Elastic Stackの標準構成(ロギング編)
Elastic Stackは幅広いユースケースで使用されています。ウェブサイトや、商品や企業内のドキュメントの検索、ログや、セキュリティ分析、ビジネス分析、IoTセンサーから出力されるメトリックの分析、可視化など、業種や規模を問わず利用されています。では、そのElastic Stackの標準的な構成は、どのようなものになるでしょうか。特にログを保存するようなユースケースを考えてみましょう。
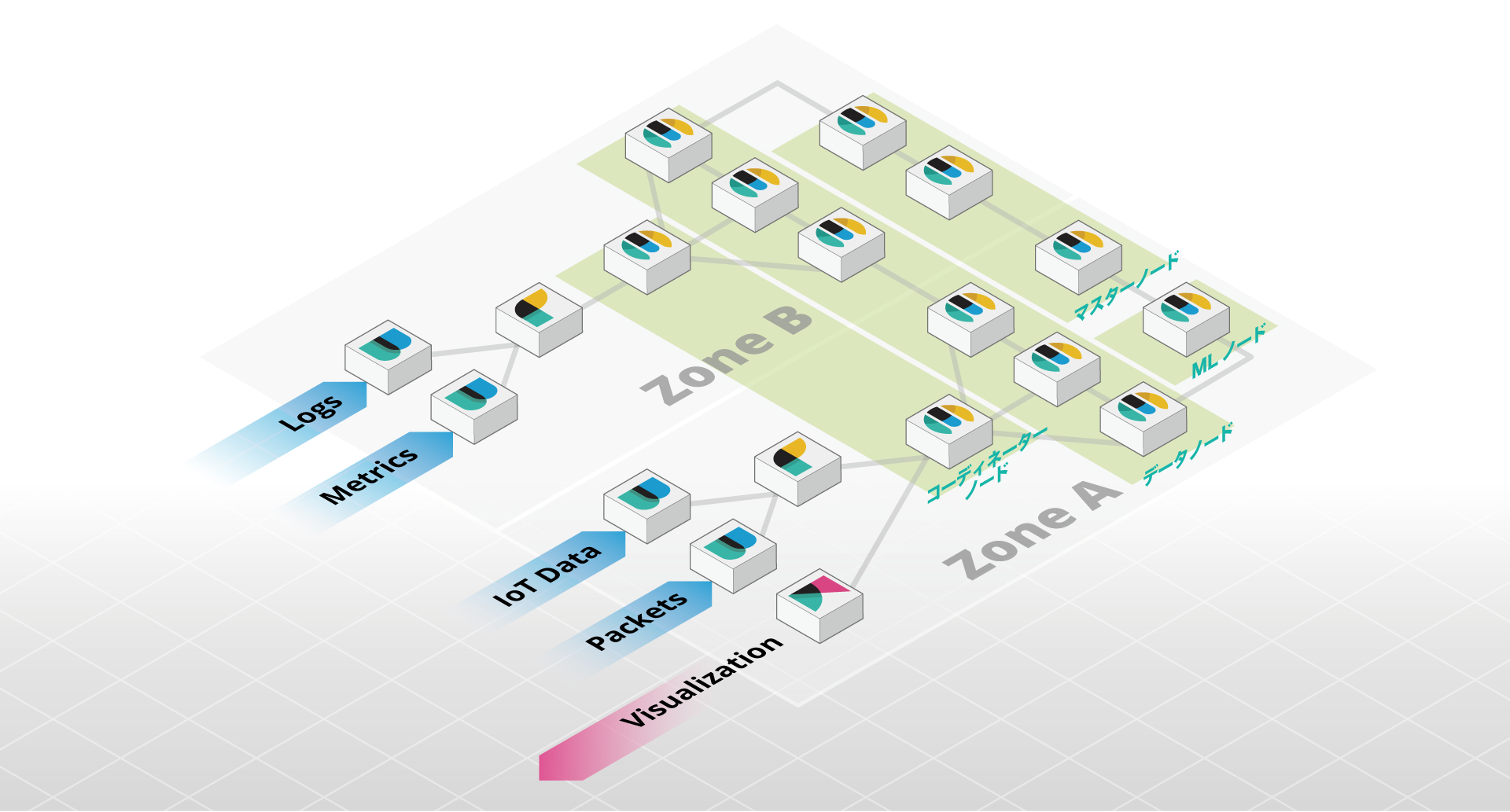
ログを収集する(Logstash、Beats)
ログやメトリックの収集には、LogstashやBeats(Filebeat、Metricbeat、Packetbeat、Winlogbeat、Auditbeat、Heartbeat)を使用します。Beatsは、軽量なログ・メトリック収集のためのエージェントとして、生成元のサーバーに直接インストールすることができます。例えば、Filebeatをウェブサーバーにインストールし、アクセスログをElasticsearchに送ることができます。Logstashは高機能なパイプラインプロセッサーとして、多様なデータソース、データの加工やエンリッチメントを行います。出力先はElasticsearchに限りません。大規模な環境では、Beatsで収集したデータを一旦Logstashに集約し、必要な加工を行ったのちに、Elasticsearchに送信するといったことがよく行われます。複雑なログのパースをGrokで行うといった場合には、高性能なCPUを持ったサーバーをLogstashに割り当てることをお勧めします。
ログを受信する(コーディネーター専用ノード)
LogstashやBeatsから、Elasticsearchのデータノードに直接送信することも出来ますが、その前段にコーディネーター専用ノードを設けることが出来ます。これは、適切なデータノードにトラフィックをルートする、ロードバランサーのような役割を担います。コーディネーター専用ノードを設置しない場合、各データノードがコーディネーターとしての役割を兼ねることになり、自身がログをインデックスするのと同時に、他のノードへのトラフィックも転送します。Beatsからデータを投入する場合には、ログのパースや加工を行うインジェストノードとしての役割を兼ねることができます。
データを保存する(データノード)
Elasticsearchは、投入されたデータを、データノードに保存します。単位時間あたりに保存することが出来る量は、ストレージのI/O性能に大きく依存しますので、ハードウェアに直接接続されたSSDを使用するのが第一の選択肢です。パブリッククラウドのIaaSや、プライベートクラウドの仮想環境で運用する場合には、インスタンスストアなどと呼ばれる揮発性(エフィネラル)ストレージが第一の選択肢です。1台のデータノードに、無限にデータを蓄えることができるわけではありません。1台のデータノードが管理することができるインデックスのサイズの上限は、ElasticのオフィシャルマネージドサービスであるElasticsearch Serviceで採用している基準にしたがって、64GBの物理メモリあたり5TB程度と考えていただくのが良いでしょう。
ログのサイズとインデックスサイズの関係
1日800GBのログが出力され、その全てをElasticsearchにインデックスしたら、どの程度のストレージが必要でしょうか。Elasticsearchは、高速でリアルタイムな検索のために転置インデックスやレプリカなどを作成しますので、元のログに比べて情報量は増加しています。その割合は、ログの種類や、インデックスの設定、マッピングに大きく依存します。これらがどの程度の影響があるかを記したブログがあります。これによると、Apacheのログに対して明示的なマッピングとDEFLATE(best_compression)圧縮を施した場合に、元のログのサイズの50%弱になることがわかります(Structured data file. Test 4)。何もマッピングを指定しなかった場合には、Elastic Stack 5.0で採用されたtextとkeywordのマルチフィールドとしてマッピングされます。この場合には、60%程度になるようです(Structured data file. Test 2)。これに1つのレプリカを作成した場合には、合計インデックスサイズは2倍になります。つまり、1日あたり800GBのログをインデックスし、30日間保存したい場合には、少なくとも24TBぐらいのストレージが必要であると言えます。
マスター(候補)ノード
マスターノードは、クラスターステートと呼ばれるクラスター内で一意に共有される仮想的なインデックスを管理します。このクラスターステートで、各ノードの役割や設定、インデックスの設定、マッピングなどの重要な情報を管理しています。マスターノードは他のノードからのクラスターステートのリクエストに、いつでも即時に応える必要があります。特にログを保存するようなユースケースの場合には、データーノードやその他の役割のノードからは分離させることが求められます。
マスター候補ノードは3台以上必要です。これは、スプリットブレインと呼ばれる問題を避けるためで、多数派のマスター候補ノードが属するクラスターでのみマスターノードを選出し、そうでないクラスターではデータの登録を防ぐためのに更新を行わせない、重要な要素です。
マシンラーニング(ML)ノード
IT運用の分野では、ネットワークトラフィックやCPU使用率の急激な上昇や下降、セキュリティ分析においては、攻撃元のIPアドレスなど、他とは違った振る舞いを検出するために、Elastic Stackの機械学習が使用されています。この機械学習のジョブはElasticsearchにインデックスされるデータを常に監視し、異常検知のためのモデルを構築するのと同時に、異常が認められればアラート機能を使って、メールやSlackで担当者に通知したり、ウェブフックで外部のシステムと連携を行ったりします。ネットワークやCPUの負荷が高い処理ですので、その他の役割を持ったノードとは分離してください。
可用性ゾーンと配置
パブリッククラウドを使用している場合には、可用性ゾーンが提供されている場合があります。プライベートクラウドやオンプレミスで運用する場合でも、仮想マシンの物理ホスト、サーバーのラック、レーン、ビルディングなど、異なる可用性を持つ範囲があります。それらに適切にElastic Stackの各コンポーネントを配置する必要があります。
LogstashやBeatsのデータソースによっては、大量にデータが生成されることが考えられ、後段であるElasticsearchにスムーズにデータを送信することは、部分的な消失を防ぐ上で欠かせません。コーディネーター専用ノードは、各ゾーンにそれぞれ1台以上設置し、LogstashやBeatsの出力先として、両方とも設定しておきます。これでいずれかのゾーンが利用不可能な状態になっても、処理を継続することができます。
データノードは、必要な台数を各ゾーンに割り当てますが、2つの可用性ゾーンがある場合、いずれか一方のみで運用が継続できるよう設計します。3つの可用性ゾーンがあれば、1ゾーンで障害時が発生した場合には、残りの2つのゾーンで運用します。Elasticsearchのフォースアウェアネスを使って、レプリカが適切に異なるゾーンに配置されるよう、ノード、インデックス、双方設定を行ってください。
先の毎日800GBのログを収集し30日間保存するケースでは、各可用性ゾーンにぞれぞれ3-4台のデータノードを配置します。
マスター候補ノードは、2つの可用性ゾーンがあれば、1台、2台に分けて配置します。3ゾーンの場合には、それぞれ1台マスター候補ノードを配置します。
MLノードは、1台以上をいずれかのゾーンに配置します。配置されたゾーンで障害が発生した場合には、異常が検知できなくなる可能性がありますが、復旧次第、遡って異常検知を再開します。
Kibanaのサーバーとしての主な役割は、静的なコンテンツの配信とレポートの生成です。Elasticsearchノードに比べて、その負荷は高くありませんので、多くの場合、処理を分散させる必要はありませんが、利用者からの求めに応じて複数のゾーンにKibanaのインスタンスを配置し、ロードバランサー経由で接続させるような構成も考えられます。Kibanaが接続するElasticsearchは、コーディネーター専用ノードです。
各Elasticsearchノードの実際の設定
初期設定では、全てのElasticsearchノードは、全ての役割を持つことができます。これまでの説明にしたがって、elasticsearch.ymlを以下のように設定します。
マスター候補ノード
discovery.zen.ping.unicast.hosts: [master-1, master-2, master-3] discovery.zen.minimum_master_nodes: 2 node.master: true node.data: false node.ingest: false node.ml: false
データノード
discovery.zen.ping.unicast.hosts: [master-1, master-2, master-3] discovery.zen.minimum_master_nodes: 2 node.master: false node.data: true node.ingest: false node.ml: false node.attr.zone: zone1
コーディネーター専用ノード
discovery.zen.ping.unicast.hosts: [master-1, master-2, master-3] discovery.zen.minimum_master_nodes: 2 node.master: false node.data: false node.ingest: true node.ml: false
MLノード
discovery.zen.ping.unicast.hosts: [master-1, master-2, master-3] discovery.zen.minimum_master_nodes: 2 node.master: false node.data: false node.ingest: false node.ml: true
Elasticsearchノードをコマンドラインなどで起動している場合には、bin/elasticsearch -E discovery.zen.ping.unicast.hosts=master1,master2,master3 -E discovery.zen.minimum_master_nodes=2 -E node.master=true -E node.data=false -E node.ml=false -E node.ingest=false(マスター候補ノードの場合)などとオプションとして与えることができます。
この他、Elasticsearchが使用するヒープサイズ(通常は物理メモリの半分)の設定を、jvm.optionsファイルに行ってください。通常は31GBを上限に設定します。
まとめ
Elastic Stackの標準的な構成を案内しました。正しい設計や設定は、クラスターの安定運用に大きく寄与します。特にElastic Stackの活用が広がるようになると、後に構成を変更することは運用負荷が増えますので、事前に十分検討してください。ご不安な場合には、アドバイスを差し上げますので、こちらのフォームよりお気軽にお問い合わせください。
また、ElasticのオフィシャルマネージドサービスであるElasticsearch Serviceを使えば、これらの設定があらかじめ行われているだけでなく、ログを分析・可視化するためによりストレージを有効活用するHot/Warm構成や、ワンクリックでのクラスターの起動やアップグレードなど、運用を助ける機能が提供されています。合わせてぜひご検討ください。