ECE 2.0: Supercharge Your Use Case
We recently released Elastic Cloud Enterprise (ECE) 2.0 which includes a number of features that give you and your team additional flexibility in managing and scaling your Elastic fleet. This blog post highlights three use cases that take advantage of these new capabilities.
Before you begin
This blog post assumes you are already familiar with the new concepts introduced in ECE 2.0, which were covered in the release blog post. If you are unfamiliar with the features described below, we encourage you to spend a few minutes reading about them in our user guide before moving on.
- Allocator tags: key-value pairs that allow you to classify your hardware and later use this classification with instance configurations to match a specific component to the underlying hardware.
- Instance configurations: custom configuration that matches each Elastic component to an underlying set of allocators. For example: your Kibana instance, machine learning node, Elasticsearch data node, and so on.
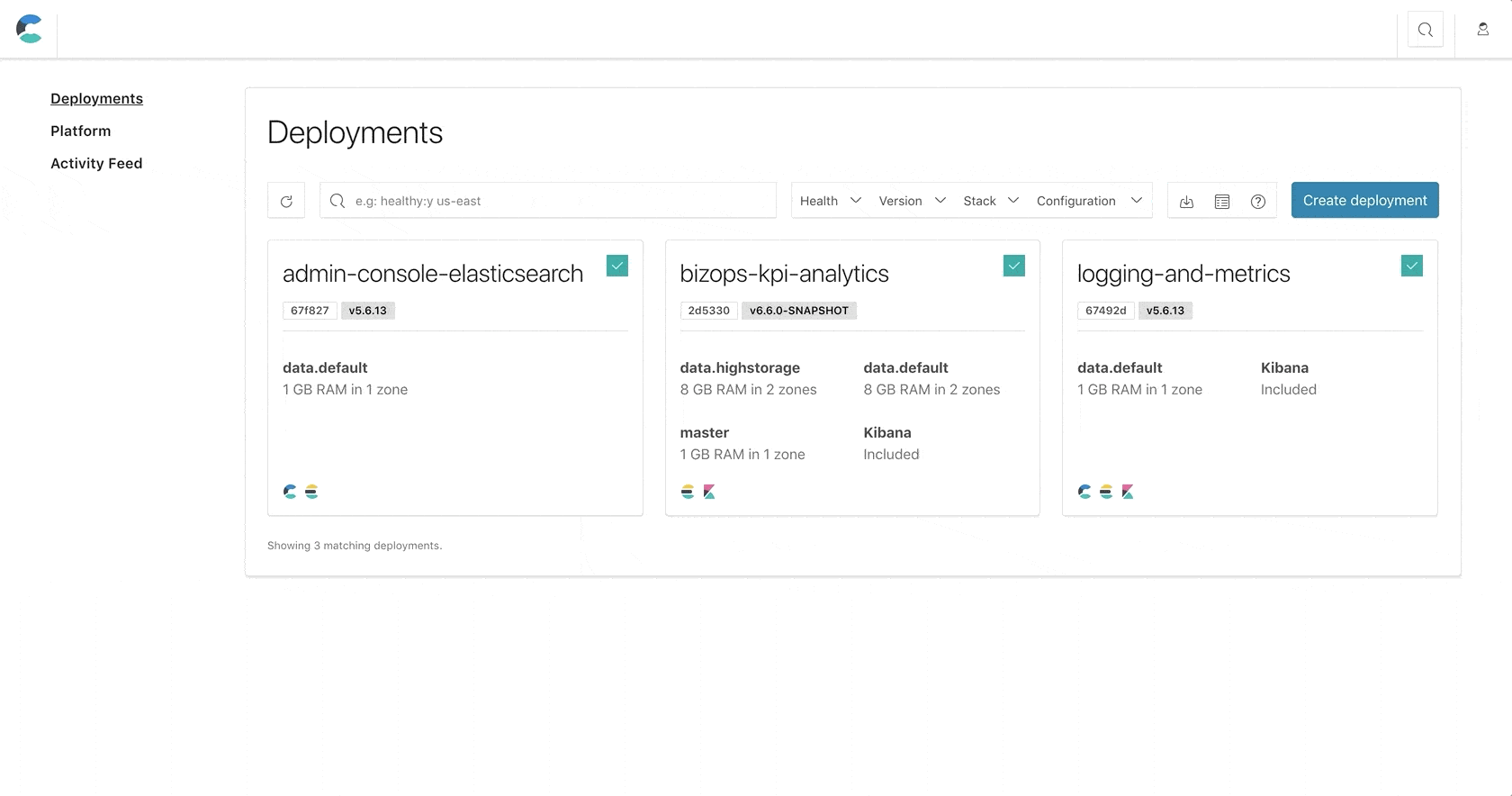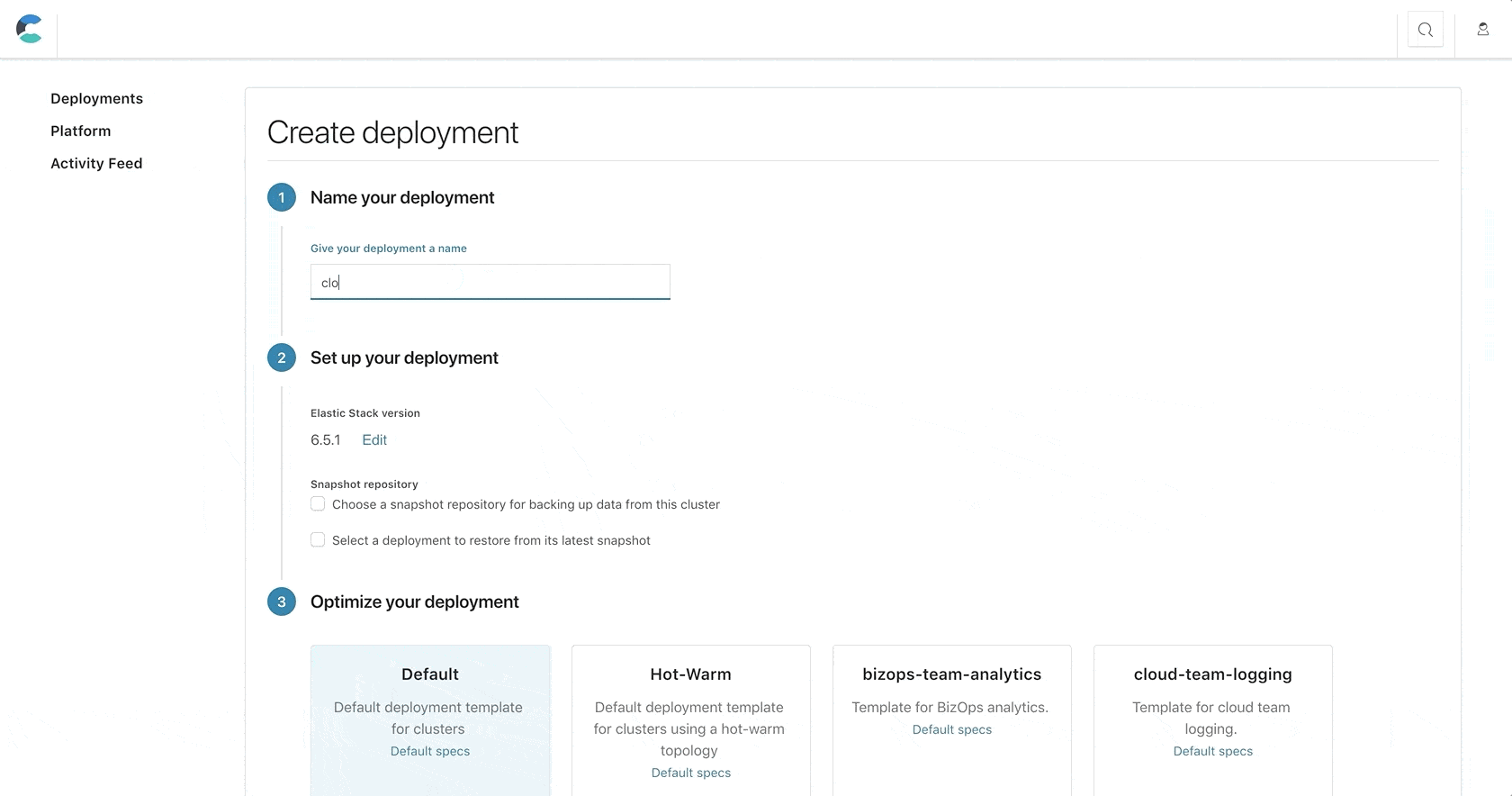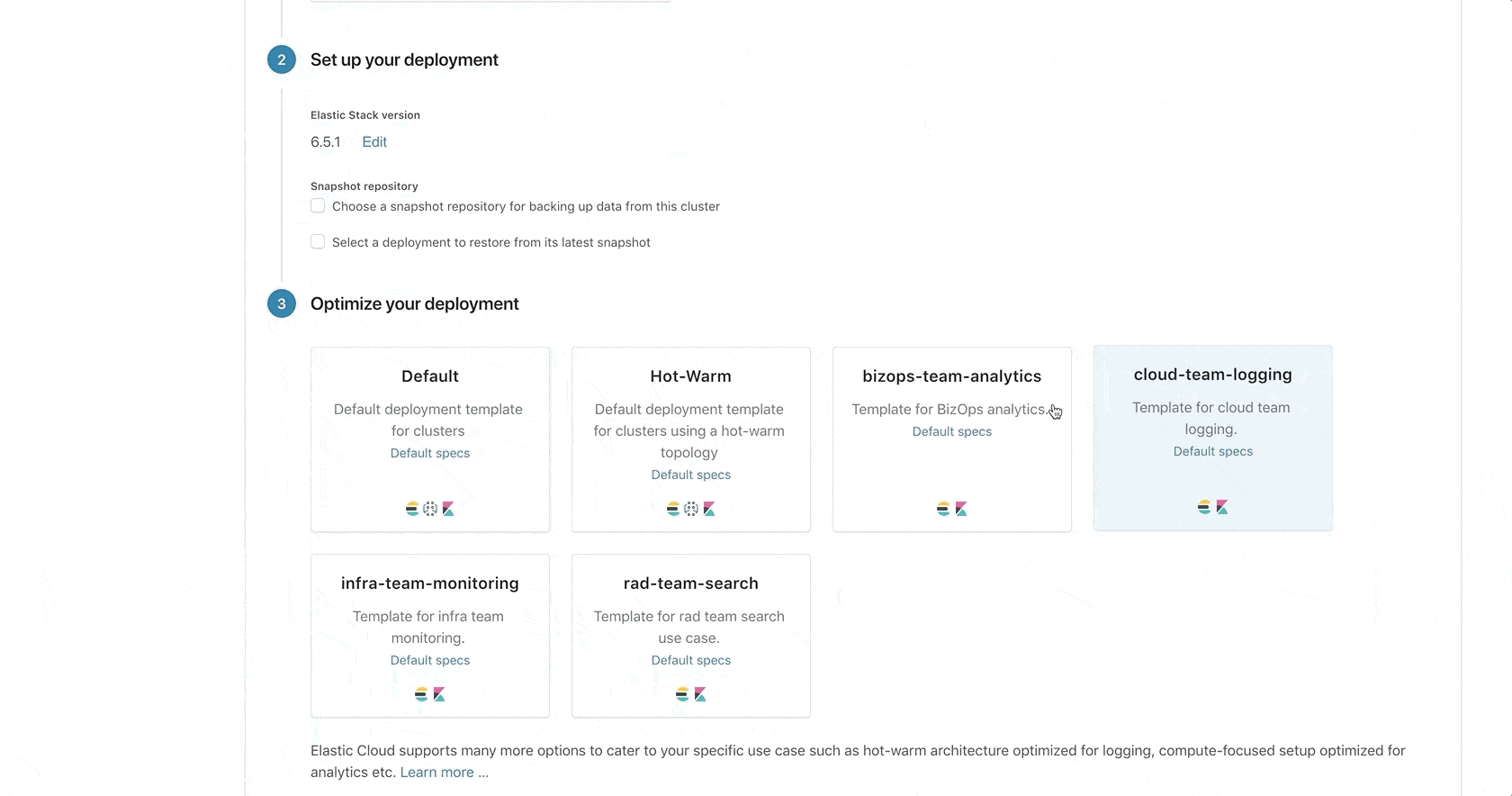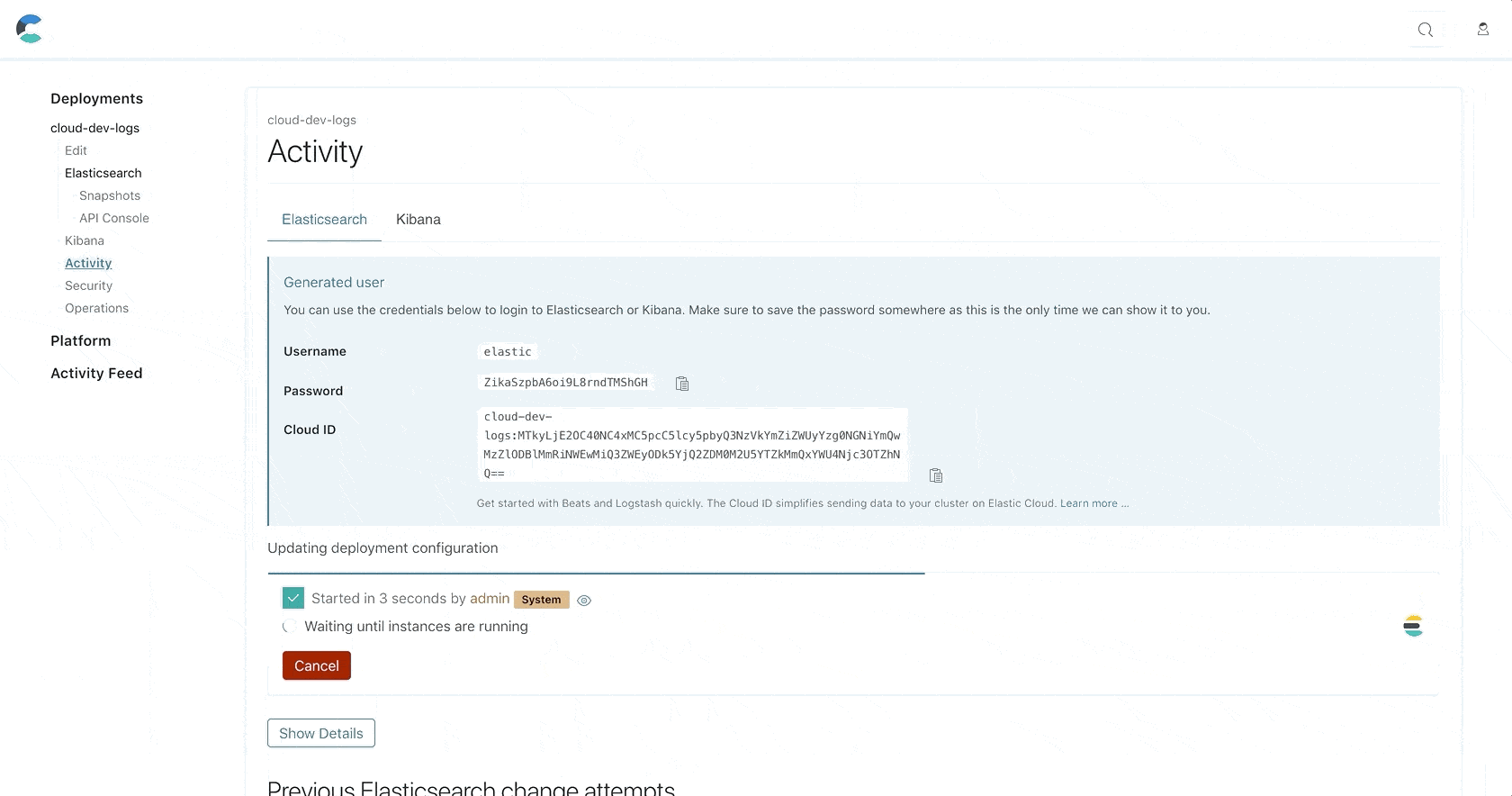
- Deployment templates: a set of instance configurations that will be used to provision a new deployment when a specific template is selected.
Using the right hardware for the right use case
The Elastic Stack can be used for search, logging, metrics, security analytics, and much more. In order to give you maximum performance it is important to use the right hardware for the specific use case. Thankfully you can use a combination of allocator tagging and instance configurations to help define RAM:Disk ratios and ensure you use the best hardware available for each use case when using ECE. If you are using Amazon Web Services or Google Compute Engine be sure to check out the configurations we use for those respective platforms with our Elasticsearch Service.
Logging
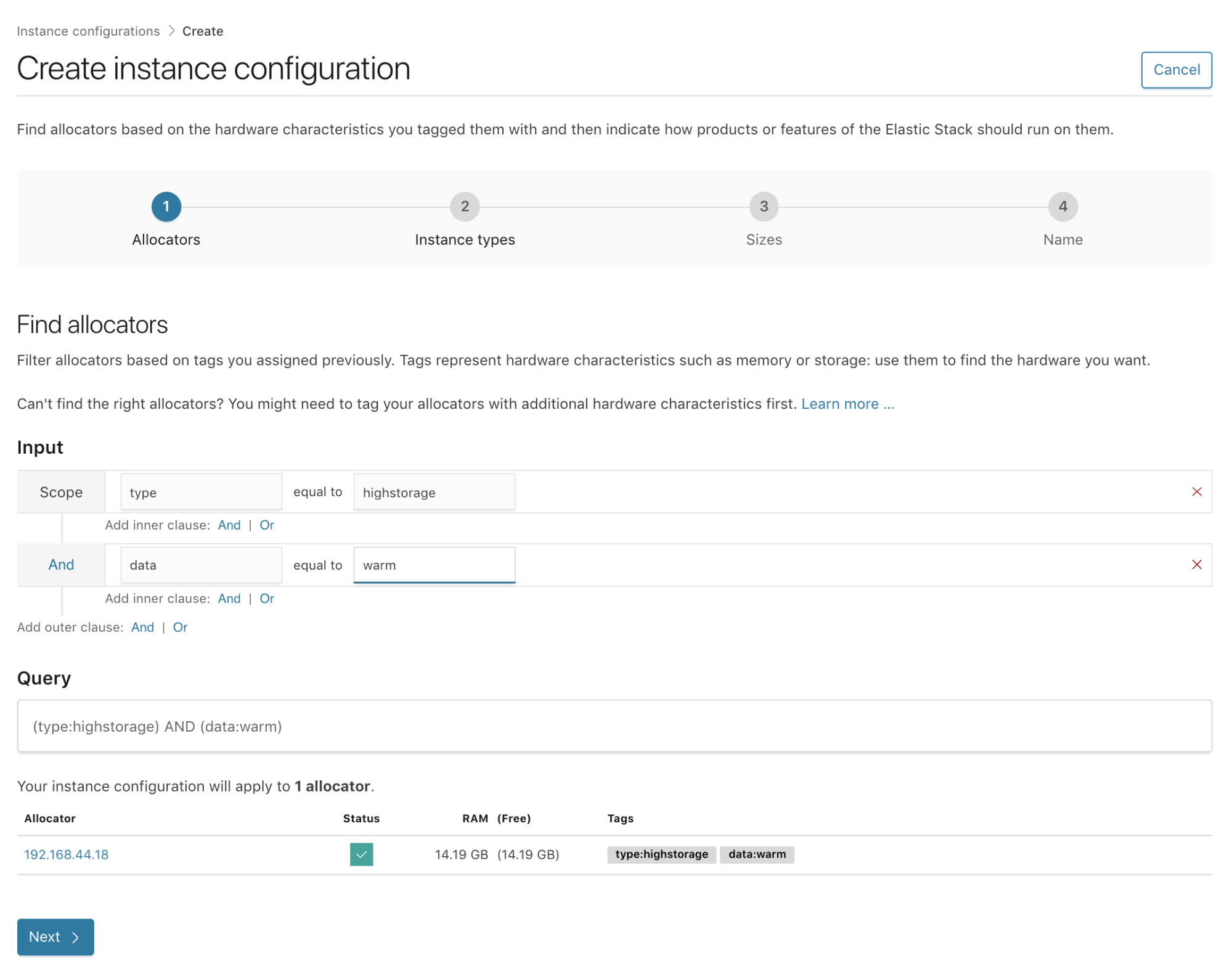
When building for logging use cases, there are several hardware types that will help you optimize costs without slowing down your ingestion rate or your searches for recent data. This is because we now allow you to configure a hot-warm architecture with a hot tier for ingestion of new data (which is searched more frequently) and a warm tier to retain data, that is less frequently queried, for longer retention period.
For the hot tier, we recommend using fast local storage with a smaller RAM:Disk ratio used in High IO hardware profile. In our Elasticsearch Service we use local NVMe SSD storage as well as a RAM:Disk ratio of 1:30. For the warm tier, we use a larger RAM:Disk ratio of around 1:100 with slower spinning disks that are normally used in a hardware profile optimized for storage.
In order to support this setup you can tag the relevant hosts meant to host the hot tier with tags like type:highio and hot:true, while the hosts dedicated for the warm nodes can be tagged with type:highstorage and warm:true.

Once tagged, create the relevant instance configurations — one to match the I/O optimized hosts, and one to match the storage optimized hosts. You are now ready to create your first hot-warm deployment template, or edit the one that we provide out-of-the-box by adding the relevant filters to the match the relevant hosts.
Node Types
Using different hardware for Kibana, dedicated master nodes, and ingest nodes
One of the most powerful features of ECE is the ability to configure different instance configurations based on different roles of your Elastic Stack deployment. One of the top tricks is to use servers that have a high capacity of memory for Kibana and dedicated master nodes, without having too much local storage. This means you can also use much smaller RAM:Disk ratios such as 1:4, or 1:8 for Kibana and dedicated master nodes, as neither use much storage.
On the ingest side of the deployment, you may want to prioritize for CPU depending on the number of pipelines and operations you have. You can once again have a low amount of storage for hosts running these instance configurations. CPU time is shared between deployments based on their relative RAM. For example, in a 256GB RAM and 16 Cores machine, a node with 32GB of RAM with get the same CPU ratio. In this case that’s 32 / 256 which is 12.5% of the CPU time shares.
In these example you can tag your allocators with something like the following:
- Allocators used for Kibana and master nodes:
type:highmem,kibana:true,master:true - Allocators used for Ingest nodes:
type:highcpu,ingest:true

Then, edit the preconfigured instance configuration or create new ones, applying the required allocators filters to ensure they will be deployed on the relevant hosts.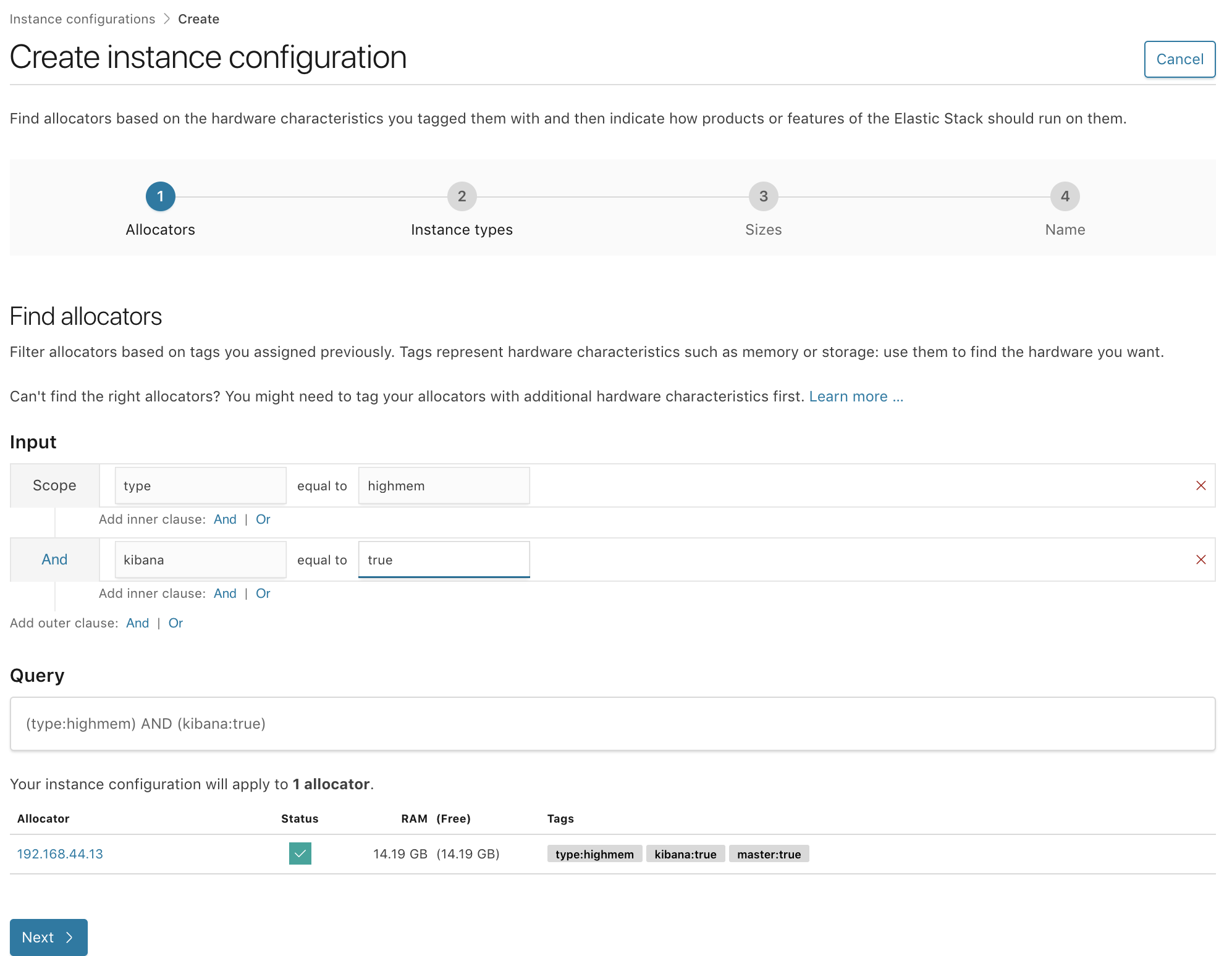
Not all environments are born equal
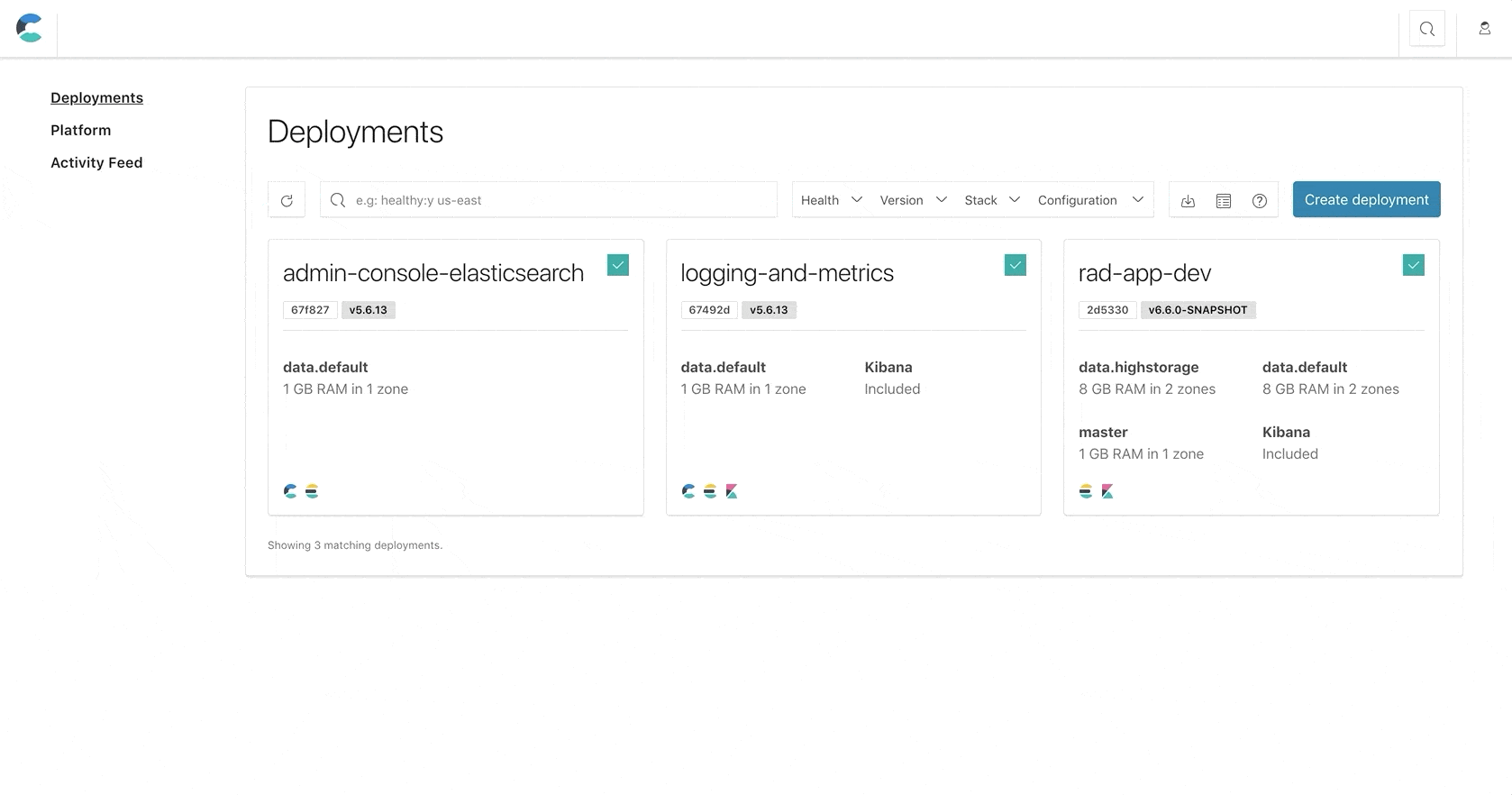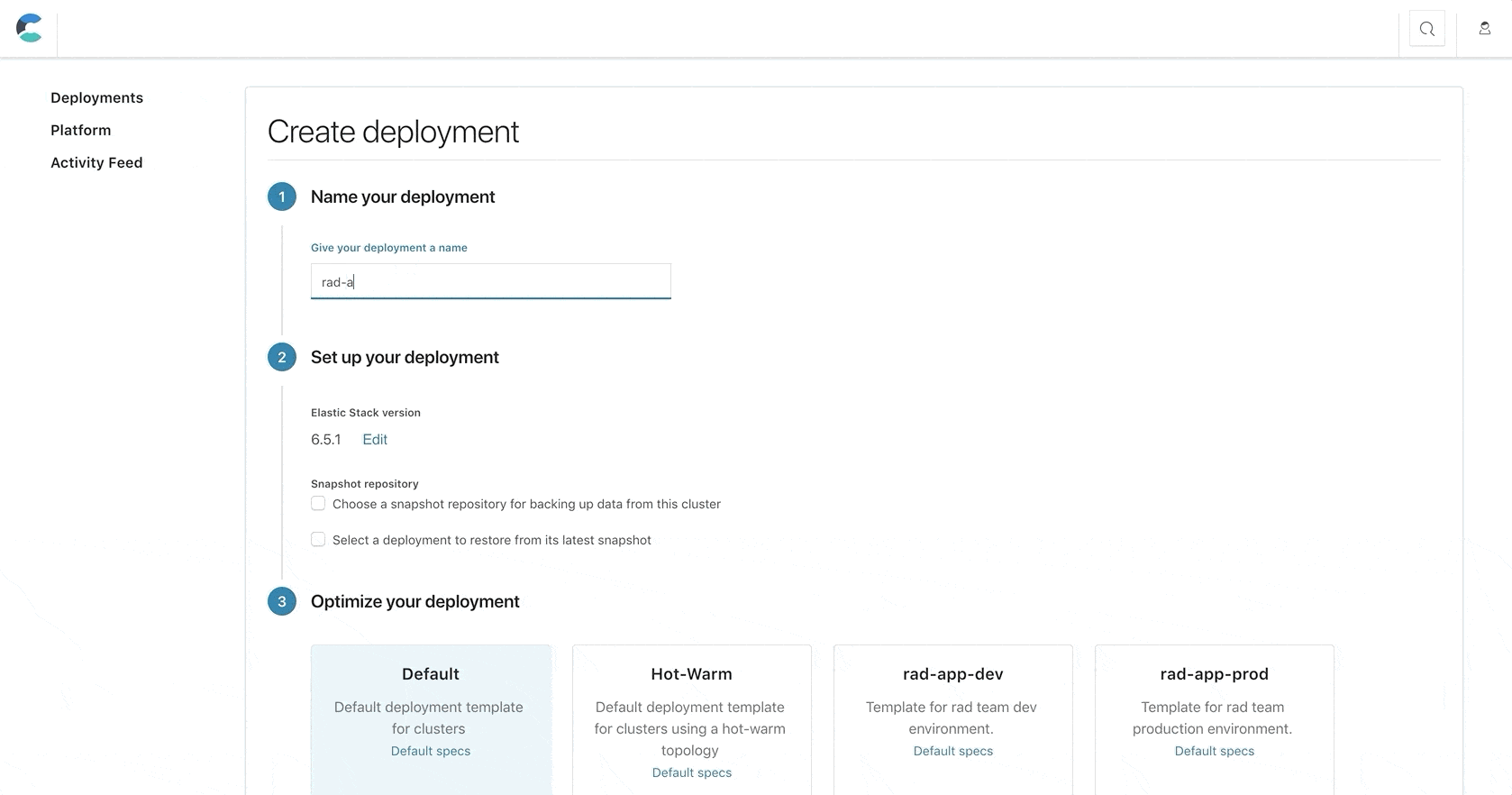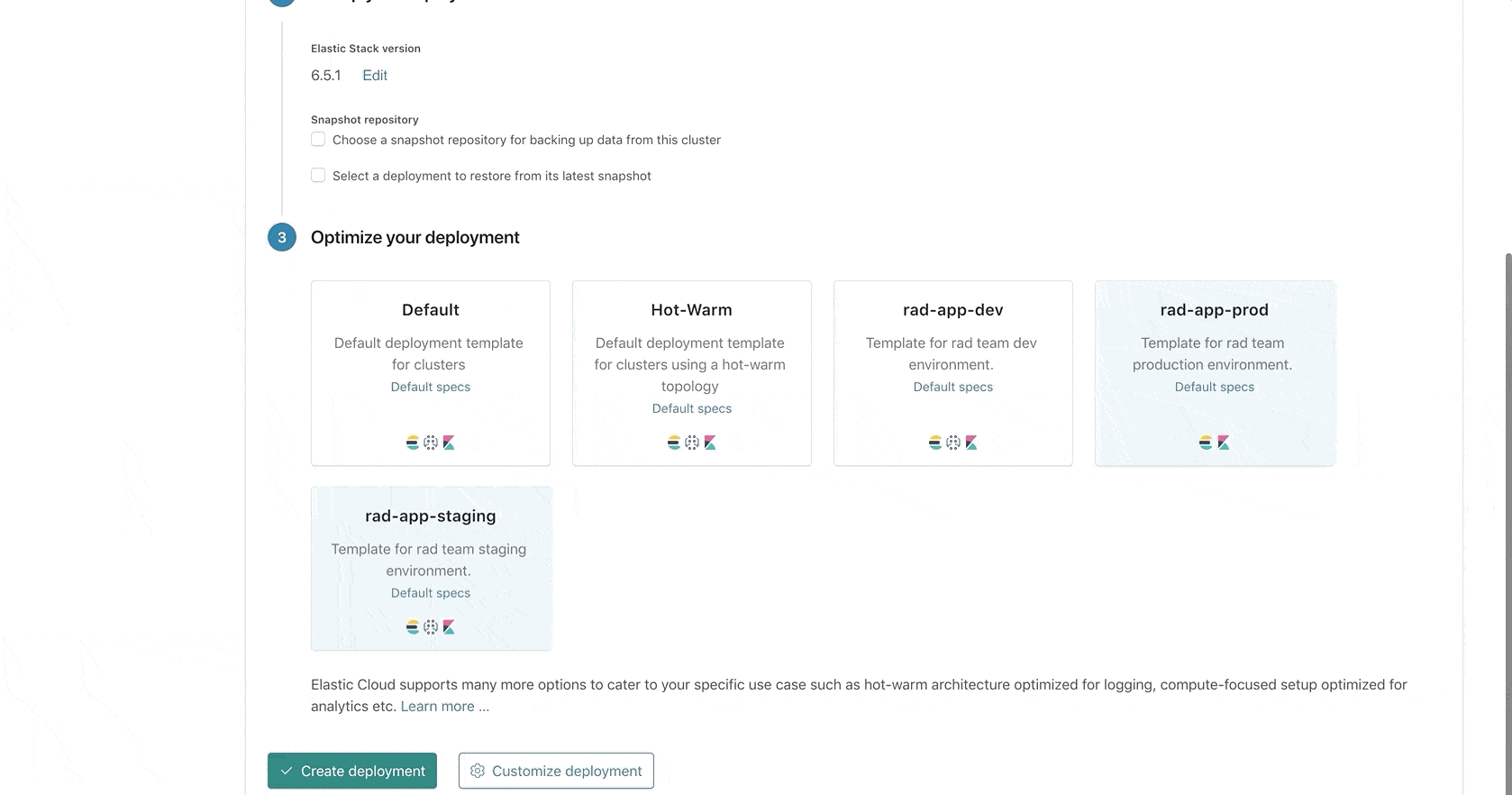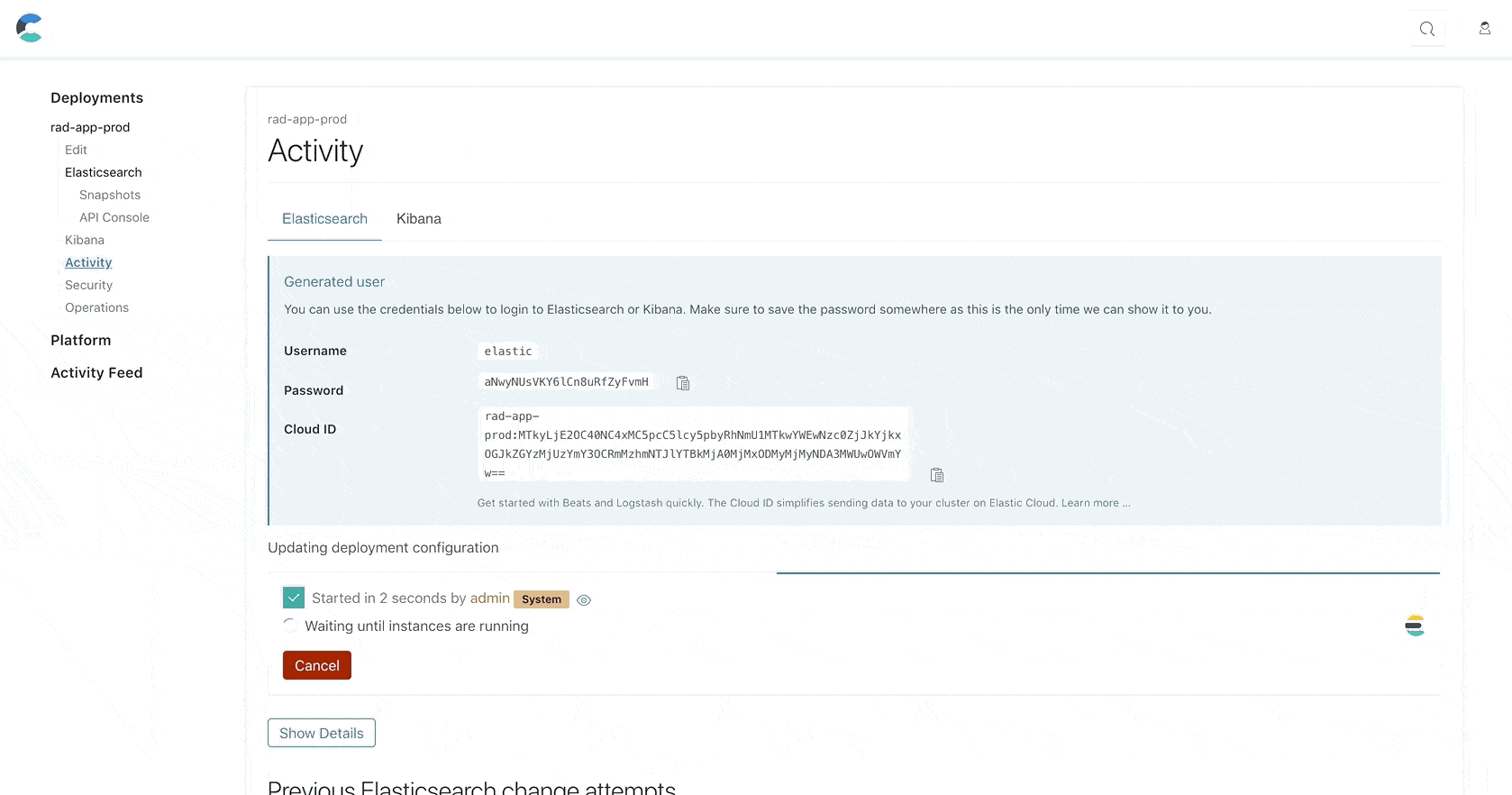
Using the same cluster for your dev, staging, and production is obviously not a great idea. Teams often have a cluster per environment; one used by developers to work on new features; a staging cluster to test new features before they are rolled out to production; and, lastly, a production cluster to support a production environment or application. Each environment has different high availability requirements — for example deploying across one, two, or three availability zones, differing numbers of replicas, snapshots intervals, and so on. These different requirements between environments means that you can suffer varying amounts of downtime before you start getting those urgent “machine down” alerts.
It comes as no surprise that hosts used for host production workloads are monitored and adhere to a strict time to repair, and there is a preference to bundle production workloads on the same set of hosts. This preference can now be achieved in ECE by creating a set of deployment templates for each environment. For example rad-app-search-dev, rad-app-search-staging, rad-app-search-prod, will each be deployed on a different set up of hosts.
A similar use case is when each environment also resides in a different network segment, in some cases even a completely separate virtual private cloud (VPC). While this setup will require “poking a hole” in each VPC in order for ECE control plane services to access the allocators in it, and a set of proxies that will be set up in each environment to direct requests to the relevant nodes, it is very common for customers to have a single pane of glass to manage deployments across all of their deployments.
Your teams deserve the best
Often times companies choose ECE as their preferred weapon of choice to manage thousands of clusters in order to allow internal users to spin up and manage their deployments with ease while optimizing resource utilization since, by default, ECE will always attempt to fill allocators while respecting the allocator search criteria. A common ask from our users is to isolate deployments on different allocators based on the team that will use those deployments.
The reasons to separate teams can vary. One example is a need to use different budgets to pay for the underlying hardware, which is a very common request for ECE installations where a centralized IT team will manage ECE in order to provide Elastic Stack as a Service, allowing their internal teams to leverage the zero downtime upgrades, ease of scaling a deployment with a single REST API request, etc.
Another example is when teams have different needs and different SLAs. A certain team might use Elastic as an internal logging solution while another is highly dependent on their Elasticsearch cluster as part of their production tool set. Now, with the ability to build these requirements into deployment templates, you don’t need to worry about constantly checking how a deployment is running, and you can rest easy knowing that each deployment is running on the correct host. This also helps teams better plan for redundancy and disaster recovery for each deployment. To do so, simply create a deployment template for each team with the relevant configuration “baked in” and you’re good to go!
Mix and match
Each example provided here can be mixed with one or several other use cases. For example, you can isolate based on teams and within a set of allocators dedicated to a specific team or have a different set of allocators for each environment. Or, have a set of different hardware profile for each environment.
Our goal is to provide you with the tools you need to support any type of hardware and any use case so that offer your users the best Elastic experience possible.
We hope this blog post provided you with a few use cases where these new features can help you better manage your ECE environment, optimise performance by introducing new hardware profiles that will better match your needs, and provide a much needed isolation between environments and teams. If you have other ways that you are using these features we’d love to hear about them and if you haven’t had a chance, try out ECE with a free trial. Don’t be shy — take it for a spin!