Introducing Multi-Language Engines in Elastic App Search
You can optimize your Elastic App Search Engine for a specific language right out-of-the-box. We are launching with 13 languages, including: English, Spanish, German, Danish, Russian, Chinese, Korean, and Japanese.
But how does this change the underlying search methodology? How will this help improve a visitor's search experience? Do these benefits require more configuration? Onwards for answers, or reference the documentation to get started right away.
The Exercise? Analyze and Tokenize
Search is about analysis. The first analysis takes place when your index is built within your search engine. During the indexing process, the text within your documents is converted into tokens. The tokens are then organized against the index as a term.
Once the index has been structured, each search query takes place against the index. The incoming text is analyzed, converted to tokens, and then matched against indexed terms. The closer the incoming query terms can get to the indexed term, the more relevant the search will be.
If you were using Elasticsearch to craft search on your own, you might need to configure one - or several - custom analyzers to best handle the depths of your chosen language. How the tokens are created and how the terms are built relates directly to how you have configured your analyzer, or set of analyzers. While in typical cases an effective language analyzer can be included as part of basic index creation, deeper configurations require the tuning of character filters, a tokenizer, and token filters.
App Search abstracts this complexity away, providing you with an optimized, API-based solution to weave into your application. To demonstrate how this works, we can look at how App Search Engines can now interpret Chinese characters.
High Work Money
The basic setting within an App Search Engine is Universal. It is configured well and is ideal for most search cases. However, when a language is specified, the App Search Engine will use a custom analyzer that is optimized for that language.
For example, within Universal settings, search is clever enough to query for words as they fit together within a document, instead of running an independent search for each word. A search for hockey``stick would not search for hockey and then stick independent of each other. It would search for hockey stick.
While that is useful in English — or for Universal term matching — we can see how this would lead to confusing queries in other languages...
This pair of Chinese characters represents the idea of salary:
工资 : salary
It is made up of two different characters, work and money
工 : work
资 : money
With language agnostic analysis, the tokenizer will separate the two characters into two tokens and then look for matches against them on a literal — not syntax aware — basis.
If we consider that a Chinese searcher has performed a query for salary, we would expect them to receive results for work money instead of salary. You can see how confusing this might be!
In English, search will provide results that consider the relationship between work money- like with hockey stick. However, in Chinese, the two characters represent an entirely different concept.
By using the appropriate Chinese analyzer, the system is aware that 工资 is a bigram — a pair of terms — and so it will create a token for the pair together, building the right term for salary within the index. The bigram: 工资 will now be associated with salary instead of work money. Combined, the token means more than its disparate parts.
App Searchery
Configuring a specific language within App Search is now a simple part of Engine creation.
If you are creating an App Search Engine via the App Search API, then an example POST would look like this. The following will create a new Chinese - zh - Engine called panda:
curl -X POST 'https://host-xxxxxx.api.swiftype.com/api/as/v1/engines' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer private-xxxxxxxxxxxxxxxxxxxx' \
-d '{
"name": "panda",
"language": "zh"
}'
Languages coincide with a language code. The codes follow IETF RFC 5646 which coincides with ISO 639-1 and ISO 3166-1.
If you would like to use a GUI to create your Engine, the language selector will be present within Engine creation during on-boarding and within the dashboard:
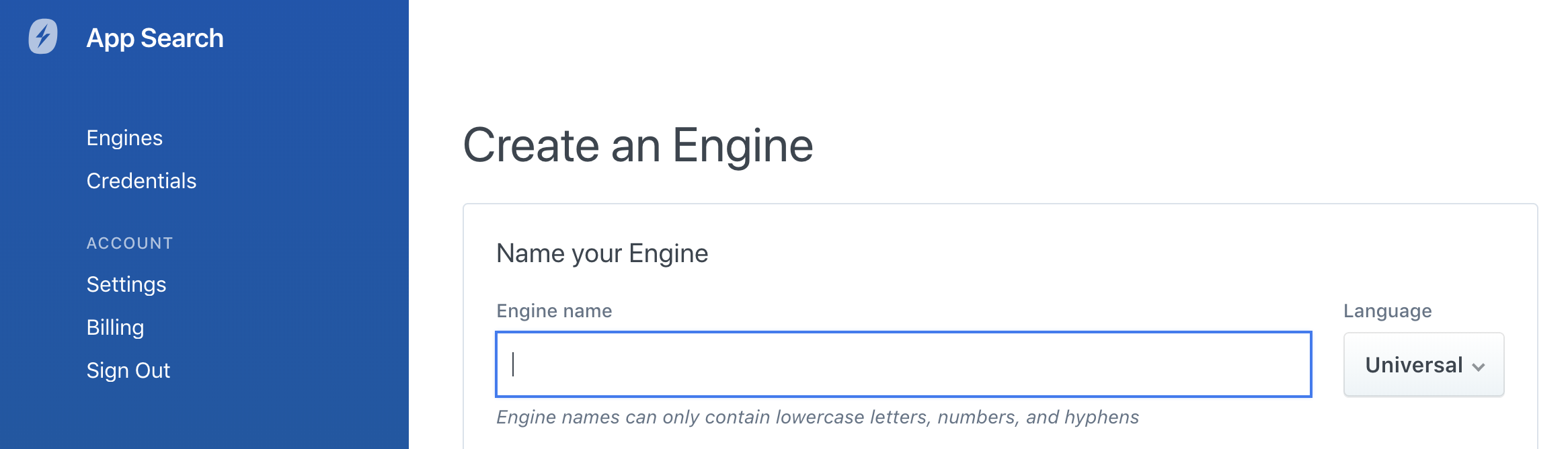
You can see which language an Engine is configured for by looking at the top-left under your Engine name. If you do not see a language, then the type is Universal:
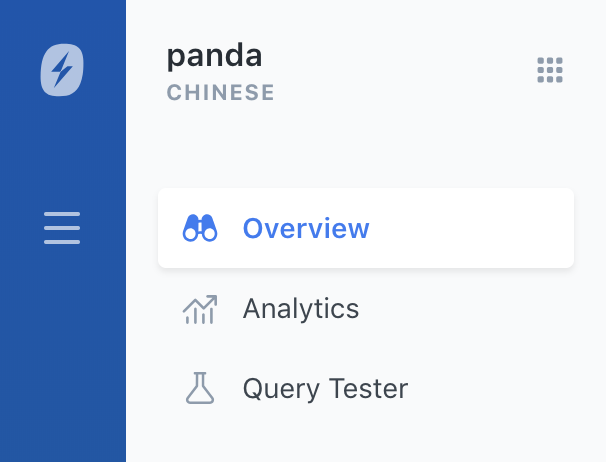
Now that you have an Engine specializing in a particular language, are there any special steps required? Nope! The advanced, language specific analysis takes place each time data is indexed into the Engine. After that, search queries in those languages will apply the same relevant, language-optimized analyzer that is used during indexing.
Summary
If you could focus on just one value, data type, and language, then search would still be a daunting technical challenge. In reality, search is immensely more complex: we have many values, many data types, and a vast breadth of languages to support. The eventual dream is wildly accurate, language and data type agnostic search with context predicted by machine learning.
Until then, Elastic App Search is an effective way to add vast search expertise into your applications. With 14 well-optimized languages at your fingertips, you can get back to building quality search experiences through an intuitive dashboard and simple, dynamic, well-maintained APIs. You can sign-up for a 14-day trial to experiment with the APIs and to see if Elastic App Search is right for you.
Update: Multi-language support is now available within Elastic Site Search. Enter your domain, select your language, then allow the Site Search Crawler to index your pages for you. After that, install the snippet and enjoy a quality search experience.*