Too many fields! 3 ways to prevent mapping explosion in Elasticsearch


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
A system is said to be "observable" when it has three things: logs, metrics, and traces. While metrics and traces have predictable structures, logs (especially application logs) are usually unstructured data that need to be collected and parsed to be really useful. Therefore, getting your logs under control is arguably the hardest part of achieving Observability.
In this article, we’ll dive into three effective strategies developers can use to manage logs with Elasticsearch. For an even more in-depth overview, check out the video below.
[Related article: Leveraging Elastic to improve data management and observability in the cloud]
Putting Elasticsearch to work for your data
Sometimes we don't have control over what types of logs we receive in our cluster. Think of a log analytics provider that has a specific budget for storing its customers’ logs and needs to keep storage at bay (Elastic deals with many similar cases in Consulting).
More often than not, we have customers indexing fields "just in case" they need to be used for search. If that is the case for you, then the following techniques should prove to be valuable in helping you cut costs and focus your cluster performance on what really matters.
Let's first outline the problem. Consider the following JSON document with three fields: message, transaction.user, transaction.amount:
{
"message": "2023-06-01T01:02:03.000Z|TT|Bob|3.14|hello",
"transaction": {
"user": "bob",
"amount": 3.14
}
}
The mapping for an index that will hold documents like these could be something like the following:
PUT dynamic-mapping-test
{
"mappings": {
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}
However, Elasticsearch allows us to index new fields without having to necessarily specify a mapping beforehand, and that's part of what makes Elasticsearch so easy to use: we can onboard new data easily. So it's okay to index something that deviates from the original mapping, like:
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field with arbitrary data"
}
}
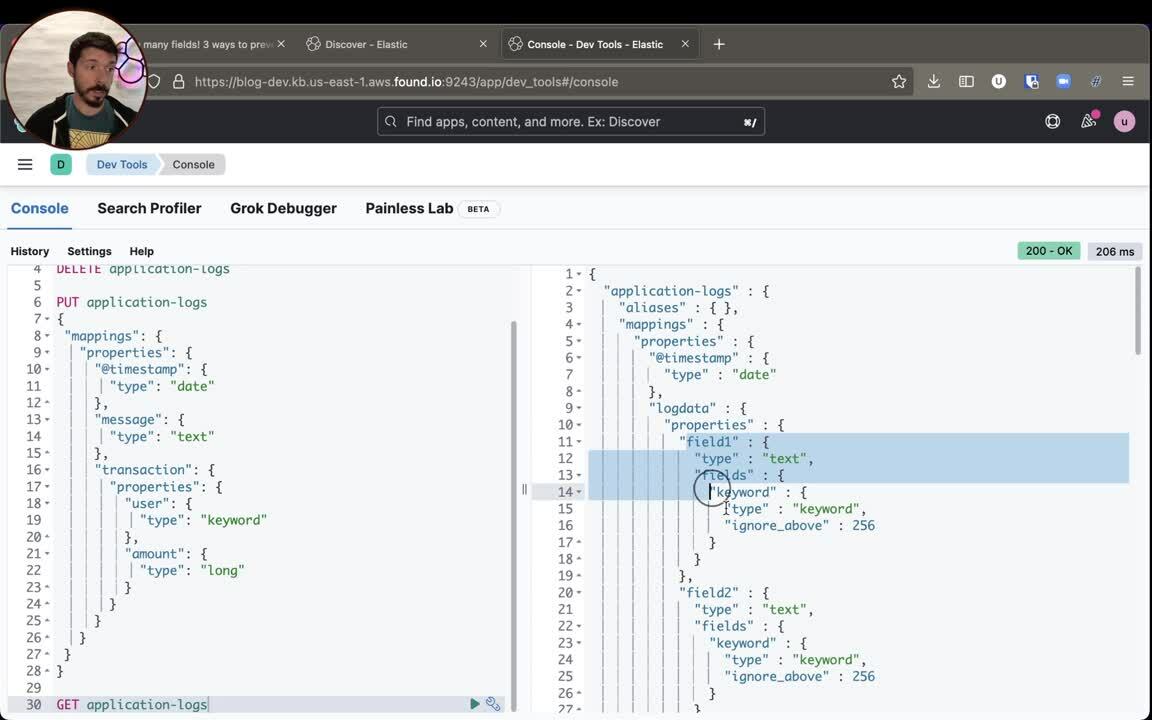
A GET dynamic-mapping-test/_mapping will show us the resulting new mapping for the index. It now has transaction.field3 as both text and keyword — actually two new fields.
{
"dynamic-mapping-test" : {
"mappings" : {
"properties" : {
"transaction" : {
"properties" : {
"user" : {
"type" : "keyword"
},
"amount" : {
"type" : "long"
},
"field3" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"message" : {
"type" : "text"
}
}
}
}
}
Great, but that is now part of the problem: when we don't have any control over what is being sent to Elasticsearch, we can easily face the problem called mapping explosion. Nothing prevents you from creating sub fields and sub sub fields, which will have the same two types text and keyword, like:
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}We would be wasting RAM and disk space to store those fields, as data structures will be created to make them searchable and aggregatable. It might be the case that those fields are never used — they are there "just in case" they need to be used for search.
One of the first steps we take in consulting when asked to optimize an index is to inspect the usage of every field in an index to see which ones are really searched and which ones are just wasting resources.
Strategy #1: Being strict
If we want to have complete control over the structure of the logs we store in Elasticsearch and how we store them, we can set a clear mapping definition so anything that deviates from what we want is simply not stored.
By using dynamic: strict at either top-level or in some sub-field, we reject documents that don't match what is in our mappings definition, forcing the sender to comply with the pre-defined mapping:
PUT dynamic-mapping-test
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Then when we try to index our document with an extra field…
POST dynamic-mapping-test/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field"
}
}
}… the response we get is this:
{
"error" : {
"root_cause" : [
{
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [field3] within [transaction] is not allowed"
}
],
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [field3] within [transaction] is not allowed"
},
"status" : 400
}If you are absolutely sure you just want to store what is in the mappings, this strategy forces the sender to comply with the pre-defined mapping.
Strategy #2: Not too strict
We can be a little bit more flexible and let documents pass, even if they are not exactly how we expect, by using "dynamic": "false".
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "false",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}When using this strategy, we accept all documents that come our way but only index the fields that are specified in the mapping, making the extra fields simply not searchable. In other words we are not wasting RAM on the new fields, only disk space. The fields can still be visible in the hits of a search, and that includes a top_hits aggregation. However, we can’t search or aggregate on them, as no data structures are created to hold their content.
It doesn't need to be all or nothing — you can even have the root to be strict and a sub-field to accept new fields without indexing them. Our Setting dynamic on inner objects documentation covers it pretty well.
PUT dynamic-mapping-disabled
{
"mappings": {
"dynamic": "strict",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"dynamic": "false",
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Strategy #3: Runtime Fields
Elasticsearch supports both schema on read and schema on write, each with its caveats. With dynamic:runtime, the new fields will be added to the mapping as Runtime Fields. We index the fields that are specified in the mapping and make the extra fields searchable/aggregatable only at query time. In other words, we don't waste RAM up front on the new fields, but we pay the price of a slower query response, as the data structures will be built at run time.
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
}
}Let's index our large document:
POST dynamic-mapping-runtime/_doc
{
"message": "hello",
"transaction": {
"user": "hey",
"amount": 3.14,
"field3": "hey there, new field",
"field4": {
"sub_user": "a sub field",
"sub_amount": "another sub field",
"sub_field3": "yet another subfield",
"sub_field4": "yet another subfield",
"sub_field5": "yet another subfield",
"sub_field6": "yet another subfield",
"sub_field7": "yet another subfield",
"sub_field8": "yet another subfield",
"sub_field9": "yet another subfield"
}
}
}A GET dynamic-mapping-runtime/_mapping will show that our mapping is changed upon indexing our large document:
{
"dynamic-mapping-runtime" : {
"mappings" : {
"dynamic" : "runtime",
"runtime" : {
"transaction.field3" : {
"type" : "keyword"
},
"transaction.field4.sub_amount" : {
"type" : "keyword"
},
"transaction.field4.sub_field3" : {
"type" : "keyword"
},
"transaction.field4.sub_field4" : {
"type" : "keyword"
},
"transaction.field4.sub_field5" : {
"type" : "keyword"
},
"transaction.field4.sub_field6" : {
"type" : "keyword"
},
"transaction.field4.sub_field7" : {
"type" : "keyword"
},
"transaction.field4.sub_field8" : {
"type" : "keyword"
},
"transaction.field4.sub_field9" : {
"type" : "keyword"
}
},
"properties" : {
"transaction" : {
"properties" : {
"user" : {
"type" : "keyword"
},
"amount" : {
"type" : "long"
}
}
},
"message" : {
"type" : "text"
}
}
}
}
}The new fields are now searchable like a normal keyword field. Note the data type is guessed upon indexing the first document, but this can also be controlled using dynamic templates.
GET dynamic-mapping-runtime/_search
{
"query": {
"wildcard": {
"transaction.field4.sub_field6": "yet*"
}
}
}Result:
{
…
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"hits" : [
{
"_source" : {
"message" : "hello",
"transaction" : {
"user" : "hey",
"amount" : 3.14,
"field3" : "hey there, new field",
"field4" : {
"sub_user" : "a sub field",
"sub_amount" : "another sub field",
"sub_field3" : "yet another subfield",
"sub_field4" : "yet another subfield",
"sub_field5" : "yet another subfield",
"sub_field6" : "yet another subfield",
"sub_field7" : "yet another subfield",
"sub_field8" : "yet another subfield",
"sub_field9" : "yet another subfield"
}
}
}
}
]
}
}Great! It's easy to see how this strategy could be useful when you don't know what type of documents you are going to ingest, so using Runtime Fields sounds like a conservative approach with a nice tradeoff between performance and mapping complexity.
Note on using Kibana and Runtime Fields
Keep in mind that if we don't specify a field when searching on Kibana using its search bar, (for example, just typing "hello" instead of "message: hello",that search will match all fields, and that includes all runtime fields we have declared. You probably don't want this behavior, so our index must use the dynamic setting index.query.default_field. Set it to be all or some of our mapped fields, and leave the runtime fields to be queried explicitly (e.g., "transaction.field3: hey").
Our updated mapping would finally be:
PUT dynamic-mapping-runtime
{
"mappings": {
"dynamic": "runtime",
"properties": {
"message": {
"type": "text"
},
"transaction": {
"properties": {
"user": {
"type": "keyword"
},
"amount": {
"type": "long"
}
}
}
}
},
"settings": {
"index": {
"query": {
"default_field": [
"message",
"transaction.user"
]
}
}
}
}Choosing the best strategy
Each strategy has its own advantages and disadvantages, so the best strategy will ultimately depend on your specific use case. Below is a summary to help you make the right choice for your needs:
|
Strategy |
Pros |
Cons |
|
#1 - strict |
Stored documents are guaranteed to be compliant with the mapping |
Documents are rejected if they have fields that are not declared in the mapping |
|
#2 - dynamic: false |
Stored documents can have any number of fields, but only mapped fields will use resources |
Fields that are not mapped cannot be used for searches or aggregations |
|
#3 - Runtime Fields |
All advantages of #2 Runtime Fields can be used in Kibana like any other field |
Relative slower search response times when querying the Runtime Fields |
Observability is where the Elastic Stack really shines. Whether it involves securely storing years of financial transactions while tracking impacted systems or ingesting several terabytes of daily network metrics, our customers are doing Observability ten times faster at a fraction of the cost.
Looking to get started with Elastic Observability? The best way is in the cloud. Start your free trial of Elastic Cloud today!
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print