Deploying Elasticsearch on Microsoft Azure
UPDATE: This article refers to our old getting started experience for Elastic on Microsoft Azure. You can now take advantage of a more streamlined way to get started with Elastic on Microsoft Azure. Check out our latest blog to learn more.
| September 3, 2019: Elasticsearch Service on Elastic Cloud is now available on Microsoft Azure. |
I recently had the chance to present at Azure OpenDev, giving an overview of what running and using Elasticsearch and the Elastic Stack looks like today. What I'd like to do today is spend a few minutes going into more detail on some of the topics.
But first, here's the recording:
See the event website for the other talks by Microsoft, GitHub, CloudBees / Jenkins, Chef, and HashiCorp.
Azure Marketplace
As demonstrated in the talk, the easiest way to get started with Elastic on Azure is to use the official deployment template in the Azure Marketplace. You can deploy it directly from the Azure Portal and it's going to handle all of the steps required to get Elasticsearch and Kibana up and running: Provisioning instances and storage, deploying and configuring the software, setting up networking and finally bringing everything up.
We have a good blog post about how to use it.
Now, there is another way of using it besides running it from the Marketplace. Since it is open source (the sources are on Github) you can also choose to deploy it from the command line. This allows you to automate things, and to make any customizations to its workings that you might want to do. We have another good blog post about that.
If you're using the template, please drop us some feedback at azuremarketplace@elastic.co.
Hardware
Some of the most often asked questions when deploying on Azure are:
Which instances should I use?
Keep in mind this section was written in November 2017.
Elasticsearch - Data Nodes We found the DS series of memory optimized instances to be a good fit. Like every other data store Elasticsearch is very dependent on the amount of memory available to itself (as the JVM heap) and to the underlying host system (used for the important filesystem cache). You can read a bit more about how memory should be assigned in this blog post.
We also recommend using Premium Storage. Backed by Solid State Drives (SSD) it allows Elasticsearch to reach its stored data quickly - and users will benefit from improved response times. Premium Managed Disks also come with encryption at rest (via Storage Service Encryption).
Elasticsearch - Master Nodes For bigger clusters, we recommend having three dedicated master nodes. They will not be storing any data, but will handle cluster management tasks like creating new indices and rebalancing shards. Small D series instances are most often good enough.
Kibana Same as master nodes, Kibana has relatively light resource requirements. Most computations are pushed down to Elasticsearch, so you can usually run Kibana on small D series instances as well.
Logstash Since it typically does a lot of processing it is best deployed on the FS series.
Availability
Oftentimes you will want to deploy a highly available Elasticsearch cluster that stays online even in the face of instance or zone failure. Azure has several concepts that help you design redundancy into your deployment and the documentation is a good read.
Regions Azure has geographical regions around the world. Each region then contains multiple data centers very close together. You will most likely want to choose whichever region is closest to you, or closest to the users of the system. All nodes of an Elasticsearch cluster should be deployed in the same region.
Availability Sets Each tier of the Elastic Stack should be in in its own set. Two instances of Kibana should be in one, two instances of Logstash in another, and the Elasticsearch nodes in a third set.
Fault and Update Domains Azure distributes instances across fault and update domains. During a planned maintenance event, only one update domain is going to be rebooted at a time, while only the machines in the same fault domain are sharing a power source and a network switch. Distributing your instances across domains ensures the availability of instances in expected and unexpected circumstances.
Availablity Zones Azure is previewing the concept and is supporting three zones per region. Going forward, this is likely going to be the best way to deploy Elasticsearch. Each zone should have one master-eligible node (or a dedicated master node) and data nodes should be distributed across zones and tagged appropriately using Shard Allocation Awareness.
Scale Sets When using dedicated Elasticsearch master nodes (see above), using Scale Sets is a good way to scale the Elasticsearch data nodes up and down as needed.
Backup
Elasticsearch has a Snapshot Restore API to ship index files to a remote backup location. An official plugin for Azure is available, and it supports all Standard storage accounts.
Collecting Data with Beats and Logstash
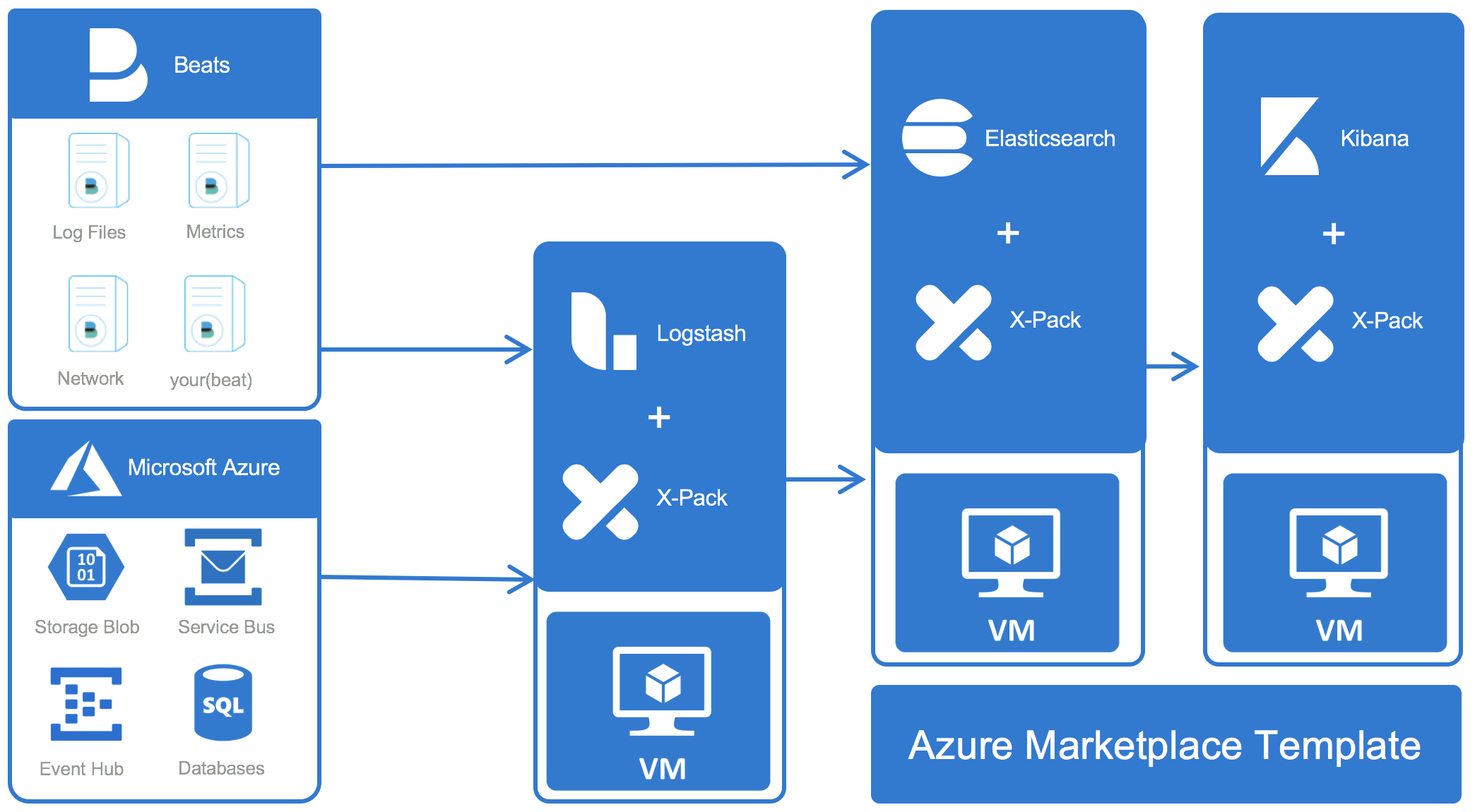
Beats
We've recently added support for enriching events collected by the Beats with Azure metadata (instance_id, instance_name, machine_type, region).
So no matter whether you use Filebeat to tail log files, Metricbeat for system metrics, the new Auditbeat for Linux audit logs, or any other of the many official and community beats - you will always know on which machine an event originated.
Logstash
In contrast to the Beats which collect data from the source, Logstash is commonly used to receive data from the Beats for further processing - or to pull data from intermediary systems. There are a number of third party input plugins available specifically for Azure:
Azure Event Hub Reads data from Event Hub partitions.
Azure Storage Blobs Given a storage account name, access key, and container name, it will read the container contents.
Azure Service Bus Topics Reads messages from a Service Bus topic.
Summary
Deploying Elasticsearch and the Elastic Stack on Azure is a great idea, and hopefully this post gives you many pointers on how to do it. Let us know how it goes!