Was sind Wort-Einbettungen?
Definition: Wort-Einbettung
Wort-Einbettung ist eine in der natürlichen Sprachverarbeitung (Natural Language Processing, NLP) verwendete Technik, bei der Wörter als Zahlen dargestellt werden, um sie computergestützt verarbeiten zu können. Dieser Ansatz ist sehr beliebt für erlernte numerische Darstellungen von Texten.
Da Maschinen Unterstützung brauchen, um Wörter zu verarbeiten, muss jedem Wort für die Verarbeitung ein Zahlenformat zugeordnet werden. Dies kann auf verschiedene Arten erreicht werden:
- Bei der One-Hot-Kodierung wird jedem Wort in einem Text eine eindeutige Zahl zugewiesen. Diese Zahl wird in einen Binärvektor (mit Einsen und Nullen) umgewandelt, der das Wort darstellt.
- Bei der anzahlbasierten Darstellung wird gezählt, wie oft ein bestimmtes Wort in einem Text vorkommt, um dem Wort einen entsprechenden Vektor zuzuordnen.
- Die SLIM-Kombination verwendet beide Methoden, damit der Computer sowohl die Bedeutung der Wörter als auch deren Auftretenshäufigkeit im Text kennt.
Bei der Wort-Einbettung wird ein hochdimensionaler Raum erstellt, in dem jedem Wort ein Dichtevektor (mehr dazu weiter unten) aus Zahlen zugewiesen wird. Mit diesen Vektoren kann der Computer anschließend die Beziehungen zwischen Wörtern verstehen und Vorhersagen treffen.
Wie funktioniert die Wort-Einbettung bei der natürlichen Sprachverarbeitung?
Für die Wort-Einbettung bei der natürlichen Sprachverarbeitung werden Wörter als Dichtevektoren aus reellen Zahlen in einem hochdimensionalen Raum mit bis zu 1.000 Dimensionen dargestellt. Bei der Vektorisierung werden Wörter in numerische Vektoren umgewandelt. Ein Dichtevektor ist ein Vektor, in dem die meisten Einträge nicht gleich null sind. Das Gegenteil davon ist ein dünnbesetzter Vektor, wie etwa bei der One-Hot-Kodierung, der viele Nulleinträge enthält. Diesen hochdimensionalen Raum nennt man auch „Einbettungsraum“.
Wörter, die ähnliche Bedeutungen haben oder in einem ähnlichen Kontext verwendet werden, erhalten ähnliche Vektoren und sind einander daher im Einbettungsraum nahe. „Tee“ und „Kaffee“ sind Beispiele für Wörter, die einander nahe sind, wohingegen „Tee“ und „See“ einen größeren Abstand zueinander haben, weil sie unterschiedliche Bedeutungen haben und nicht oft gemeinsam verwendet werden, obwohl sich die beiden Wörter ähneln.
Die verschiedenen Methoden zur Erstellung von Wort-Einbettungen in der natürlichen Sprachverarbeitung werden allesamt mit einer großen Menge von Textdaten trainiert, die man auch als Korpus bezeichnet. Wikipedia und Google News sind zwei gängige Beispiele, die oft als Basis für vorgefertigte Einbettungskorpora verwendet werden.
Als Korpus kann auch eine benutzerdefinierte und speziell für den Anwendungsfall erstellte Einbettungsebene verwendet werden, wenn andere vorab trainierte Korpora nicht genügend Daten liefern. Beim Training lernt das Modell, jedem Wort einen eindeutigen Vektor anhand der Wortnutzungsmuster in den jeweiligen Daten zuzuweisen. Diese Modelle können verwendet werden, um Wörter in beliebigen neuen Textdaten in Dichtevektoren umzuwandeln.
Wie werden Wort-Einbettungen erstellt?
Wort-Einbettungen können auf verschiedene Arten erstellt werden. Die Auswahl der Technik hängt von den jeweiligen Anforderungen ab. Dabei gilt es, die Größe des Datensatzes, die Datendomäne und die Komplexität der Sprache zu berücksichtigen. Hier finden Sie Informationen zur Funktionsweise der beliebtesten Wort-Einbettungstechniken:
- Word2vec ist ein Algorithmus mit zwei Ebenen, der auf einem neuronalen Netz basiert, einen Textkorpus als Eingabe erhält und einen Satz von Vektoren ausgibt (daher der Name). Ein häufig verwendetes Beispiel für Word2vec ist „König - Mann + Frau = Königin“. Durch die Ableitung der Beziehung zwischen „König“ und „Mann“ und zwischen „Mann“ und „Frau“ kann der Algorithmus das Wort „Königin“ als passende Entsprechung für „König“ identifizieren. Word2vec wird entweder mit Skip-Gram- oder mit CBOW-Algorithmen (Continuous Bag of Words) trainiert. Skip-Gram versucht, Kontextwörter aus einem Zielwort abzuleiten. Continuous Bag of Words funktioniert umgekehrt und sagt ein Zielwort anhand des Kontexts der umgebenden Wörter vorher.
- GloVe (Globale Vektoren) basiert auf der Idee, dass die Bedeutung eines Wortes vom gemeinsamen Auftreten des Wortes mit anderen Wörtern in einem Textkorpus abgeleitet werden kann. Der Algorithmus erstellt eine Grauwertematrix, die erfasst, wie häufig bestimmte Wörter im Korpus zusammen vorkommen.
- fasText ist eine Erweiterung des Word2vec-Modells und basiert auf der Idee, Wörter als Sätze von Zeichen-n-Grammen oder als Unterworteinheiten anstelle von ganzen Wörtern abzubilden. fasText verwendet ein ähnliches Modell wie Skip-Gram und erfasst Informationen über die interne Struktur von Wörtern, um neues und bisher unbekanntes Vokabular besser zu verarbeiten.
- ELMo (Embeddings from Language Models, Einbettungen aus Sprachmodellen) unterscheidet sich von den oben genannten Wort-Einbettungen und verwendet ein Deep Neural Network, um den gesamten Kontext zu analysieren, in dem ein Wort vorkommt. Auf diese Weise können subtile Nuancen in der Bedeutung erfasst werden, die den anderen Einbettungstechniken unter Umständen entgehen.
- TF-IDF (Term Frequency – Inverse Document Frequency, Begriffshäufigkeit – umgekehrte Dokumenthäufigkeit) ist ein mathematischer Wert, der durch die Multiplikation der Begriffshäufigkeit (TF) mit der umgekehrten Dokumenthäufigkeit (IDF) entsteht. TF bezieht sich auf das Verhältnis der Zielbegriffe im Dokument zur Gesamtzahl der Begriffe im Dokument. IDF ist ein Logarithmus des Verhältnisses der Gesamtzahl der Dokumente zur Anzahl der Dokumente, die den Zielbegriff enthalten.
Welche Vorteile bieten Wort-Einbettungen?
Wort-Einbettungen bieten zahlreiche Vorteile im Vergleich zu herkömmlichen Ansätzen zur Darstellung von Wörtern bei der natürlichen Sprachverarbeitung. Wort-Einbettungen sind inzwischen ein Standardansatz bei der NLP und es gibt zahlreiche vorab trainierte Einbettungen für verschiedene Anwendungen. Dank dieser umfassenden Verfügbarkeit können Forscher und Entwickler die Einbettungen mühelos in ihre Modelle einbinden, ohne sie von Grund auf trainieren zu müssen.
Wort-Einbettungen werden eingesetzt, um die Sprachmodellierung zu verbessern, bei der es darum geht, das nächste Wort in einem Text zu ermitteln. Durch die Darstellung von Wörtern als Vektoren können die Modelle den Kontext, in dem ein Wort auftritt, besser erfassen und genauere Vorhersagen treffen.
Die Erstellung von Wort-Einbettungen ist oft schneller als herkömmliche Engineering-Techniken, da neuronale Netze mit großen Textkorpora unbeaufsichtigt trainiert werden können, um Zeit und Aufwand zu sparen. Nachdem eine Einbettung trainiert wurde, kann sie ohne zusätzliches Feature Engineering als Eingabe-Feature für vielfältige NLP-Aufgaben eingesetzt werden.
Wort-Einbettungen haben normalerweise eine viel niedrigere Dimensionalität als One-Hot-kodierte Vektoren. Daher können sie mit weniger Arbeitsspeicher und Rechenleistung gespeichert und verarbeitet werden. Wort-Einbettungen stellen Wörter als Dichtevektoren dar und sind damit eine effizientere Darstellungsmethode als Techniken mit dünnbesetzten Vektoren. Außerdem können sie die semantischen Beziehungen zwischen Wörtern besser erfassen.
Welche Nachteile haben Wort-Einbettungen?
Wort-Einbettungen haben zwar viele Vorteile, allerdings gilt es auch einige Nachteile zu berücksichtigen.
Das Trainieren von Wort-Einbettungen erfordert umfangreiche Computing-Ressourcen, insbesondere bei Verwendung von großen Datensätzen oder komplexen Modellen. Vorab trainierte Einbettungen belegen oft große Mengen an Speicherplatz, was für Anwendungen mit begrenzten Ressourcen problematisch sein kann. Wort-Einbettungen werden mit einem endlichen Vokabular trainiert und können daher keine Wörter abbilden, die nicht im Vokabular enthalten sind. Dies kann bei Sprachen mit großem Vokabular oder bei anwendungsspezifischer Terminologie Probleme bereiten.
Wenn die Dateneingaben einer Wort-Einbettung Verzerrungen enthalten, kann die Wort-Einbettung diese Verzerrungen widerspiegeln. Wort-Einbettungen können beispielsweise Verzerrungen im Hinblick auf Geschlecht, Volkszugehörigkeit oder andere Stereotypen enthalten, die wiederum praktische Auswirkungen haben können, wenn die Modelle eingesetzt werden.
Wort-Einbettungen gelten oft als Blackbox, da die zugrunde liegenden Modelle wie etwa die neuronalen Netze von GloVe oder Word2Vec komplex und schwer zu interpretieren sind.
Wort-Einbettungen sind nur so gut wie die Daten, mit denen sie trainiert wurden. Verwenden Sie daher nach Möglichkeit genügend Daten, um eine praxistaugliche Wort-Einbettung zu erhalten. Wort-Einbettungen können zwar die allgemeine Beziehung zwischen Wörtern erfassen, übersehen aber manchmal bestimmte menschliche Nuancen, die schwieriger zu erkennen sind, wie etwa Sarkasmus.
Wort-Einbettungen weisen jedem Wort einen Vektor zu. Daher sind Homographen (Wörter mit gleicher Schreibweise und unterschiedlicher Bedeutung) schwer zu verarbeiten. („August“ kann beispielsweise ein Vorname oder ein Monat sein.)
Wofür werden Wort-Einbettungen verwendet?
Wort-Einbettungen werden verwendet, um die Vektorsuche zu unterstützen. Sie sind entscheidend für Aufgaben im Bereich der natürlichen Sprachverarbeitung, wie etwa Standpunktanalyse, Textklassifizierung oder Sprachübersetzung. Wort-Einbettungen liefern einen effektiven Weg, mit dem Computer die semantischen Beziehungen zwischen Wörtern erkennen und erfassen können. Damit lassen sich exaktere und effizientere NLP-Modelle erstellen als mit manuellem Feature Engineering. Auf diese Weise ergibt sich ein zugängliches und effektives Endergebnis für die Nutzer.
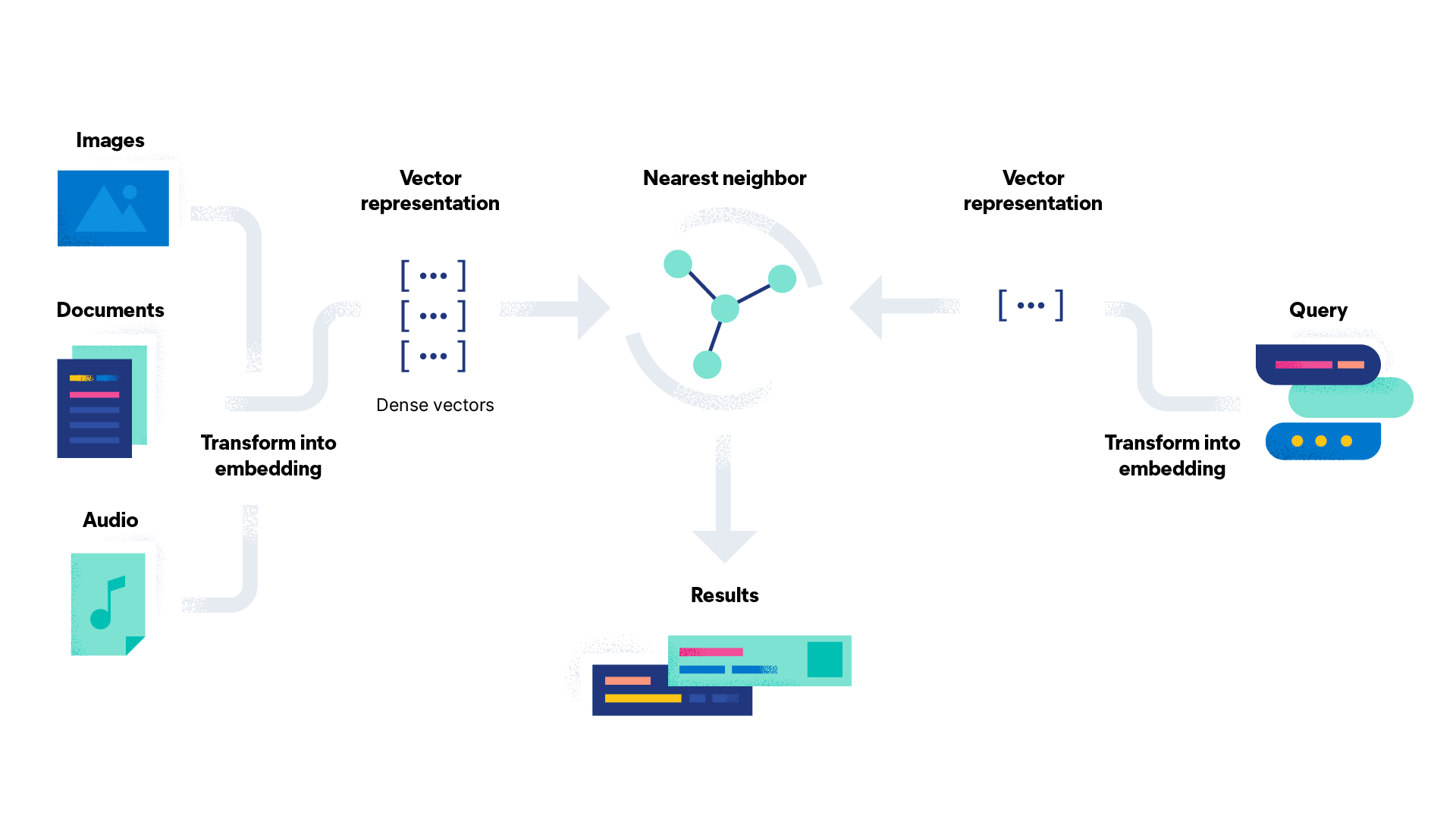
Wort-Einbettungen können für vielfältige Zwecke eingesetzt werden. Hier sind einige Anwendungsfälle für Wort-Einbettungen:
- Standpunktanalyse: Bei der Standpunktanalyse werden Wort-Einbettungen eingesetzt, um Texte als positiv, negativ oder neutral zu kategorisieren. Die Standpunktanalyse wird oft von Unternehmen eingesetzt, um das Feedback zu deren Produkten in Bewertungen und Social-Media-Beiträgen zu analysieren.
- Empfehlungssysteme: Empfehlungssysteme schlagen den Nutzern Produkte oder Dienste auf Basis ihrer vorherigen Interaktionen vor. Ein Streaming-Dienst kann beispielsweise Wort-Einbettungen verwenden, um den Nutzern neue Titel anhand ihres bisherigen Sehverhaltens vorzuschlagen.
- Chatbots: Chatbots nutzen natürliche Sprachverarbeitung, um mit Kunden zu kommunizieren und passende Antworten auf deren Fragen zu generieren.
- Suchmaschinen: Suchmaschinen nutzen die Vektorsuche, um die Genauigkeit der gelieferten Ergebnisse zu verbessern. Dabei werden Wort-Einbettungen verwendet, um Nutzeranfragen mit dem Inhalt von Webseiten zu vergleichen und bessere Übereinstimmungen zu liefern.
- Originalinhalte: Originalinhalte werden durch die Transformation von Daten in lesbare natürliche Sprache erstellt. Wort-Einbettungen können auf viele verschiedene Inhaltstypen angewendet werden, von Produktbeschreibungen bis hin zu Aufbereitungsanalysen nach Sportbegegnungen.
Erste Schritte mit Wort-Einbettungen und Vektorsuche mit Elasticsearch
Elasticsearch ist eine verteilte, freie und offene Suchmaschine und Analytics Engine für Daten aller Art, inklusive Analysen strukturierter und unstrukturierter Texte. Elasticsearch speichert Ihre Daten und ermöglicht schnelle Suchvorgänge, feinjustierte Relevanz sowie leistungsstarke und skalierbare Analysen. Elasticsearch ist das Herzstück des Elastic Stack, einer Reihe von freien und offenen Tools für die Ingestion, Anreicherung, Speicherung, Analyse und Visualisierung von Daten.
Mit Elasticsearch können Sie:
- Benutzererlebnisse und Conversions optimieren
- Neue Einblicke, Automatisierungsformen, Analysen und Berichte generieren
- Die Produktivität Ihrer Mitarbeiter mit internen Dokumenten und Anwendungen steigern