Was sind Vektoreinbettungen?
Definition des Begriffs „Vektoreinbettungen“
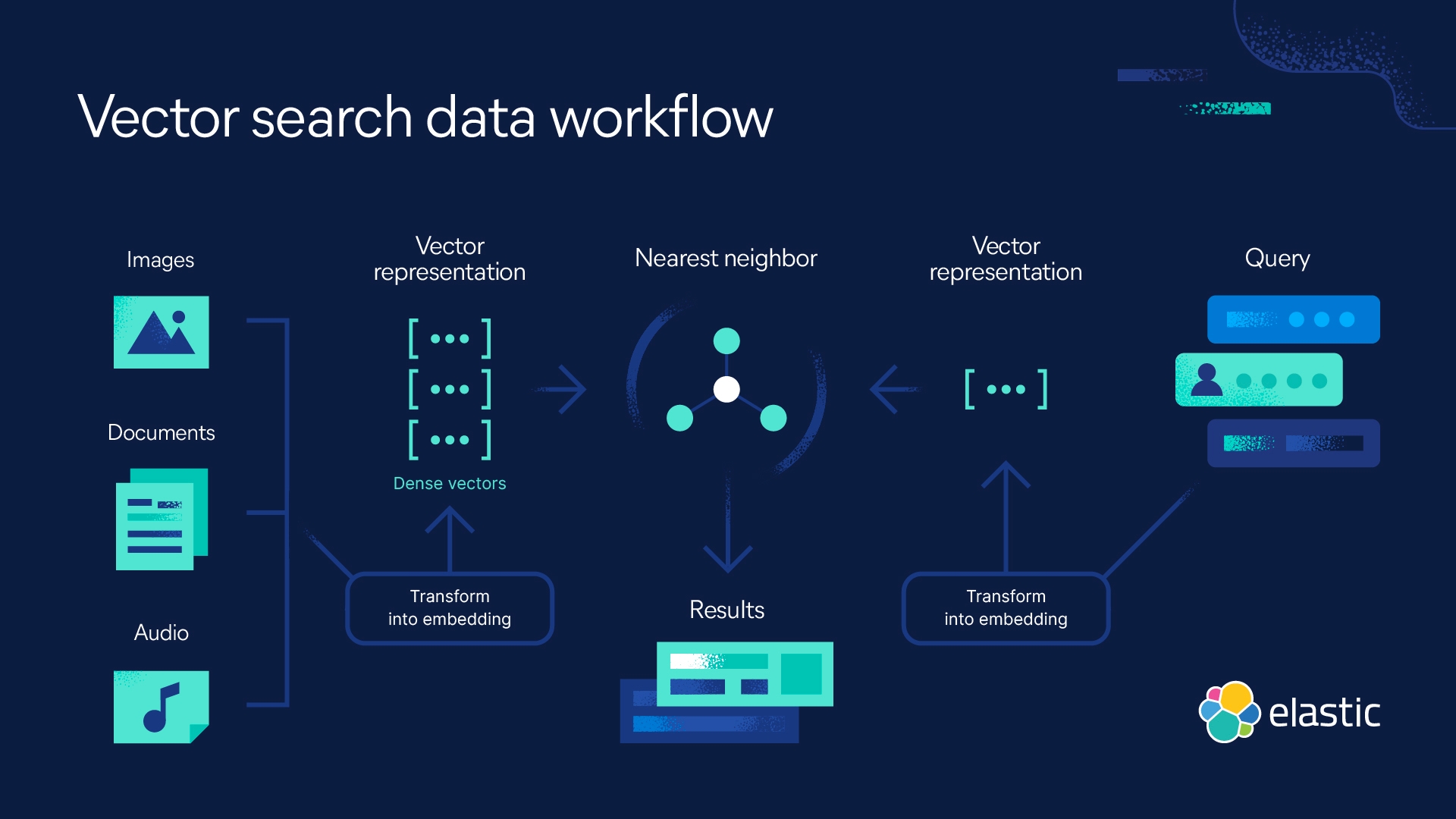
Vektoreinbettungen sind eine Möglichkeit, Wörter, Sätze und andere Daten in Zahlen umzuwandeln, die deren Bedeutung und Beziehungen erfassen. Sie stellen unterschiedliche Datentypen als Punkte in einem mehrdimensionalen Raum dar, wobei ähnliche Datenpunkte näher beieinander liegen. Diese numerischen Darstellungen helfen Maschinen, diese Daten effektiver zu verstehen und zu verarbeiten.
Wort- und Satzeinbettungen gehören zu den häufigsten Unterarten von Vektoreinbettungen, es gibt aber auch noch andere. Einige Vektoreinbettungen können ganze Dokumente darstellen. Darüber hinaus kommen auch Bildvektoren zum Abgleich visueller Inhalte, Nutzerprofilvektoren zur Ermittlung der Vorlieben der Nutzerin oder des Nutzers, Produktvektoren zur Identifizierung ähnlicher Produkte und viele andere Vektorarten mehr zum Einsatz. Vektoreinbettungen helfen Machine-Learning -Algorithmen dabei, Muster in Daten zu finden und Aufgaben wie Sentimentanalyse, Sprachübersetzung, Empfehlungssysteme und vieles mehr durchzuführen.
Arten von Vektoreinbettungen
Es gibt verschiedene Arten von Vektoreinbettungen, die häufig in verschiedenen Anwendungen verwendet werden. Hier nur einige Beispiele:
Worteinbettungen stellen einzelne Wörter als Vektoren dar. Methoden wie Word2Vec, GloVe und FastText lernen Worteinbettungen, indem sie semantische Beziehungen und Kontextinformationen aus großen Textkorpora erfassen.
Satzeinbettungen stellen ganze Sätze als Vektoren dar. Modelle wie Universal Sentence Encoder (USE) und SkipThought generieren Einbettungen, die die Bedeutung und den Kontext der Sätze in ihrer Gesamtheit erfassen.
Dokumenteinbettungen stellen Dokumente (Zeitungsartikel, wissenschaftliche Abhandlungen, Bücher usw.) als Vektoren dar. Sie erfassen die semantischen Informationen und den Kontext des gesamten Dokuments. Algorithmen wie Doc2Vec und Paragraph Vectors sind in der Lage, Dokumenteneinbettungen zu lernen.
**Bildeinbettungen** erfassen verschiedene visuelle Merkmale und nutzen diese, um Bilder als Vektoren darzustellen. Methoden wie CNNs (Convolutional Neural Networks) und vortrainierte Modelle wie ResNet und VGG generieren Bildeinbettungen, die bei der Erledigung von Aufgaben wie Bildklassifizierung, Objekterkennung und Erkennung ähnlicher Bilder helfen.
Nutzereinbettungen stellen Nutzer:innen in einem System oder auf einer Plattform als Vektoren dar. Sie erfassen Vorlieben, Verhaltensweisen und Eigenschaften der Nutzer:innen. Nutzereinbettungen können in vielerlei Bereichen eingesetzt werden – von Empfehlungssystemen über personalisiertes Marketing bis hin zur Nutzersegmentierung.
Produkteinbettungen stellen Produkte im E‑Commerce oder in Empfehlungssystemen als Vektoren dar. Sie erfassen die Attribute, Merkmale, Funktionen und alle anderen verfügbaren semantischen Informationen des jeweiligen Produkts. Algorithmen können diese Einbettungen nutzen, um Produkte anhand ihrer Vektordarstellungen zu vergleichen, zu empfehlen und zu analysieren.
Sind Einbettungen und Vektoren dasselbe?
Im Kontext von Vektoreinbettungen gilt: Ja, die Begriffe „Einbettung“ und „Vektor“ beschreiben dasselbe. Beide beziehen sich auf numerische Darstellungen von Daten, wobei jeder Datenpunkt durch einen Vektor in einem hochdimensionalen Raum dargestellt wird.
Der Begriff „Vektor“ beschreibt dabei ein Array von Zahlen, das eine bestimmte Dimensionalität besitzt. Im Fall der Vektoreinbettungen repräsentieren diese Vektoren jeden der oben genannten Datenpunkte in einem kontinuierlichen Raum. Dagegen bezieht sich der Begriff „Einbettung“ speziell auf die Methode, Daten als Vektoren so darzustellen, dass sinnvolle Informationen, semantische Beziehungen oder kontextbezogene Merkmale erfasst werden. Die Aufgabe von Einbettungen besteht darin, die zugrunde liegende Struktur oder die Eigenschaften der Daten zu erfassen. Sie werden in der Regel durch Trainingsalgorithmen oder Modelle erlernt.
Die Begriffe „Einbettung“ und „Vektor“ sind zwar im Zusammenhang mit Vektoreinbettungen austauschbar, aber der Begriff „Einbettung“ betont das Konzept der Darstellung von Daten in einer sinnvollen und strukturierten Weise, während der Begriff „Vektor“ sich auf die numerische Darstellung selbst bezieht.
Wie werden Vektoreinbettungen erstellt?
Vektoreinbettungen werden durch einen Machine-Learning-Prozess erstellt, bei dem ein Modell darauf trainiert wird, die oben genannten Daten (und andere) in numerische Vektoren umzuwandeln. Zusammengefasst funktioniert das wie folgt:
- Zunächst muss ein ausreichend großes Dataset zusammengesammelt werden, das die Art der Daten repräsentiert, für die Sie Einbettungen erstellen möchten, also z. B. Text oder Bilder.
- Als Nächstes müssen Sie diese Daten vorverarbeiten. Das umfasst, je nach Art der Daten, verschiedene Aufgaben, vom Herausfiltern von unerwünschtem Rauschen bis zum Normalisieren von Text oder zum Verkleinern bzw. Vergrößern von Bildern.
- Anschließend wählen Sie ein Modell für ein neuronales Netz aus, das für Ihre Datenziele geeignet ist, und speisen die vorverarbeiteten Daten in das Modell ein.
- Das Modell lernt Muster in den Daten und Beziehungen zwischen ihnen, indem es während des Trainings seine internen Parameter anpasst. Es lernt beispielsweise, häufig zusammen auftretende Wörter miteinander in Zusammenhang zu bringen oder optische Merkmale in Bildern zu erkennen.
- Beim Lernen erzeugt das Modell numerische Vektoren (oder Einbettungen), die die Bedeutung oder die Eigenschaften der Daten darstellen. Jeder Datenpunkt, z. B. jedes Wort oder jedes Bild, wird durch einen eindeutigen Vektor dargestellt.
- An diesem Punkt können Sie die Qualität und Effektivität der Einbettungen bewerten, indem Sie deren Performance bei bestimmten Aufgaben messen oder Menschen beurteilen lassen, wie ähnlich die zurückgegebenen Ergebnisse sind.
- Sobald Sie festgestellt haben, dass die Einbettungen gut funktionieren, können Sie sie für die Analyse und Verarbeitung Ihrer Datasets einsetzen.
Wie sehen Vektoreinbettungen aus?
Die Länge oder Dimensionalität des Vektors hängt vom konkret verwendeten Einbettungsverfahren und davon ab, wie die Daten dargestellt werden sollen. Wenn Sie z. B. Worteinbettungen erstellen, haben diese oft Dimensionen, die von einigen Hundert bis zu einigen Tausend reichen – das ist für die visuelle Darstellung durch Menschen viel zu komplex. Satz- oder Dokumenteinbettungen können höhere Dimensionen haben, da sie noch komplexere semantische Informationen erfassen.
Die Vektoreinbettung selbst wird in der Regel als eine Abfolge von Zahlen dargestellt, wie z. B. [0.2, 0.8, -0.4, 0,6, ...]. Jede Zahl in der Abfolge entspricht einem konkreten Merkmal oder einer konkreten Dimension und leistet einen Beitrag zur Gesamtdarstellung des Datenpunkts. Dabei sei darauf hingewiesen, dass die eigentlichen Zahlen innerhalb des Vektors für sich genommen keine Bedeutung haben. Die semantischen Informationen werden durch die relativen Werte und Beziehungen zwischen den Zahlen erfasst. Sie ermöglichen es den Algorithmen, die Daten effektiv zu verarbeiten und zu analysieren.
Anwendungsbereiche für Vektoreinbettungen
Vektoreinbettungen können in einer breiten Palette von Anwendungen in vielen Bereichen zum Einsatz kommen. Hier sind einige der häufigsten, denen Sie begegnen können:
Die Verarbeitung natürlicher Sprache (NLP) nutzt Vektoreinbettungen in großem Umfang für Aufgaben wie Sentimentanalyse, Erkennung benannter Entitäten, Textklassifizierung, maschinelle Übersetzung, Beantwortung von Fragen und Prüfung der Ähnlichkeit von Dokumenten. Durch die Einbettungen können Algorithmen textbezogene Daten effektiver verstehen und verarbeiten.
Suchmaschinen verwenden Vektoreinbettungen, um Informationen abzurufen und semantische Beziehungen zu identifizieren. Vektoreinbettungen helfen der Suchmaschine, als Antwort auf eine Suchanfrage thematisch relevante Webseiten anzuzeigen, Artikel zu empfehlen, falsch geschriebene Wörter in der Suchanfrage zu korrigieren und ähnliche zugehörige Suchanfragen vorzuschlagen, die Nutzer:innen weiterhelfen könnten. Diese Anwendung wird häufig zur Unterstützung der semantischen Suche eingesetzt.
Systeme für personalisierte Empfehlungen nutzen Vektoreinbettungen, um Nutzervorlieben und Artikelmerkmale zu erfassen. Sie helfen dabei, Nutzerprofile mit Elementen abzugleichen, die die Nutzerin oder den Nutzer ebenfalls interessieren könnten, z. B. Produkte, Filme, Songs oder Nachrichtenartikel, und zwar auf der Grundlage enger Übereinstimmungen zwischen der Nutzerin oder dem Nutzer und den Elementen im Vektor. Ein bekanntes Beispiel dafür ist das Empfehlungssystem von Netflix. Haben Sie sich schon einmal gefragt, wie es ihm gelingt, Filme auszuwählen, die Ihrem Geschmack entsprechen? Das System bewertet, welche Elemente (Filme) eine große Ähnlichkeit mit den Inhalten aufweisen, die sich die Nutzerin oder der Nutzer normalerweise ansieht.
Visuelle Inhalte können ebenfalls über Vektoreinbettungen analysiert werden. Algorithmen, die auf diese Arten von Vektoreinbettungen trainiert sind, können Bilder klassifizieren, Objekte identifizieren und sie in anderen Bildern erkennen, nach ähnlichen Bildern suchen und die verschiedensten Arten von Bildern (und Videos) in konkrete Kategorien einordnen. Ein Beispiel für ein häufig genutztes Tool zur Bildanalyse ist die von Google Lens verwendete Bilderkennungstechnologie.
Anomalieerkennung Algorithmen verwenden Vektoreinbettungen, um ungewöhnliche Muster oder Ausreißer in verschiedenen Datentypen zu identifizieren. Der Algorithmus wird auf Einbettungen trainiert, die normales Verhalten darstellen, sodass er lernen kann, auf der Grundlage von Abständen oder Unähnlichkeitswerten zwischen Einbettungen Abweichungen von der Norm zu erkennen. Dies ist besonders hilfreich bei Cybersecurity -Anwendungen.
Graph Analytics verwendet Grapheinbettungen, bei denen die Graphen eine Sammlung von Punkten („Knoten“) sind, die durch Linien („Kanten“) verbunden sind. Jeder Knoten stellt eine Entität dar, z. B. eine Person, eine Webseite oder ein Produkt, und jede Kante stellt eine Beziehung oder Verbindung zwischen diesen Entitäten dar. Diese Vektoreinbettungen können Freunde in sozialen Netzwerken vorschlagen, Cybersicherheitsanomalien erkennen (siehe oben) und vieles andere mehr.
Auch Audio und Musik können verarbeitet und eingebettet werden. Vektoreinbettungen erfassen Audiomerkmale, die es Algorithmen erlauben, effektiv Audiodaten zu analysieren. Dies kann für eine Vielzahl von Anwendungen wie Musikempfehlungen, Genreklassifizierung, Audio-Ähnlichkeitssuche, Spracherkennung und Sprecherverifizierung genutzt werden.
Vektoreinbettung mit Elasticsearch
Die Elasticsearch-Plattform ist von sich aus in der Lage, leistungsstarkes Machine Learning und KI in Lösungen zu integrieren. So können Sie Anwendungen entwickeln, von denen Ihre Nutzer:innen profitieren und die dazu beitragen, die anstehende Arbeit schneller zu erledigen. Elasticsearch ist die zentrale Komponente des Elastic Stack, einer Sammlung von Open-Source-Tools für das Ingestieren, Anreichern, Speichern, Analysieren und Visualisieren von Daten.
Mit Elasticsearch können Sie:
- Benutzererlebnisse und Conversions optimieren
- neue Einblicke gewinnen, Abläufe automatisieren, Daten analysieren und Berichte generieren
- Die Produktivität Ihrer Mitarbeiter mit internen Dokumenten und Anwendungen steigern
Experimentieren Sie mit hochmodernen KI-Suchfunktionen mit Ihren eigenen Daten mithilfe von AI Playground.