Detecting threats in AWS Cloudtrail logs using machine learning
Cloud API logs are a significant blind spot for many organizations and often factor into large-scale, publicly announced data breaches. They pose several challenges to security teams:
- Cloud API transactions do not leave network or host-based evidence. For this reason, they cannot be monitored, searched, or analyzed using conventional security tools and products like network security devices or endpoint-based security agents. This tends to create significant blind spots in cloud threat detection as we will see in case studies throughout this blog.
- They tend to resist detection using conventional search rules. A cloud API transaction log message created by unauthorized or malicious activity can be indistinguishable (apart from very subtle contextual nuances) from the thousands or millions of similar messages that were benign.
- Distinguishing between routine and malicious messages can require technical expertise and environmental familiarity to understand nuance, such as the calling user context or source location. Alerting on such threats with search rules would require prior knowledge of how common attacks manifest and which user contexts are likely to be compromised.
For all of these reasons, cloud API logs are resistant to conventional threat detection and hunting techniques. Even if there were enough technical personnel for all organizations to maintain robust threat hunting teams, it is infeasible to manually sift millions or billions of CloudTrail events in order to find the few outliers that indicate malicious activity.
In this blog, we’ll take an in-depth look at detection techniques through cloud API logs analysis, exploring two use cases of public record incidents in order to apply real-world examples of how threats can slip through conventional detection methods. We will walk through how to use search-based detection rules and show how to use Elastic’s machine learning based anomaly detection to identify rare and unusual activity in your cloud API logs.
Case study 1: Exfiltration via snapshots
Let’s consider some examples. Recently, there was a public record data breach affecting cloud-hosted user information. While there were many dimensions to this particular intrusion set, the cloud dimensions are interesting because they featured tactics that had not been seen before.
The attackers in this case decided that the most efficient way to copy the target data in bulk was to share snapshots in the victim’s cloud account with themselves using a built-in sharing feature — one commonly used for rapid instance deployment or disaster recovery. Once the snapshots were shared with the attacker’s account, they could copy or download data in case their cloud account was suspended, once incident response began.
Moving snapshots in this way can yield a copy of the virtual disks attached to virtual machines running in a cloud account — potentially including the contents of each virtual server’s complete file system and any databases or other data structures stored there. In other words, it is a way of forklifting bulk data from one account to another.

If we’re ingesting and monitoring CloudTrail logs, we can alert on this kind of activity with a search rule. Sharing a snapshot to another AWS account invokes the ModifySnapshotAttribute API call that is recorded in a CloudTrail log message and includes changes to snapshot permissions:
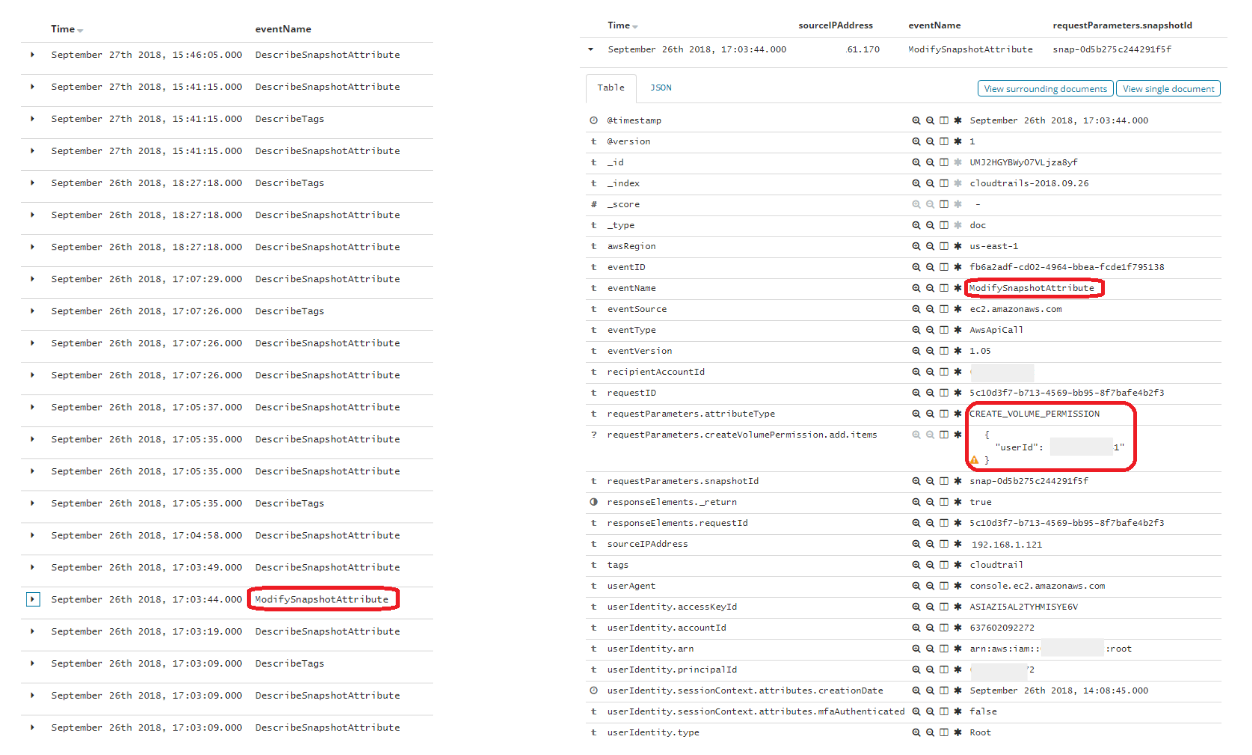
We included a search rule for this event among the CloudTrail rules we shipped in version 7.9 of the Elastic Stack. The rule name is “AWS EC2 Snapshot Activity” and it has its own MITRE ATT&CK® technique in the cloud matrix: “Transfer Data to Cloud Account (T1537),” which is a technique in the Exfiltration tactic category:

Using a search rule for this is workable because while modifying snapshot permissions does happen normally, it does not usually happen hundreds or thousands of times per week, so we can alert on this without risk of alert fatigue. This rule can be further tuned, of course, by exempting user contexts who normally or routinely modify snapshot permissions.
Manual hunting for anomalous snapshot activity can also be undertaken using the search in this rule:
event.dataset:aws.cloudtrail and event.provider:ec2.amazonaws.com and event.action:ModifySnapshotAttribute
Hunting will also tend to reveal what normal snapshot workflow looks like in an environment. This can be useful for tuning this rule with exceptions for normal snapshot activity.
Case study 2: Multistage lateral movement
Let’s next consider a harder problem in detection. In 2019, another public record incident took place that also featured a cloud attack surface. In this case, data was reportedly taken from a particular set of S3 (the AWS Simple Storage Service) buckets.
In order to accomplish this, the attacker first relayed connections through an insecure WAF (web application firewall) in order to connect to the metadata service, which is not normally reachable from the Internet as a security precaution due to the sensitive nature of the data it contains. It is normally reachable only from a running EC2 instance.
There were five phases to this complex attack that effectively combined a number of techniques in order to obtain credentialed access. While none of these were necessarily critical by themselves, combining them into a sort of chained exploit made it possible to transition from an anonymous to credentialed user and then steal large amounts of data from the S3 bucket:
- A server-side request forgery (SSRF) attack was made through an insecure web application firewall instance to gain access to the metadata service API
- The attacker then routed commands and queries to the metadata service, which is not otherwise remotely accessible, through the WAF
- Credentials for the WAF service account were retrieved from the metadata service
- The WAF service account credentials retrieved were used to enumerate data in the S3 using APIcommands like “ListBuckets”
- The WAF service account credentials were subsequently used to retrieve data from the S3
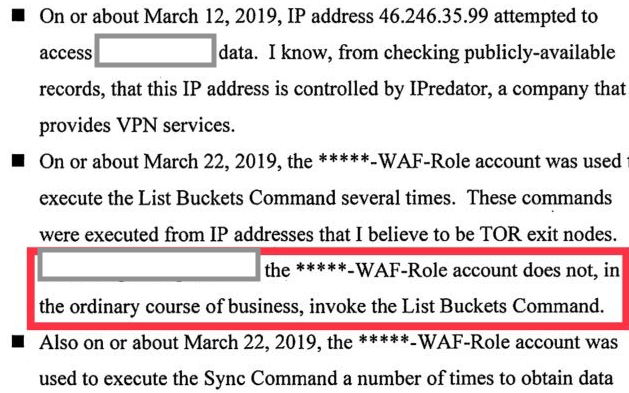
This attack leaves several pieces of evidence in the CloudTrail log messages. There would be events showing that a role associated with the WAF began calling methods related to S3, such as ListBuckets. In addition, the logs would show this activity sourced from an IP address associated with a VPN service and a set of TOR (the onion router) exit nodes, both of which were unusual and suspicious.
VPN services and TOR are commonly used to obscure or hide one’s source IP address on the Internet, and are thus frequently used to anonymize network traffic. These may or may not be useful detection methods for every enterprise, though. Organizations could maintain a list of TOR exit nodes (where TOR meets the Internet) in order to alert on activity sourcing from these kinds of networks but this activity tends to be ever-present in most diverse Internet traffic — we don’t always want to alert on each and every connection of this kind to avoid alert fatigue.
We could refine our approach and restrict our alerting to authenticated activity from TOR nodes to reduce traffic volumes associated with scanning activity (very common), which tends to be much more interesting — but what about VPN services? How many VPN services are there? How many do enterprises use legitimately? And how would we enumerate the IP addresses they use if those aren’t published? In the final analysis, trying to enumerate “good” and “bad” source IP addresses quickly becomes infeasible. Even if we could perfectly identify both TOR nodes and VPN services, this attack could just as well have come from somewhere else, such as a compromised third-party network or even another cloud instance.
Let’s consider the ListBuckets command. This command, along with other S3 commands, is used normally thousands of times per week in most cloud environments — far too often to alert on without drowning the SOC in false positive alerts and inflicting alert fatigue on analysts. What we need to do is to imitate what threat hunters do and consider this activity relative to the normal spectrum of normal behavior in the spectrum. There are at least two kinds outliers in these particular events:
- The user context for the ListBuckets command. The WAF role normally does not use this command, as it is unrelated to the WAF function.
- The source IP address for the commands would have been unusual.
In order to hunt for these without generating a flood of alerts, we can use the combination of Elastic unsupervised machine learning technology and machine learning rules to find outliers in the CloudTrail data and turn these results into detection alerts.
There are five different machine learning rules in the CloudTrail package. One looks for unusual commands for a user context. When the ListBuckets command is invoked in my dev environment (a command I have not used before) this action is flagged by the machine learning job that powers a rule named Unusual AWS Command for a User.
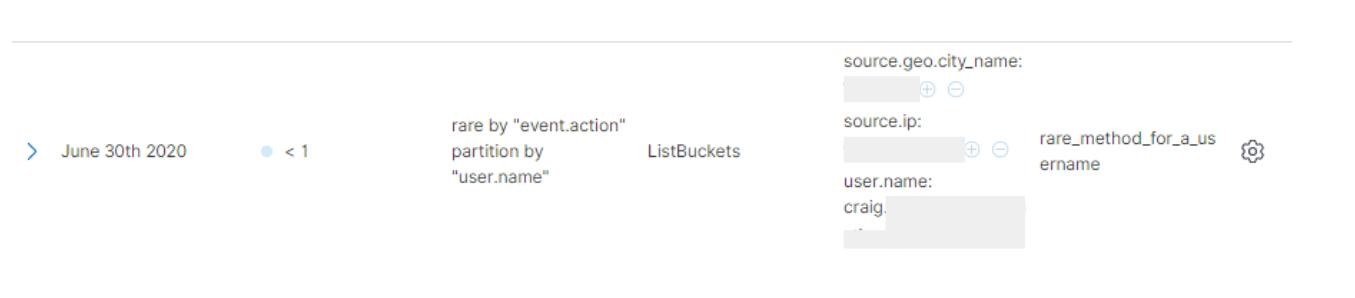
This anomaly result can also be turned into a detection alert in Elastic Security. Many of these rules contain playbooks in the “investigation notes” field that contain suggested procedures and avenues of investigation for unusual cloud activity, and this one is no exception:

This rule package contains rules that will also find unusual logins for users who do not normally access the management console. In this case, the model has detected an unusual username authenticating to the console:

Another of the included machine learning rules identifies commands with an unusual geolocation. We selected geolocation instead of source IP because the source IP in cloud data tends to have both very high cardinality (a very large number of IP addresses) and a long tail of outliers since modern distributed systems use numerous IP addresses and networks. We found that geolocation outliers are both more sparse and more interesting. In the examples below, the ML jobs have found API methods being called from geographic locations that are unusual for the dataset:
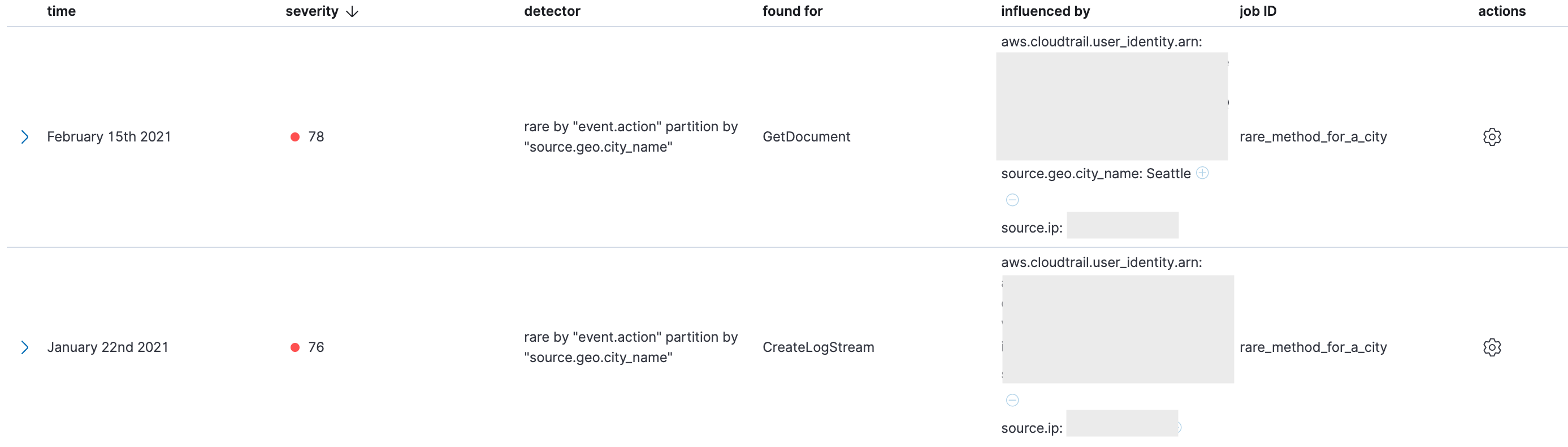
This is particularly relevant to the phase of this incident where activity was coming from the TOR network. The TOR network is globally distributed and uses random exit nodes that can be problematic to predict and monitor. The result is that when using TOR, a username will tend to come from IP addresses in a wider range of geographic locations then they normally do. These anomaly results can be transformed into detection alerts in Elastic Security by a machine learning rule:

We can detect the unusual credential access and API activity using the rare function in Elastic machine learning. Working backwards, we can achieve detection even earlier in this sequence by performing anomaly detection on the metadata service. Let’s work on steps 2-3 in this incident where the attacker obtained valid credentials from the metadata service.
What is the metadata service?
The metadata service is a web service API that listens on a reserved IP address in most cloud networks and allows cloud workload instances to ask questions about themselves and their roles. Instances can also retrieve user data and tokens or credentials they have been assigned and are authorized to use. These requests are authenticated and authorized by a reference monitor that maintains a mapping of instance IDs and MAC addresses that are used to identify a calling instance.
This service is called the “mapping service” in AWS. This authentication method works because virtual network switches are not learning switches; the hypervisor maintains a mapping of MAC addresses and instance IDs. MAC address spoofing, like most layer two attacks that require a learning switch, are ineffective in most virtual environments. The result is that while an instance can only interrogate the metadata service about itself, a program or user persisting on an instance can also interrogate the metadata service and ask questions about the source instance.
In many cases, credentials associated with an instance can also be retrieved from the metadata service that can also be used elsewhere — including from the public Internet, depending on identity and access management (IAM) policies.
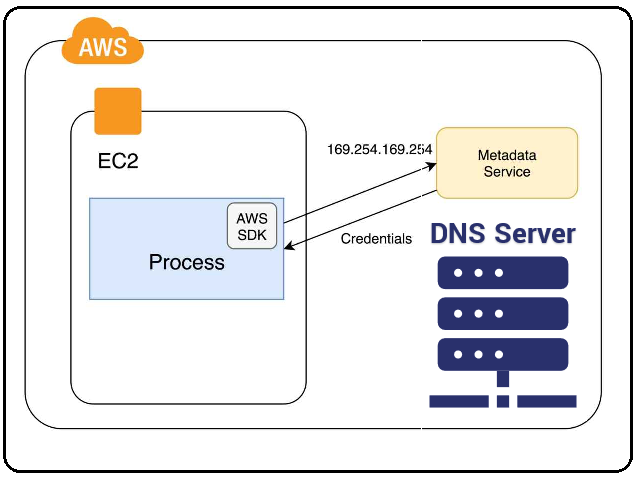
Metadata service access is mostly programmatic, called by programs and scripts, and so the cardinality of the process and user names in metadata connection events is not very high. Because normal metadata behavior does not vary much, it is a great place to apply anomaly detection. Conventional search rules will not benefit us here, however, because the metadata service is normally used hundreds or thousands of times per day.
A simple search-based alert for metadata activity would quickly overwhelm us with a flood of false positive alerts on benign activity. Using anomaly detection, we can limit alerting to the set of metadata events that are unusual enough to be suspicious.
In the following example, we’re looking for rare process names accessing the metadata service — in this case, curl. While this could be manual troubleshooting, it is interesting because this is also one way that a threat actor might interrogate the metadata service after obtaining persistence on a cloud workload instance:

In this example, we’re looking for a user accessing the metadata service who does not normally use the service. While this could be manual troubleshooting, it is interesting because this could also be a threat actor interrogating the metadata service after obtaining persistence on a cloud workload instance:

Additionally, we included two cloud anomaly detection packages that analyze error messages:
- Rare AWS Error Code
- Spike in AWS Error Messages
These are interesting as potential indications and warnings for suspicious activity because threat actors sometimes produce new errors, or bursts of common errors, as they work to establish persistence, elevate privileges, and move laterally.
These anomaly detection jobs are relevant to application performance monitoring (APM) and operational observability in addition to security. We have found, for example, that the Rare AWS Error Code rule sometimes predicts an imminent service failure by a matter of minutes.

Conclusion
In this post, we have examined two case studies on cloud threat activity from two public record cases and how conventional detection methods can miss things. We discussed techniques for detection using analysis of cloud API logs in detail.
We have considered how machine learning-based anomaly detection with the rare function can detect threat activity, including threat activity resistant to conventional search-based detection rules. We’ve also shown how machine learning-based anomaly detection is a powerful addition to conventional search-based rules. While neither technology is a panacea, the combination of the two is an effective way to maximize threat detection efficacy.
Elastic's internal security research team researches adversary tradecraft and develops new detection rules and machine learning jobs for multiple platforms including cloud. Our users can expect to see our continued focus on increasing the cost of cloud attacks.
Configuring our Filebeat modules to ship logs to Elasticsearch and enable detection rules in Elastic Security is easy. Our free detection rules help security teams monitor those logs and detect suspicious behavior, regardless of the size of their team. Elastic Security enables analysts to triage and investigate those alerts quickly and efficiently.
If you’re interested in trying out Elastic, you can download our products free or sign up for a free 14-day trial of Elastic Cloud.