Skalierbare Infrastrukturüberwachung für hohe Kardinalität
Elastic bietet Ihnen eine Full-Stack-Beobachtbarkeit Ihrer Infrastruktur, erkennt Anomalien, ermittelt die Ursachen und automatisiert die Behebung – alles auf Basis von KI –, sodass Sie Ihre Kapazitäten besser planen und Probleme schneller beheben können. Die spaltenorientierte Speicherung sorgt für hohe Leistung bei geringen Kosten.



Voll ausgestattet mit KI, überall dort, wo Sie bereits arbeiten
Halten Sie eine funktionsfähige Konfiguration bereit, die sofort nach dem Anschließen einsatzbereit ist. Elastics Kubernetes-Überwachung enthält vorkonfigurierte Dashboards, Warnungen, SLOs und Machine-Learning-Jobs sowie Agentenfähigkeiten und eine MCP-App für Gesundheitsüberwachung, Anomalieerkennung, Vorfalluntersuchungen und Sanierung.

Erstklassige Effizienz
Erhalten Sie vollständige Transparenz in der Infrastruktur und umfangreiche Log-Analysen, ohne die Leistung zu beeinträchtigen oder Daten zu verlieren. Die Elasticsearch-Kolumnen-Metrik-Engine übertrifft andere in Bezug auf Ingest, Speicher und Abfragegeschwindigkeit bei jeder skalieren.
Erfahren Sie, wie wir Elasticsearch als führenden spaltenbasierten Metrik-Datenspeicher neu aufgebaut haben. Siehe Benchmarks.
SCHEMA-AGNOSTISCH
Ein Datenspeicher, alle Formate, kein Kontextwechsel
Die meisten Infrastruktur-Monitoring-Systeme normalisieren alles in einem einzigen Schema oder zwingen Sie, sich durch mehrere Backends und Abfragesprachen zu navigieren. Wir tun das nicht. Egal, ob Sie uns OpenTelemetry, Prometheus, Beats oder ein anderes Format senden, Elasticsearch speichert jedes nativ in einem einheitlichen Datenspeicher und fragt es unverändert ab. Keine Übersetzungsschicht, kein Informationsverlust, keine manuellen Untersuchungen.
Richten Sie den Fokus auf Ihre Infrastruktur
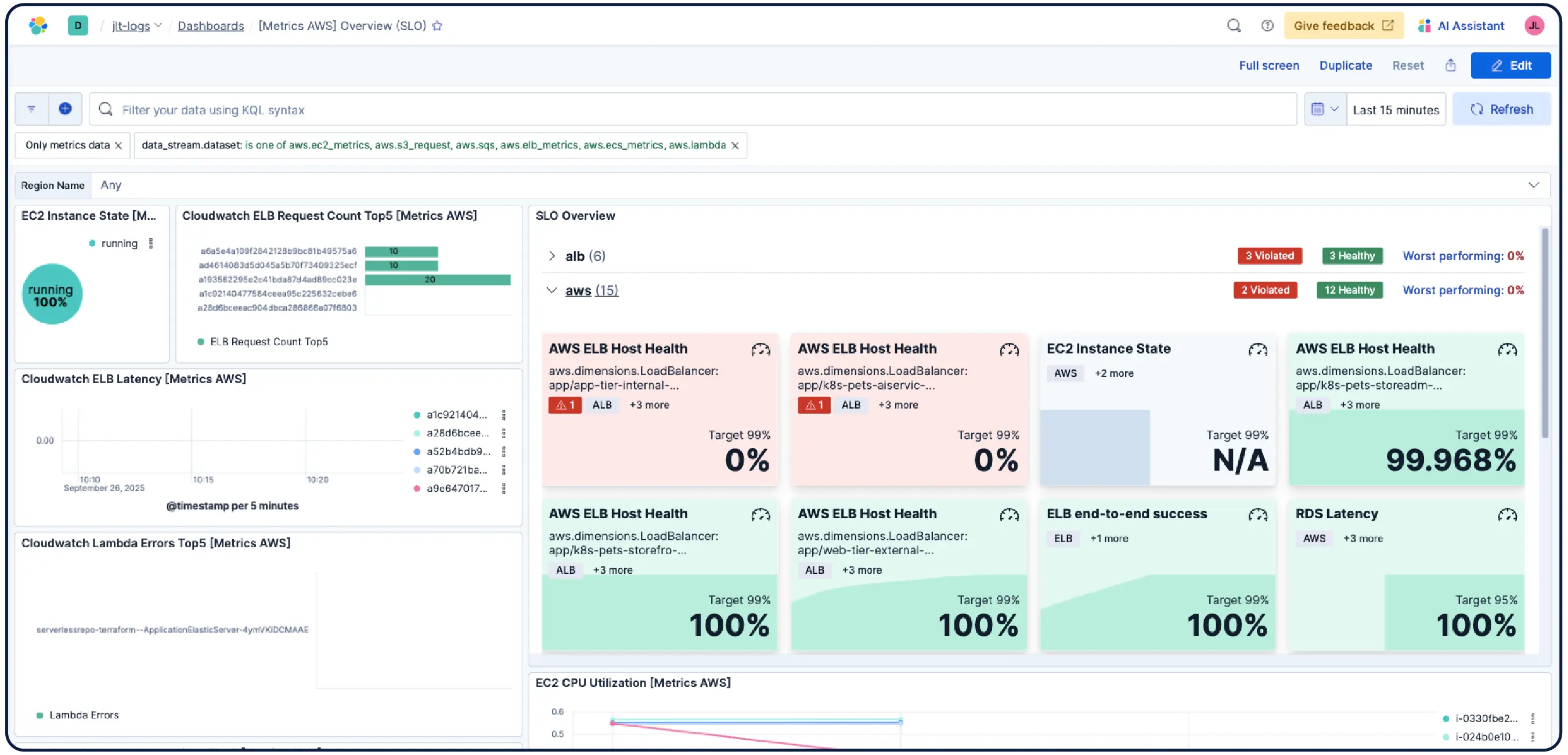
Egal, ob Sie Kubernetes-Cluster, VMs, Cloud- oder On-Prem-Server ausführen, machen unsere über 550+ vorgefertigten Integrationen, leichtgewichtigen Agenten und agentenlosen Collector für AWS, Azure und Google Cloud Platform die Ingest Painless.
Suchen, filtern, aggregieren und visualisieren Sie Daten in Discover. Speichern Sie Sitzungen in Dashboards, richten Sie Warnmeldungen ein und führen Sie ES|QL-Abfragen über beliebige Daten für eine einheitliche Analyse aus. Filtern Sie nach beliebigen Metriken auf beliebigen Dimensionen und führen Sie PromQL direkt in Kibana aus.
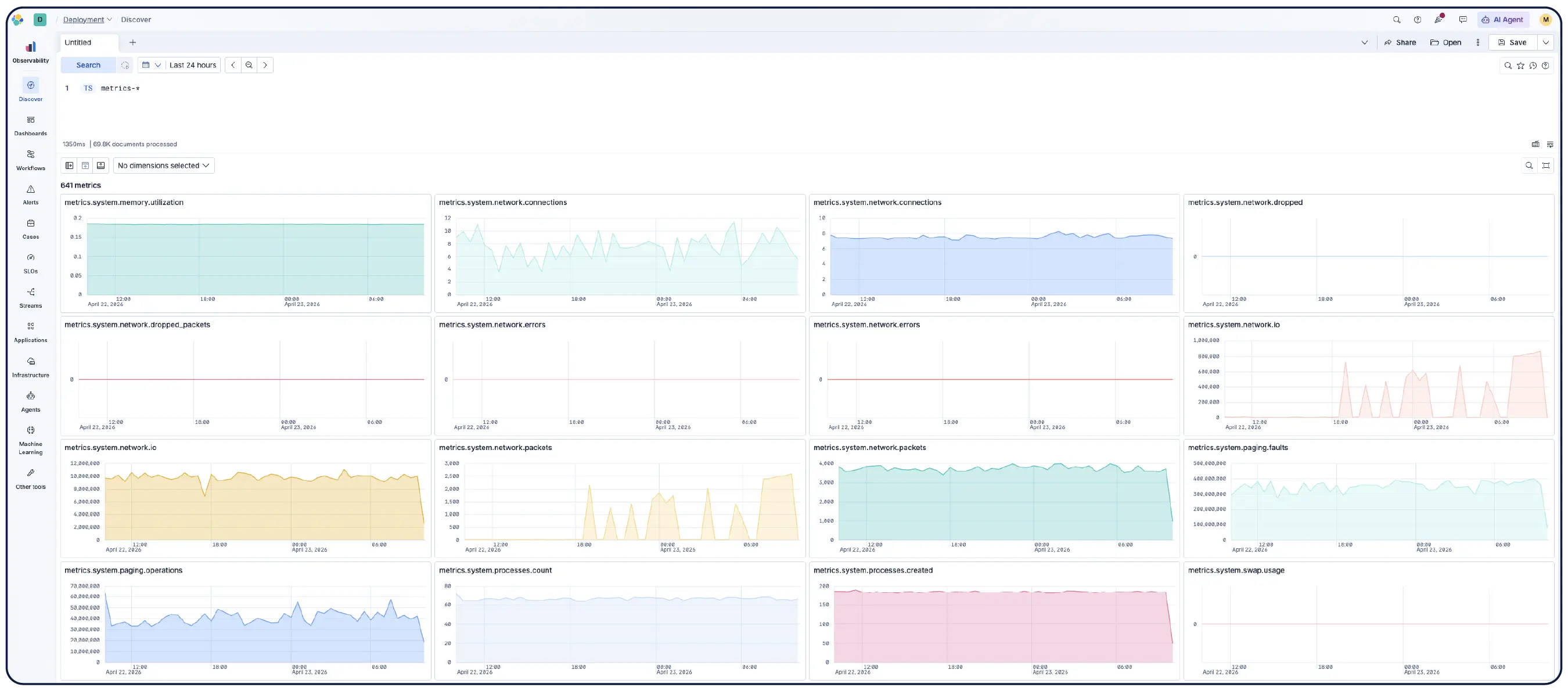
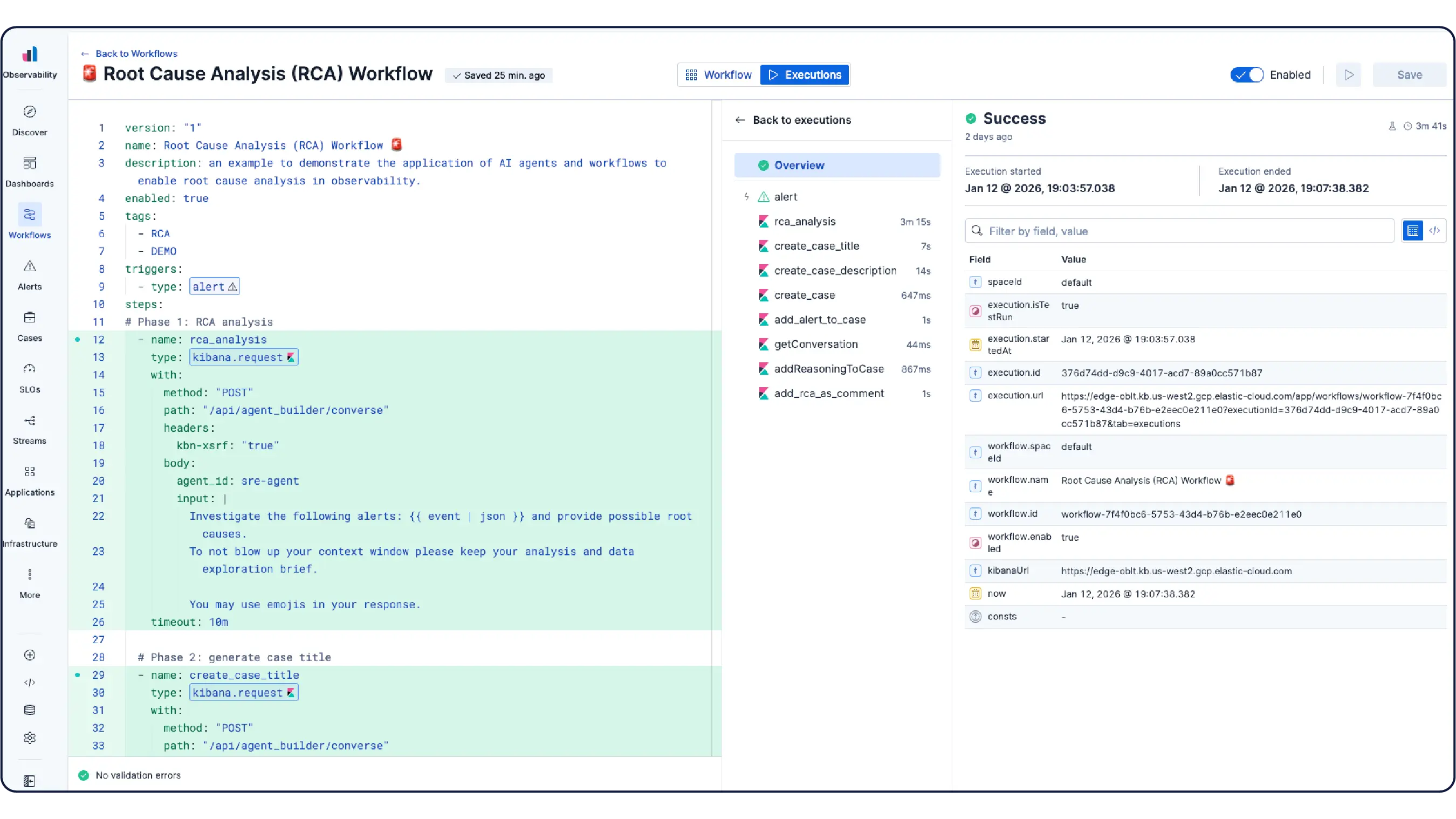
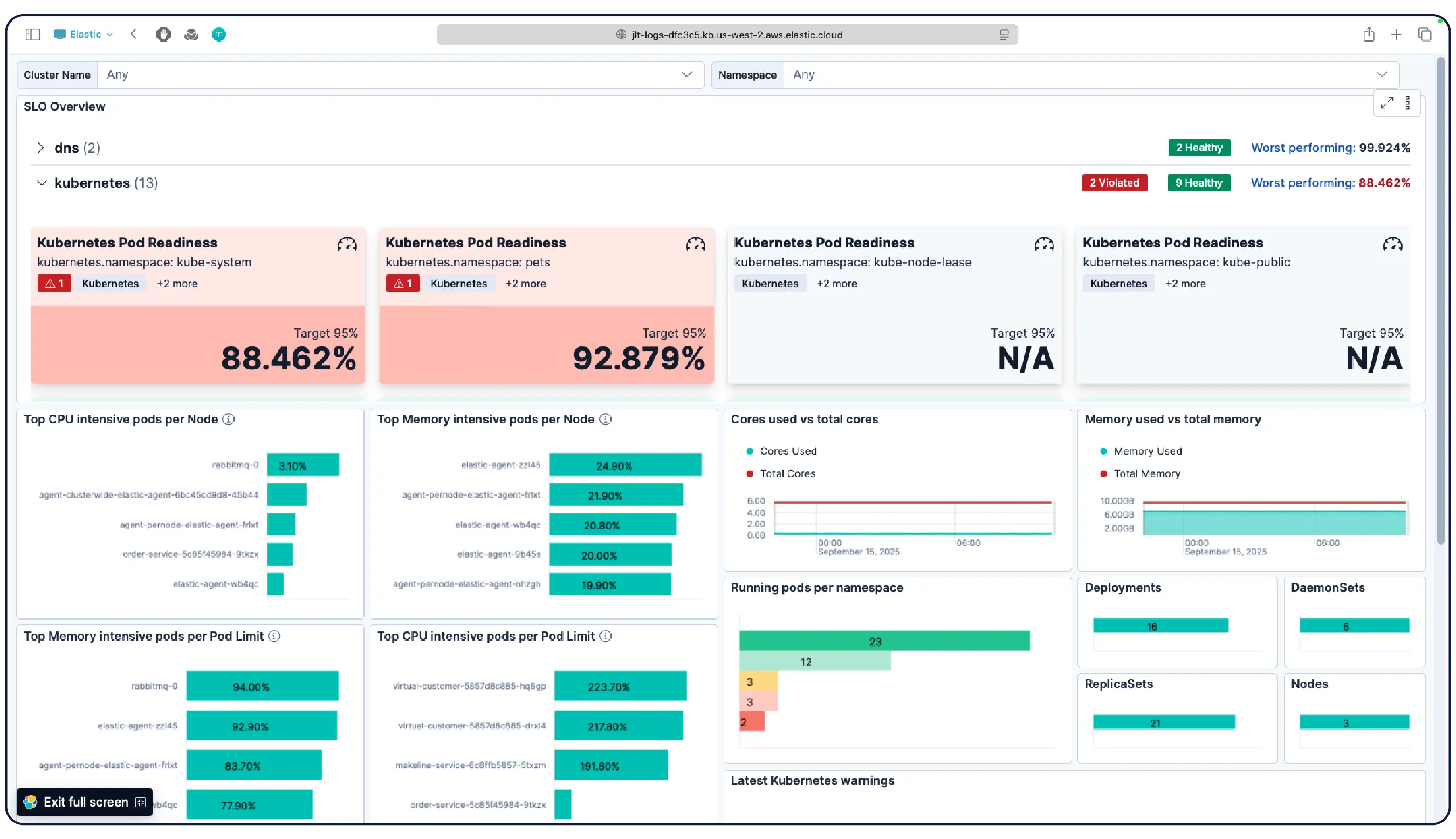
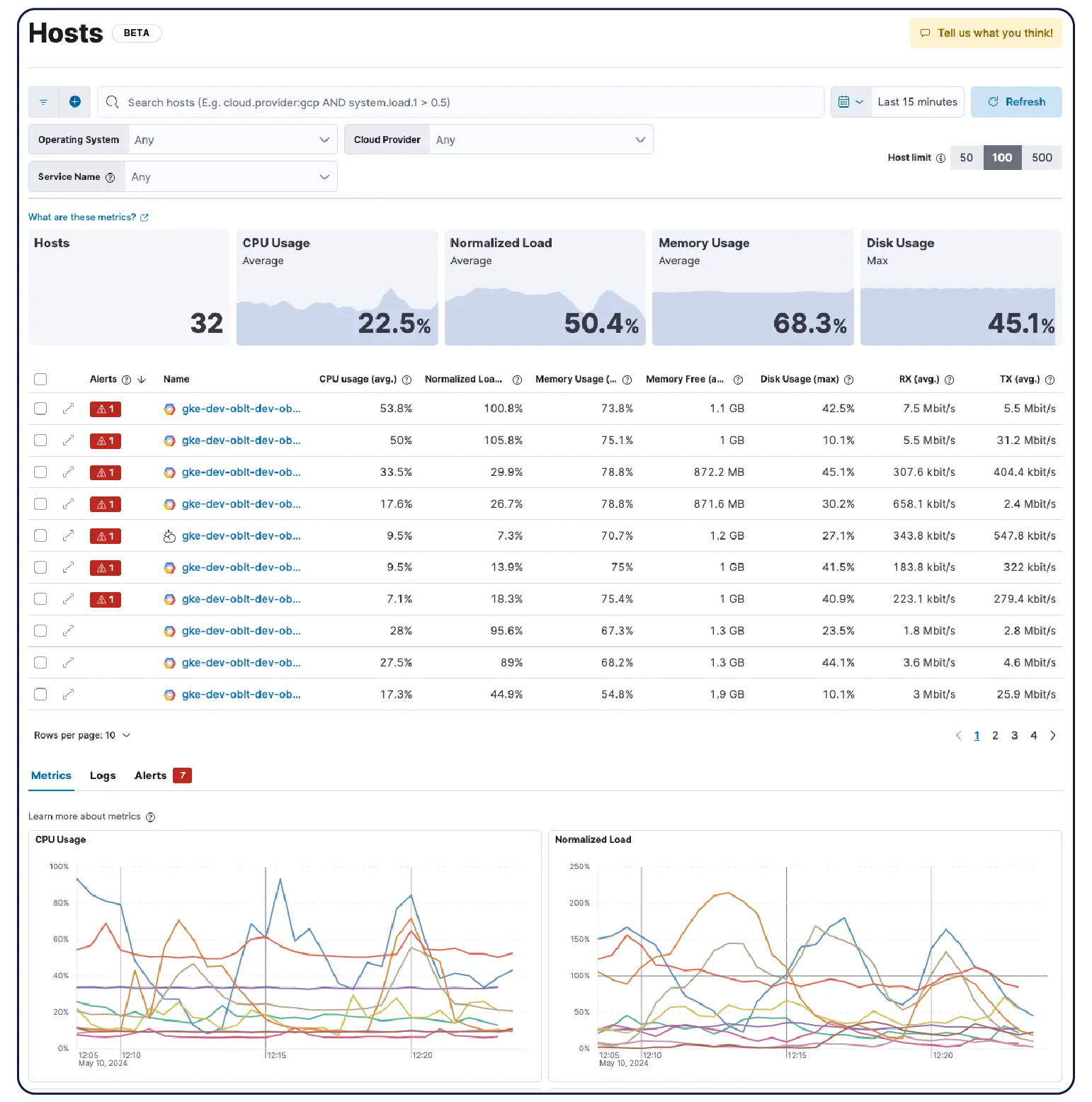
Erfahren Sie, warum sich Unternehmen wie Ihres für Elastic Observability entscheiden
Kunden-Spotlight

Comcast erfasst mit Elastic täglich 400 Terabyte an Daten, um Dienste zu überwachen und die Ursachenanalyse zu beschleunigen und so ein erstklassiges Kundenerlebnis zu gewährleisten.
Kunden-Spotlight

Zooplus nutzt Elastic zur Überwachung von 2.500 Microservices, 20.000 Containern, 600 AWS-Konten mit 70 AWS-Diensten sowie 40 Kubernetes-Clustern.
Kunden-Spotlight

Informatica senkte die Kosten und reduzierte die MTTR, indem es seinen gesamten Logging-Aufwand für mehr als 100 Anwendungen und mehr als 300 Kubernetes-Cluster auf Elastic migrierte.
Am Chat teilnehmen
Verbinden Sie sich mit der globalen Community von Elastic und nehmen Sie an offenen Gesprächen und an der Zusammenarbeit teil.

Stellen Sie Fragen, erhalten Sie Antworten und verschaffen Sie sich Gehör in unserem offenen Forum.

Tauchen Sie in Elastic ein. Lernen Sie, erkunden Sie und treten Sie mit Gleichgesinnten in Kontakt.

.jpg)
Häufig gestellte Fragen
Was ist Infrastrukturüberwachung?
Was ist Infrastrukturüberwachung?
Die Infrastrukturüberwachung verfolgt den Zustand und die Leistung der Systeme, auf denen Ihre Anwendungen ausgeführt werden – Webserver, Container, Cloud-Instanzen, Netzwerkgeräte, Caches, Warteschlangen, Datenbanken, Speicher und mehr. Sie erfasst Metriken wie CPU-Auslastung, Speichernutzung, Festplatten-E/A und Pod-Neustarts, sodass Teams Ressourcenüberlastung erkennen, Fehler frühzeitig erkennen und verstehen können, wie sich der Zustand der Infrastruktur auf das Anwendungsverhalten auswirkt. Effektive Infrastrukturüberwachung korreliert diese Metriken mit Logs und Traces, sodass Entwickler ohne Toolwechsel von der Meldung „Dieser Host ist überlastet“ direkt zur eigentlichen Ursache gelangen.
Wie überwacht Elastic die Infrastruktur?
Wie überwacht Elastic die Infrastruktur?
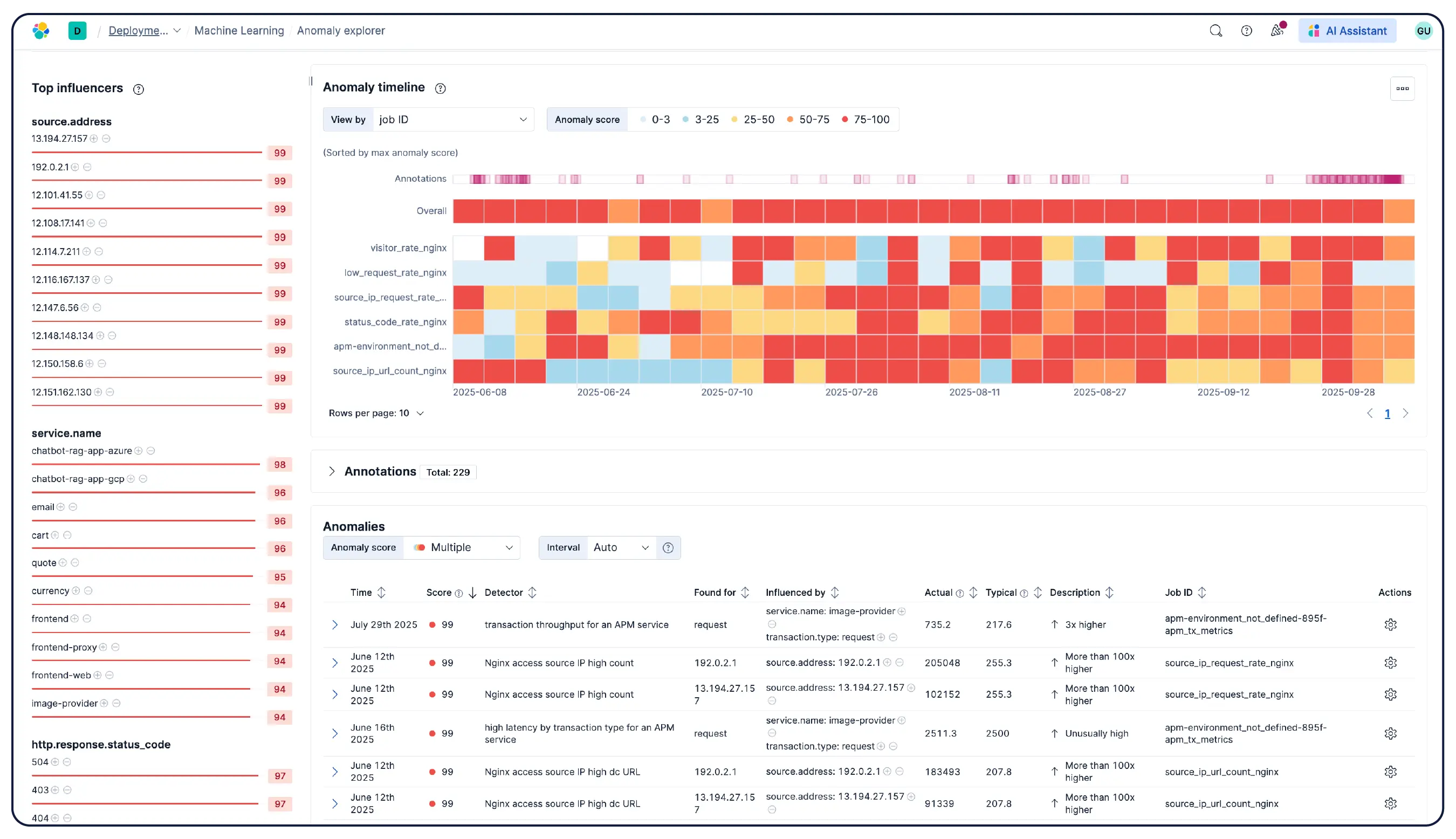
Elastic Observability erfasst Metriken, Logs und Traces von Hosts, Containern, Cloud-Diensten und Kubernetes-Clustern und korreliert diese in Elasticsearch, sodass Teams alle Signale an einem Ort untersuchen können. Elastic bietet Transparenz über Cloud-, On-Prem-, Kubernetes-, serverlose und Host-Umgebungen hinweg mit über 550 sofort einsatzbereiten Integrationen und nativer OpenTelemetry-Unterstützung. Elastic Agent übernimmt die Erfassung zentral über Fleet – eine Agentenkonfiguration pro Host ist nicht erforderlich. Die auf Machine Learning basierende Anomalieerkennung deckt ungewöhnliche Auslastungsmuster automatisch auf, und da Infrastrukturmetriken zusammen mit Anwendungs-Traces und -Logs vorliegen, können Entwickler von einer Warnmeldung aus direkt in den korrelierten Kontext wechseln, ohne die Platform verlassen zu müssen.
Unterstützt Elastic die Kubernetes-Überwachung?
Unterstützt Elastic die Kubernetes-Überwachung?
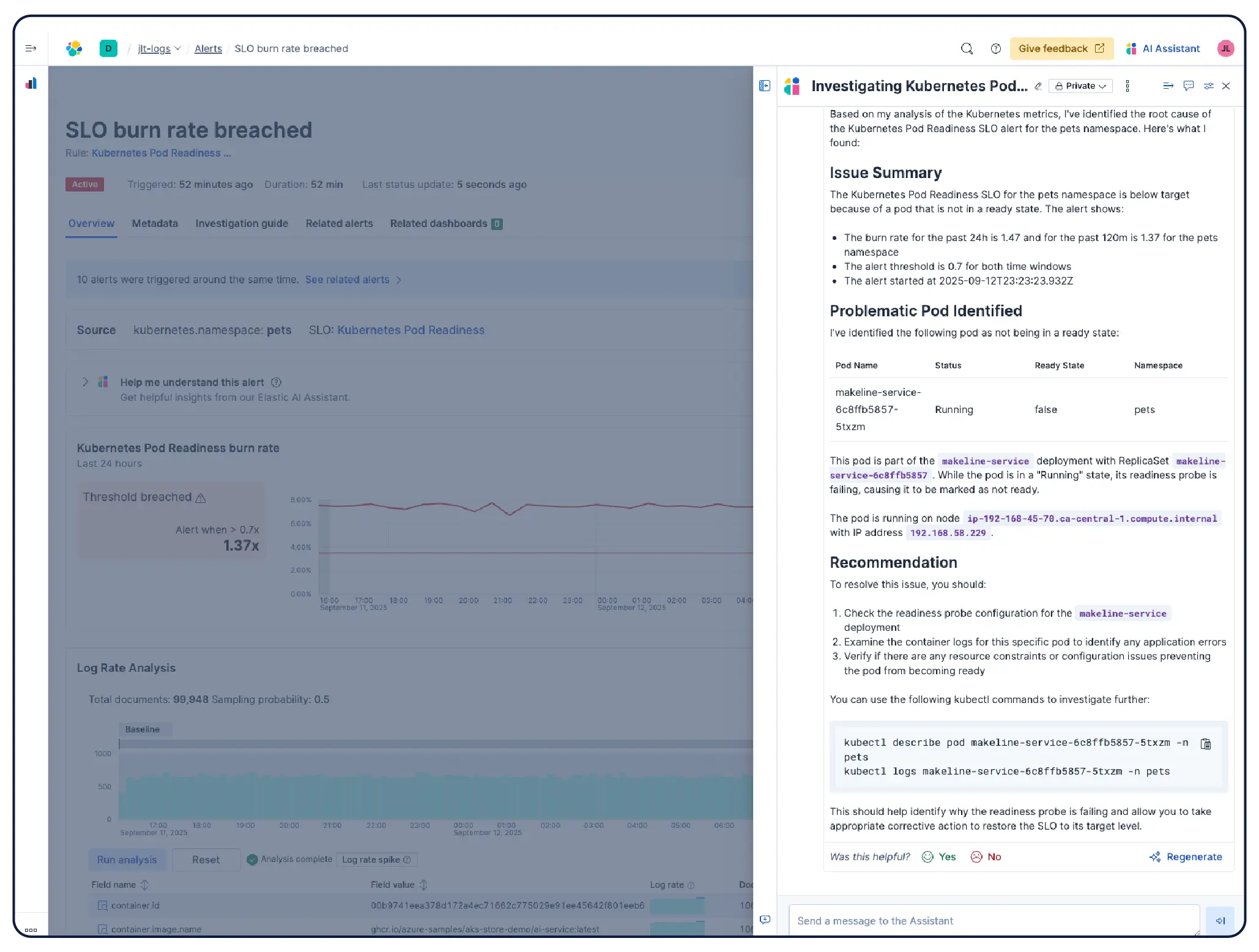
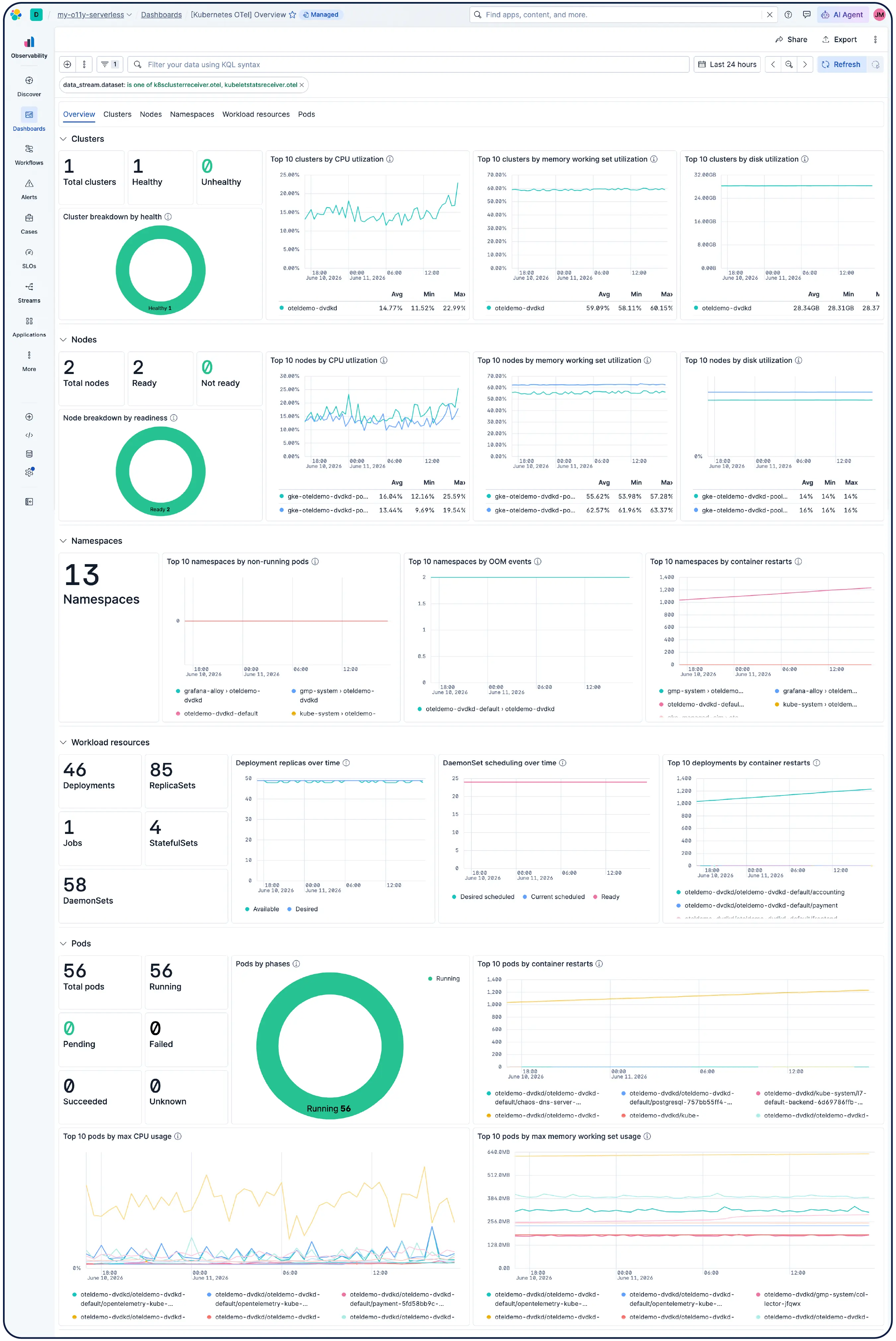
Ja. Elastic Observability ist für die Überwachung von Kubernetes-Umgebungen konzipiert, einschließlich verwalteter Cluster auf EKS, AKS und GKE sowie selbstverwalteter Cluster. Elastic entdeckt automatisch Änderungen in dynamischen Kubernetes-Workloads und überwacht Dienste und Komponenten überall, wo sie ausgeführt werden, mit Metadatenanreicherung beim Ingest, sodass Sie gemeinsame Attribute im System filtern, verfolgen und identifizieren können. Während die Pods hoch- und herunterfahren, hält Elastic ohne manuelle Neukonfiguration mit. Cluster-Ressourcenauslastung, Pod-Level-log, Anwendungs-Traces und Infrastrukturmetriken werden alle aus einem einzigen Deployment gesammelt und in Kibana korreliert, wobei Anomalieerkennung und log-Kategorisierung Probleme aufdecken, auf die Sie nicht geachtet haben.
Welche Datenformate werden von Elastic unterstützt?
Welche Datenformate werden von Elastic unterstützt?
Elastic Observability basiert auf offenen Standards. Es verarbeitet nativ das OpenTelemetry-Protokoll (OTLP) – Protokolle, Metriken und Traces – ohne Schema-Konvertierung oder proprietäre Übersetzung. EDOT, die Elastic Distribution von OpenTelemetry, bietet Ihnen ein produktionsbereites, OTel-natives Ökosystem: Installieren Sie den EDOT Collector, aktivieren Sie die automatische Instrumentierung mit Programmiersprachen-SDKs, und Ihre Daten fließen mit dem OTel-Schema unverändert in Elasticsearch. Prometheus-Metriken und PromQL werden nativ unterstützt, und über 450 Ein-Klick-Integrationen decken Cloudanbieter, Datenbanken, Message Queues, Netzwerkgeräte und Anwendungsframeworks ab. Elastic Agent und Beats verarbeiten strukturierte und unstrukturierte Log-Formate aus praktisch jeder gängigen Quelle.
Wie reduziert Elastic die Kosten für die Infrastrukturüberwachung?
Wie reduziert Elastic die Kosten für die Infrastrukturüberwachung?
Elastic geht die Kosten für die Observability sowohl auf der Speicherebene als auch auf der Architekturebene an. Der LogsDB-Indexmodus kann den Speicherbedarf für Log um bis zu 65 % reduzieren, indem er die Datenreihenfolge optimiert, Duplikate durch synthetische _source-Einträge beseitigt und die Komprimierung verbessert. Bei Metriken nutzen Zeitreihendaten-Streams (TSDS) spaltenorientierten Speicher und zeitreihenspezifische Codecs – Delta-of-Deltas, Run-Length-Codierung, XOR-Codierung –, wodurch der für Metriken benötigte Festplattenspeicher bei Integrationen wie Kubernetes, AWS und Nginx um bis zu 70 % reduziert wird. Für Teams, die Elastic Cloud Serverless nutzen, dient der cloudnative Objektspeicher als primäres Aufzeichnungssystem, sodass alle Daten zu den Kosten des Objektspeichers gespeichert werden, ohne dass Tiering oder Kapazitätsplanung erforderlich sind.
Wie verhält sich die Preisgestaltung der Metriken von Elastic im Vergleich zu Wettbewerbern?
Wie verhält sich die Preisgestaltung der Metriken von Elastic im Vergleich zu Wettbewerbern?
Elastic Observability nutzt eine verbrauchsabhängige Preisgestaltung ohne Gebühren pro Host und ohne Abrechnung nach Höchstwerten. Bei der Preisgestaltung von Datadog pro Host werden Autoscaling-Ereignisse anhand der höchsten Knotenanzahl des gesamten Monats abgerechnet, nicht anhand der durchschnittlichen Nutzung. Benutzerdefinierte Metriken verursachen zusätzliche Kosten und können bis zu 52 % der durchschnittlichen Rechnung ausmachen. Das Modell von Elastic sorgt dafür, dass kurzlebige Workloads und Prometheus-Umgebungen mit hoher Kardinalität keine Überraschungen am Monatsende mit sich bringen.