How we sped up data ingestion in Elasticsearch 8.6, 8.7, and 8.8


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
As some of you already noticed, Elasticsearch 8.6, 8.7, and 8.8 brought good indexing speedups across a wide range of data sets, from simple keywords to heavy KNN vectors, as well as ingest-pipeline-heavy ingestion workloads. Ingestion involves many components — running ingest pipelines, inverting data in memory, flushing segments, merging segments — and all of these usually take a non-negligible amount of time. Fortunately for you, we've made improvements across all of these areas, enabling faster speeds for end-to-end ingestion.
As an example, 8.8 is 13% faster than 8.6 at ingestion on our benchmark that simulates a realistic logging use-case with multiple data sets, ingest pipelines, etc. The following chart shows the ingestion rate going from ~22.5k docs/s to ~25.5k docs/s over the period of time when we implemented these optimizations.
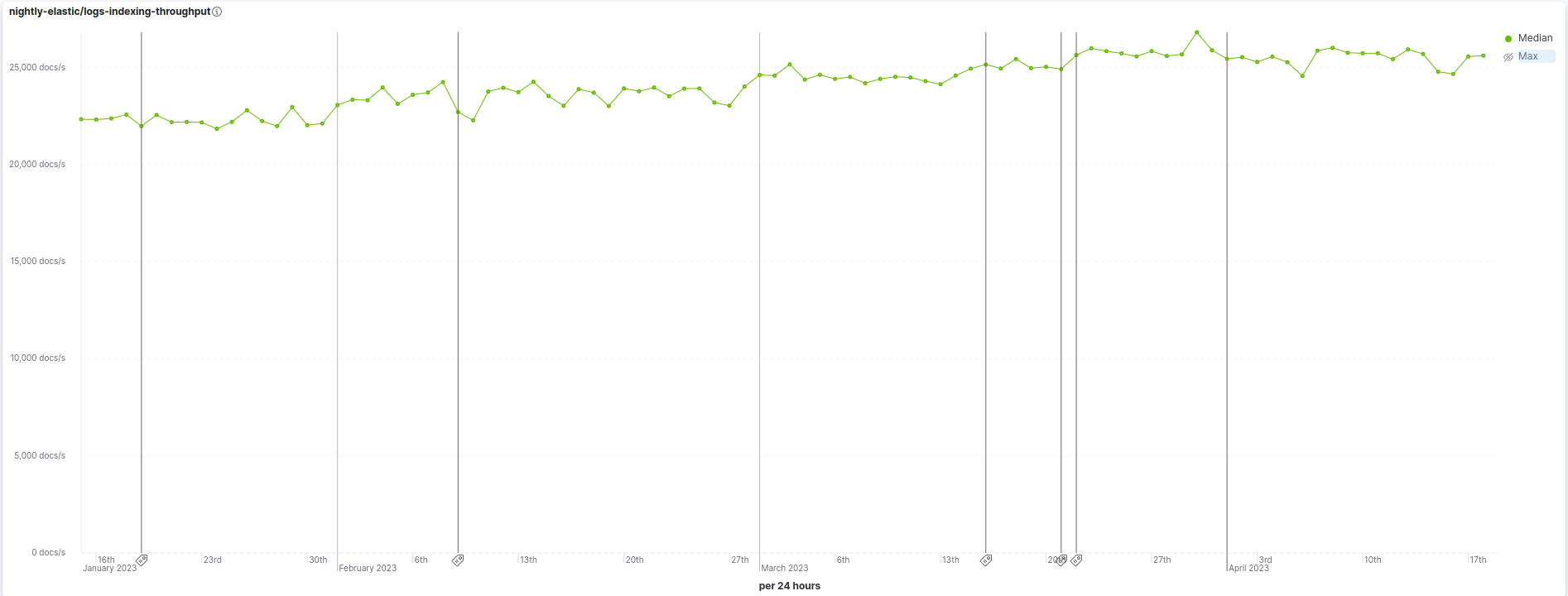
This blog dives into some of the changes that helped achieve ingestion speedups in 8.6, 8.7, and 8.8.
Faster merging of kNN vectors
The underlying structure for Elasticsearch’s kNN search is Lucene’s Hierarchical Navigable Small World (HNSW) graph. This graph provides exceptionally fast kNN search even over millions of vectors. However, building the graph itself can be an expensive task; it requires performing multiple searches across the existing graph, building the connections, and updating the current neighbor sets. Previous to Elasticsearch 8.8, when segments were merged, an entirely new HNSW graph index was created — meaning every vector, from every segment, was individually added to a completely empty graph. As segments get larger, their numbers increase, and merging can get prohibitively expensive.
In Elasticsearch 8.8, Lucene makes a significant improvement on merging HNSW graphs. Lucene intelligently reuses the largest existing HNSW graph. So, instead of starting with an empty graph as before, Lucene takes advantage of all the previous work done building the existing largest segment. The impact of this change is significant when merging larger segments. On our own benchmarks, we found a reduction of over 40% in time spent on merging and over twice as fast refresh throughput. This significantly reduces the load experienced by the cluster when indexing larger vector data sets.
Optimizations to ingest pipelines
Ingest pipelines use processors to perform transformations on documents before they are indexed — for example, setting or removing fields, parsing values like dates or json strings, and looking up geolocation using an ip address or other data enrichment. With ingest pipelines, it’s possible to send lines of text from a log file and have Elasticsearch do the heavy lifting to transform that text into a structured document. Most of our out-of-the-box integrations use ingest pipelines to enable you to parse and enrich new data sources in minutes.
In 8.6 and 8.7, we’ve optimized ingest pipelines and processors in several ways:
- We’ve removed most of the overhead of passing a single document through multiple pipelines.
- We’ve optimized some of the most commonly used processors:
- Set and append processors that use mustache templates now have faster template model creation and mustache template execution.
- Date processors now cache their associated date parsers.
- Geoip processors no longer rely on reflection.
- In 8.6.0, we optimized painless scripts in two ways, which improved script processors and conditional checks.
- Additionally, overall metrics and statistics on ingest processing are more accurate than before:
- Time spent serializing data after pipeline execution is correctly accounted for.
- Documents that execute against multiple pipelines are only counted once.
- Finally, optimizations of low-level hot code have resulted in less overhead for all documents processed, like faster set intersections, faster metadata validation, and faster self-reference checks.
Combining all these improvements, we have 45% better ingest pipeline performance on our nightly security integration benchmark and 35% better ingest pipeline performance for our nightly logging integration benchmark.
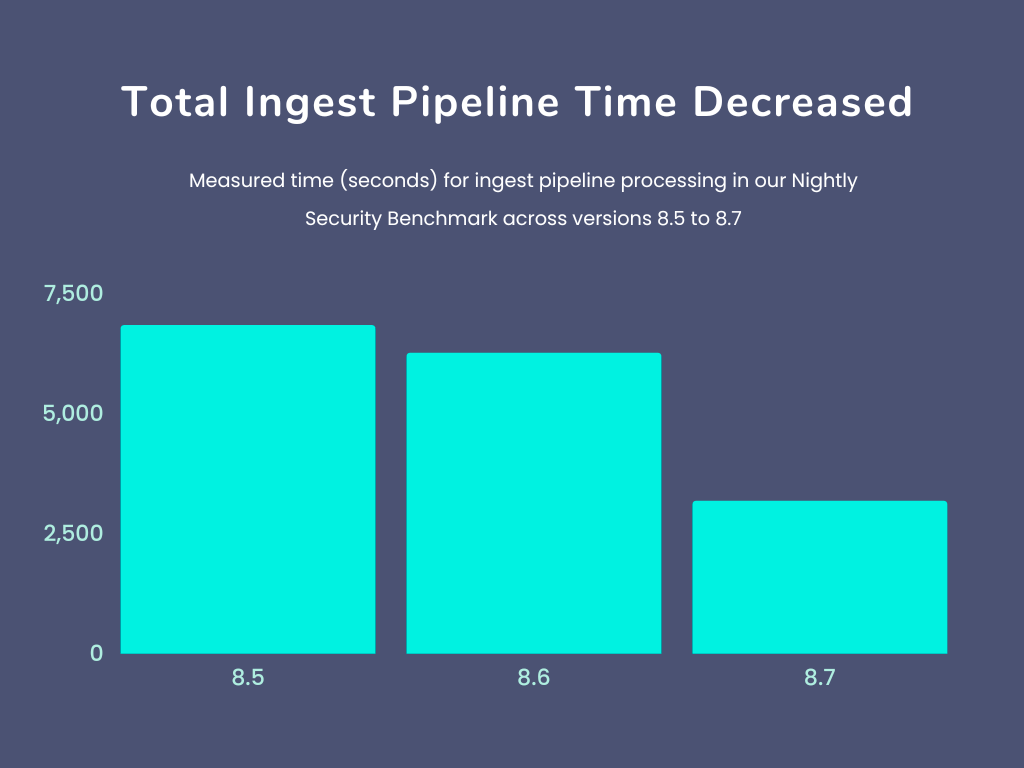
We expect these speedups to be representative of the improvement that a non-trivial ingest use case would see after an upgrade to 8.7 or a more recent version.
Optimizations to keyword and numeric fields
We have many data sets where a majority of the fields are simple numeric and keyword fields, and they would automatically benefit from improvements to these field types. Two main improvements helped with indexing these field types:
- Elasticsearch switched to Lucene's IntField, LongField, FloatField, and DoubleField when applicable, which are new in Lucene 9.5, as well as Lucene's KeywordField, new in Lucene 9.6. These fields allow users to enable both indexing and doc values on a single Lucene field — you would otherwise need to provide two fields: one that enables indexing and another one that enables doc values. It turns out that this change that was aimed at making Lucene more user-friendly also helped with the indexing rate, more than we had anticipated! See annotations AH and AJ to see the effect of these changes on Lucene's nightly benchmarks.
- Simple keywords now get indexed directly instead of going through the TokenStream abstraction. TokenStreams are typically the output of analyzers and expose terms, positions, offsets, and payloads — all the information that is required to construct an inverted index for a text field. For the sake of consistency, simple keywords also used to get indexed by producing a TokenStream that would return a single token. Now the keyword value gets indexed directly, without going through the TokenStream abstraction. See annotation AH to see the effect of this change on Lucene's nightly benchmarks.
Optimizations to index sorting
Index sorting is a powerful feature to speed up queries by enabling early query termination or by clustering documents that are likely to match the same queries together. Furthermore, index sorting is part of the foundation of time-series data streams. So we spent some time addressing some of the index-time bottlenecks of index sorting. This resulted in a good 12% ingestion speedup on our benchmark that ingests a simple data set of HTTP logs sorted by descending @timestamp.
A new merge policy for time-based data
Until recently, Elasticsearch has always relied on Lucene's default merge policy: TieredMergePolicy. This is a very sensible merge policy that tries to organize segments into tiers of exponential sizes, where each tier has 10 segments by default. It's good at computing cheap merges, reclaiming deletes, etc. So why would you want to use a different merge policy?
Time-based data is special in that it usually gets ingested in approximate @timestamp order, so segments that get flushed via subsequent refreshes would generally have non-overlapping ranges of timestamps. This is an interesting property for range queries on the @timestamp field, as many segments would often either not overlap with the query range at all or be fully contained by the query range, which are two cases that range queries deal with extremely efficiently. Unfortunately, this property of segments that have non-overlapping time ranges gets invalidated by TieredMergePolicy, since it happily merges non-adjacent segments together.
So shards that have a `@timestamp` date field now use Lucene's LogByteSizeMergePolicy for time-based data, TieredMergePolicy's predecessor. A key difference between the two is that LogByteSizeMergePolicy only ever merges adjacent segments, which preserves the property that segments have non-overlapping @timestamp ranges through merges — assuming that data gets ingested in @timestamp order. This change has sped up by as much as 3x some queries of our EQL benchmark, which need to walk over events in `@timestamp` order in order to identify sequences of events!
But this property is also a downside as LogByteSizeMergePolicy has less flexibility than TieredMergePolicy to compute merges of equal-size segments, which is the best way to limit write amplification through merges. In order to mitigate this downside, the merge factor has been raised to 32 from 10 with TieredMergePolicy until now. While increasing the merge factor usually makes search slower, the impact is limited by the fact that LogByteSizeMergePolicy merges data more aggressively than TieredMergePolicy for the same merge factor, and by the fact that retaining the property that segments have non-overlapping @timestamp ranges significantly helps range queries on the timestamp, the most common type of filter on time-based data.
That's it for 8.6, 8.7, and 8.8. We have a few more speedups coming in upcoming minors, so stay tuned!
Want to learn more about what was included in each of these releases? Read their respective release blogs for the details:
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print