Follow the Leader: An Introduction to Cross-Cluster Replication in Elasticsearch
The Needs of the Many
The ability to natively replicate data to an Elasticsearch cluster from another Elasticsearch cluster is our most heavily requested feature, and one that our users have long been asking for. After years of engineering effort laying the necessary foundations, building new fundamental technology into Lucene, and iterating and refining our initial design, we are excited to announce that cross-cluster replication (CCR) is now available and production-ready in Elasticsearch 6.7.0. In this post, the first in a series, we will provide some brief introduction to what we have implemented, and some technical background on CCR. In future posts we will deep-dive into specific CCR use cases.
Cross-cluster replication in Elasticsearch enables a variety of mission-critical use cases within Elasticsearch and the Elastic Stack:
- Disaster Recovery (DR) / High Availability (HA): Tolerance to withstand a datacenter or region outage is a requirement for many mission-critical applications. This requirement was previously solved in Elasticsearch with additional technologies, which added additional complexity and management overhead. Satisfying cross-datacenter DR / HA requirements can now be solved natively in Elasticsearch, utilizing CCR, with no additional technologies.
- Data Locality: Replicate data in Elasticsearch to get closer to the user or application server, reducing latencies that cost you money. For example, a product catalog or reference dataset may be replicated to twenty or more data centers around the world, to minimize the distance between the data and the application server. Another use case may be a stock trading firm with offices in London and New York. All trades in the London office are written locally and replicated to the New York office, and all trades in the New York office are written locally and replicated to London. Both offices have a global view for all trades.
- Centralized Reporting: Replicate data from a large number of smaller clusters back to a centralized reporting cluster. This is useful when it may not be efficient to query across a large network. For example, a large global bank may have 100 Elasticsearch clusters around the world, each within a different bank branch. We can use CCR to replicate events from all 100 banks around the world back to a central cluster where we can analyze and aggregate events locally.
Prior to Elasticsearch 6.7.0, these use cases could be partially addressed with third-party technologies, which is cumbersome, carries a lot of administration overhead, and has significant drawbacks. With cross-cluster replication natively integrated into Elasticsearch, we free our users of the burden and drawbacks of managing complicated solutions, can offer advantages above what existing solutions can provide (e.g., comprehensive error handling), and provide APIs within Elasticsearch and UIs in Kibana for managing and monitoring CCR.
Stay tuned for our follow-up posts to dive into each of these use-cases in greater detail.
Getting Started with Cross-Cluster Replication
Hop on over to our downloads page to obtain the latest releases of Elasticsearch and Kibana, and dive in with our getting started guide.
CCR is a platinum level feature, and is available through 30-day trial license that can be activated through the start trial API or directly from Kibana.
A Technical Introduction to Cross-Cluster Replication
CCR is designed around an active-passive index model. An index in one Elasticsearch cluster can be configured to replicate changes from an index in another Elasticsearch cluster. The index that is replicating changes is termed a “follower index” and the index being replicated from is termed the “leader index”. The follower index is passive in that it can serve read requests and searches but can not accept direct writes; only the leader index is active for direct writes. As CCR is managed at the index level, a cluster can contain both leader indices and follower indices. In this way, you can solve some active-active use cases by replicating some indices one way (e.g., from a US cluster to a European cluster), and other indices the other way (from a European cluster to a US cluster).
Replication is done at the shard level; each shard in the follower index will pull changes from its corresponding shard in the leader index, which means that a follower index has the same number of shards as its leader index. All operations are replicated by the follower, so that operations to create, update, or delete a document are replicated. Replication is done in near real-time; as soon as the global checkpoint on a shard advances an operation is eligible to be replicated by a following shard. Operations are pulled and indexed efficiently in bulk by the following shard, and multiple requests to pull changes can be in flight concurrently. These read requests can be served by the primary and its replicas, and aside from reading from the shard, do not put any additional load on the leader. This design allows CCR to scale with your production load, so that you can continue to enjoy the high-throughput indexing rates you have come to appreciate (and expect) in Elasticsearch.
CCR supports both newly-created indices and existing indices. When a follower is initially configured, it will bootstrap itself from the leader index by copying the underlying files from the leader index in a process similar to how a replica recovers from the primary. After this recovery process completes, CCR will replicate any additional operations from the leader. Mappings and settings changes are automatically replicated as-needed from the leader index.
From time to time, CCR might encounter error scenarios (e.g., a network failure). CCR is able to automatically classify these errors into recoverable errors, and fatal errors. When a recoverable error occurs, CCR enters a retry loop so that as soon as the situation that led to the failure is resolved, CCR will resume replication.
Status of replication can be monitored through a dedicated API. Via this API, you can monitor how closely the follower is tracking the leader, see detailed statistics about the performance of CCR, and track any errors that require your attention.
We have integrated CCR with the monitoring and management apps within Kibana. The monitoring UI gives you insight into CCR progress and error reporting.

Elasticsearch CCR Monitoring UI in Kibana
The management UI enables you to configure remote clusters, configure follower indices, and manage auto-follower patterns for automatic index replication.
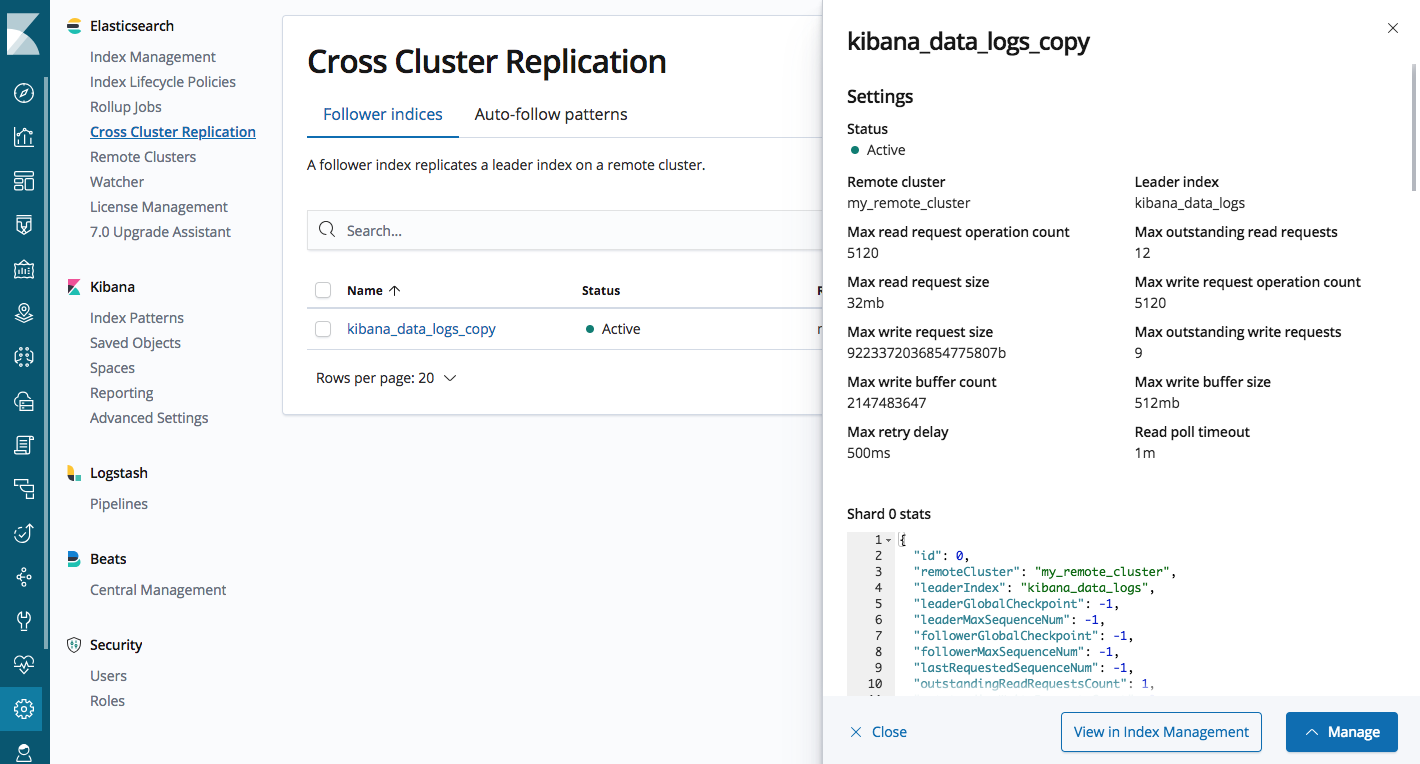
Elasticsearch CCR Management UI in Kibana
Simon Says, Follow Today’s Indices
Many of our users have workloads that create new indices on a periodic basis. For example, daily indices from log files that Filebeat is pushing or indices rolled over automatically by index lifecycle management. Rather than having to manually create follower indices to replicate these indices from a source cluster, we have built auto-follow functionality directly into CCR. This functionality allows you to configure patterns of indices to automatically be replicated from a source cluster. CCR will monitor source clusters for indices that match these patterns, and configure following indices to replicate those matching leader indices.
We have also integrated CCR and ILM so that time-based indices can be replicated by CCR, and managed in both source and target clusters by ILM. For example, ILM understands when a leader index is being replicated by CCR and so carefully manages destructive operations like shrinking and deleting indices until CCR has finished replicating.
Those Who Don’t Know History
For CCR to be able to replicate changes, we require a history of operations on the shards of the leader index, and pointers on each shard to know what operations are safe to replicate. This history of operations is governed by sequence IDs and the pointer is known as the global checkpoint. There is a complication though. When a document is updated or deleted in Lucene, Lucene marks a bit to record that the document is deleted. The document is retained on disk until a future merge operation merges the deleted documents away. If CCR replicates this operation before the delete is merged away, then all is well. Yet, merges occur on their own lifecycle, and this means that a deleted document could be merged away before CCR has had the opportunity to replicate the operation. Without some ability to control when deleted documents are merged away, CCR could miss operations and be unable to fully replicate the history of operations to the follower index. Early in the design of CCR we planned to use the Elasticsearch translog as a source for the history of these operations; this would have side-stepped the problem. We quickly realized that the translog was not designed for the access patterns that CCR needed to perform effectively. We considered putting additional data structures on top of and alongside the translog to achieve the performance that we needed, but there are limitations to this approach. For one, it would add more complexity to one of the most critical components of our system; this is simply not consistent with our engineering philosophy. Further, it would tie our hands for future changes that we intend to build on top of the history of operations where we would be forced to either limit the types of searches that can be done on the history of operations, or reimplement all of Lucene on top of the translog. With this insight, we realized that we needed to build natively into Lucene functionality that would give us control over when a deleted document is merged away, effectively pushing the history of operations into Lucene. We call this technology “soft deletes”. This investment into Lucene will pay off for years to come as not only is CCR built on it, but we are reworking our replication model on top of soft deletes, and the forthcoming changes API will be based on them too. Soft deletes are required to be enabled on leader indices.
What remains then is for a follower to be able to influence when soft deleted documents are merged away on the leader. To this end, we introduced shard history retention leases. With a shard history retention lease, a follower can mark in the history of operations on the leader where in history that follower currently is. The leader shards know that operations below that marker are safe to be merged away, but any operations above that marker must be retained for until the follower has had the opportunity to replicate them. These markers ensure that if a follower goes offline temporarily, the leader will retain operations that have not yet been replicated. Since retaining this history requires additional storage on the leader, these markers are only valid for a limited period after which the marker will expire and the leader shards will be free to merge away history. You can tune the length of this period based on how much additional storage you are willing to retain in case a follower goes offline, and how long you’re willing to accept a follower being offline before it would otherwise have to be re-bootstrapped from the leader.
Summary
We are delighted for you to try out CCR and share with us your feedback on the functionality. We hope you enjoy this functionality as much as we enjoyed building it. Stay tuned for future posts in this series where we will roll up our sleeves and explain in more detail some of the functionality in CCR and the use-cases that CCR is aimed at. And if you have any CCR questions, reach out on the Discuss forum.
The thumbnail image associated with this post is copyright by NASA, and is licensed under the CC BY-NC 2.0 license. The banner image associated with this post is copyright by Rawpixel Ltd, is licensed under the CC BY 2.0 license, and is cropped from the original