Ingest data directly from Google BigQuery into Elastic using Google Dataflow


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Today we’re excited to announce support for direct BigQuery data ingestion to the Elastic Stack. Now data analysts and developers can ingest data from Google BigQuery to the Elastic Stack with just a few clicks in the Google Cloud Console. By leveraging Dataflow templates, native integrations allow customers to simplify their data pipeline architecture, and eliminate operational overhead related to agent installation and management.
Many data analysts and developers use Google BigQuery as a data warehouse solution and the Elastic Stack as a search and dashboard visualization solution. To enhance the experience for both solutions, Google and Elastic have worked together to provide a simplified way to ingest data from BigQuery tables and views to the Elastic Stack. And all of this is possible with just a few clicks in the Google Cloud Console, without ever installing any data shippers or ETL (extract, transform, load) tools.
In this blog post, we’ll cover how to get started with agentless data ingestion from Google BigQuery to the Elastic Stack.
Simplify BigQuery + Elastic use cases
BigQuery is a popular serverless data warehouse solution that makes it possible to centralize data from different sources, such as custom applications, databases, Marketo, NetSuite, Salesforce, web clickstreams, or even Elasticsearch. Users can do joins of datasets from different sources and then run SQL queries to analyze data. It’s common to utilize the output of BigQuery SQL jobs to create further views and tables in BigQuery, or create dashboards to share with other stakeholders and teams in your organization — which can be achieved with Kibana, Elastic’s native data visualization tool!
Another key use case for BigQuery and the Elastic Stack is a full-text search. BigQuery users can ingest data into Elasticsearch and then query and analyze the search results using Elasticsearch APIs or Kibana.
Streamline data ingest
Google Dataflow is a serverless, asynchronous messaging service based on Apache Beam. Dataflow can be used instead of Logstash to ingest data directly from the Google Cloud Console. The Google and Elastic teams worked together to develop an out-of-the-box Dataflow template for pushing data from BigQuery to the Elastic Stack. This template replaces data processing such as data format transformation previously completed by Logstash in a serverless manner — with no other changes for users who previously used the Elasticsearch ingest pipeline.
If you are using BigQuery and Elastic Stack today, you need to install a separate data processor like Logstash or a custom solution on a Google Compute Engine virtual machine (VM), and then use one of these data processors to send data from BigQuery to the Elastic Stack. Provisioning a VM and installing a data processor requires process and management overhead. Now you can skip this step and ingest data directly from BigQuery to Elastic using a dropdown menu in Dataflow. Removing friction is valuable to many users — especially when it can be done with a few clicks in the Google Cloud Console.
Here is a summary of data ingestion flow. The integration works for all users, regardless of whether you are using the Elastic Stack on Elastic Cloud, Elastic Cloud in the Google Cloud Marketplace, or a self-managed environment.
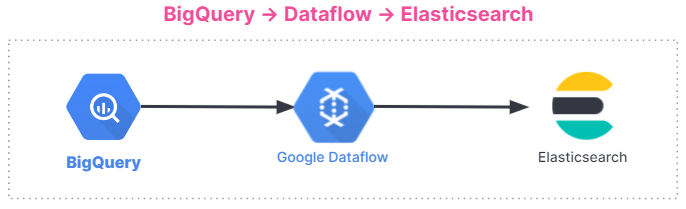
Get started
To illustrate how easy it is to integrate data from BigQuery to Elasticsearch, we'll use a public dataset from the popular Q&A forum Stack Overflow. Within just a few clicks you can ingest the data via the Dataflow batch job, and start searching and analyzing in Kibana.
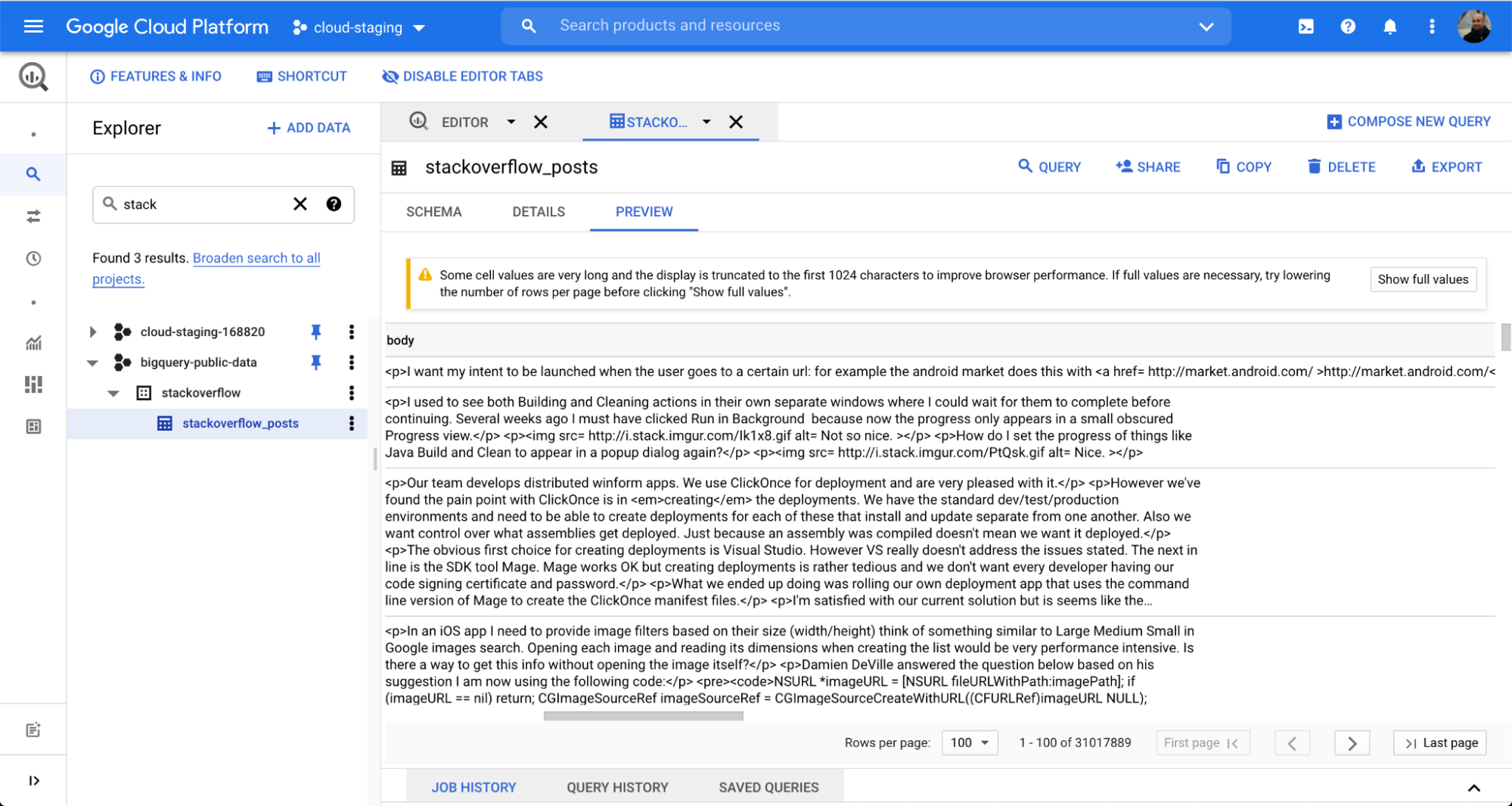
We used a table called stackoverflow_posts under the BigQuery data set stackoverflow. It has several structured fields as columns like post body, title, comment_count, etc., which we’ll bring into Elasticsearch to perform free text search and aggregation.
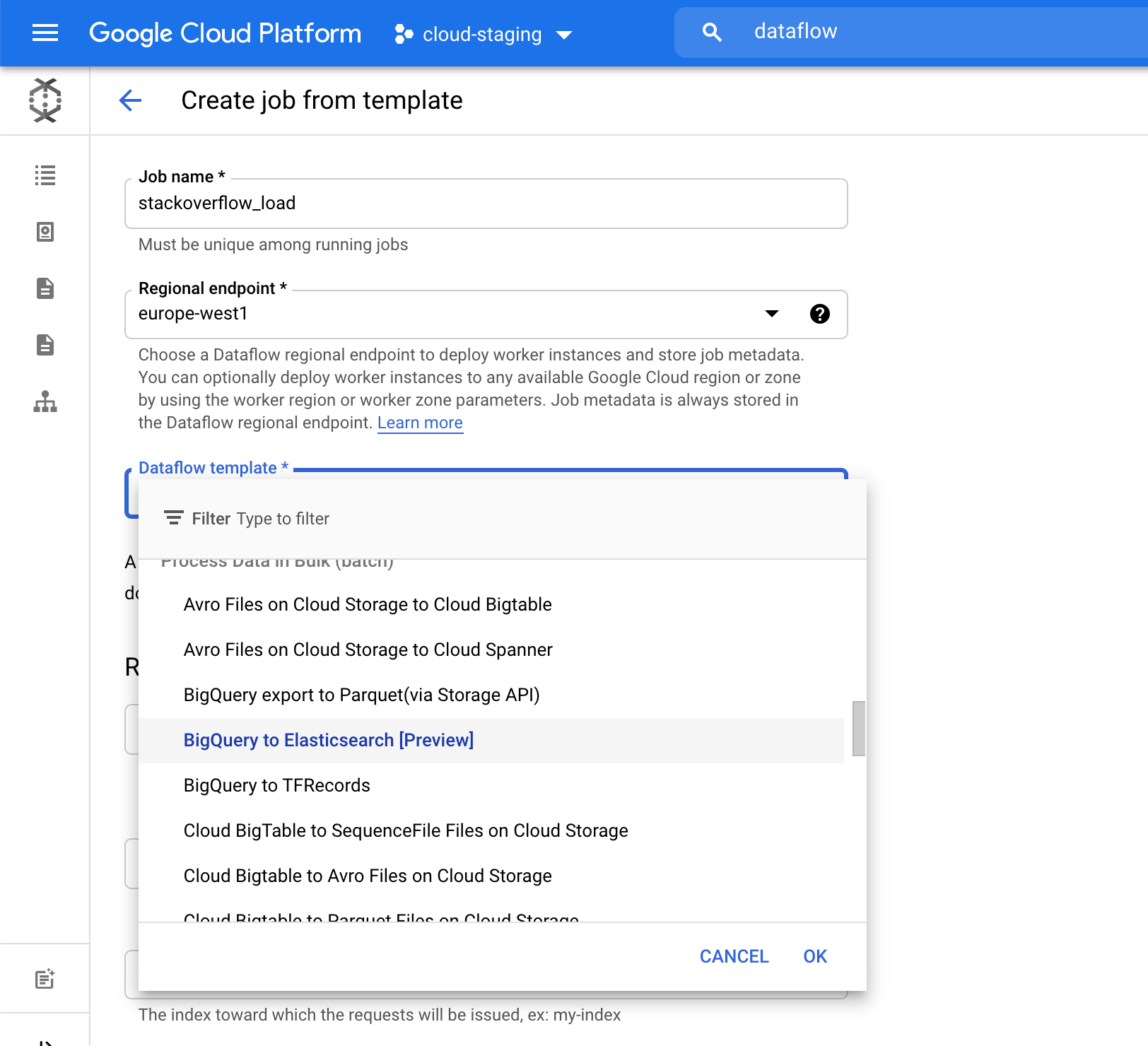
For the Elasticsearch index field, pick an index name where your data will be loaded. For example, we used the stack-posts index. Table in BigQuery to read from in the form of: my-project:my-dataset.my-table. In our example it is bigquery-public-data:stackoverflow.stackoverflow_posts.
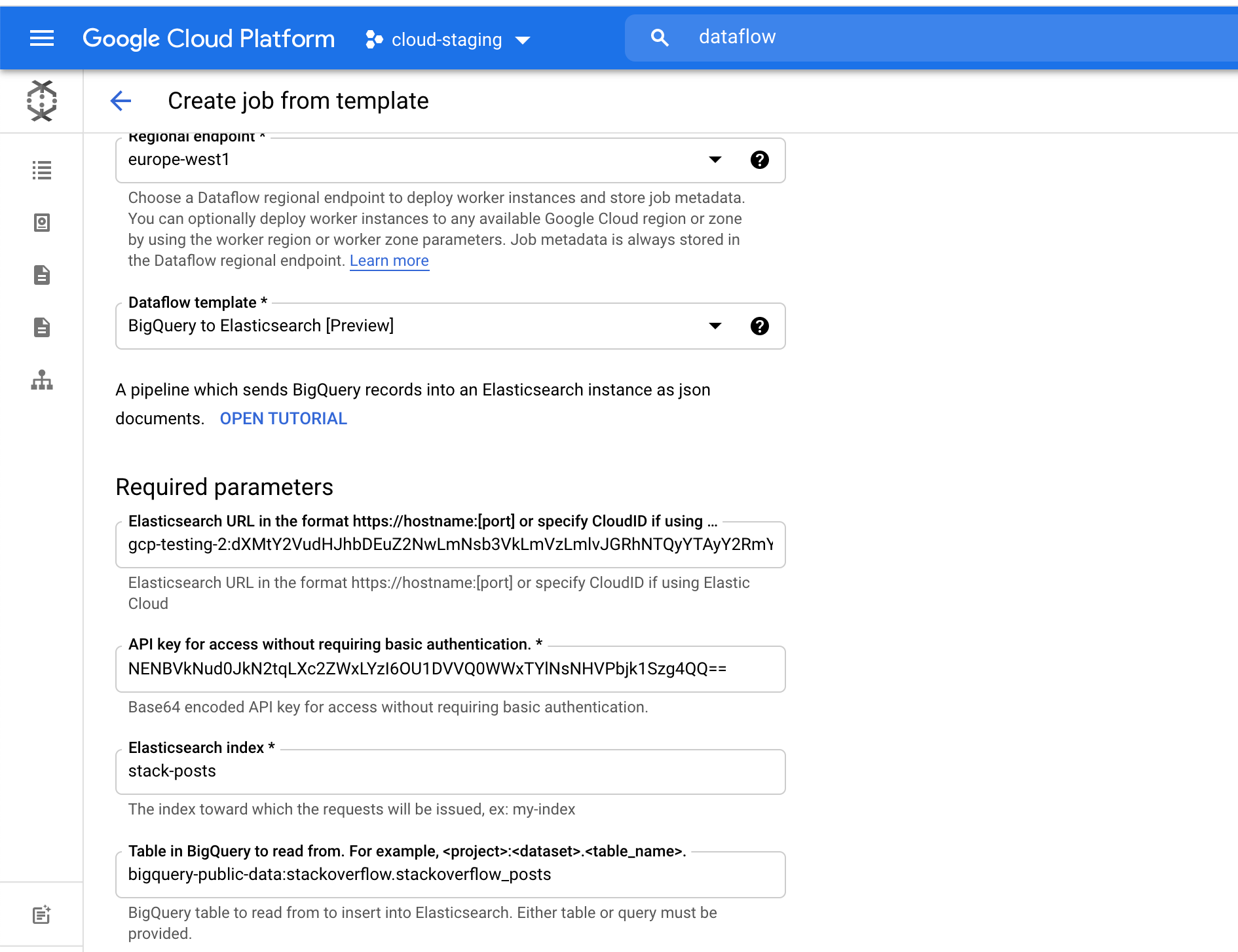
Click Run Job to start the batch processing.
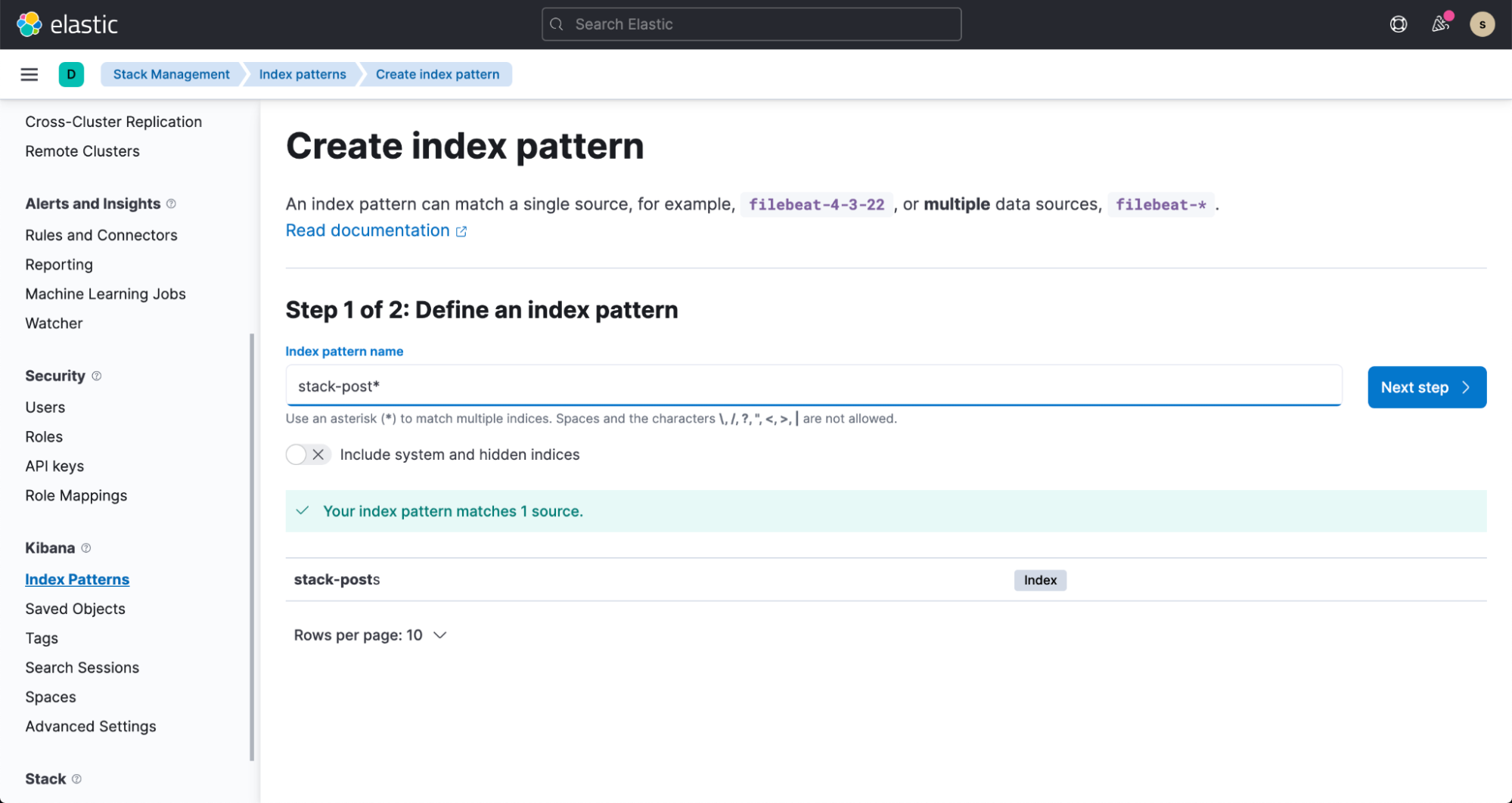
Within a few minutes, you can see the data flowing into your Elasticsearch index. To visualize this data, create an index pattern by following the documentation.
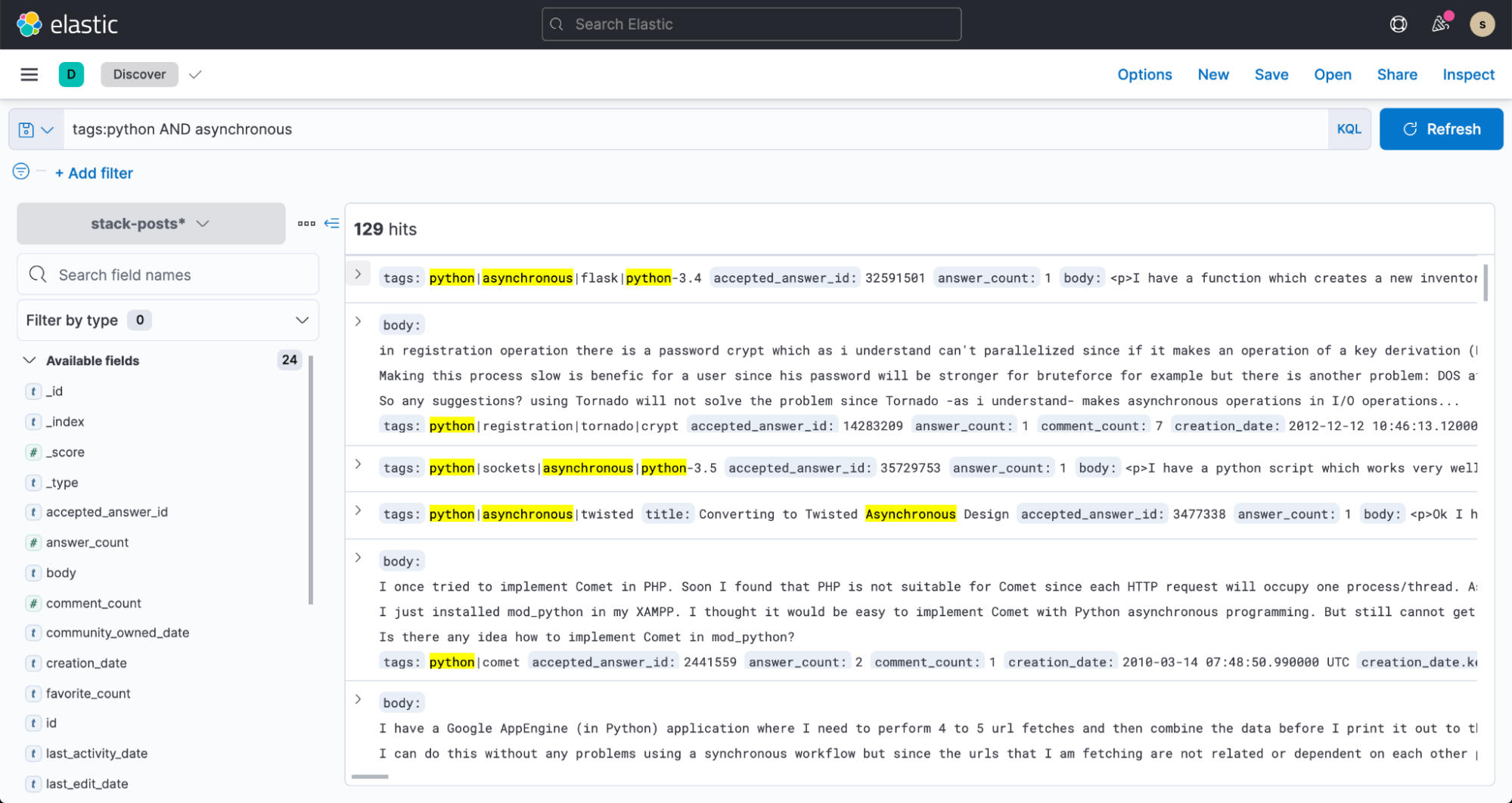
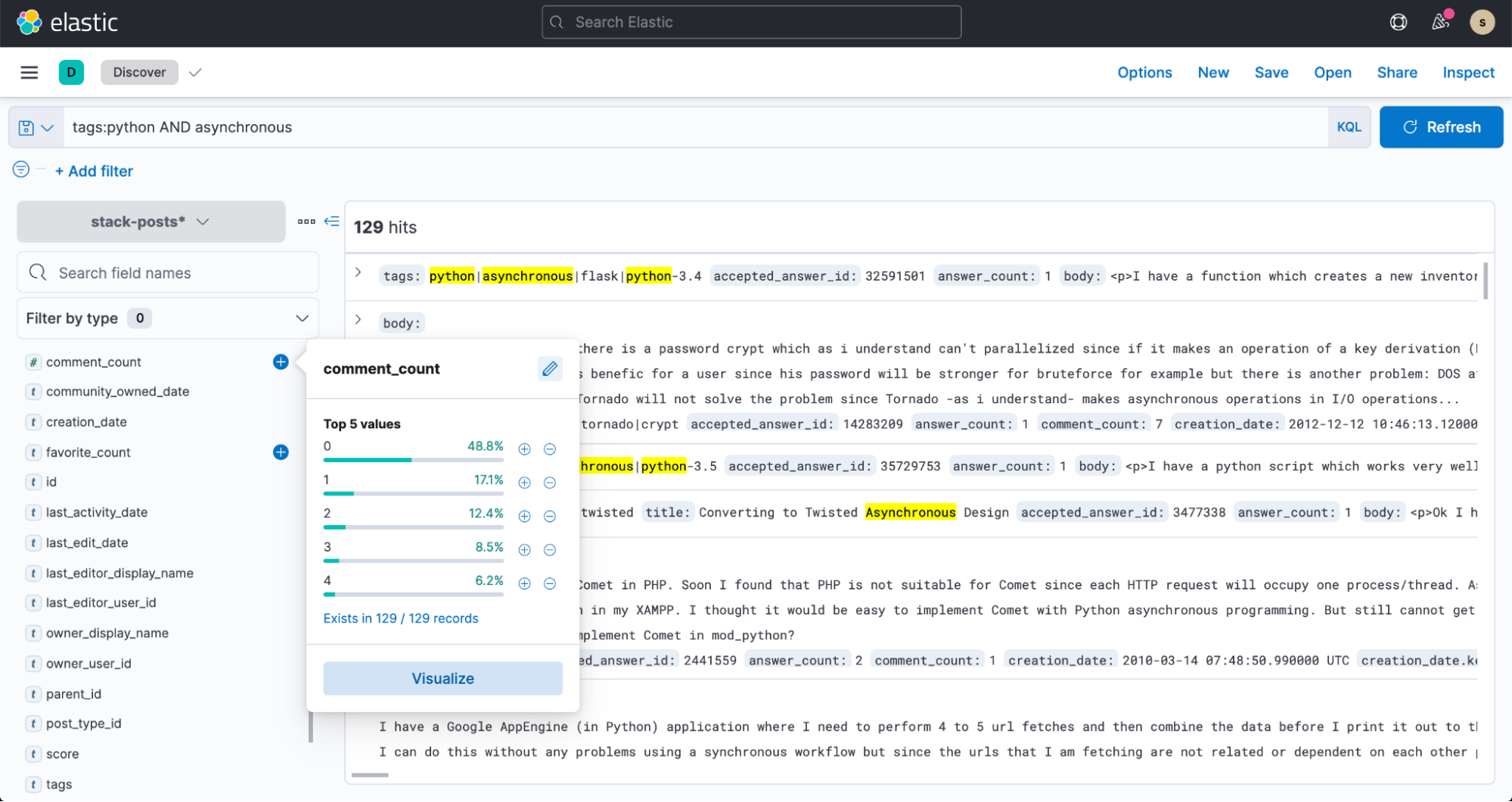
And now, head over to Discover in Kibana and start searching your data!
Wrapping up
Elastic is constantly making it easier and more frictionless for customers to run where they want and use what they want — and this streamlined integration with Google Cloud is the latest example of that. Elastic Cloud extends the value of the Elastic Stack, allowing customers to do more, faster, making it the best way to experience our platform. For more information on the integration, visit Google’s documentation. To get started using Elastic on Google Cloud, visit the Google Cloud Marketplace or elastic.co.Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print