Harnessing search to advance equity in healthcare
Applying multilingual NLP models and analytics to improve end user experience


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
As more productive and healthy populations live longer, healthcare will be one of the most important aspects of society. The COVID-19 pandemic has accelerated adoption of modern technologies and shined a light on the importance of patient experiences. As more consumers are taking control of their data, healthcare systems are getting stretched. According to a study published by Deloitte and the Scottsdale Institute, 92% of healthcare technology leaders see digital capabilities as a path to achieve better patient experience.
In this blog post, we’ll explore how Elastic’s search capabilities can help address potential barriers to health equity, as outlined in the Center for Medicare & Medicaid Services (CMS) strategic pillars — specifically, how to deliver relevant results for healthcare information to beneficiaries with limited English proficiency and understanding patterns of what consumers are searching for or asking.
By the end, you’ll be able to develop your own search application by incorporating the following elements in a practical way:
- Applying natural language processing (NLP) machine learning models
- Using semantic search for multilingual queries without increasing your storage footprint
- Bringing in user analytics
- Tuning analytics to continuously improve the end-user experience
Using code provided by the Elastic GitHub repository you don’t need to sweat the code — it’s all there! Additionally there are more details on how to set things up if you’d like to get hands-on.
Loading up with initial knowledge
We’ll start by gathering a dataset of insurance-related question and answer pairs from the Insurance Library website. This corpus* contains over 12,000 questions from real world users that are answered by licensed insurance agents with deep domain knowledge.
To keep this on point, we’ll upload this data as a file; if you’re interested in using the Elasticsearch Python client to do this programmatically, check out the Github repository.
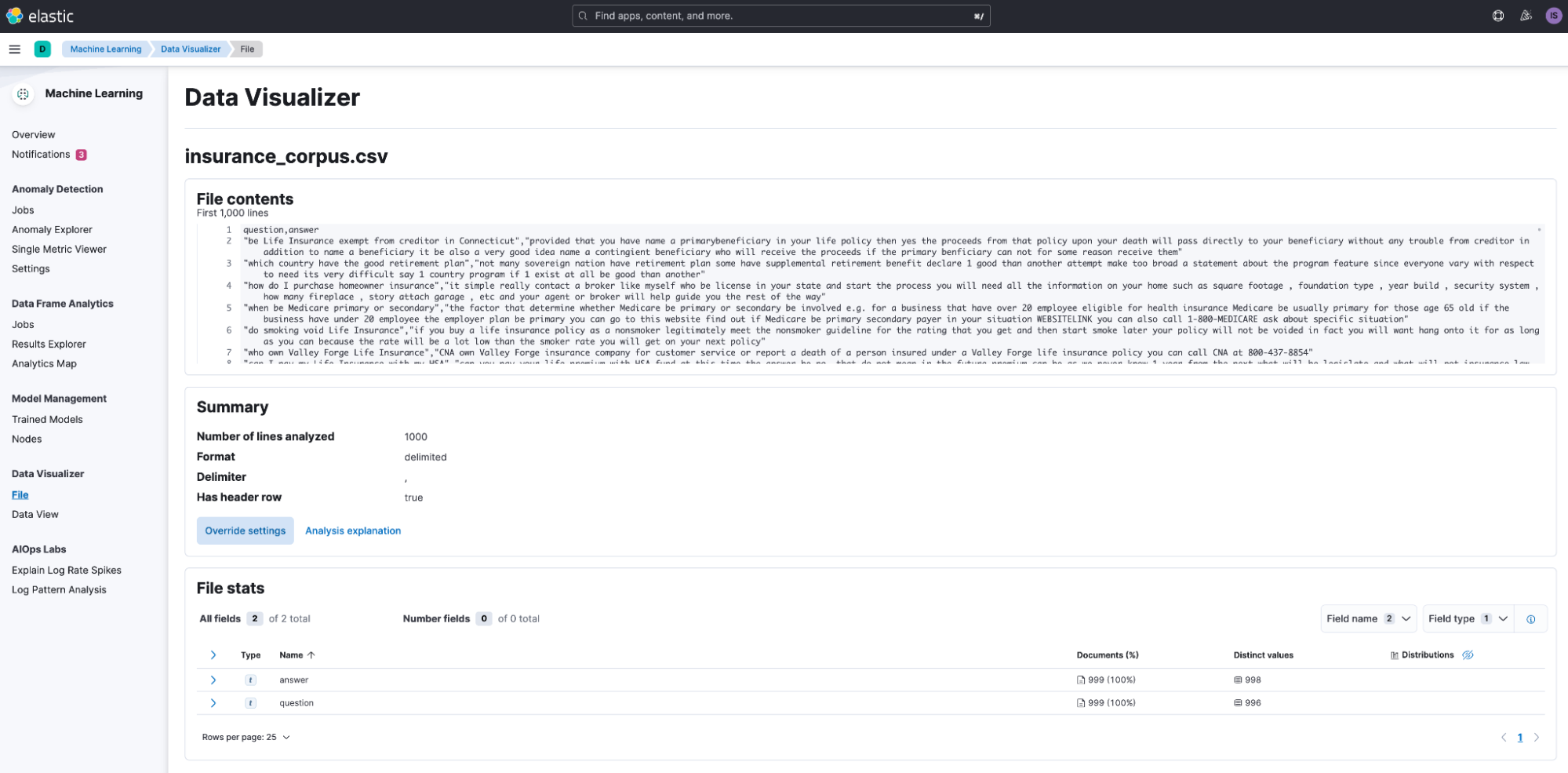
Using the File Data Visualizer, we now have a wealth of knowledge sitting inside Elasticsearch waiting to be found.
Building up a search application
The Elastic platform comes with an analytics user interface called Discover that you can use right away to explore and query your data. Our end goal here though is to build a search application that is powered by Elastic to tackle our specific use case so we’ll approach this in the following bite-size pieces:
- Create a back-end service to query Elasticsearch for the insurance questions we imported through the File Data Visualizer. In this prototype we use Express.js.
- Build a front-end UI that connects to the back-end service to present insurance question results. In this prototype we use Angular.
Elastic comes with a rich set of APIs that enables developers to start building interesting applications! We’ll start building our back-end service by creating an endpoint that makes use of the Search API to return basic search results for a query.
app.get('/search-insurance', async (req, res) => {
query = req.query.query;
const response = axios.get('https://<ELASTICSEARCH_ENDPOINT>/insurance_qa_train_blog/_search', {
headers: {
'Content-Type': 'application/json',
'Authorization': 'ApiKey ${api_key}'
},
data: {
'query': {
'match': {
'question': {
'query': query
}
}
},
'_source': [
'question',
'answer'
]
}
}).then(response => {
res.send(response.data.hits.hits)
});
})If we try a search in English of “do I need renter’s insurance,” we get a number of relevant results.

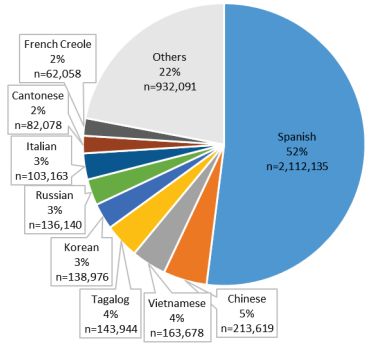
That’s great for English speakers, but let’s think about how we can support non-English speakers. As published by the CMS, communication and language barriers are associated with decreased quality of care and outcomes so helping to bridge that gap is the goal. Taking a look at specific languages spoken by Medicare beneficiaries with limited English proficiency, Spanish is overwhelmingly the most common in the United States and across most states, with over half identifying it as the language they speak at home.
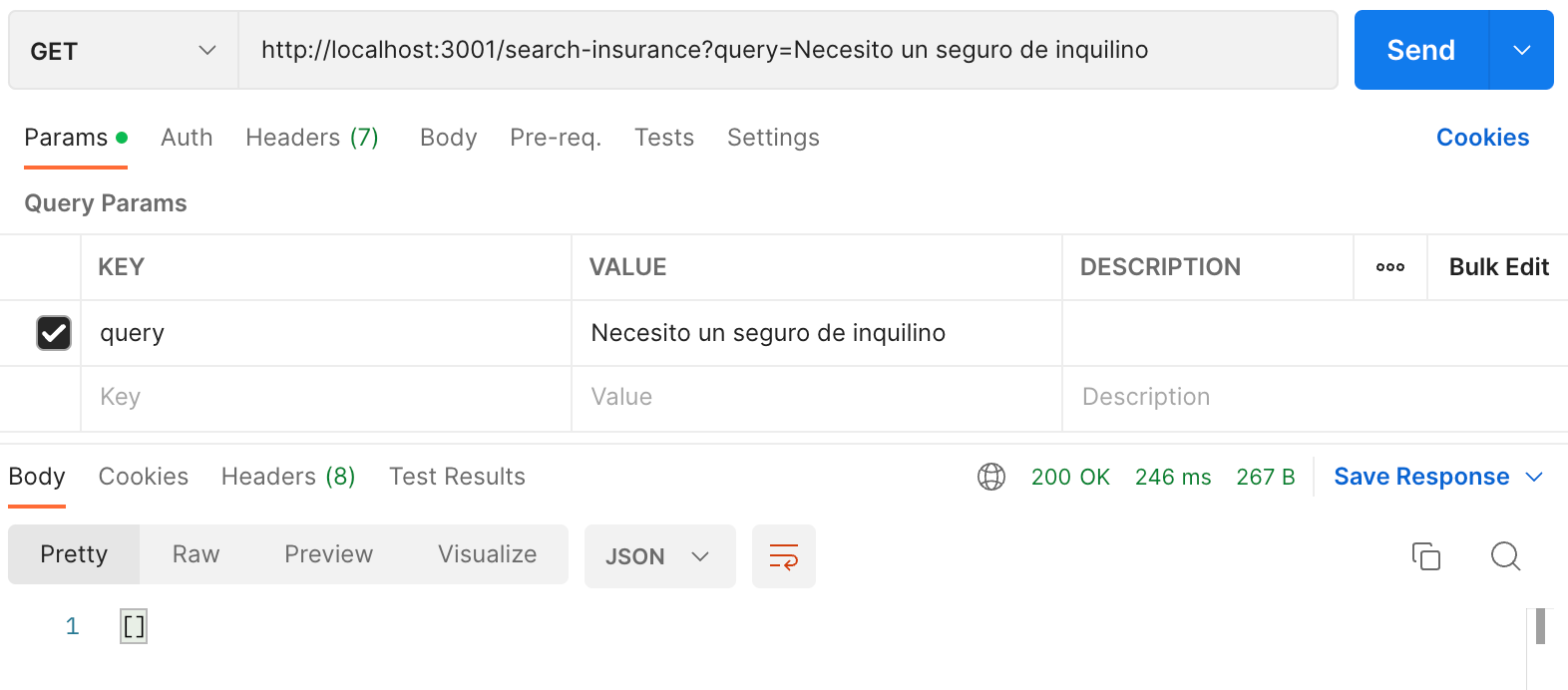
So what happens if we try this in another language like Spanish? With a question of “necesito un seguro de inquilino,” we get 0 results. Not too surprising since our API hasn’t gone to school to learn other languages. However, it’s never too late to keep learning so let’s see an approach of how we can do this.
Learning new languages
We could approach this in different ways, such as by having someone or some program translate the corpus of insurance questions into different languages. Or if we had sources of data in different languages, we could apply language identification as described in a previous blog about multilingual search to store it using language-specific analyzers.
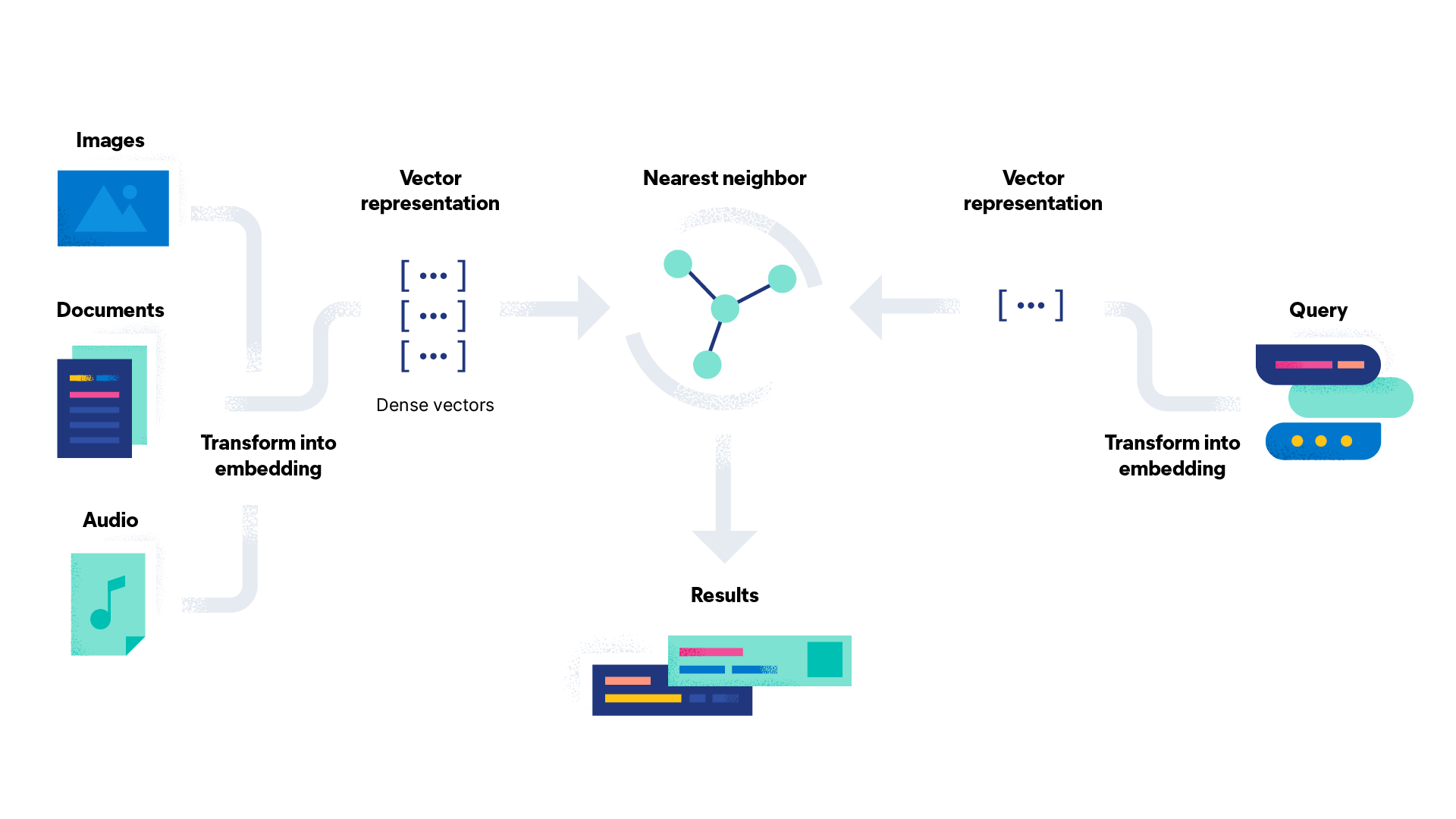
A parallel approach we can pursue until we get those translations complete is to bring NLP models into Elastic, a capability that was introduced in version 8.0. Breaking it down, there are essentially 3 steps:
- Import a trained NLP model: The one we’ll use is a multilingual model that supports 15 languages: Arabic, Chinese, Dutch, English, French, German, Italian, Korean, Polish, Portuguese, Russian, Spanish, Turkish.
- Convert our insurance questions into a vector representation: We do this by running the questions through the NLP model and storing those vectors into Elasticsearch
- Now we search: When we get a search query, that also get the NLP treatment to get represented as a vector and we can then use a nearest neighbor search to find relevant matches
The type of search we’ll do now goes by a couple monikers — semantic search, kNN search, vector search. Let’s take a quick look at some code to get this search going.
Importing a trained model
We can do this using eland, which is a Python Elasticsearch client for working with ML models. First, we build the eland docker client:
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .Then, we can run the client to install the NLP model to Elastic.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url https://elastic:<password>@<elasticsearch_endpoint>:9243/ \
--hub-model-id sentence-transformers/distiluse-base-multilingual-cased-v1 \
--task-type text_embedding \
--startTo learn more, see our multi-part blog series on getting started with NLP.
Converting the insurance questions to a vector representation
In order to prepare the question set for a vector search, we need to create text embedding (i.e., vector representation) of each of the questions using the ML model we just imported.
We'll do this by creating a separate index that will store these text embeddings. From Stack Management > Dev Tools, run the following request:
PUT insurance-questions-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine"
}
}
}
}Now we create a pipeline that each document goes through to create the text embeddings.
PUT _ingest/pipeline/insurance-question-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__distiluse-base-multilingual-cased-v1",
"target_field": "qa_text_embedding",
"field_map": {
"question": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}We're now ready to reindex our questions so they go through the ML inference pipeline to create the text embeddings, which then get stored in our new index named insurance-questions-embeddings.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "insurance-questions"
},
"dest": {
"index": "insurance-questions-embeddings",
"pipeline": "insurance-question-embeddings"
}
}Performing the search
With our insurance questions now carrying a text embedding value, which was created from the NLP model we imported, we’re now ready to search. First we use the Infer Trained Model API to take our search query and get its dense vector representation.
async function infer_nlp_vectors(query) {
const response = axios.post(
'https://<ELASTICSEARCH_ENDPOINT>/_ml/trained_models/sentence-transformers__distiluse-base-multilingual-cased-v1/_infer',
{
'docs': {
'text_field': query
}
}
return response;
}We can then feed our search query (in its vector form) to the Search API and use the kNN option to perform the nearest neighbor search we were talking about.
async function semanticSearch(query_dense_vector) {
const response = axios.get('https://<ELASTICSEARCH_ENDPOINT>/insurance-qa-embeddings/_search',
data: {
'knn': {
'field': 'qa_text_embedding.predicted_value',
'query_vector': query_dense_vector,
'k': 10,
'num_candidates': 100
},
'_source': [
'question',
'answer'
]
}
});
return response;
}Let’s see how our query in Spanish works now that we’ve taught our application some new languages.
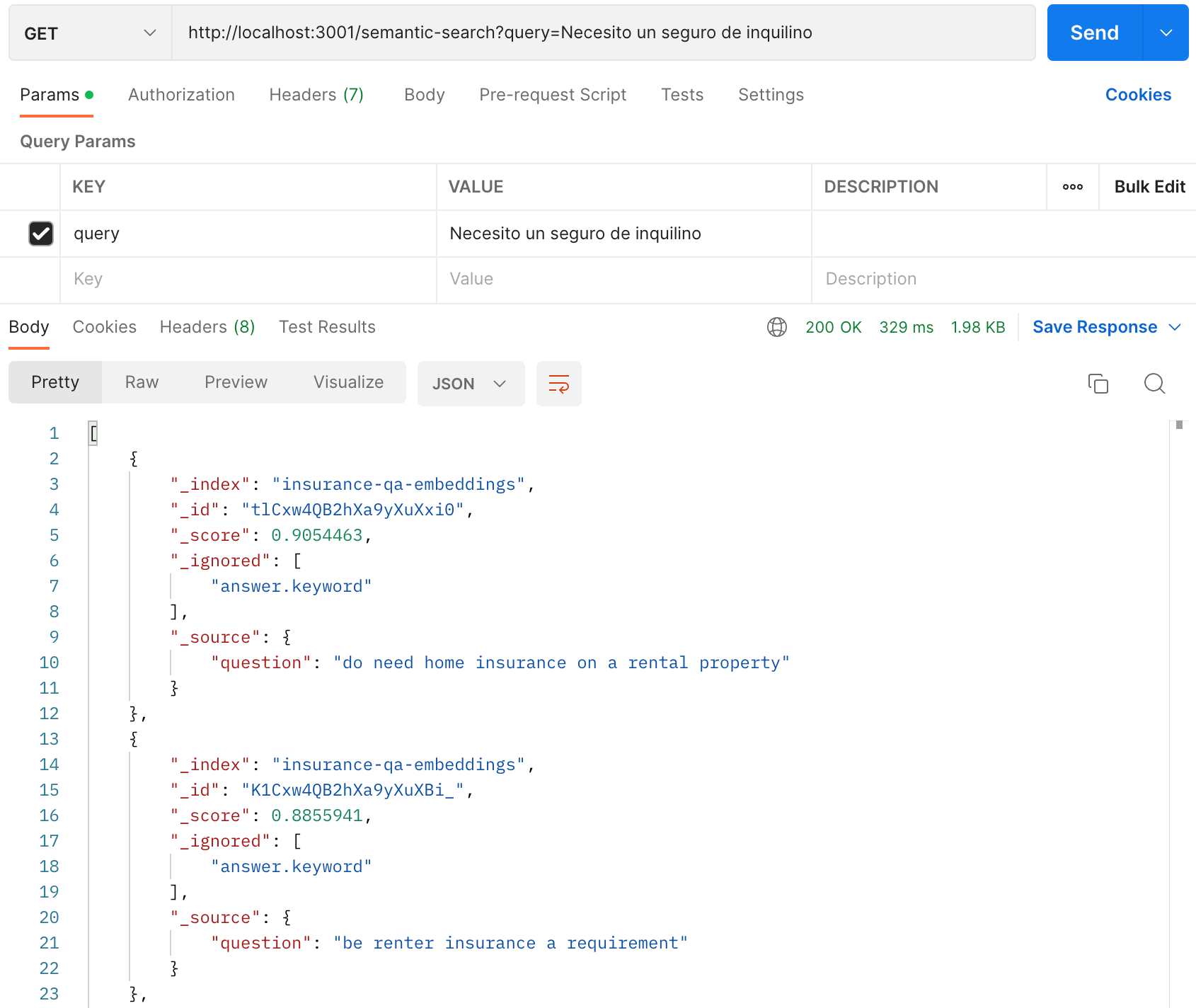
We’re now getting results without having to translate the 12,000 insurance questions into Spanish!
Making ourselves presentable
Since most people prefer not to get their everyday information in JSON format, let’s wrap our newly minted semantic search API with a user interface.
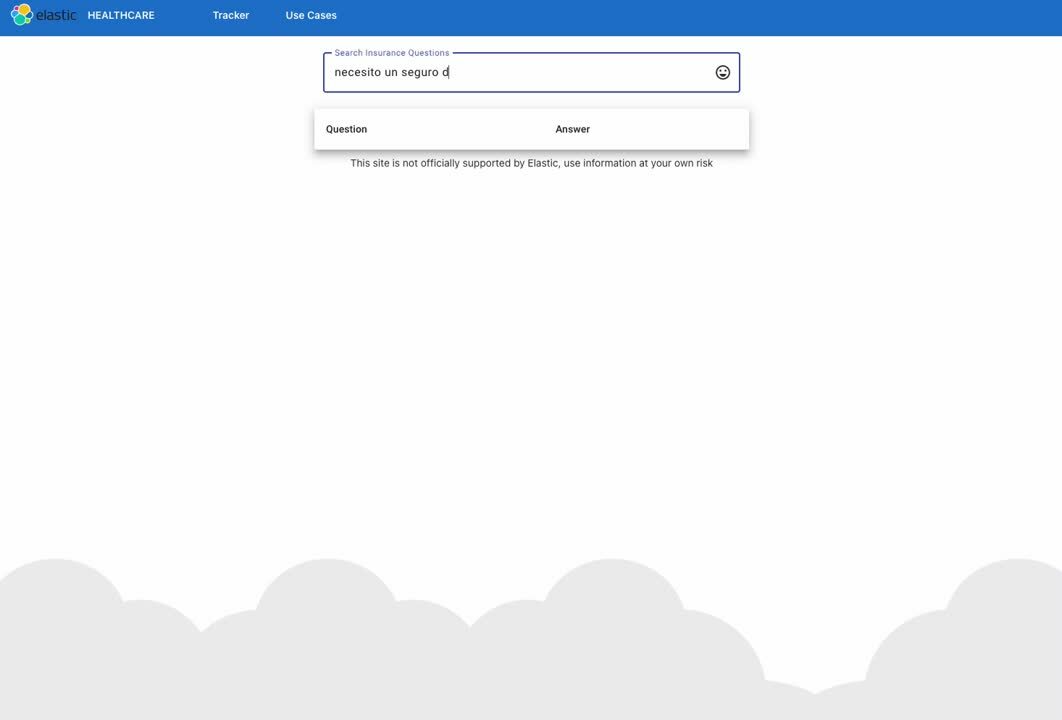
Our users can now use our search capability, we’re done now… right? Never! There’s always more to be done, and there is a rich set of APIs to accomplish modern search enhancements, such as:
- Adding suggesters for that “did you mean this?” experience
- Implementing auto-complete with the search-as-you-type capability
- Working on tuning results
Actionable insights with search analytics
Now we’ll focus on what we want to know, what users are searching for, and if they’re finding it. For this a feedback loop is critical! Users often won’t take the time to complain about what they can’t find, so having that behind the scenes analytics helps provide insights before it takes center stage and helps improve overall end-user satisfaction.
We can use Elastic App Search, which is a powerful toolkit for search developers that gives us all the tuning and analytics capabilities for us. We’re able to add this toolkit on top of an existing Elasticsearch index by creating what’s referred to as an App Search engine. Think of this as a layer on top of our data that will give us tons of insight.
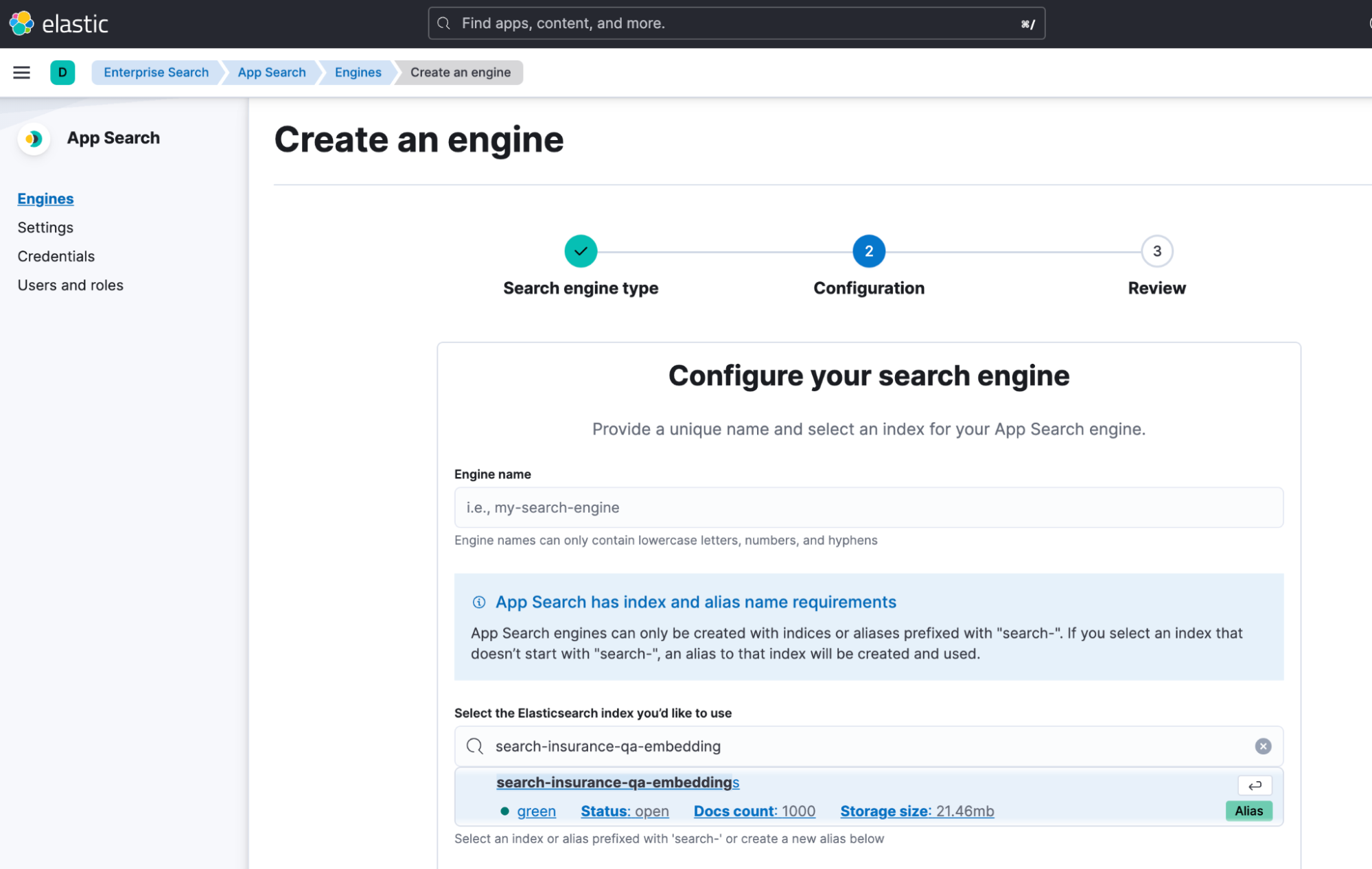
Let’s take a look at how this changes our API call. Instead of the regular Elasticsearch Search API endpoint, we make a minor modification to communicate through the App Search API which extends core Elasticsearch capability.
In this example, we can perform a hybrid search; one that does a vector search, and another that performs a traditional (BM25-based) search. This results in a combined relevancy score that can be used to show what matters most.
async function semanticSearchAnalytics(query_dense_vector, query) {
const response = await axios.post(
'https://<ELASTIC_ENDPOINT>/api/as/v1/engines/insurance-app-search/elasticsearch/_search',
{
'query': {
'match': {
'question': {
'query': query,
'boost': 0.5
}
}
},
'knn': {
'field': 'qa_text_embedding.predicted_value',
'query_vector': query_dense_vector,
'k': 5,
'num_candidates': 50,
'boost': 0.5
},
'_source': ['question', 'answer']
},
{
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ${apiKey}',
'X-Enterprise-Search-Analytics': query,
'X-Enterprise-Search-Analytics-Tags': query
}
}
);
return response;
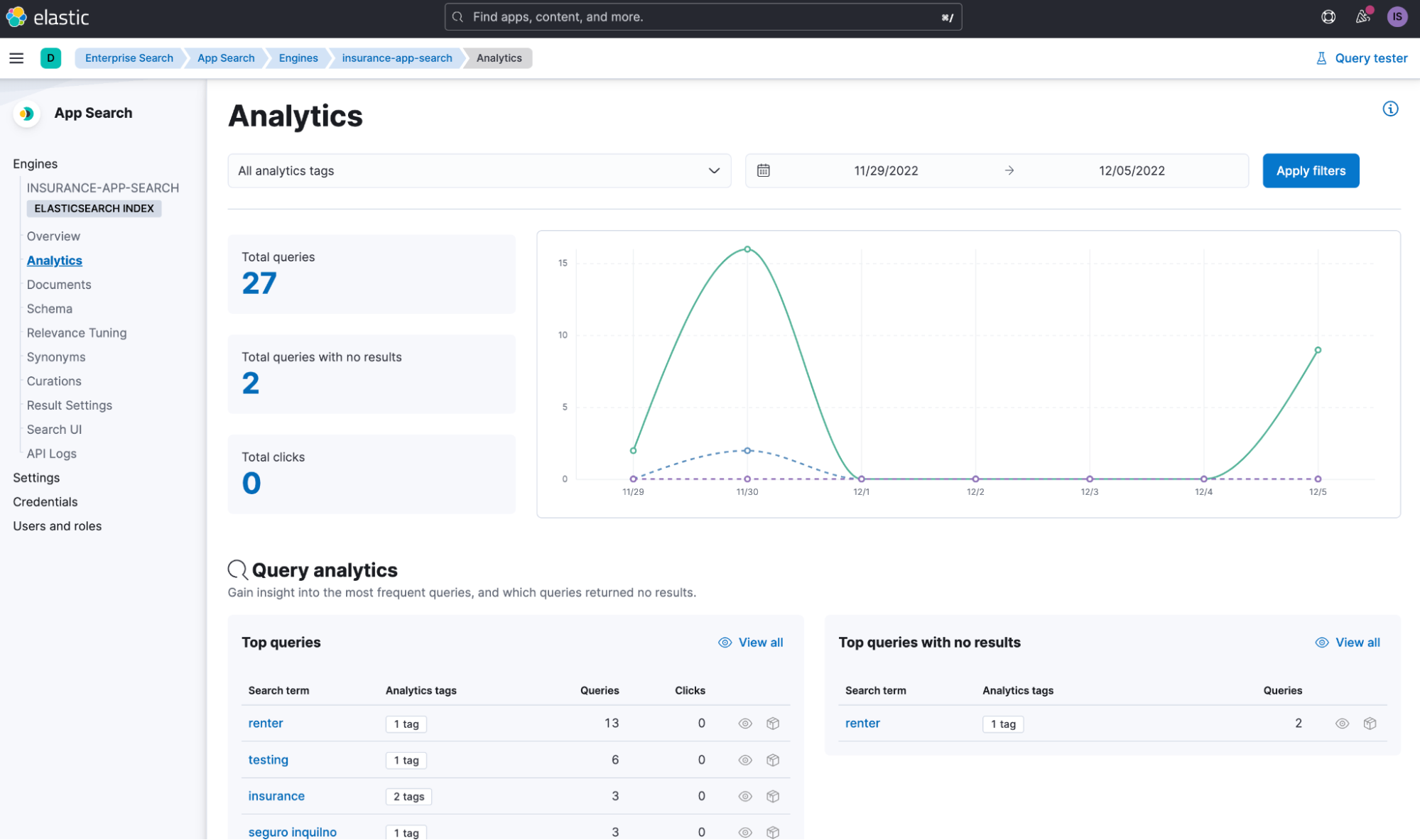
}The result? Greater insights provided by the analytics for our App Search engine and answers to questions like:
- What are users searching for?
- What are the popular search topics?
- Or… what aren’t they finding results for?
Wrapping up
Hopefully this blog post has given you some insight into how to apply NLP and user analytics to your search applications. Start a 30-day cloud trial for free with no credit card to spin up an Elastic deployment quickly (we are FedRAMP Moderate authorized on AWS GovCloud) and start exploring how you can break down barriers with the search goodies Elastic has to offer.
Source:
*Applying Deep Learning to Answer Selection: A Study and An Open Task Minwei Feng, Bing Xiang, Michael R. Glass, Lidan Wang, Bowen Zhou ASRU 2015
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print