What's in a name? The name Lucene is Doug's wife's middle name, which was also her grandmother's first name.
Happy birthday, Lucene
Celebrating 20 years of Apache Lucene
Apache Lucene — the backbone of Elasticsearch — is proof that when open source software is nurtured by a thriving community, it can flourish and grow into technology that powers digital experiences across the globe. Elastic celebrates the connection and integration with Lucene’s code and community through a collective timeline highlighting fun facts and key milestones.
It all started with Java
When Doug Cutting decided to learn Java, he honed his skills by creating a new search indexer project. This endeavour led him to author the first version of Lucene — making it available (as free and open source software) via SourceForge in April of 2000. Lucene was Doug's fifth search engine, having previously written two while at Xerox PARC, one at Apple, and a fourth at Excite.

Fun Fact
Everyone has an origin story
Everyone has their own unique story for how they got started with Lucene. How will your story begin?

Lucene joins Apache
In September, Lucene joins the Apache Jakarta Project. Jakarta was a family of open source Java projects, including Apache Tomcat and Apache Struts.

Milestone
Lucene 1.2 becomes the first release of Lucene under the Apache license, marking its departure from LGPL licensing.
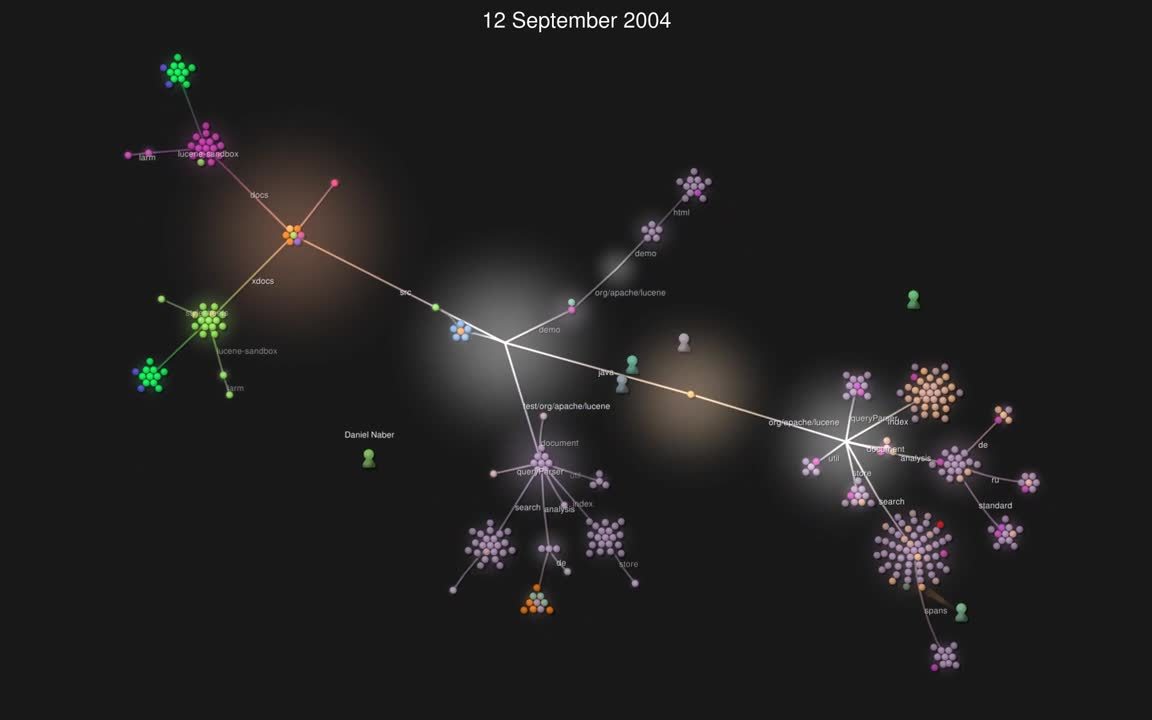
Committed to open source
In 2002, Lucene saw nearly 400 commits from 13 unique authors — and it's only grown since then. Observe the first years of commits and see how they've grown over time.
Milestone
Lucene 1.3 introduces some early flexibility with PerFieldAnalyzerWrapper, allowing fields to use different approaches to tokenizing.
Navigating search
Shay Banon releases Compass — an open source project built on top of Lucene — aiming to simplify the integration of search into any Java application. Compass would serve as the precursor for Elasticsearch.

Milestone
Lucene 1.4 introduces hit sorting, allowing the results of a given query to be sorted by any indexed field.
Reading for (code) writers
Lucene in Action is first published. This guide to Lucene remains the best selling technical manual for the project.

Fun Fact
In 2005, there were 484 commits from 11 unique authors.
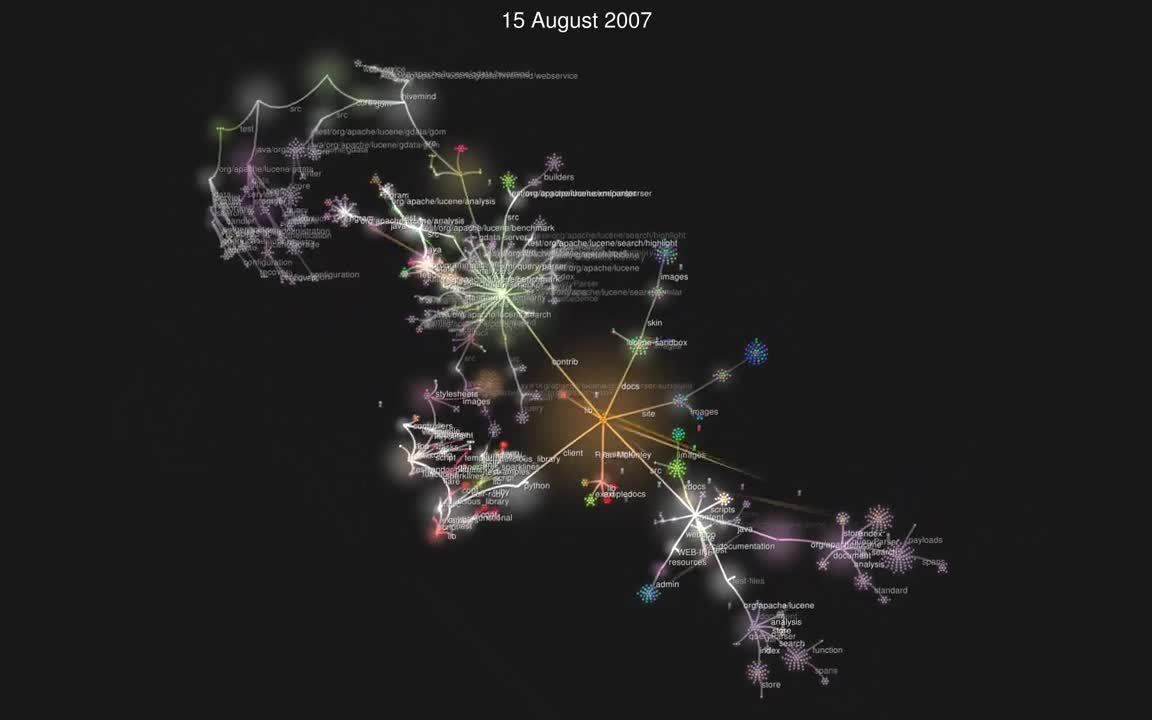
Committed to solving problems, big and small
Visualize Lucene commits from 2005-2009
Milestone
Lucene 1.9 introduces DateTools, allowing users to format dates for better readability, as well as handle dates before 1970.
Milestone
Lucene 2.0 mirrors 1.9, aside from dropping deprecated APIs. Some contribute the longevity of the project to this type of maintenance.
Fun Fact
With some help from Doug, Shay submits his first contribution to the Lucene codebase (LUCENE-511). Fellow Elastic co-founder, Simon Willnauer, also works with Doug, delivering on a request to implement a GData server on top of Lucene (LUCENE-578).
Milestone
Lucene 2.1 updates QueryParser to allow Unicode characters to be added in their Unicode escape form. \u1F973 \u1F973 \u1F973
Milestone
Lucene 2.2 includes some small optimizations with big impact. Increase to two buffer sizes yields a 10-18% write performance boost.
Celebrating community
For an open source project, 20 years is a long time. Without a doubt, Lucene's longevity is a testament to the strength and diversity of its community.

Milestone
Lucene 2.3 improves how the IndexWriter utilizes RAM for buffering documents — leading to a 2-8x indexing speed boost.
Milestone
Lucene 2.9 changes its API to reflect the segmented structure of its indices, boosting speeds with this new realignment.
Milestone
Lucene 3.0 is the first version to require Java 5 at runtime, making use of new JVM features like generics, enums, and variable arguments.
Fun Fact
Co-founder of Elastic, Uri Boness, starts the first Dutch Lucene User Group.
Connecting code
The Lucene and Solr repositories are merged. While sharing the same repo, Lucene is still available to download and use by itself.

Fun Fact
Elasticsearch 0.1.0 is released on February 7! The open source, distributed, RESTful search engine is built on top of Lucene.
Fun Fact
Simon starts Berlin Buzzwords, a conference focused on open source software projects working towards big data management.
Committed to building a strong community
Visualize Lucene commits from 2010-2014

Fun Fact
Twitter implements a patched version of Lucene for real-time search.
4.0? 4.oh wow!
Lucene 4.0 is full of important new features. Improved index flexibility via the Codecs API, added similarity models (BM25, DFR, and more), and the introduction of doc values elevate Lucene into the world of serious analytics.

Fun Fact
On February 9 — almost exactly two years since the first Elasticsearch commit — Elastic is founded by Steven Schuurman, Uri Boness, and Lucene contributors Simon Willnauer and Shay Banon. Hey, that's us!
Milestone
Lucene 4.3 adds a cost API to approximate query match counts. This adds significant speed by running cheap queries first.
Fun Fact
Search suggestions are standard these days, but that doesn't mean they're easy. Learn how Lucene first approached this complex task.
Continued commitment to Lucene
Apache Lucene is at the heart of Elasticsearch, and Elastic has made contributing to core Lucene a priority. In fact, core committers have been on the Elastic team since Day 1.

Milestone
Lucene 4.8 implements a common format that includes checksums for all index files, making it possible to better detect hardware errors.
Committed to the future of search
Visualize Lucene commits from 2015-2019

Milestone
Lucene 5.0 is primarily motivated by the removal of support for 3.x indices. Managing technical debt isn't glamorous, but it is important.
Milestone
Lucene 5.1 adds two-phase intersections for phrase queries, boosting speeds by splitting approximation and confirmation into two steps.
Fun Fact
Elastic's first This Week in Elasticsearch and Apache Lucene blog was published on March 25, a series that ran until 2020.
Branching out
With the introduction of BKD tree data structures for multidimensional search, Lucene is no longer just a full-text search engine, but a search engine of anything. This opened the door for the advancements we're currently watching unfold in the world of geospatial search, scoring using dynamic features, and more.

Milestone
Lucene 6.0 adds support for indexing multi-dimensional points (BKD trees) and sets BM25 as the default similarity model (not TF/IDF).
Fun Fact
Lucene moves from a Subversion repository to Git, allowing users to more accurately control versions and releases.
Now featuring...
After 20 years of community development, calling Lucene "feature-rich" is an understatement. With so many features to choose from, everyone has a few favorites.

Milestone
Lucene 6.5 introduces logic to automatically run range queries in the most efficient way, creating considerable performance boosts.
Milestone
Lucene 7.0 updates the doc value API from random access to iterative, optimizing performance with sparse data (nearly empty fields).
Looking forward to the future
There's no end in sight when it comes to what's possible with Lucene. Find out what the future may hold, and what folks are excited about.

Milestone
Lucene 7.6 allows BKD trees to index a subset of their dimensions, effectively treating them like R-trees (the standard structure in geo).
Magic WAND
Lucene 8.0 implements the Block-Max WAND algorithm, creating a tremendous boost in search result speeds over large collections of documents by excluding low scoring results from the set.

Lucene turns 20!
To those who have contributed to Lucene over the years, a sincere "thank you" from all of us who have enjoyed this incredible open source project. We look forward to many more years of search innovation, and are excited to see who else joins the project.

Fun Fact
Lucene community members collaborate on an academic paper that highlights the intersection of technological advancement and academia.
Fun Fact
Nervous about contributing your first pull request to Lucene? Don't be! Respect and kindness are at the heart of this thriving OSS community.
2050
01001100!
AI bots commemorate Lucene's 50th birthday with interplanetary celebrations. AI-generated poetry praising Lucene's new interdimensional indexing functionality floods the outerweb, crashing servers across all universes and rendering any otherwise antiquated human efforts at productivity useless.
