KI für SREs
Erkennen Sie automatisch Probleme, ergreifen Sie empfohlene Maßnahmen und lösen Sie Probleme schneller mit Machine Learning (ML) und generativer KI.
Geführte Demo
Ihr stets verfügbarer Teamkollege für den Betrieb
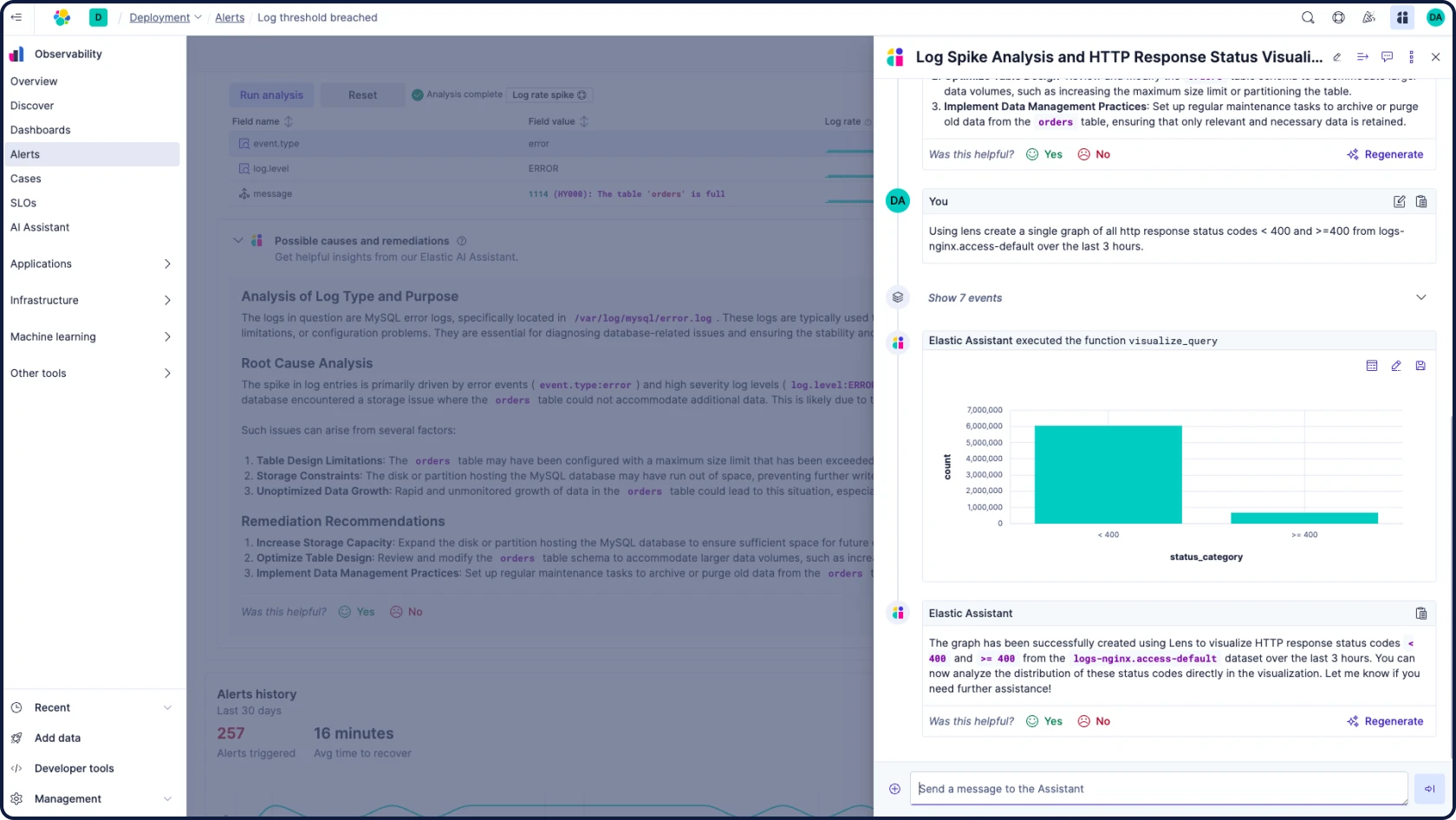
Stellen Sie Fragen in natürlicher Sprache und erhalten Sie präzise Antworten – basierend auf Ihren Beobachtungsdaten, ML-Jobs und internem Wissen wie Runbooks oder vergangenen Vorfällen.
KERN-KI-TECHNOLOGIE
Wie wir Beobachtbarkeitsdaten in operative Intelligenz umwandeln






KI-GESTEUERTE FUNKTIONEN
Lassen Sie die KI die Arbeit erledigen
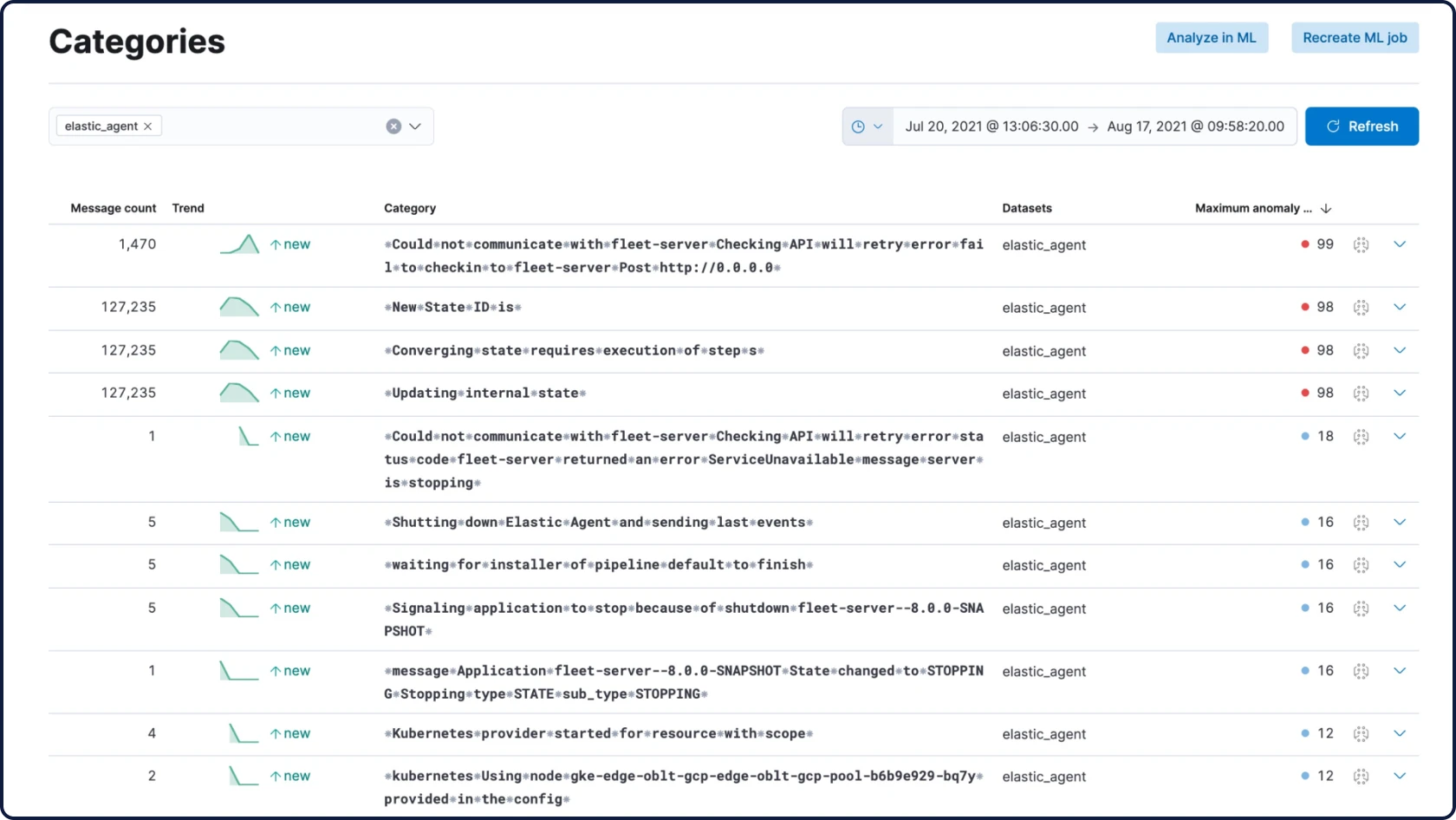
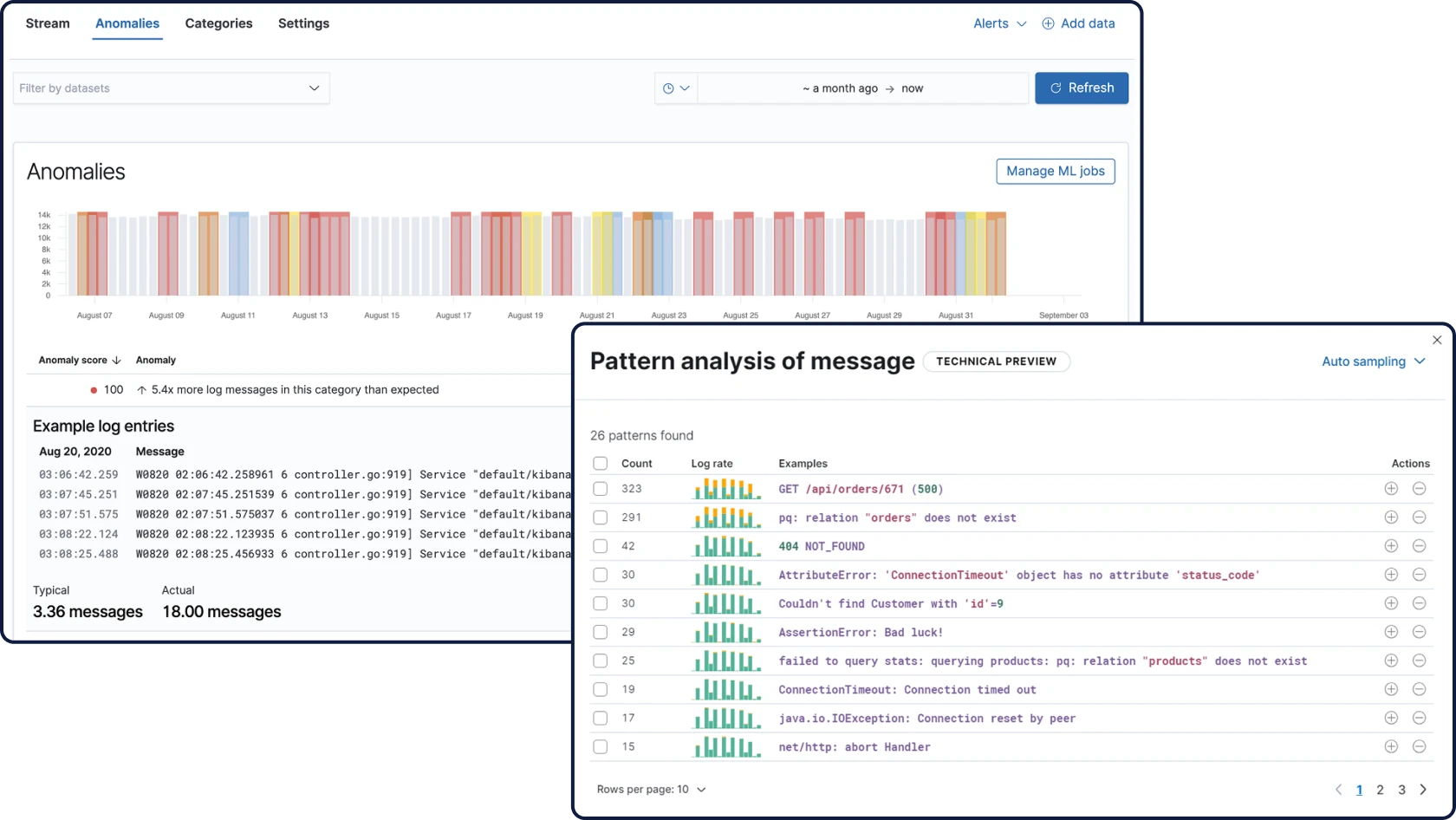
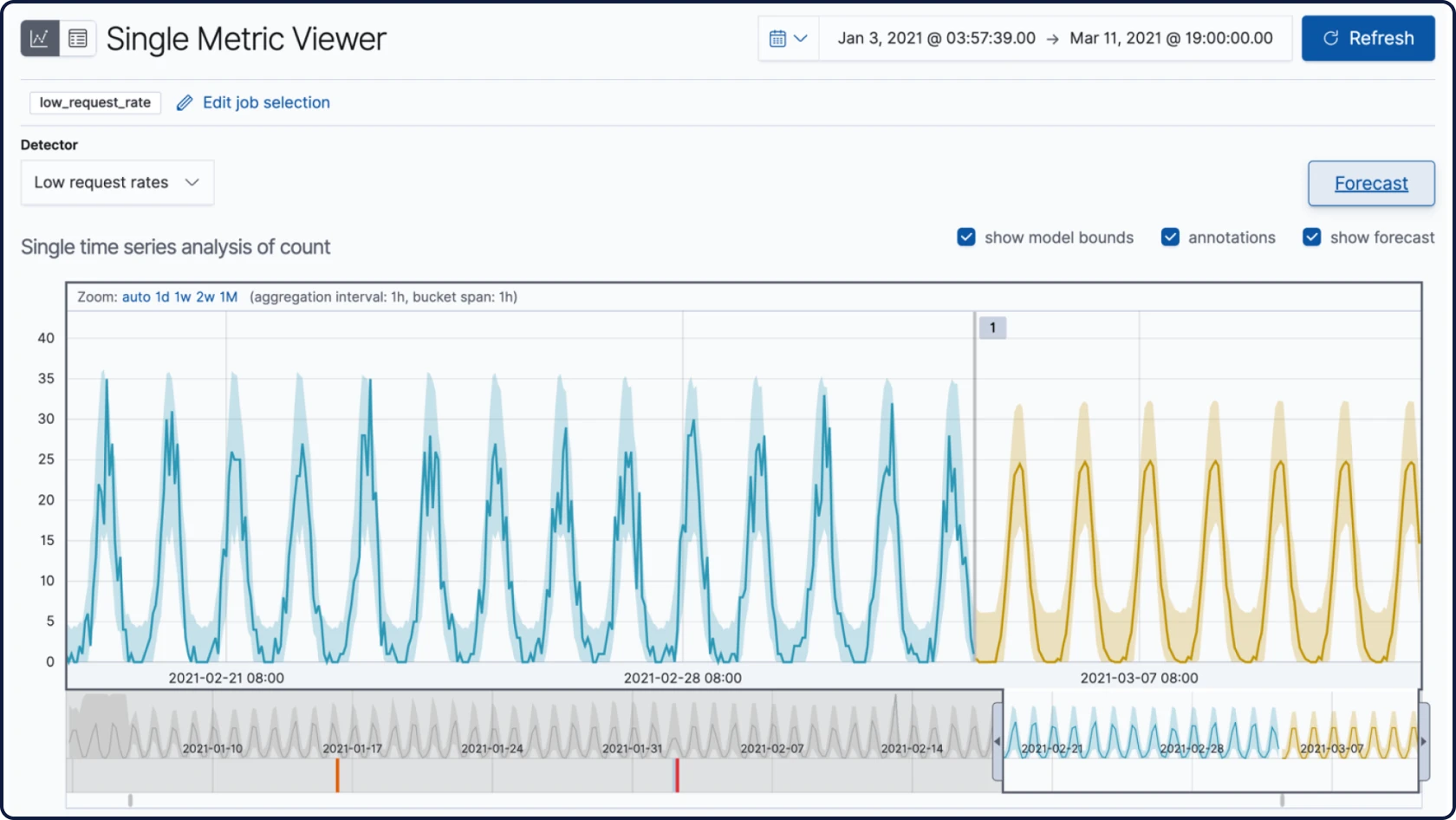
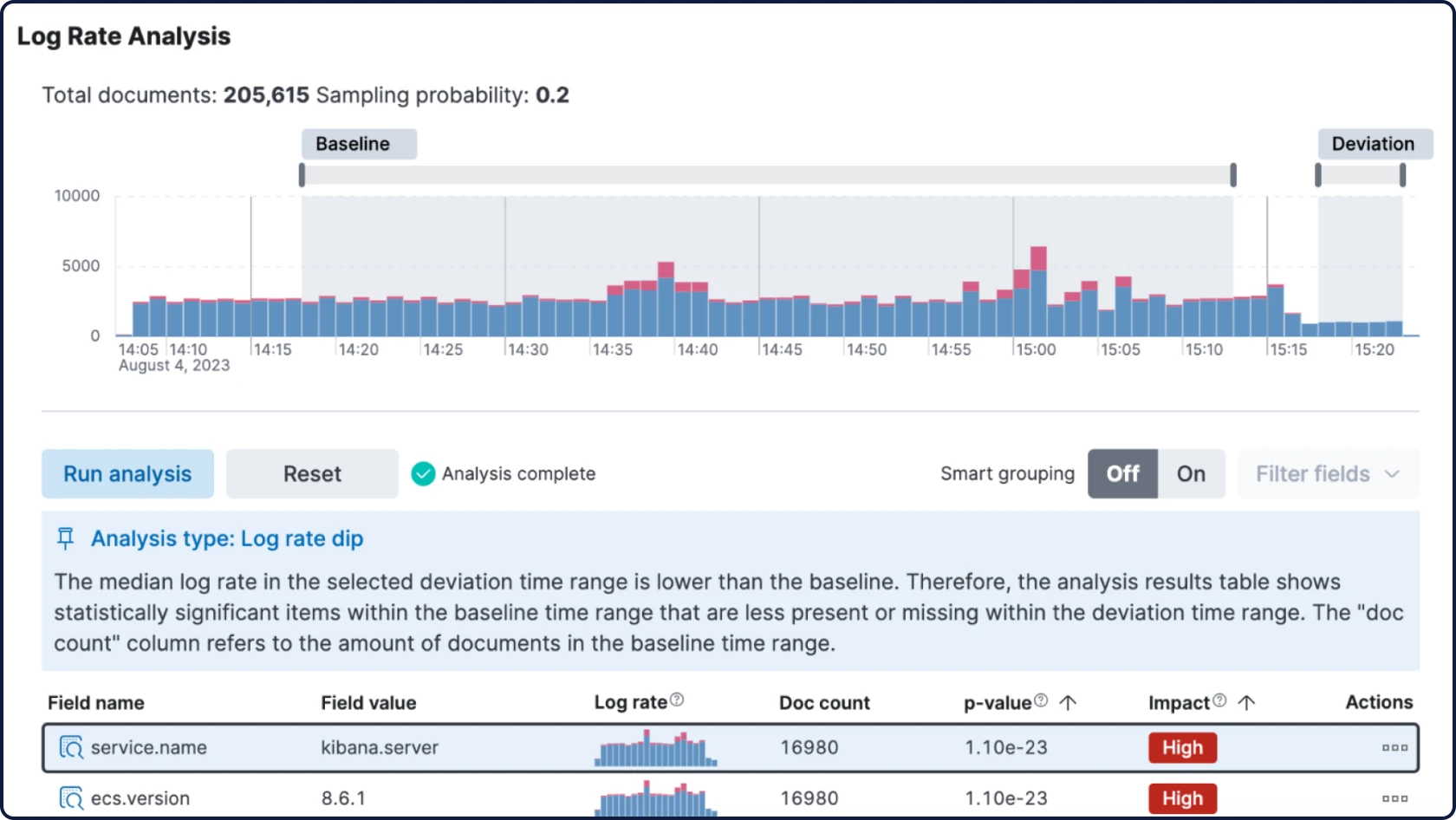
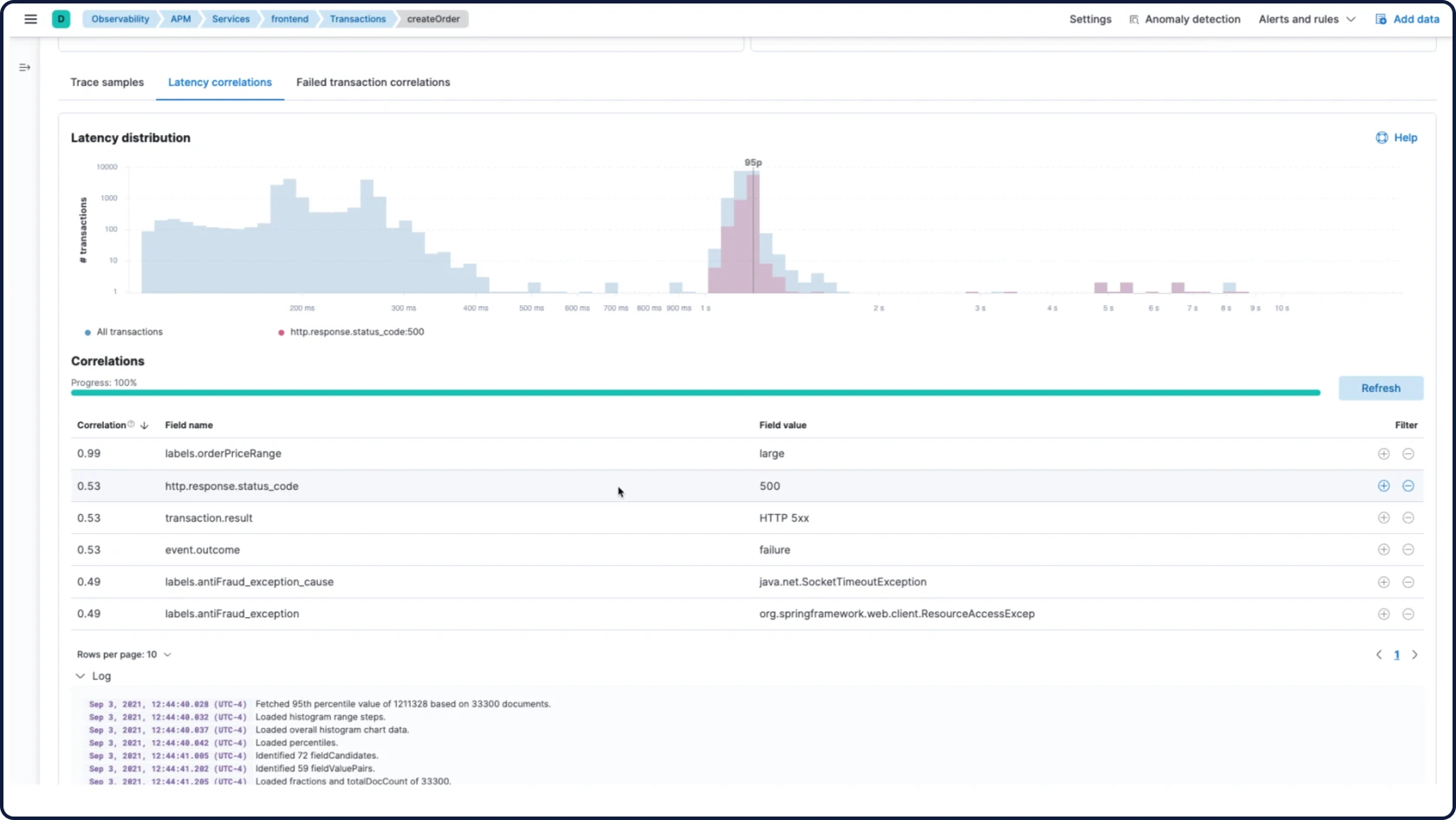
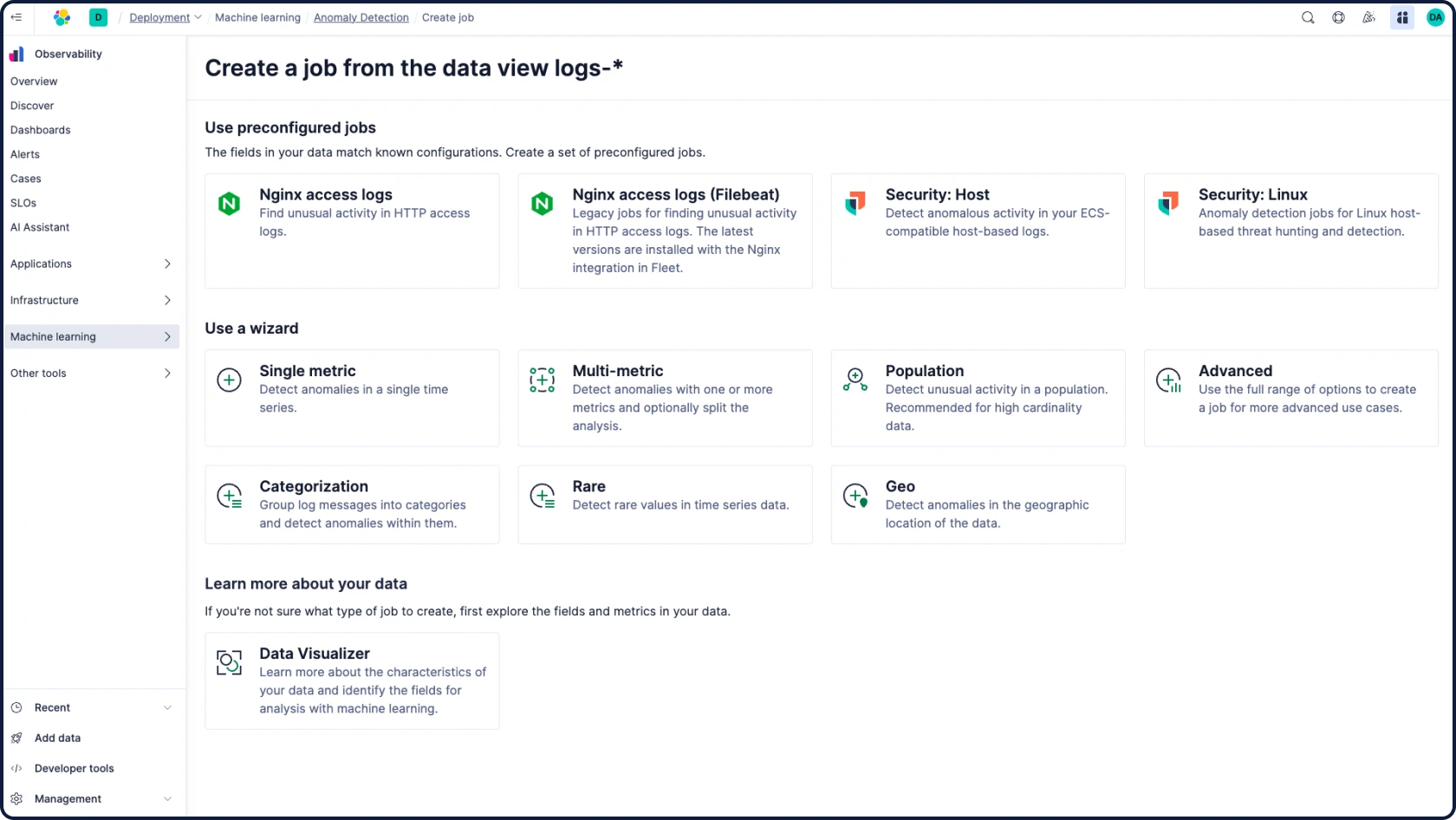
Elastic ingestiert Daten von überall her und stellt automatisch Muster dar, hebt Anomalien hervor und zeigt Spitzen auf – so erhalten Sie Antworten und vermeiden Überlastung.
- Elastic AI Assistant analysiert Ihre Beobachtbarkeitsdaten, erklärt Probleme und zeigt die relevantesten nächsten Schritte basierend auf Ihren internen Wissensdatenbanken und Runbooks durch RAG auf.
Erfahren Sie, warum sich Unternehmen wie Ihres für Elastic Observability entscheiden
Von der Ursache bis zur Lösung, beschleunigt durch KI.
Kunden-Spotlight

Dish Media nutzt Elastic, um Anomalien in Echtzeit zu erkennen, die Lösungszeiten von Stunden auf Minuten zu verkürzen und Entwicklern sofortigen Zugriff auf die benötigten Daten zu geben – alles aus einer einheitlichen Ansicht.
Kunden-Spotlight

Mithilfe des Elastic AI Assistant konnte Hexaware die Teameffizienz um 50 % steigern, da die Teams nun in der Lage sind, benutzerdefinierte Diagramme in Minuten statt in Stunden zu erstellen. Mit Elastic Machine Learning sanken die Fehlalarme um 96 %.
Kunden-Spotlight

Informatica wendet das integrierte Elastic Machine Learning auf Datenbank-, Netzwerk- und Kubernetes-Logs an, um proaktiv Anomalien zu erkennen und Probleme schneller zu lösen und gleichzeitig die Kosten für Beobachtbarkeit und Sicherheit um 50 % zu senken.