How to add support for more languages in your Elastic Enterprise Search engines


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Engines in Elastic App Search enable you to index documents and provide out-of-the-box, tunable search capabilities. By default, engines support a predefined list of languages. If your language is not on that list, this blog explains how you can add support for additional languages. We’ll do this by creating an App Search engine that has analyzers set up for that language.
Before we dive into the details, let’s define what an Elasticsearch analyzer is:
An Elasticsearch analyzer is a package that contains three lower-level building blocks: character filters, tokenizers, and token filters. Analyzers can be built-in or custom. Built-in analyzers pre-package building blocks into analyzers suitable for different languages and types of text.
Analyzers for each field are used to:
- Index. Each document field will be processed with its corresponding analyzer and broken down into tokens to ease searching.
- Search. The search query will be analyzed to ensure a proper match with the indexed fields that have already been analyzed.
Elasticsearch index-based engines enable you to create App Search engines from existing Elasticsearch indices. We'll create an Elasticsearch index with our own analyzers and mappings and use that index in App Search.
There are four steps in this process:
1. Create an Elasticsearch index and index documents
To get started, let’s take an index that has not been optimized for any language. Let’s assume this is a new index that has no predefined mappings and it is created when documents are indexed for the first time.
In Elasticsearch, mapping is the process that defines how a document and the fields it contains are stored and indexed. Each document is a collection of fields, which each have their own data type. When mapping your data you create a mapping definition, which contains a list of fields pertinent to the document.
Back to our example. The index is called books, where the title is in the Romanian language. We picked Romanian because it is my language and it is not included in the list of languages that App Search supports by default.
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2. Add language analyzers to the books index
When we inspect the books index mapping, we see it is not optimized for Romanian. You can tell as there is no analysis field in the settings block and the text fields do not use a custom analyzer.
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}If we try to create an App Search engine with the books index, we’ll have two issues. First, search results will not be optimized for Romanian, and next, features like Precision Tuning will be disabled.
A quick note on different types of Elastic App Search engines:
- The default option is an App Search managed engine, which will automatically create and manage a hidden Elasticsearch index. With this option, you have to use the App Search documents API to ingest data in your engine.
- With the other option, App Search creates an engine with an existing Elasticsearch index — in this case, App Search will use the index as it is. Here, you can ingest data directly in the underlying index by using the Elasticsearch index documents API.
[Related article: Elasticsearch Search API: A new way to locate App Search documents]
When you create an engine from an existing Elasticsearch index, if the mappings do not follow App Search conventions not all features will be enabled for that engine. Let’s have a closer look at App Search mapping conventions by looking at an engine that is fully managed by App Search. This engine has two fields, title and author, and uses the English language.
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}You’ll see the title field has several subfields. The date, float, and location subfields are not text fields.
Here, we are interested in how to set the text fields that App Search requires. There are more than a few fields! This documentation page explains the text fields used in App Search. Let’s look at the analyzers that App Search sets for a hidden index belonging to an App Search managed engine:
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}If we want to create an index that we can use in App Search, for a different language — for example Norwegian, Finnish, or Arabic — we would need similar analyzers. For our example, we need to ensure that the stem and stopword filters use the Romanian version.
Going back to our initial books index, let's add the right analyzers.
A quick word of caution here. For existing indices, analyzers are a type of Elasticsearch setting that can only be changed when an index is closed. In this approach, we start with an existing index and therefore need to close the index, add analyzers, and then reopen the index.
Note: As an alternative, you could also recreate the index from scratch with the right mappings and then index all the documents. If that is better for your use case, feel free to skip the parts of this guide that discuss opening and closing the index, and reindexing.
You can close the index by running POST books/_close. And after that, we will add the analyzers:
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}You can see that we're adding the ro-stem-filter for stemming in Romanian, which will improve search relevance for word variations that are specific to Romanian. We're including the Romanian stop words filter (ro-stop-words-filter) to make sure Romanian stop words are not considered for searching purposes.
And now we will reopen the index by executing POST books/_open.
3. Update index mapping to use analyzers
Once we have the analysis settings in place, we can modify the index mapping. App Search uses dynamic templates to ensure that new fields have the right subfields and analyzers. For our example, we will only add the subfields to the existing title and author fields:
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4. Reindex the documents
The books index is now almost ready to be used in App Search!
We just need to ensure that the documents we indexed before we modified the mapping have all the right subfields. To do this, we can run a reindex in place using update_by_query:
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}Since we are using a match_all query, all existing documents will be updated.
With an update by query request, we can also include a script parameter to define how to update the documents.
Note that we are not changing the documents, but we do want to reindex existing documents as they are to ensure that the text fields author and title have the right subfields. Hence, we do not need to include a script in our update by query request.
We now have a language-optimized index we can use in App Search with Elasticsearch engines! You’ll see the benefits in action in the following screenshots.
We’ll use the book title One Hundred Years of Solitude as reference. The translated title in Romanian is Un veac de singurătate. Pay attention to the word veac, which is the Romanian word for “century.” We’ll run a search with the plural form of veac, which is veacuri. We ingested this data record in both the examples we’re about to look at:
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
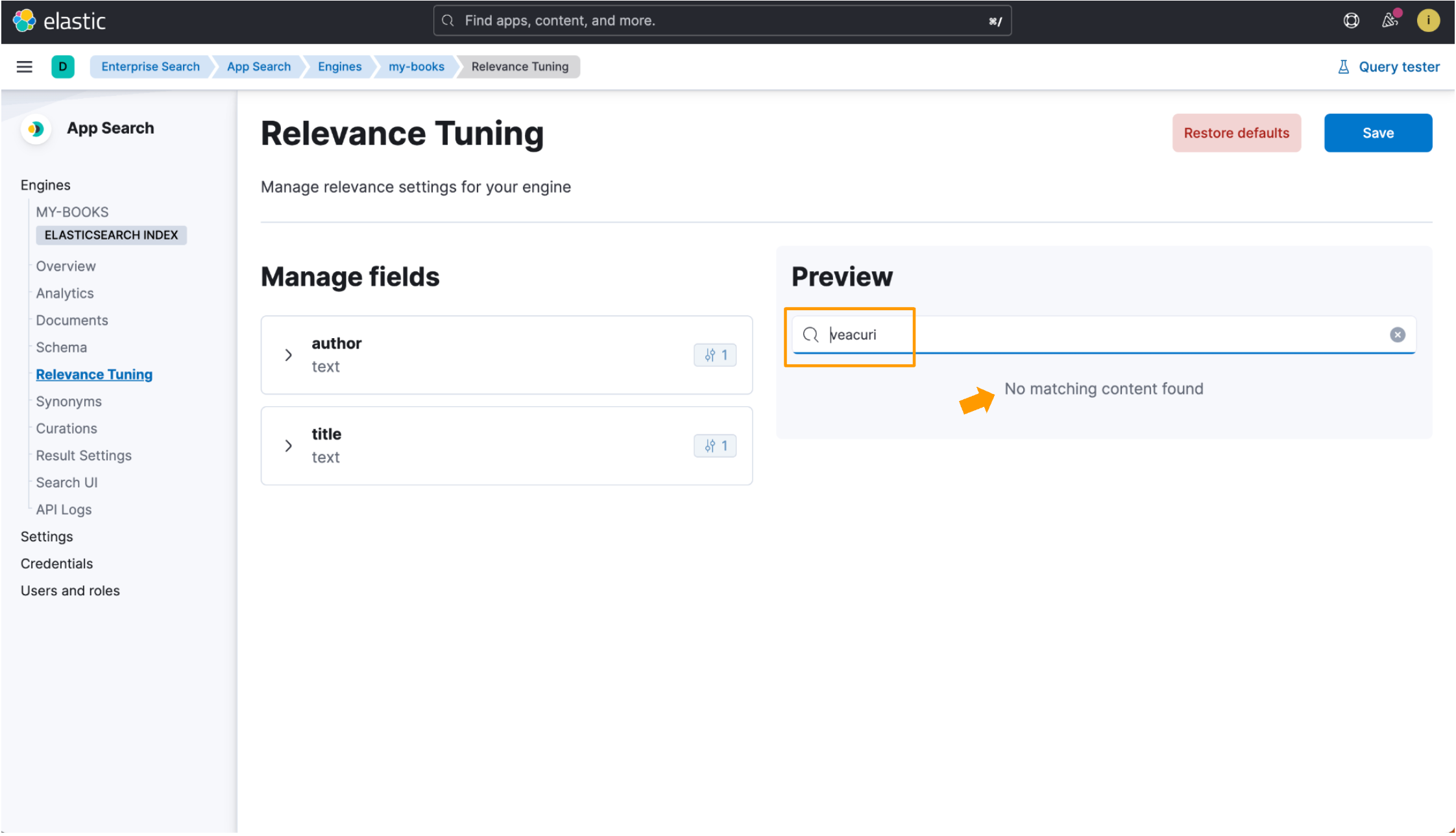
}When an index is not optimized for a language, the Romanian book title Un veac de singurătate is indexed with the standard analyzer, which works well for most languages but might not always match on relevant documents. Searching for veacuri does not show any results, as this search input does not match any plain text in the data record.
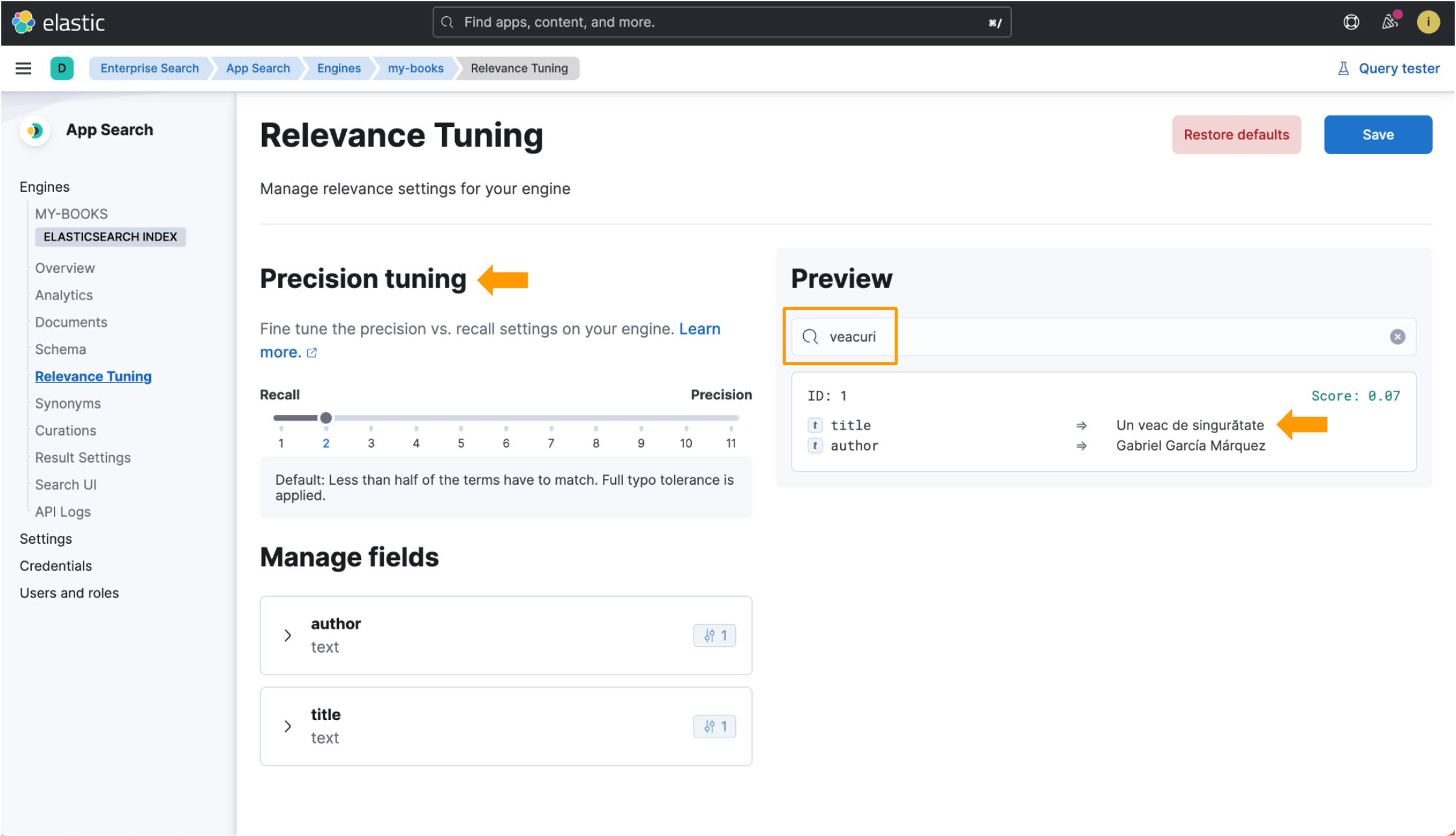
When using the language-optimized index, however, when we search for veacuri, Elastic App Search matches that to the Romanian language word veac and returns the data we’re looking for. Precision tuning fields are also available within the Relevance Tuning view! Look at all the highlighted bits in this image:
So, with that, we added support in Elastic Enterprise Search for Romanian, which is my language! The process used in this guide can be replicated to create indices optimized for any other language supported by Elasticsearch. For the full list of supported language analyzers in Elasticsearch, have a look at this documentation page.
Analyzers in Elasticsearch is a fascinating topic. If you’re interested in learning more, here are a few other resources:
- Elasticsearch Text analysis overview docs page
- Elasticsearch Built-in analyzer reference docs page (See this sub-page for list of supported language analyzers.)
- Learn more about Elastic Enterprise Search and Elastic Cloud trial
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print