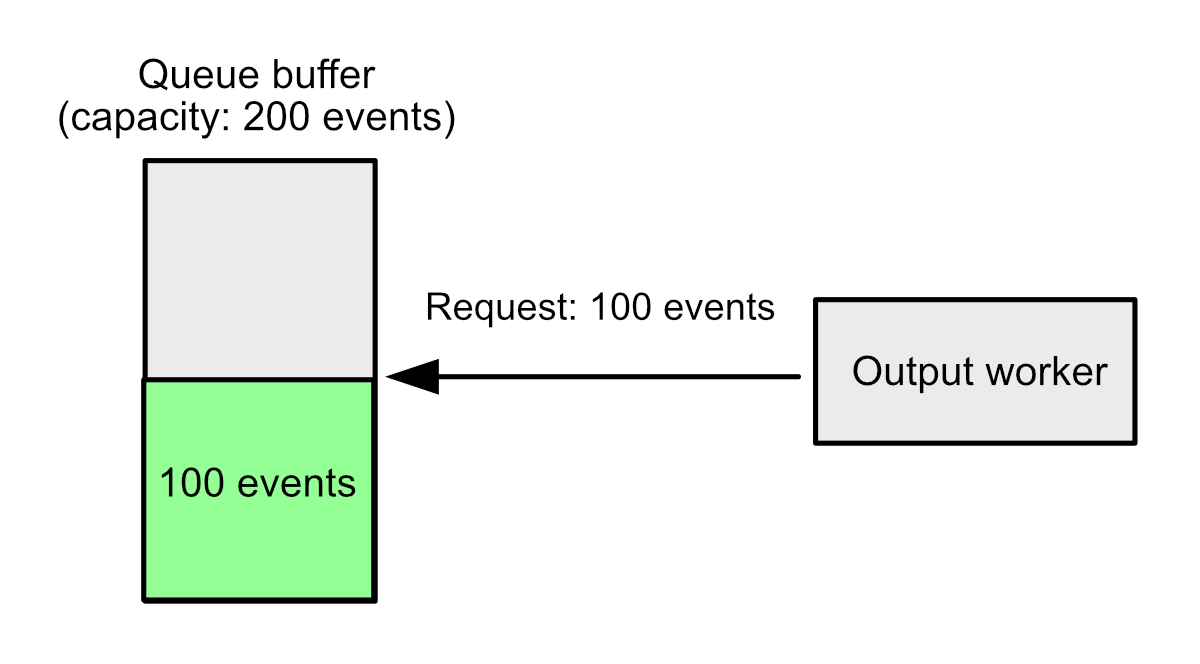
bulk_max_size: 100
flush.timeout: 5s
flush.min_events: 200
Suppose the output requests 100 events. The queue has 100 events, but it won't return anything until it fills a full buffer of 200 events. If more events don't come in, it will wait a full 5 seconds to return any events, even though the request could have been filled immediately.
This has always been a pitfall, but it became more serious in 8.12 when we increased the default flush.timeout from 1 second to 10. For most users, this gave better performance, since large event batches are more efficient to ingest. But users who had tuned their outputs with a low bulk_max_size saw increased latency, even though there should have been enough events to start ingesting immediately.
Example 3: Smaller event batches
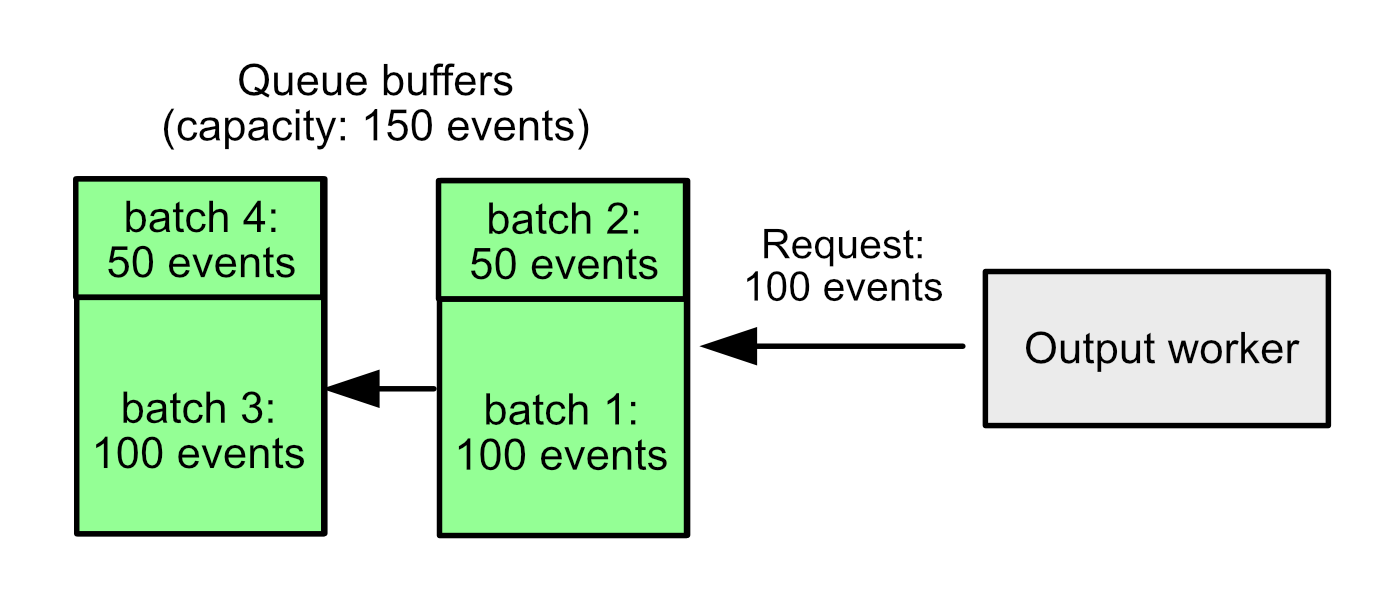
bulk_max_size: 100
flush.timeout: 1s
flush.min_events: 150
Here we have a queue with 300 events and an output that requests 100 events at a time. We should be able to send 300 events as three batches of 100 events each, but the queue’s buffer size is 150 events, and the queue only returns events from one buffer at a time. So, what happens instead is each buffer is split into two batches — one with 100 events and one with 50.
For most configurations, an output worker will occasionally get fewer events than it asked for even if more events are in the queue. This isn't enough to make a huge difference, but it slightly reduces efficiency and would be nice if we could return the right number of events every time.
What we did about it
We ended up rewriting the queue to remove the chain of internal buffers entirely. Instead, we now use a single fixed buffer, wrapping around the end as needed. Events are also copied out of this shared buffer to assemble output batches. flush.timeout now works exactly the way most people expected it to: the queue will immediately return the requested number of events if they're available or else it will wait up to the specified timeout to fill the request (but only the current request, not some larger internal limit!).
This refactor required a compromise that the original queue tried to avoid — event batches are no longer a single contiguous sequence in memory. But in exchange, we get huge benefits:
The memory problem in example one is gone. As soon as the output confirms a batch of events has been processed, the queue can release its memory no matter where it falls relative to other event batches.
The latency problem in example two is gone. If the queue has enough events, it will return them. It doesn't matter where they fall in the event sequence.
The batch size problem in example three is gone. Since events no longer need to come from a contiguous buffer, we don't need to split batches based on internal memory boundaries.
flush.min_events is now a legacy parameter which, for backwards compatibility, specifies a global maximum on the size of an event batch. If you're using a performance preset, you can ignore this parameter entirely, but custom queue configurations are now recommended to set it to a large value and use bulk_max_size to control batch size. As long as flush.min_events is large enough, there's no longer any performance advantage to changing it.
The results
In our internal benchmarks, we saw significant memory savings for all presets (these differences were measured with Filebeat using a filestream input on structured json events):
| Preset | Memory savings |
| balanced | 17% |
| throughput | 18% |
| scale | 18% |
| latency | 24% |
All presets also show a 3% reduction in the CPU cost per event.
The payoff of performance presets
By defining built-in presets for common performance goals, we took a lot of the guesswork out of configuring Elastic Agent and Beats. Now we're seeing the follow-up benefits, as this gives us a set of common configurations to target in our optimization work. Expect these improvements to continue in version 8.14 and beyond!
What else is new in Elastic 8.13? Check out the 8.13 announcement post to learn more >>
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print