How do I enable Elasticsearch for my data?
Elastic App Search is the fastest mechanism to go from nothing to robust search over your data. One of the primary reasons for this is the multiple options available to developers to ingest content into Elastic App Search.

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Regardless of what kind of data your enterprise is working with, from big databases to blog posts, here at Elastic, we know that you just want to be able to search over it. For our customers, the outputs, no matter the inputs, all raise the same question: “What do I need to do to get search enabled for my data?” Fortunately, there are myriad ways to get your datasource fully indexed and searchable in Elastic Cloud. In this blog post, I am going to define all the ways you can ingest data using Elastic.
Just point and crawl
The quickest way to get data into Elastic App Search is to use the web crawler, which was made generally available in Elastic 7.15. The web crawler allows you to identify a URL and define a sitemap, as well as crawl rules and document handling and just start a crawl. If your website content is in a “crawable” state (available over the public internet, server-side rendered, and does not have a robots.txt that blocks crawlers) pages will begin to be indexed in Elastic App Search after you start a crawl.
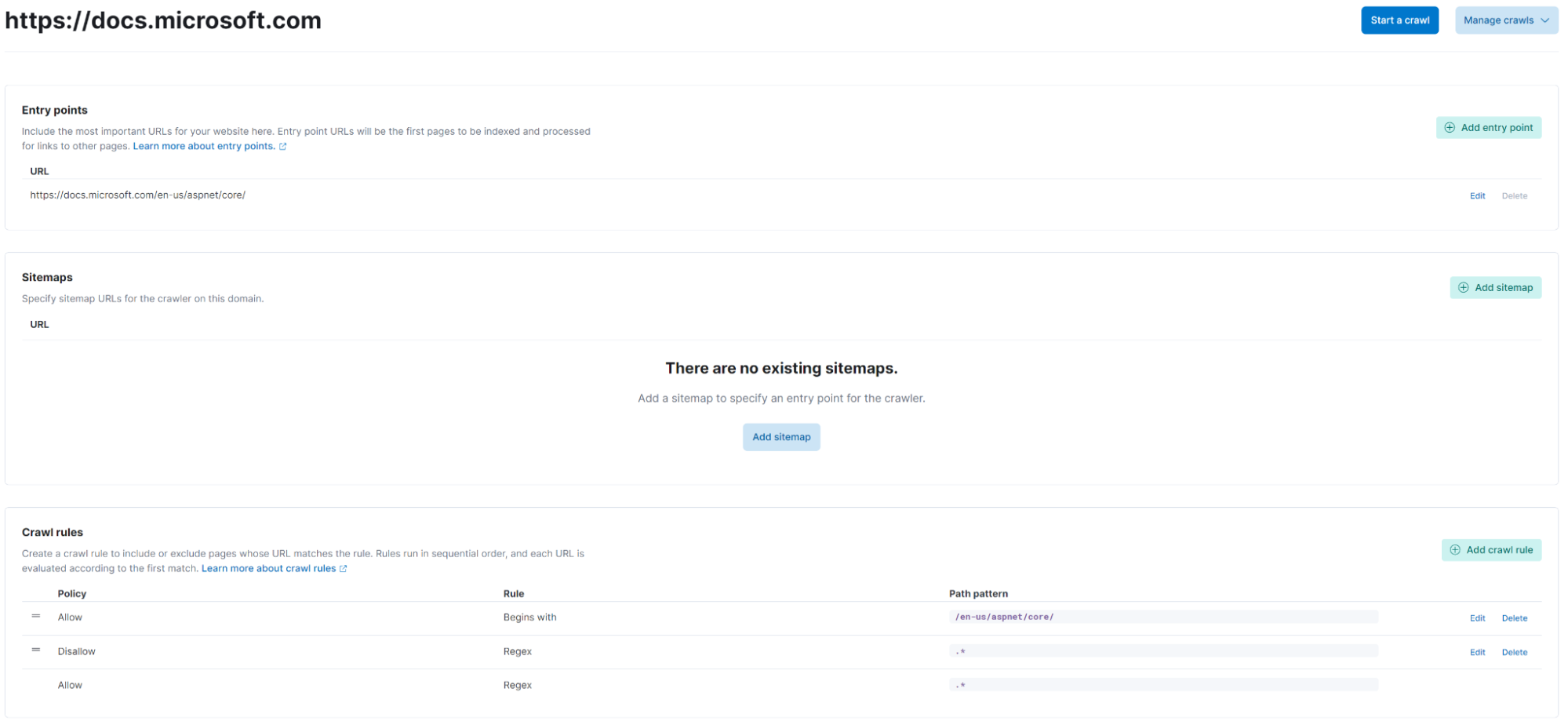
Depending on your route structure and content size, this may take some time Afterwards you have a fully-indexed dataset that you can analyze and tune to the needs of your users. For more information on the web crawler, visit the web crawler documentation.

Ingestion of JSON data
The web crawler is extremely powerful, and the ability to just point at your data and index it with little-to-no intervention is empowering. But, what happens in the scenario where we have data that doesn’t meet the predefined criteria for it to be crawlable? Maybe the data isn’t web content at all, but data used and managed by other systems? For these scenarios, we also offer the ability to ingest data in one-off workflows, such as file upload and text-paste options. In these scenarios, users have the ability to supply a JSON file representing their data and upload it or paste it into a web browser. In both cases, there is a maximum allowed content size, which is roughly 100 KB of JSON data.
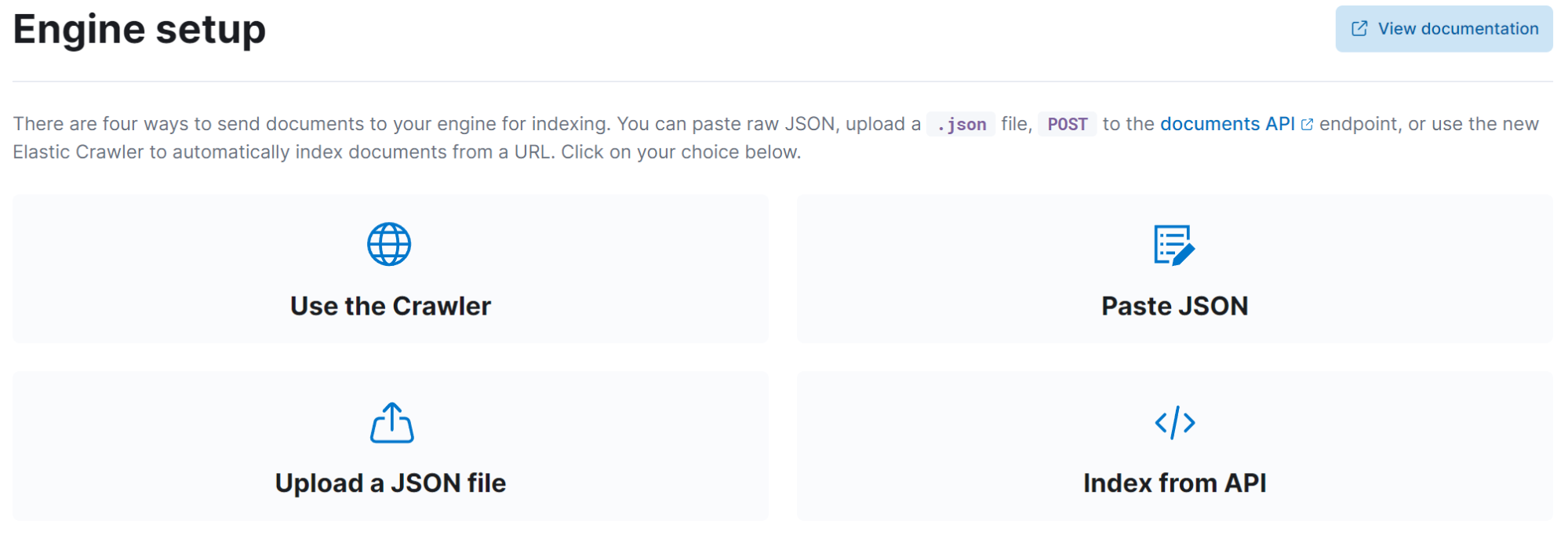
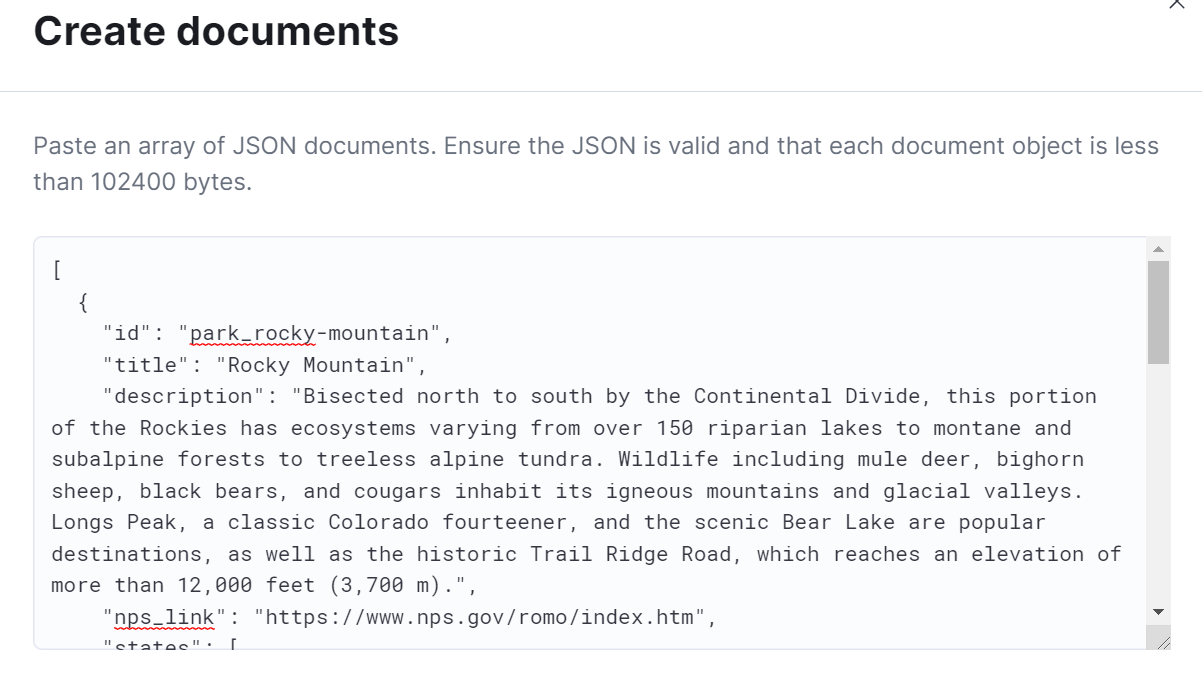
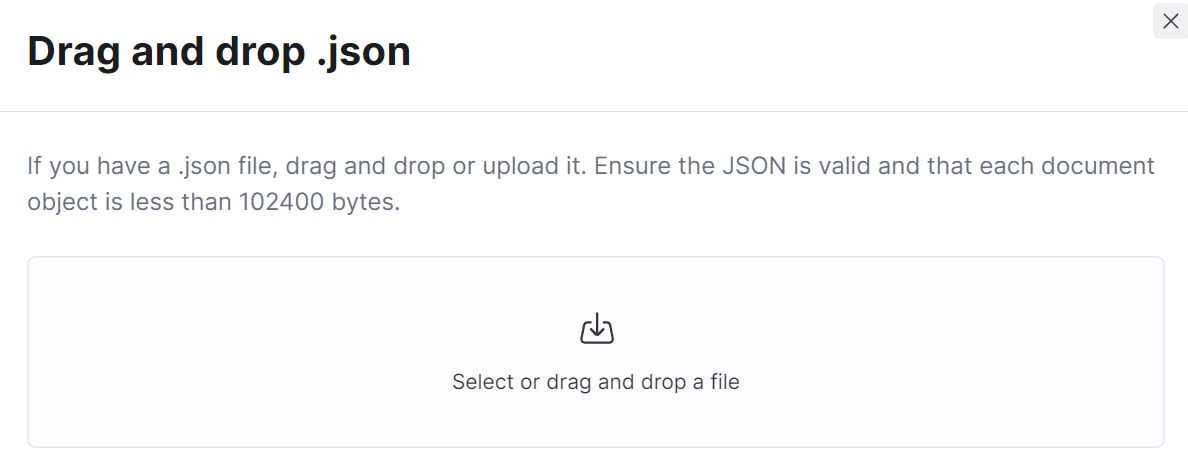
When you want to index data at scale
We have seen how frictionless it can be to get data into Elastic App Search in different modalities. However there is still the use case for "everything else," when our data is ever changing and large. In that case, there is a suite of well defined APIs to index content into Elastic App Search and enable a reusable method to update that content. For example, let's say I have a dataset representing all the statistics for the entire history of Major League Baseball (MLB) and I want to be able to search over that data in the most performant and scalable way possible. I can create a custom process particular to my needs to index and refresh this data as needed.
The dataset in question currently resides in an on-prem SQL Server database. SQL Server is a relational database platform created by Microsoft.
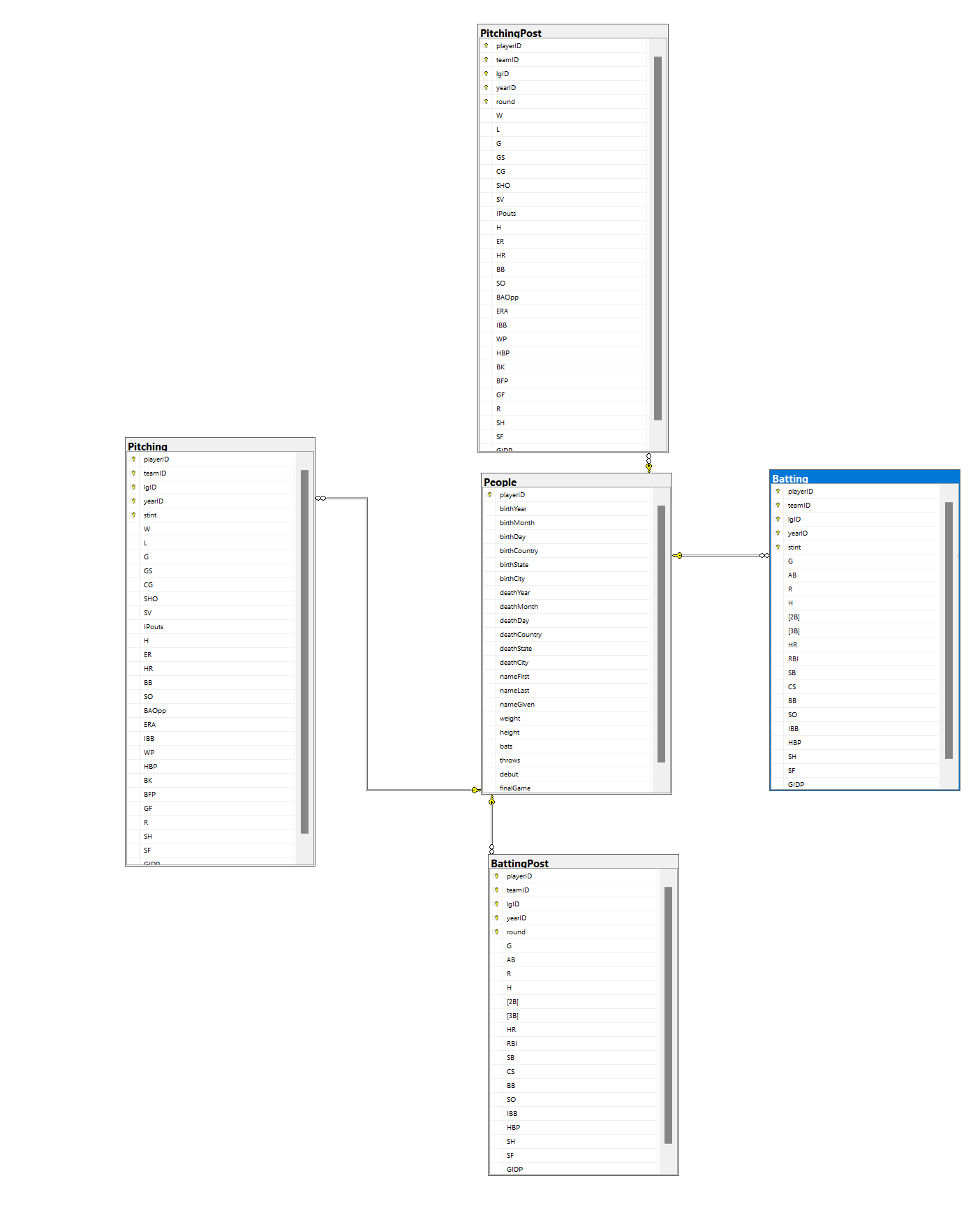
What I want to be able to do is index player batting and pitching statistics and be able to search over and analyze this data. There are a few steps that I will need to take in order to get to a solution that satisfies my goals:
- Create a process to take the relational data and format it into a way that I can then index into Elastic (data in Elastic is stored in denormalized format, so we will need to create a mechanism to map the data).
- Create another process to actually index this data into Elastic, using the Elastic App Search API (see Documents API for more information on document indexing)
- Start by indexing a small sample of data, and confirm my data is being indexed and stored the way I want before moving to the entire dataset.
Here are some rough numbers of row counts representing my dataset.
Person: 19,370
Batting: 104,324
BattingPost: 139,430
Pitching: 45,806
PitchingPost: 5,445
Though this isn’t a massive dataset as it pertains to rows, I know that I will need to create a structure that represents ALL BATTING AND ALL PITCHING statistics for each person. This means that after the indexing exercise completes, there will be 19,370 fairly large documents in Elastic App Search.
For the first step, I'll perform data retrieval and convert the relational data into a structured document per person. I am going to gloss over the details here, but I have chosen to use .NET 6 as the programming language to retrieve this data and serialize it into a JSON structure that I will then go and send to the Elastic App Search API for indexing. Here is the entire snippet of what that code looks like:
using IHost host = Host.CreateDefaultBuilder(args)
.ConfigureServices((_, services) =>
services.AddDbContextPool<BaseballStatsContext>(options => options.UseSqlServer(
"Server=.;Database=BaseballStats;Trusted_Connection=True;Application Name=BaseballStatsDb"))).Build();
var databaseContext = host.Services.CreateScope().ServiceProvider.GetRequiredService<BaseballStatsContext>();
var people = databaseContext.People
.Include(person => person.Battings)
.Include(person => person.BattingPosts)
.Include(person => person.Pitchings)
.Include(person => person.PitchingPosts)
.AsSplitQuery()
.ToList();
var chunks = people
.Select((x, i) => new { Index = i, Value = x })
.GroupBy(x => x.Index / 100)
.Select(x => x.Select(v => v.Value).ToList())
.ToList();
JsonSerializerOptions options = new() // setting serialization configuration
{
ReferenceHandler = ReferenceHandler.IgnoreCycles,
PropertyNamingPolicy = new LowerCaseNamingPolicy() //make all serialized json properties lower case
};
HttpClient client = new HttpClient();
client.BaseAddress = new Uri("https://baseballsearch.ent.westus2.azure.elastic-cloud.com");
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));//ACCEPT header
foreach (var chunk in chunks)
{
HttpRequestMessage request = new HttpRequestMessage(HttpMethod.Post, "/api/as/v1/engines/baseball-stats/documents");
// get API Key from Elastic Cloud to have authenticated request
request.Headers.Authorization = new AuthenticationHeaderValue("Bearer", "");
// serialize C# object to string for post to API
string jsonString = JsonSerializer.Serialize(chunk, options);
request.Content = new StringContent(jsonString, Encoding.UTF8, "application/json");//CONTENT-TYPE header
client.Send(request);
}What this code does is query the database for all our person data (including relationships for batting and pitching), split that dataset into chunks of 100 (currently, the document create API has a limit of 100 documents per create event), and POST each chunk to my API endpoint. After it runs, I can confirm that all 19,370 documents have been indexed into Elastic.
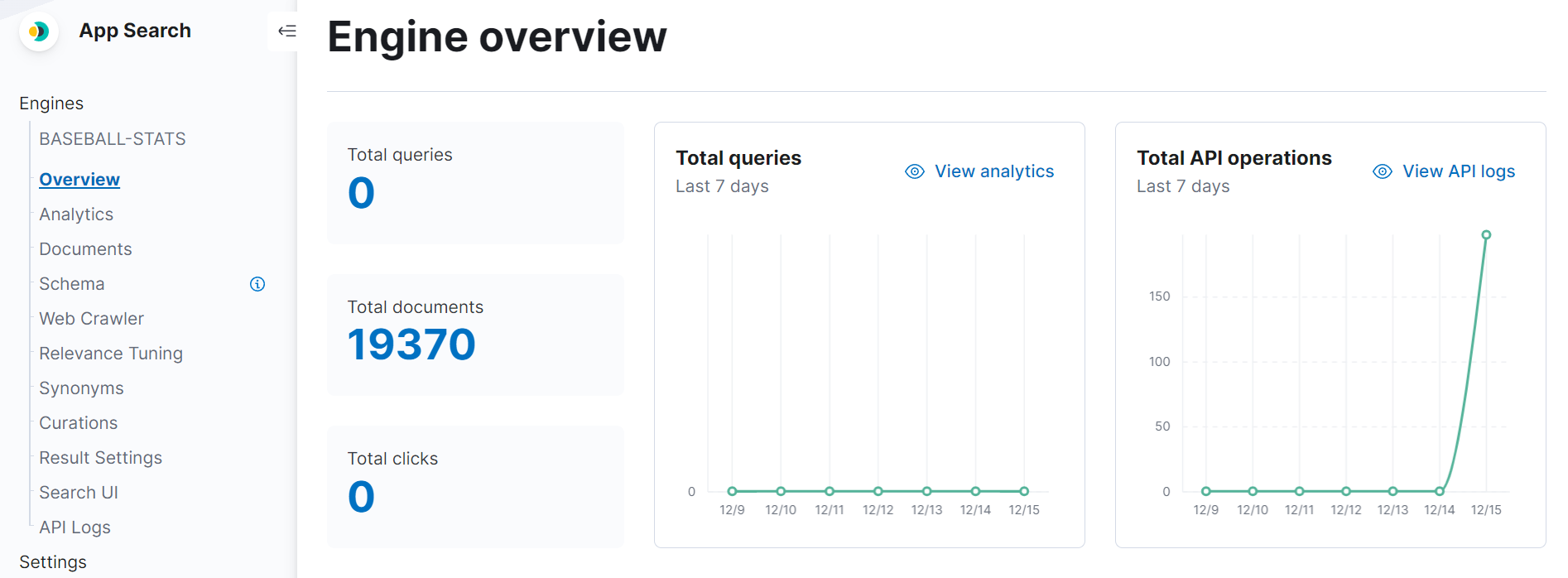
Once my data is in Elastic, I have the ability to gather insights about this data using visualization tools in Kibana as well as build a bespoke search experience for users that want to search over this data.
Ingest the way you want to
With Elastic, you have many options to ingest data to be able to search it. This blog post covered some of these options and particular use cases, and when to use them. Regardless of how your data is structured, or where it sits, you can feel comfortable knowing that you can index this content and build great search experiences with it.
There is no better way to see this in action than signing up for a free trial of Elastic Cloud. Also, if you want to read more information about these ingestion options, please take a look at the following resources.
Additional resources
- Elastic web crawler | Elastic
- Elastic 7.15: Create powerful, personalized search experiences in seconds | Elastic Blog
- What's new in Elastic Enterprise Search 7.15: Web crawler GA and personalized Workplace Search | Elastic Blog
- Crawl web content | Elastic App Search Documentation [7.16] | Elastic
- Indexing Documents Guide | Elastic App Search Documentation [7.16] | Elastic
- Documents API | Elastic App Search Documentation [7.16] | Elastic
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print