What is text classification?
Text classification definition
Text classification is a type of machine learning that categorizes text documents or sentences into predefined classes or categories. It analyzes the content and meaning of the text and then uses text labeling to assign it the most appropriate label.
Real-world applications of text classification include sentiment analysis (which determines positive or negative sentiments in reviews), spam detection (like spotting junk emails), and topic categorization (like organizing news articles into relevant topics). Text classification plays a major role in natural language processing (NLP) by enabling computers to understand and organize large amounts of unstructured text. This simplifies tasks such as content filtering, recommendation systems, and customer feedback analysis.
Types of text classification
Types of text classification you might encounter include:
Text sentiment analysis determines the sentiment or emotion expressed in a piece of text, usually categorizing it as positive, negative, or neutral. It’s used to analyze product reviews, social media posts, and customer feedback.
Toxicity detection, related to text sentiment analysis, identifies offensive or harmful language online. It helps moderators of online communities maintain a respectful digital environment in online discussions, comments, or social media posts.
Intent recognition is another subset of text sentiment analysis used to understand the purpose (or intention) behind a user's text input. Chatbots and virtual assistants often use intent recognition to respond to user queries.
Binary classification categorizes text into one of two classes or categories. A common example is spam detection, which classifies text, such as emails or messages, into either spam or legitimate categories to automatically filter out unsolicited and potentially harmful content.
Multiclass classification categorizes text into three or more distinct classes or categories. This makes it easier to organize and retrieve information from content such as news articles, blog posts, or research papers.
Topic categorization, related to multiclass classification, groups documents or articles into predefined topics or themes. For example, news articles can be categorized into topics like politics, sports, and entertainment.
Language identification determines the language in which a piece of text is written. This is useful in multilingual contexts and language-based applications.
Named entity recognition focuses on identifying and classifying named entities within a text, such as names of people, organizations, locations, and dates.
Question classification deals with categorizing questions based on the expected answer type, which can be useful for search engines and question-answering systems.
Text classification process
The text classification process involves several steps, from data collection to model deployment. Here is a quick overview of how it works:
Step 1: Data collection
Collect a set of text documents with their corresponding categories for the text labeling process.
Step 2: Data preprocessing
Clean and prepare the text data by removing unnecessary symbols, converting to lowercase, and handling special characters such as punctuation.
Step 3: Tokenization
Break the text apart into tokens, which are small units like words. Tokens help find matches and connections by creating individually searchable parts. This step is especially useful for vector search and semantic search, which give results based on user intent.
Step 4: Feature extraction
Convert the text into numerical representations that machine learning models can understand. Some common methods include counting the occurrences of words (also known as Bag-of-Words) or using word embeddings to capture word meanings.
Step 5: Model training
Now that the data is clean and preprocessed, you can use it to train a machine learning model. The model will learn patterns and associations between the text’s features and their categories. This helps it understand the text labeling conventions using the pre-labeled examples.
Step 6: Text labeling
Create a new, separate dataset to start text labeling and classifying new text. In the text labeling process, the model separates the text into the predetermined categories from the data collection step.
Step 7: Model evaluation
Take a close look at the trained model's performance in the text labeling process to see how well it can classify the unseen text.
Step 8: Hyperparameter tuning
Depending on how the model evaluation goes, you may want to adjust the model's settings to optimize its performance.
Step 9: Model deployment
Use the trained and tuned model to classify new text data into their appropriate categories.
Why is text classification important?
Text classification is important because it enables computers to automatically categorize and understand large volumes of text data. In our digital world, we encounter massive amounts of textual information all the time. Think emails, social media, reviews, and more. Text classification allows machines to organize this unstructured data into meaningful groups using text labeling. By making sense of impenetrable content, text classification improves efficiency, makes decision-making easier, and enhances the user experience.
Text classification use cases
Text classification use cases span a variety of professional environments. Here are some real-world use cases you may encounter:
- Automating and categorizing customer support tickets, prioritizing them, and routing them to the right teams for resolution.
- Analyzing customer feedback, survey responses, and online discussions to spot market trends and consumer preferences.
- Tracking social media mentions and online reviews to monitor your brand’s reputation and sentiment.
- Organizing and tagging content on websites and e-commerce platforms using text labeling or tags to make it easier to discover content, which improves your customers’ user experiences.
- Identifying potential sales leads from social media and other online sources based on specific keywords and criteria.
- Analyzing your competitor's reviews and feedback to get insights into their strengths and weaknesses.
- Segmenting your customers based on their interactions and feedback using text labeling to tailor marketing strategies and campaigns to them.
- Detecting fraudulent activities and transactions in your financial systems based on text labeling patterns and anomalies (also known as anomaly detection).
Techniques and algorithms for text classification
Here are some techniques and algorithms used for text classification:
- Bag-of-Words (BoW) is a simple technique that counts word occurrences without considering their order.
- Word embeddings utilize various techniques that convert words into numerical representations plotted in a multidimensional space, thus capturing the complex relationships between the words.
- Decision trees are machine learning algorithms that create a tree-like structure of decision nodes and leaves. Each node tests a word's presence, which helps the tree learn patterns in the text data.
- Random forest is a method that combines multiple decision trees to improve accuracy in text classification.
- BERT (Bidirectional Encoder Representations from Transformers) is a sophisticated transformer-based classification model that can understand the context of words.
- Naive Bayes calculates the probability of a given document belonging to a particular class based on the occurrence of words in the document. It estimates the likelihood of each word appearing in each class and combines these probabilities using Bayes' theorem (a fundamental theorem in probability theory) to make predictions.
- SVM (Support Vector Machine) is a machine learning algorithm used for binary and multiclass classification tasks. SVM looks for the hyperplane that best separates the data points of different classes in a high-dimensional feature space. This helps it make accurate predictions on new, unseen text data.
- TF-IDF (Term Frequency-Inverse Document Frequency) is a method that measures the importance of words in a document compared to the entire dataset.
Evaluation metrics in text classification
Evaluation metrics in text classification are used to measure the performance of the model in different ways. Some common evaluation metrics include:
Accuracy
The proportion of correctly classified text samples out of the total samples. It gives an overall measure of the model's correctness.
Precision
The proportion of correctly predicted positive samples out of all predicted positive samples. It indicates how many of the predicted positive instances were actually correct.
Recall (or sensitivity)
The proportion of correctly predicted positive samples out of all actual positive samples. It measures how well the model identifies positive instances.
F1 score
A balanced measure that combines precision and recall, giving you an overall assessment of the model's performance when it encounters imbalanced classes.
Area Under the Receiver Operating Characteristic Curve (AUC-ROC)
A graphical representation of the model's ability to distinguish between different classes. This is especially handy in binary classification.
Confusion matrix
A table that shows the number of true positives, true negatives, false positives, and false negatives. It gives you a detailed breakdown of your model's performance.
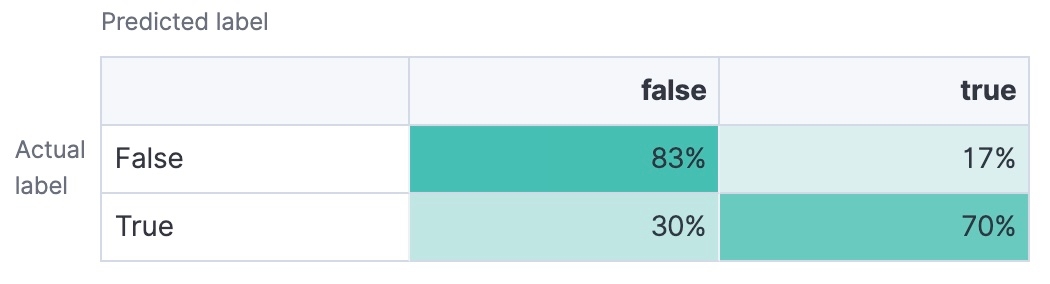
In the end, your goal should be to choose a text classification model with high accuracy, precision, recall, and F1 score, depending on your specific needs. AUC-ROC and the confusion matrix can also offer helpful insights into your model's ability to handle different classification thresholds and give you a better understanding of its performance.
Future trends in text classification
Future trends in text classification range from open AI to industry-specific tools. As machine learning technology expands, so will the capabilities of text classification. For example, as the tools and tech on the cutting edge become more accessible, they also need to become more diverse. We will soon see multilingual text classification emerge to support the growing need for multilingual support in global applications, effectively analyzing multiple languages in the same data set. Domain-specific text classification is also set to take off as models get trained to give more specific, and thus more accurate, classifications tailored to industries like legal, medical, or finance.
Of course, text classification trends will play a hand in new AI capabilities. As AI applications become more prevalent, there is a growing need for transparent and interpretable text classification models. Explainable AI involves incorporating explainability methods to understand the reasoning behind model predictions.
Deep learning models — like CNNs (convolutional neural networks) and RNNs (recurrent neural networks) — and hybrid models are neural network architectures that are being applied to text classification. CNNs are primarily used for image processing tasks, and RNNs are designed to handle sequential data, but both have demonstrated the ability to successfully understand text patterns. Hybrid models combine multiple architectures (such as CNNs, RNNs, and transformer-based models such as BERT) to leverage the strengths of different approaches for better text classification.
Future research also may explore techniques that enable text classification models to learn from fewer labeled examples (few-shot learning) or even perform text classification in classes unseen during training (zero-shot learning). Both have the potential to significantly reduce the reliance on large-labeled datasets, making text classification more scalable and adaptable to new tasks.
Text classification with Elastic
Text classification is one of many natural language processing features you will find in Elastic Search solutions. With Elasticsearch, you can classify your unstructured text, extract information from it, and apply it to your business needs quickly and easily.
Whether you need it for search, observability, or security, Elastic lets you leverage text classification to extract and organize information more efficiently for your business.