Was ist Machine Learning?
Definition: Machine Learning
Machine Learning (ML) ist eine zur künstlichen Intelligenz (KI) gehörende Disziplin, die Daten und Algorithmen einsetzt, um das Lernvermögen von Menschen zu imitieren und ihre Genauigkeit im Lauf der Zeit zu verbessern. Der Begriff wurde erstmalig in den 1950er Jahren von Arthur Samuel, einem Computerwissenschaftler und KI-Vordenker, definiert als „Forschungsgebiet, das Computer in die Lage versetzt, zu lernen, ohne explizit programmiert zu werden“.
Beim Machine Learning werden Computeralgorithmen mit großen Mengen an Daten gefüttert und lernen, Muster und Beziehungen in diesen Daten zu identifizieren. Anschließend erstellen die Algorithmen eigene Vorhersagen oder Entscheidungen auf Basis ihrer Analysen. Wenn die Algorithmen neue Daten erhalten, verfeinern sie ihre Auswahlprozesse und ihre Leistung, ähnlich wie eine Person, die ihre Aufgaben mit zunehmender Übung immer besser erledigt.
In welche vier Arten lässt sich der Bereich Machine Learning unterteilen?
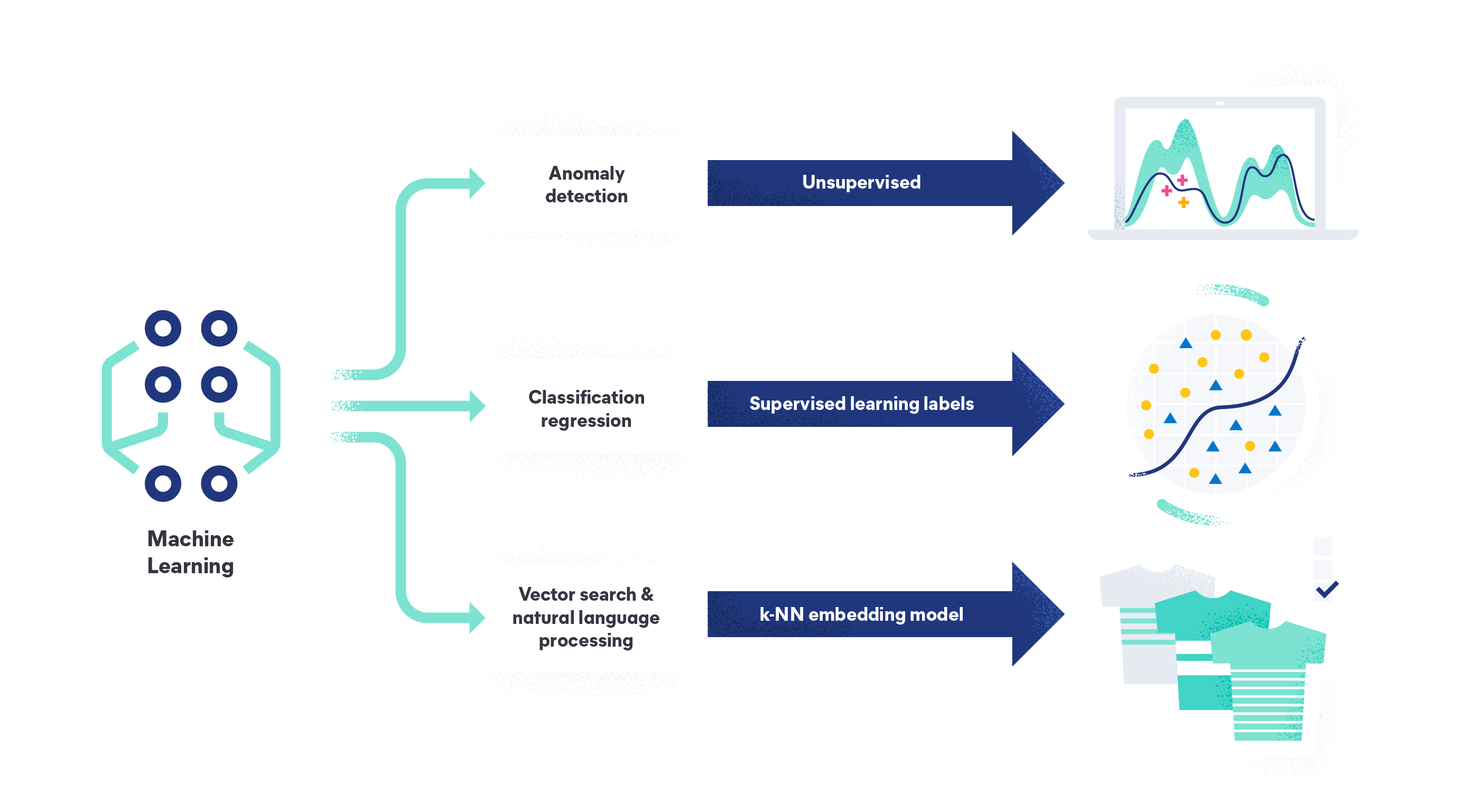
Machine Learning lässt sich in die Kategorien beaufsichtigtes Machine Learning, unbeaufsichtigtes Machine Learning, teilweise beaufsichtigtes Lernen und verstärkendes Lernen unterteilen.
Beaufsichtigtes Machine Learning ist die am häufigsten verwendete Art von Machine Learning. In beaufsichtigten Lernmodellen lernt der Algorithmus anhand von markierten Trainingsdatensätzen und verbessert seine Genauigkeit mit der Zeit. Auf diese Weise entsteht ein Modell, das Zielvariablen korrekt vorhersagen kann, wenn es Daten erhält, die es noch nicht gesehen hat. In einem solchen Modell könnten Menschen beispielsweise Bilder von Rosen und anderen Blumen markieren und das Modell damit füttern. Anschließend kann der Algorithmus neue, unmarkierte Bilder von Rosen korrekt identifizieren.
Unbeaufsichtigtes Machine Learning bedeutet, dass der Algorithmus nach Mustern in unmarkierten Daten sucht und keine Zielvariablen verwendet. Das Ziel besteht darin, Muster und Beziehungen in den Daten zu finden, die den Menschen noch nicht aufgefallen sind, wie etwa Anomalien in Logs, Traces und Metriken, um Systemprobleme und Sicherheitsbedrohungen aufzudecken.
Teilweise beaufsichtigtes Lernen ist eine Mischung aus beaufsichtigtem und unbeaufsichtigtem Machine Learning. Beim teilweise beaufsichtigten Lernen wird der Algorithmus mit markierten und unmarkierten Daten trainiert. Er lernt zunächst anhand einer kleinen Menge an markierten Daten, um Vorhersagen oder Entscheidungen auf Basis der verfügbaren Informationen treffen zu können. Anschließend werden die Vorhersagen oder Entscheidungen mit dem größeren, unmarkierten Datensatz verfeinert, indem die Daten nach Mustern und Beziehungen durchsucht werden.
Verstärkendes Lernen bedeutet, dass der Algorithmus durch Versuch und Irrtum lernt und Feedback in Form von positiven oder negativen Rückmeldungen für seine Aktionen erhält. Mögliche Beispiel sind ein KI-Agent, der lernt, ein Videospiel zu spielen, indem er Belohnungen für abgeschlossene Level und negatives Feedback für Fehler erhält, die Optimierung einer Lieferkette, indem der Agent für Kostensenkungen oder schnellere Auslieferungen belohnt wird oder Empfehlungssysteme, in denen der Agent Produkte oder Inhalte vorschlägt und durch Käufe und Klicks belohnt wird.
Wie funktioniert Machine Learning?
Machine Learning funktioniert auf verschiedene Arten. Sie können vorab trainierte Machine-Learning-Modelle auf neue Daten anwenden oder ein neues Modell von Grund auf trainieren.
Ein vorab trainiertes Machine-Learning-Modell auf neue Daten anzuwenden ist meistens schneller und weniger ressourcenintensiv. Anstatt die Parameter beim Training zu entwickeln, können Sie die Modellparameter verwenden, um Vorhersagen für Eingabedaten zu treffen. Diesen Prozess nennt man Inferenz. Dabei müssen Sie sich auch keine Gedanken um die Leistung machen, da diese bereits in der Trainingsphase ausgewertet wurde. Sie müssen jedoch die Eingabedaten sorgfältig vorbereiten, um sicherzustellen, dass sie im gleichen Format vorliegen wie die Daten, mit denen das Modell trainiert wurde.
Das Trainieren eines neuen Machine-Learning-Modells umfasst die folgenden Schritte:
Datenerfassung
Wählen Sie zunächst Ihre Datensätze aus. Die Daten können aus einer Vielzahl von Quellen stammen, wie etwa System-Logs, Metriken und Traces. Neben Logs und Metriken können Sie beim Machine Learning-Training noch verschiedene weitere Arten von Zeitreihendaten verwenden, wie etwa:
- Daten von Finanzmärkten, wie etwa Aktienkurse, Zinssätze und Devisenkurse. Diese Daten werden oft verwendet, um prädiktive Modelle zu Handels- und Investitionszwecken zu erstellen.
- Zeitreihendaten aus dem Transportwesen, wie etwa Verkehrsaufkommen, Geschwindigkeit und Reisezeiten. Diese Daten sind hilfreich, um Routen zu optimieren und Verkehrsstaus zu minimieren.
- Produktnutzungsdaten, wie etwa der Datenverkehr auf Websites oder Social-Media-Interaktionen. Mit diesen Daten können Unternehmen das Kundenverhalten besser verstehen und Verbesserungsmöglichkeiten identifizieren.
Dabei kommt es immer darauf an, dass Ihre verwendeten Daten relevant für das zu lösende Problem und repräsentativ für die Population sind, für die Sie Vorhersagen oder Entscheidungen treffen möchten.
Vorverarbeitung der Daten
Im Anschluss an die Erfassung müssen Sie die Daten vorverarbeiten, um sie für den Machine-Learning-Algorithmus nutzbar zu machen. Bei diesem Prozess können Sie die Daten beispielsweise markieren oder den einzelnen Datenpunkten in einem Datensatz Kategorien oder Werte zu weisen, damit das Machine-Learning-Modell Muster lernen und Vorhersagen treffen kann.
Außerdem können Sie fehlende Werte entfernen, Zeitreihendaten in ein kompakteres Format transformieren, indem Sie Aggregationen anwenden oder Daten skalieren, um sicherzustellen, dass alle Features ähnliche Wertebereiche verwenden. Für Deep Neural Networks wie etwa umfassende Sprachmodelle (Large Language Models, LLMs) ist es wichtig, eine große Menge an markierten Trainingsdaten zu verwenden. Für klassische beaufsichtigte Modelle ist dieser Prozess weniger wichtig.
Featureauswahl
Für bestimmte Ansätze müssen Sie auswählen, welche Features das Modell verwenden soll. Dabei identifizieren Sie die Variablen oder Attribute, die für das zu lösende Problem besonders relevant sind. Korrelationen sind ein einfacher Weg, um Features zu identifizieren. Für die weitere Optimierung sind Featureauswahlmethoden verfügbar, die von vielen ML-Frameworks unterstützt werden.
Modellauswahl
Nachdem Sie die Features ausgewählt haben, müssen Sie ein Machine-Learning-Modell auswählen, das sich gut für das zu lösende Problem eignet. Dabei können Sie unter anderem zwischen Regressionsmodellen, Entscheidungsstrukturen und neuronalen Netzen wählen. (Siehe Machine-Learning-Techniken und -Algorithmen weiter unten.)
Training
Nachdem Sie Ihr Modell ausgewählt haben, können Sie es mit den erfassten und vorverarbeiteten Daten trainieren. Beim trainieren lernt der Algorithmus, Muster und Beziehungen in den Daten zu identifizieren und in den Modellparametern zu kodieren. Für eine optimale Performance sollte das Training iterativ vorgenommen werden. Dabei können Sie beispielsweise Hyperparameter für das Modell abstimmen oder Datenverarbeitung und Featureauswahl verbessern.
Testen
Nachdem Sie das Modell trainiert haben, können Sie es mit neuen Daten testen, die es bisher noch nicht gesehen hat, und seine Leistung mit anderen Modellen vergleichen. Dabei wählen Sie das Modell mit der besten Leistung aus und bewerten die Leistung anhand von separaten Testdaten. Sie müssen bislang noch nicht verwendete Daten einsetzen, um die zukünftige Leistung Ihres Modells objektiv einschätzen zu können.
Modell bereitstellen
Sobald Sie mit der Leistung des Modells zufrieden sind, können Sie es in einer Produktionsumgebung bereitstellen, in der es Vorhersagen und Entscheidungen in Echtzeit treffen kann. Dazu können Sie das Modell beispielsweise mit anderen Systemen oder Softwareanwendungen integrieren. ML-Frameworks, die mit den beliebtesten Cloud-Computing-Anbietern integriert sind, können die Bereitstellung von Modellen in der Cloud deutlich vereinfachen.
Monitoring und Aktualisierung
Nachdem Sie das Modell bereitgestellt haben, müssen Sie dessen Leistung überwachen und es regelmäßig aktualisieren, wenn neue Daten verfügbar sind oder sich das zu lösende Problem im Lauf der Zeit verändert. Dazu müssen Sie das Modell mit neuen Daten trainieren, die Parameter anpassen oder auch einen völlig anderen ML-Algorithmus auswählen.
Warum ist Machine Learning so wichtig?
Machine Learning ist wichtig, weil dabei komplexe Aufgaben anhand von Beispielen erlernt werden, ohne spezialisierte Algorithmen programmieren zu müssen. Im Gegensatz zu algorithmischen Herangehensweisen können Sie mit Machine Learning mehr automatisieren, bessere Kundenerlebnisse anbieten und innovative Anwendungen erstellen, die bislang nicht machbar waren. Außerdem können sich Machine-Learning-Modelle mit zunehmender Nutzung iterativ selbst verbessern! Beispiele:
- Vorhersage von Trends für bessere Geschäftsentscheidungen
- Personalisierung von Empfehlungen zur Umsatzsteigerung und zur Verbesserung der Kundenzufriedenheit
- Automatisierung der Überwachung komplexer Anwendungen und IT-Infrastrukturen
- Identifizieren von Spam und Sicherheitsverletzungen
Machine Learning-Techniken und -Algorithmen
Heutzutage gibt es viele verschiedene Machine-Learning-Techniken und -Algorithmen. Ihre Auswahl hängt von dem zu lösenden Problem und der Beschaffenheit der Daten ab. Hier ist eine kurze Übersicht über die gängigsten Varianten: Lineare Regression wird eingesetzt, um Variablen mit kontinuierlichem Verlauf vorherzusagen.
Lineare Regression geht davon aus, dass eine lineare Beziehung zwischen den Eingabevariablen und der Zielvariablen besteht. Ein mögliches Beispiel ist die Vorhersage von Immobilienpreisen als lineare Kombination aus Wohnfläche, Standort, Zimmeranzahl und weiteren Merkmalen.
Logistische Regression wird für Binärklassifizierungen verwendet, bei denen die Antwort entweder ja oder nein lautet. Die logistische Regression ermittelt die Wahrscheinlichkeit der Zielvariablen anhand eines linearen Modells von Eingabevariablen. Ein mögliches Beispiel ist die Vorhersage, ob ein Kreditantrag akzeptiert wird, anhand der Kreditbewertung und anderer Finanzdaten der Bewerber.
Entscheidungsstrukturen folgen einem baumähnlichen Modell, um Entscheidungen zu möglichen Konsequenzen zuzuordnen. Jede Entscheidung (Regel) bildet einen Test einer Eingabevariablen ab, und mehrere Regeln können nacheinander in Form eines baumähnlichen Modells angewendet werden. Dabei werden die Daten in Teilmengen unterteilt, wobei in jeder Verzweigung der Baumstruktur die jeweils signifikanteste Eigenschaft verwendet wird. Mit Entscheidungsstrukturen können beispielsweise potenzielle Kunden für Marketingkampagnen anhand von demografischen Daten und Interessen ausgewählt werden.
Zufallsbäume kombinieren mehrere Entscheidungsstrukturen, um die Vorhersagegenauigkeit zu verbessern. Jede Entscheidungsstruktur wird mit einer zufälligen Teilmenge der Trainingsdaten und einer Teilmenge der Eingabevariablen trainiert. Zufallsbäume bieten mehr Genauigkeit als einzelne Entscheidungsstrukturen und eignen sich besser für komplexe Datensätze oder fehlende Daten, können jedoch sehr groß werden und viel Speicherplatz für Inferenzanwendungen benötigen.
Verstärkte Entscheidungsstrukturen trainieren eine Abfolge von Entscheidungsstrukturen, wobei jede Entscheidungsstruktur eine Verbesserung gegenüber der vorherigen Version ist. Der Verstärkungsprozess nutzt die bei der vorherigen Iteration der Entscheidungsstruktur falsch klassifizierten Datenpunkte, um eine neue Entscheidungsstruktur zu trainieren, in der die Klassifizierung dieser Punkte verbessert wird. Das beliebte XGBoost Python-Paket implementiert diesen Algorithmus.
Support Vector Machines (SVM) versuchen, eine Hyperebene zu finden, die Datenpunkte aus einer Klasse möglichst gut von denen einer anderen Klasse trennt. Dazu wird der Abstand zwischen den Klassen minimiert. Support-Vektoren beschreiben die wenigen Beobachtungen, die den Ort der trennenden Hyperebene identifizieren, die durch drei Punkte definiert wird. Der SVM-Standardalgorithmus kann nur auf Binärklassifizierungen angewendet werden. Multiklassenprobleme werden zu einer Reihe von Binärklassifizierungen reduziert.
Neuronale Netze orientieren sich an der Struktur und Funktionsweise des menschlichen Gehirns. Sie bestehen aus miteinander verbundenen Ebenen von Knoten, die Muster in Daten erkennen, indem die Stärke der dazwischen liegenden Verbindungen angepasst wird.
Clustering-Algorithmen werden verwendet, um Datenpunkte anhand ihrer Ähnlichkeit in Cluster zu gruppieren. Diese Algorithmen können für Aufgaben wie Kundensegmentierung oder Anomalieerkennung verwendet werden. Sie sind besonders hilfreich für die Segmentierung und Verarbeitung von Bildern.
Welche Vorteile bietet Machine Learning?
Machine Learning bietet zahllose Vorteile. Machine Learning kann Ihre Team dabei unterstützen, in den folgenden Kategorien bisher ungeahnte Leistungen zu erbringen:
- Automatisierung: Kognitive Aufgaben, die Menschen schwerfallen, weil sie repetitiv oder objektiv schwierig sind, können mit Machine Learning automatisiert werden. Mögliche Beispiele sind die Überwachung komplexer vernetzter Systeme, das Identifizieren verdächtiger Aktivitäten in komplexen Systemen oder Vorhersagen zu Wartungsanforderungen von Geräten.
- Kundenerlebnis: Aus Machine-Learning-Modellen gewonnene Daten können Kundenerlebnisse verbessern. In suchbasierten Anwendungen können Sie Absichten und Wünsche erfassen, um relevante und personalisierte Ergebnisse zu liefern. Die Benutzer können intuitiv suchen und finden, wonach sie suchen.
- Innovation: Machine Learning löst komplexe Probleme, die mit speziell erstellten Algorithmen nicht lösbar sind. Sie können beispielsweise unstrukturierte Daten wie Bild- oder Audiodaten durchsuchen, Verkehrsmuster optimieren und öffentliche Transportsysteme optimieren oder Gesundheitsprobleme diagnostizieren.
Anwendungsfälle für Machine Learning
Hier sind einige Kategorien, in denen sich Anwendungsfälle für Machine Learning anbieten:
Bei der Standpunktanalyse wird natürliche Sprache verarbeitet, um Textdaten zu analysieren und herauszufinden, ob der allgemeine Standpunkt positiv, negativ oder neutral ist. Auf diese Weise können Unternehmen Kunden-Feedback erhalten, indem sie eine Vielzahl von Datenquellen (z. B. Tweets auf Twitter, Facebook-Kommentare oder Produktbewertungen) analysieren, um die Meinungen und die Zufriedenheit ihrer Kunden einzuschätzen.
Bei der Anomalieerkennung werden Algorithmen eingesetzt, um ungewöhnliche Muster oder Ausreißer, die auf Probleme hindeuten können, in Daten zu erkennen. Die Anomalieerkennung wird zur Überwachung von IT-Infrastrukturen, Onlineanwendungen und Netzwerken und zum Identifizieren von Aktivitäten eingesetzt, die auf Sicherheitsverletzungen hindeuten oder im weiteren Verlauf zu Netzwerkausfällen führen können. Mit der Anomalieerkennung können außerdem betrügerische Banktransaktionen erkannt werden. Weitere Informationen über AIOps.
Bei der Bilderkennung werden Bilder analysiert, um Gegenstände, Gesichter oder andere Merkmale in den Bildern zu erkennen. Diese Variante ist auch über gängige Tools wie die Google-Bildersuche hinaus vielseitig anwendbar. Die Bilderkennung kann beispielsweise in der Landwirtschaft eingesetzt werden, um den Zustand der Felder zu überwachen und Plagen oder Krankheiten zu erkennen. Selbstfahrende Autos, medizinische Bildgebung, Überwachungssysteme und Augmented-Reality-Spiele sind weitere Anwendungsbereiche für die Bilderkennung.
Vorhersageanalysen analysieren historische Daten und identifizieren Muster, um Vorhersagen zu zukünftigen Ereignissen oder Trends zu treffen. Auf diese Weise können Unternehmen ihren Betrieb optimieren, die Nachfrage vorhersagen und potenzielle Risiken oder Chancen identifizieren. Mögliche Beispiele sind Nachfrageprognosen für Produkte, Verkehrsverzögerungen und Laufzeitprognosen für Geräte in der Fertigungsbranche.
Weitere Informationen zum Thema prädiktive Wartung
Welche Nachteile bietet Machine Learning?
Beim Einsatz von Machine Learning sollten die folgenden Nachteile beachtet werden:
- Abhängigkeit von hochwertigen Trainingsdaten: Wenn die Daten verfälscht oder unvollständig sind, ist das Modell unter Umständen auch verfälscht oder unvollständig.
- Kosten: Beim Trainieren von Modellen und beim Vorverarbeiten der Daten können hohe Kosten entstehen. Diese Kosten sind allerdings immer noch niedriger als die Kosten für die Programmierung spezialisierter Algorithmen für dieselbe Aufgabe. Außerdem wäre ein solcher Algorithmus vermutlich weniger exakt.
- Mangelnde Nachvollziehbarkeit: Die meisten Machine-Learning-Modelle, wie etwa neuronale Netze, sind in ihrer Funktionsweise wenig transparent. In diesen häufig auch als „Blackbox-Modelle“ bezeichneten Modellen ist es nur schwer nachvollziehbar, wie eine bestimmte Entscheidung getroffen wurde.
- Fachwissen: Die Liste der verfügbaren Modelle ist lang. Ohne spezialisiertes Data-Science-Team tun sich viele Unternehmen schwer mit dem Hyperparameter-Tuning für eine optimale Leistung. Die Komplexität des Trainings, insbesondere für Transformationen, Einbettungen und umfassende Sprachmodelle, erschwert die Einführung ebenfalls.
Best Practices für Machine Learning
Beim Einsatz von Machine Learning sollten die folgenden Best Practices beachtet werden:
- Stellen Sie sicher, dass Ihre Daten bereinigt, organisiert und vollständig sind.
- Wählen Sie einen passenden Ansatz für Ihr zu lösendes Problem und Ihre Daten.
- Versuchen Sie, Überanpassung zu vermeiden, also Situationen, in denen das Modell zwar mit den Trainingsdaten gut funktioniert, aber neue Daten weniger gut verarbeitet.
- Überprüfen Sie die Leistung Ihres Modells, indem Sie es Daten testen, die es noch nie gesehen hat. Die beim Entwickeln und Optimieren Ihres Modells gemessene Leistung eignet sich nicht dazu, die Leistung des Modells im Produktionseinsatz vorherzusagen.
- Passen Sie die Einstellungen Ihres Modells an, um die Leistung zu optimieren. Dieser Vorgang wird auch als Hyperparameter-Tuning bezeichnet.
- Wählen Sie Metriken zusätzlich zur Genauigkeit des Standardmodells aus, um die Leistung Ihres Modells im Kontext Ihrer tatsächlichen Anwendung und Ihres Geschäftsproblems zu bewerten.
- Dokumentieren Sie Ihren Fortschritt umfassend, damit Ihre Arbeit für andere Personen leicht verständlich und nachvollziehbar ist.
- Aktualisieren Sie Ihr Modell fortlaufend, um sicherzustellen, dass es mit neuen Daten gut umgehen kann.
Erste Schritte mit Elastic Machine Learning
Bei Elastic Machine Learning sind die Vorteile unserer skalierbaren Elasticsearch-Plattform schon mit eingebaut. Sie erhalten leistungsstarke und vorkonfigurierte Integrationen mit Observability-, Sicherheits- und Suchlösungen, deren verwendete Modelle mit weniger Trainingsaufwand eingesetzt werden können. Mit Elastic erhalten Sie neue Einblicke und können internen Nutzern und Kunden revolutionäre, zuverlässige und skalierbare Erlebnisse bieten.
Nutzen Sie die folgenden Vorteile:
Daten aus Hunderten von Quellen ingestieren und Machine Learning sowie natürliche Sprachverarbeitung mit vorab erstellten Integrationen dort einsetzen, wo sich Ihre Daten befinden
Machine Learning frei nach Ihren Anforderungen einsetzen Direkt einsetzbare, vorkonfigurierte Modelle für Ihren Anwendungsfall nutzen: vorkonfigurierte Modelle für automatisierte Überwachungs- und Threat-Hunting-Funktionen, vorab trainierte Modelle und Transformationen für NLP-Aufgaben wie Standpunktanalysen oder zum Beantworten von Fragen, sowie den Elastic Learned Sparse Encoder™, mit dem Sie eine semantische Suche mit nur einem Klick implementieren können. Falls Ihr Anwendungsfall ein optimiertes und benutzerdefiniertes Modell erfordert, können Sie auch beaufsichtigte Modelle mit Ihren eigenen Daten trainieren. Mit Elastic können Sie jederzeit den passenden Ansatz für Ihren Anwendungsfall und Ihre Fachkenntnisse einsetzen!
Machine-Learning-Ressourcen (teils nur auf Englisch verfügbar)
Begriffserklärungen zum Thema Machine Learning
- Künstliche Intelligenz beschreibt die Fähigkeit von Maschinen, Aufgaben zu erledigen, die normalerweise menschliche Intelligenz erfordern, wie etwa Lernen, Schlussfolgern, Probleme lösen oder Entscheidungen treffen.
- Neuronale Netze sind eine Art von Machine-Learning-Algorithmus, der aus miteinander vernetzten Ebenen von Knoten besteht, die Informationen verarbeiten und übermitteln. Sie orientieren sich an der Struktur und Funktionsweise des menschlichen Gehirns.
- Deep Learning ist eine Unterart von neuronalen Netzen, die viele verschiedene Ebenen verwendet und deutlich komplexere Beziehungen lernen kann als andere Machine-Learning-Algorithmen.
- Natürliche Sprachverarbeitung (Natural Language Processing, NLP) ist ein Teilgebiet der KI mit dem Ziel, Maschinen in die Lage zu versetzen, menschliche Sprache verstehen, auswerten und generieren zu können.
- Vektorsuche ist eine Art von Suchalgorithmus, der Vektoreinbettungen und den k-Nearest-Neighbor-Algorithmus (kNN) verwendet, um relevante Informationen in großen Datensätzen zu finden.