Ingest data directly from Google Cloud Storage into Elastic using Google Dataflow


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Today we’re excited to announce support for direct Google Cloud Storage (GCS) data ingestion to the Elastic Stack with Google Dataflow. Now developers, site reliability engineers (SREs), and security analysts can ingest data from GCS to the Elastic Stack with just a few clicks in the Google Cloud Console.
Many developers, SREs, and security analysts use GCS to store logs and events generated from applications and infrastructure in Google Cloud while also using the Elastic Stack to troubleshoot, monitor, or look for security anomalies from these applications and infrastructure. To enhance the experience for both solutions, Google and Elastic have worked together to provide an easy-to-use, low-friction way to ingest logs and events stored in GCS to the Elastic Stack. This allows you to simplify your data pipeline architecture, eliminate operational overhead, and reduce the time required for troubleshooting — all with just a few clicks in the Google Cloud Console, and without creating a custom data processor.
In this blog post, we’ll cover how to get started with agentless data ingestion from GCS to the Elastic Stack using Google Dataflow.
Streamline data ingest from GCS
Google Cloud Storage is an object storage solution that is often compared to Amazon S3 or Azure Blob Storage. GCS is often used for data backup and archive, data analytics with no streaming requirements, or even hosting simple web pages and applications at attractive price points. A developer, SRE, or security analyst may decide to store application or infrastructure logs and events in GCS for backup or archive purposes. A Google Cloud user may also have a data pipeline where not all of the data is ingested into the Elastic Stack, with some stored in GCS for later analysis if necessary.
Once the logs and events are in GCS, you have to decide on the ingestion method for third-party analytics solutions like Elastic. It would be ideal to be able to ingest data directly from GCS to the Elastic Stack with just a few clicks in the Google Cloud Console. This is now possible with a dropdown menu in Google Dataflow, a popular serverless data process product based on Apache Beam. Dataflow effectively pushes logs and events from GCS to the Elastic Stack. Currently, CSV file format is supported and we’ll be adding support for JSON soon.
Here is the summary of the data ingestion flow. The integration works for all users, whether you’re using the Elastic Stack on Elastic Cloud, Elastic Cloud in the Google Cloud Marketplace, or a self-managed environment.
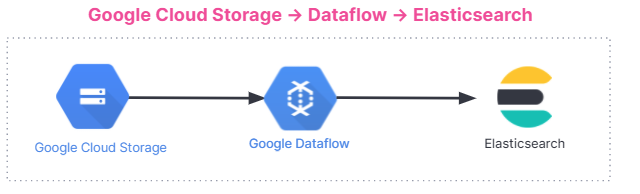
Get started
The best way to demonstrate the GCS ingest functionality is to step through an example. The following example will analyze earthquake data from USGS which catalogs a public dataset that provides information about real-time earthquakes and seismic stats. We’ll use the USGS magnitude 2.5+ earthquakes from the past month as a CSV. Here we’re showing only the first five lines of the file to give you an idea of what the data looks like:

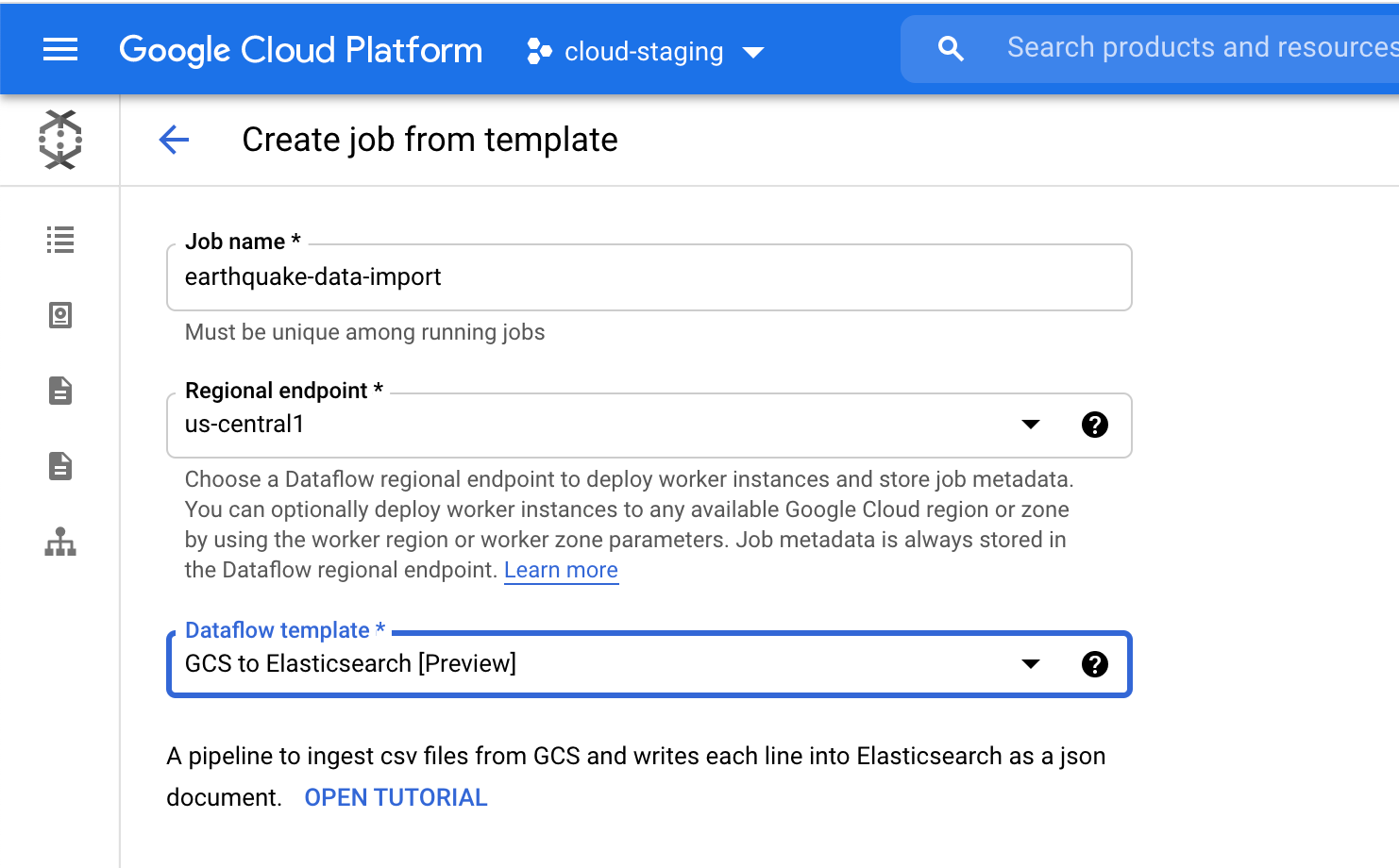
In the Dataflow page on the Google Cloud Console, select the GCS to Elasticsearch template. The template creates the schema for the JSON document using one of the following:
- Javascript UDF (if provided)
- JSON schema (if provided)
- CSV headers* (default)
If either a UDF or JSON schema is provided then it will be used instead of the CSV headers.
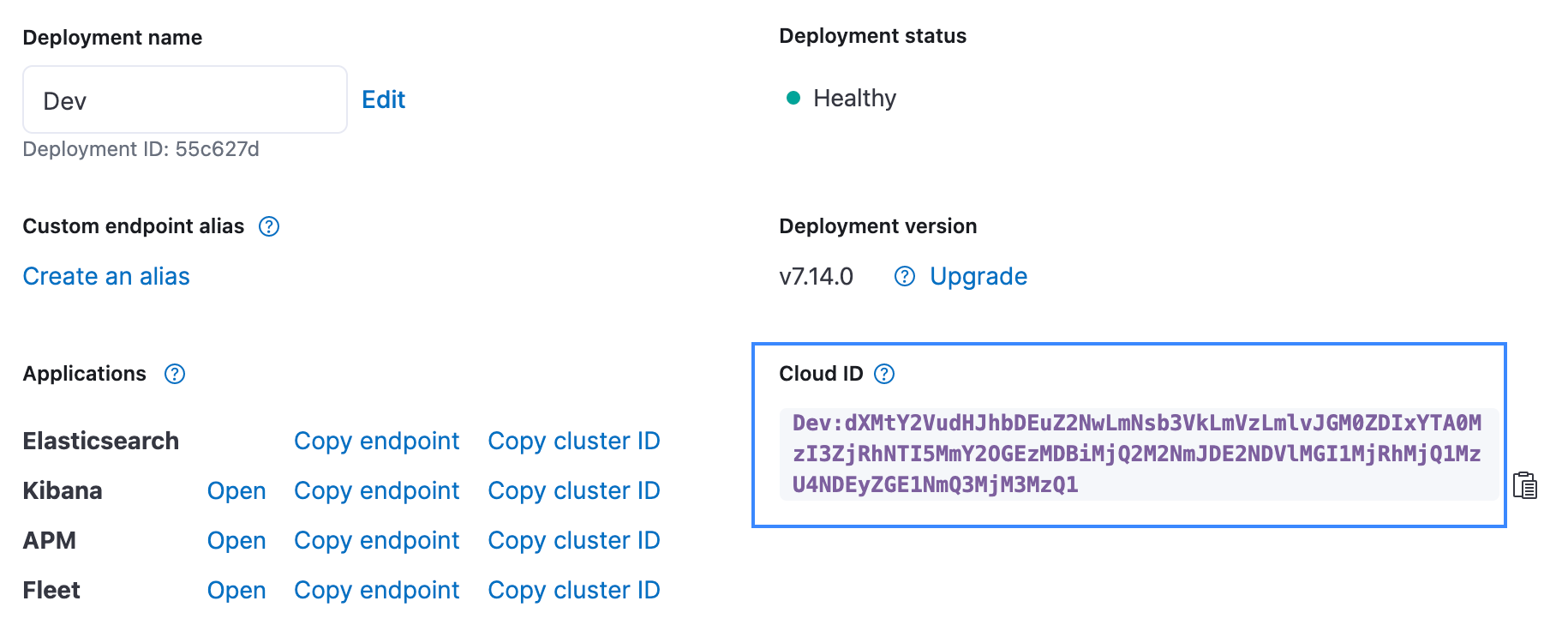
For the Elasticsearch index field, pick an index name where your data will be loaded. For example, we used the quakes index.
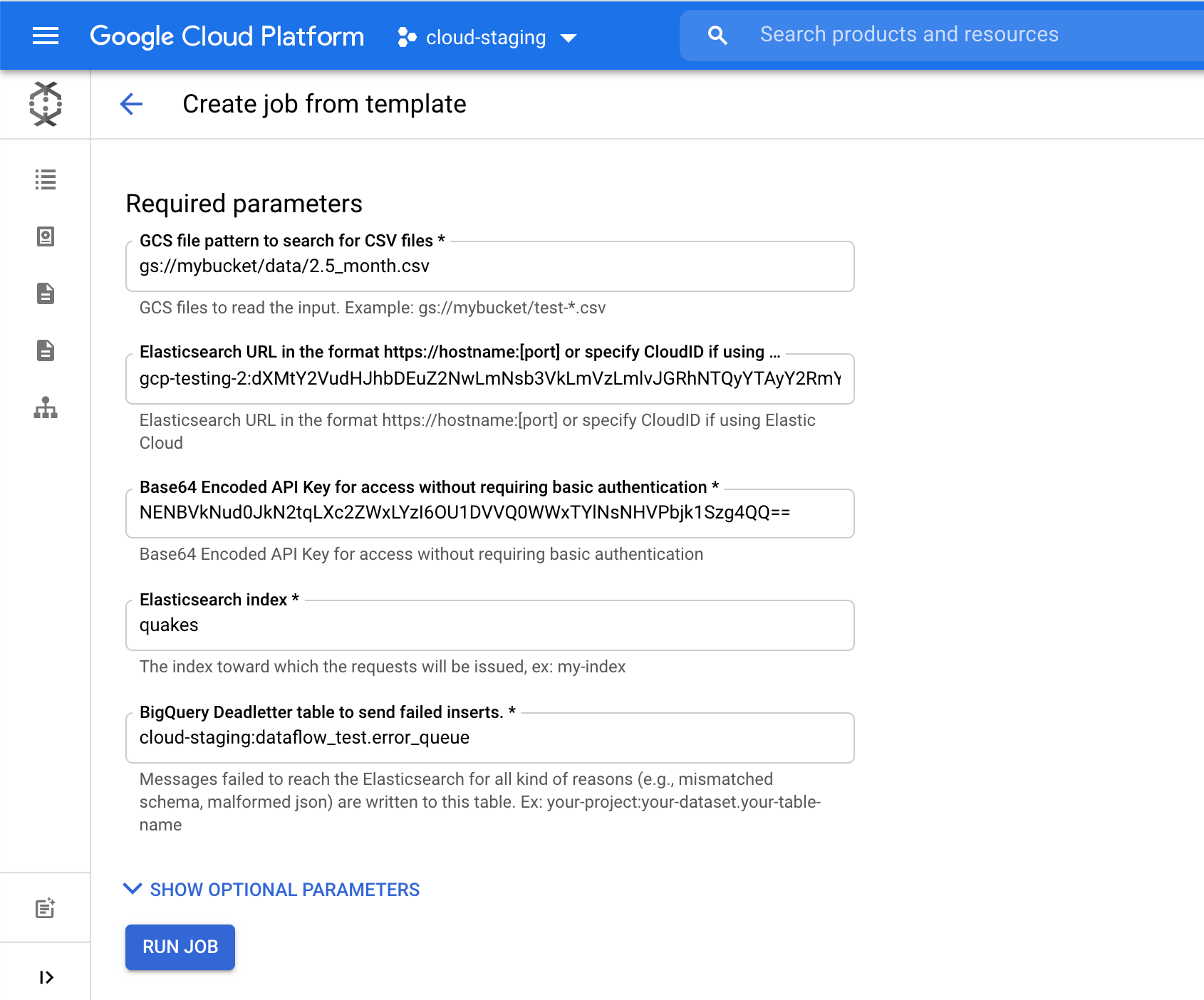
Click on Run Job to start ingesting this earthquake data in GCS to Elasticsearch, all without leaving the Google Cloud console.
You can then navigate to Kibana, create an index pattern, and start visualizing in minutes:
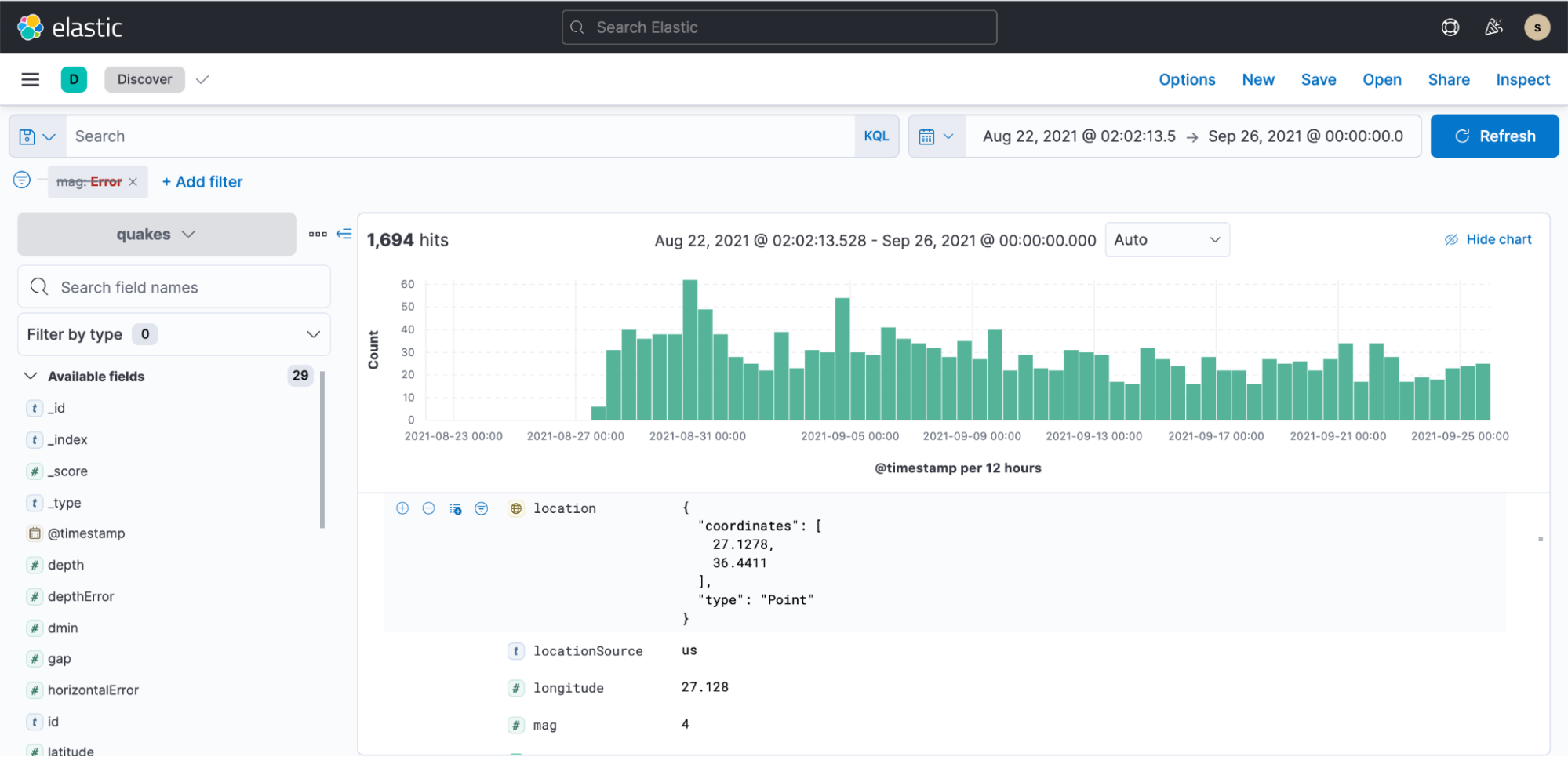
Sample dashboard that shows presentation of earthquake data:
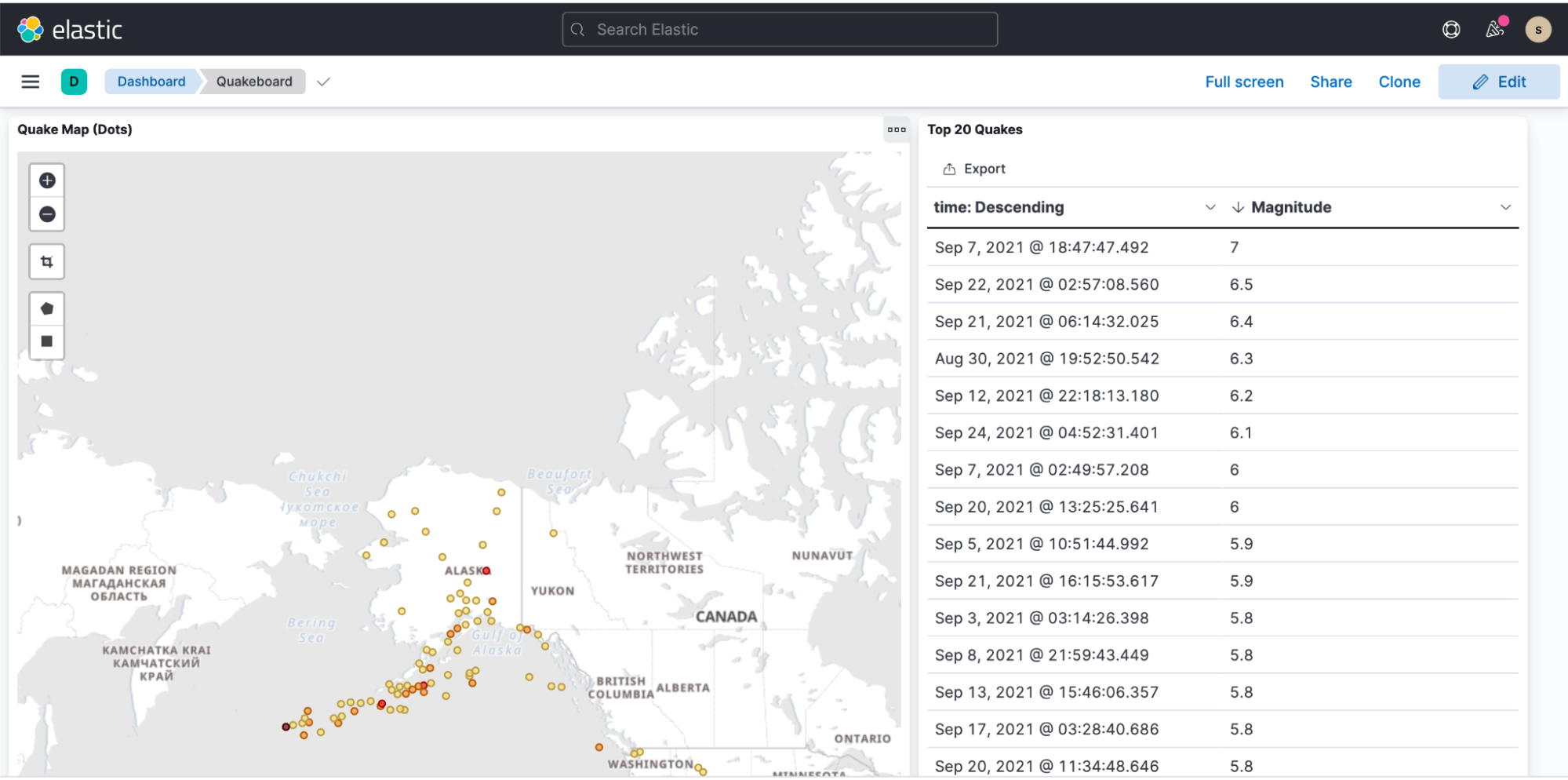
Wrapping up
Elastic is constantly making it easier for customers to run where they want and use what they want — and this streamlined integration with Google Cloud is the latest example of that. Elastic Cloud extends the value of the Elastic Stack, allowing customers to do more, faster, making it the best way to experience our platform. For more information on the integration, visit Google’s documentation. To get started using Elastic on Google Cloud, visit the Google Cloud Marketplace or elastic.co.Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print