A tutorial on building local agent using LangGraph, LLaMA3 and Elasticsearch vector store from scratch
This article will provide a detailed tutorial on implementing a local, reliable agent using LangGraph, combining concepts from Adaptive RAG, Corrective RAG, and Self-RAG papers, and integrating Langchain, Elasticsearch Vector Store, Tavily AI for web search, and LLaMA3 via Ollama.
In this tutorial we are going to see how we can create a reliable agent using LangGraph, LLaMA3 and Elasticsearch Vector Store from scratch. We will be combining ideas from 3 Advanced RAG papers:
Adaptive RAG for Routing: Which directs questions to a vector store or web search based on the content
Corrective RAG for Fallback: Using this we will introduce a Fallback retrival where if a question isn't relevant to the vector store, we will use a web-search instead.
Self RAG for Self Correction: Additonally, we will add self-correction to check generations for hallucinations and relevance, and if they're not suitable, we'll fallback to web search again.
Hence what we are aiming to build is a complex RAG flow and demonstrate its reliability and local execution on our system.
Background information
What is an LLM agent?
An LLM-powered agent can be described as a system that leverages a Large Language Model (LLM) to reason through problems, devise plans to solve them, and execute these plans using a set of tools.
In essence, these agents possess complex reasoning abilities, memory, and the means to carry out tasks.
Building agents with an LLM as the core controller is an exciting concept. Several proof-of-concept demonstrations, such as AutoGPT, GPT-Engineer, and BabyAGI, serve as inspiring examples. The potential of LLMs extends beyond generating well-written text, stories, essays, and programs; they can be framed as powerful general problem solvers.
Agent system overview
In an LLM-powered autonomous agent system, the LLM functions as the agent’s brain, complemented by several key components:
Planning
Subgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.
Reflection and refinement: The agent engages in self-criticism and self-reflection over past actions, learns from mistakes, and refines future steps, thereby improving the quality of final results.
Memory
Short-term memory: Serves as a dynamic repository of the agent's current actions and thoughts, akin to its "train of thought," as it endeavors to respond to a user's query in real-time. It allows the agent to maintain a contextual understanding of the ongoing interaction, enabling seamless and coherent communication.
Long-term memory: Acts as a comprehensive logbook, chronicling the agent's interactions with users over an extended period, spanning weeks or even months. It captures the history of conversations, preserving valuable context and insights gleaned from past exchanges. This repository of accumulated knowledge enhances the agent's ability to provide personalized and informed responses, drawing upon past experiences to enrich its interactions with users.
Hybrid memory: It combines the advantages of both STM and LTM to enhance the agent's cognitive abilities. STM ensures that the agent can quickly access and manipulate recent data, maintaining context within a conversation or task. LTM expands the agent's knowledge base by storing past interactions, learned patterns, and domain-specific information, enabling it to provide more informed responses and make better decisions over time.
Tool use
In the context of LLM (Large Language Model) agents, tools refer to external resources, services, or APIs (Application Programming Interfaces) that the agent can utilize to perform specific tasks or enhance its capabilities. These tools serve as supplementary components that extend the functionality of the LLM agent beyond its inherent language generation capabilities.
Tools could also include databases, knowledge bases, and external models.
As an illustration, agents can employ a RAG pipeline for producing contextually relevant responses, a code interpreter for addressing programming challenges, an API for conducting internet searches, or even utilize straightforward API services such as those for weather updates or instant messaging applications.
Types of LLM agents and use cases
Conversational agents: Engage users in natural language dialogues to provide information, answer questions, and assist with tasks. They utilize LLMs to generate human-like responses.
Task-oriented agents: Focus on completing specific tasks or objectives by understanding user needs and executing relevant actions. Examples include virtual assistants and automation tools.
Creative agents: Generate original content such as artwork, music, or writing. They use LLMs to understand human preferences and artistic styles, producing content that appeals to audiences.
Collaborative agents: Work with humans to achieve shared goals by facilitating communication and cooperation. LLMs help these agents assist in decision-making, report generation, and providing insights.
Approach: ReAct/Langchain agent vs LangGraph ?
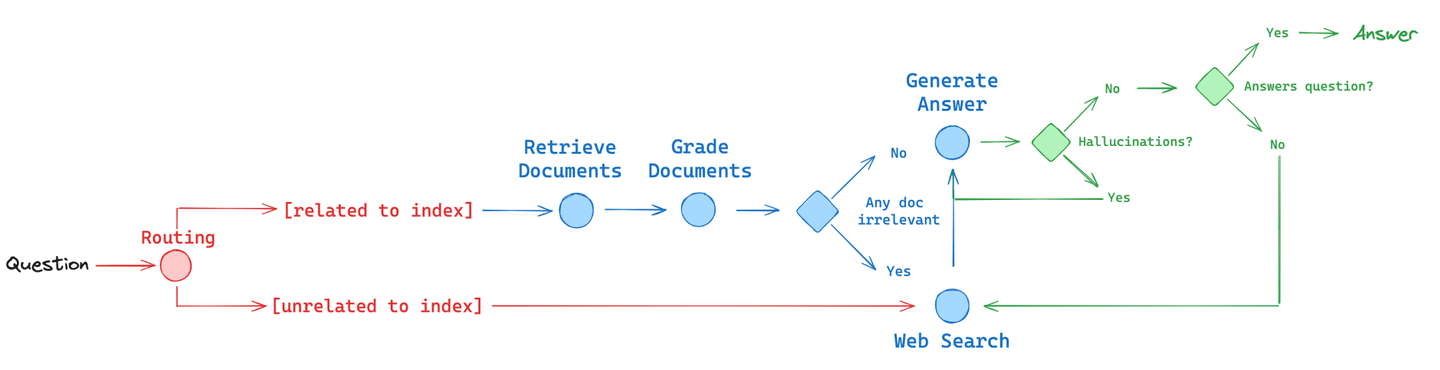
Now, let's consider using an agent to build a corrective RAG (Retrieval-Augmented Generation) system, represented by that middle blue component that can bee seen in the diagram above. When people think about agents, they often mention "ReAct"—a popular framework for building agents (not to be confused with the React.js framework). The typical flow in a ReAct agent looks like this:
The LLM (Language Learning Model) plans by selecting an action, observing the result, reflecting on it, and then choosing the next action. ReAct agents usually leverage memories, such as chat history or a vector store, and can utilize various tools. If we were to implement this flow as a ReAct agent, it would look something like this:
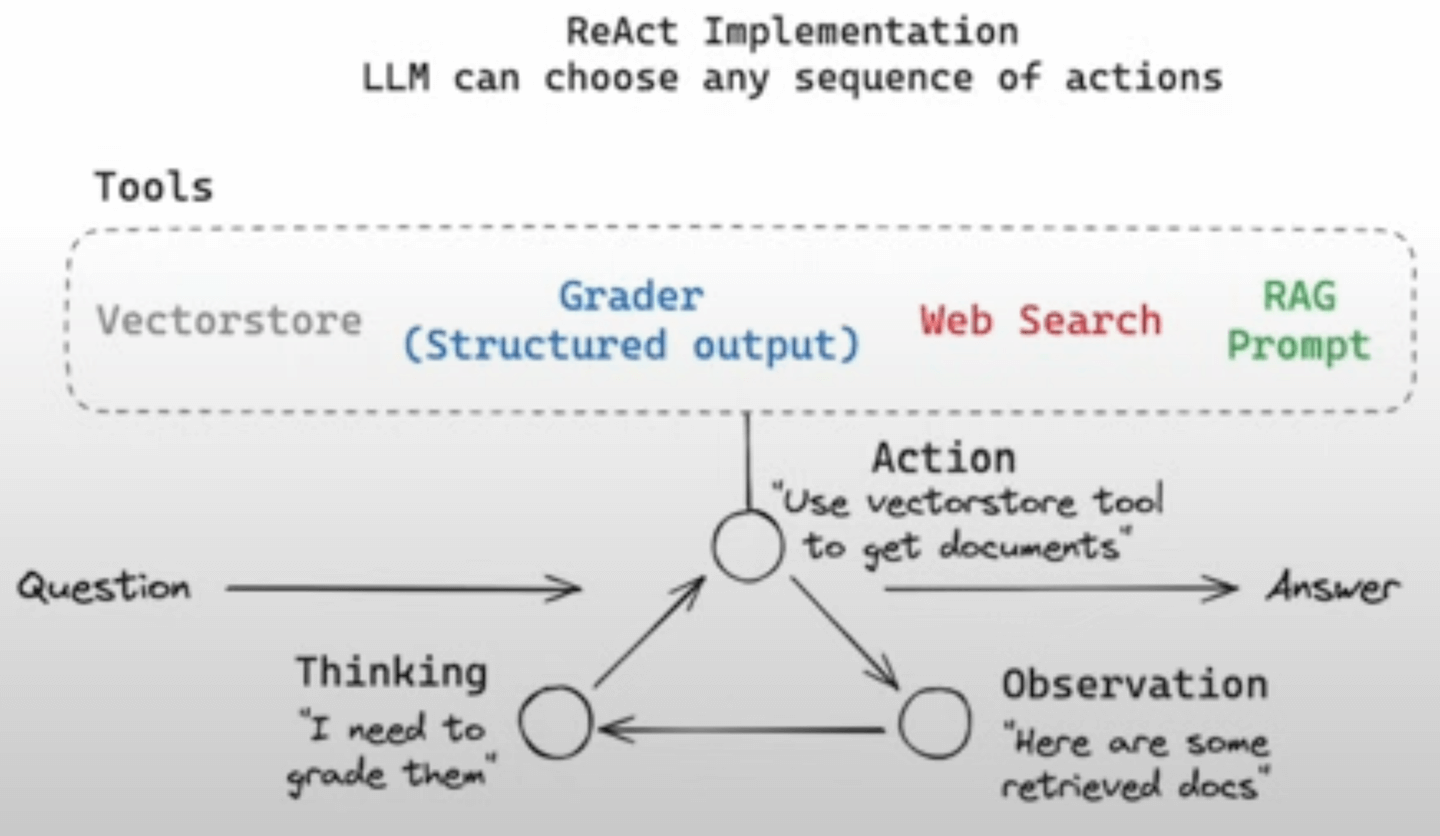
The agent would receive a question and perform an action, such as using its vector store to retrieve relevant documents.
It would then observe the retrieved documents and decide to grade them. The agent would go back to its action phase and select the grading tool.
This process would repeat in a loop, following a defined trajectory until the task is complete.
This is how ReAct-based agents typically function.
However, this approach can be quite complex and involve a lot of decision-making. Instead, we’ll use a different method to implement this system. Rather than having the agent make decisions at every step in the loop, we’ll define a "control flow" in advance. As engineers, we can lay out the exact sequence of steps we want our agent to follow each time it runs, effectively taking the planning responsibility away from the LLM. This predefined control flow allows the LLM to focus on specific tasks within each step.
In terms of memory, we can use what’s called a "graph state" to persist information across the control flow, making it relevant to the RAG process (e.g., documents and questions). For tool usage, each graph node can utilize a different tool: the Vectorstore Retrieval node (depicted in grey) will use a retriever tool, the Grade Documents node (depicted in blue) will use a grading tool, and the Web Search node (depicted in red) will use a web search tool:
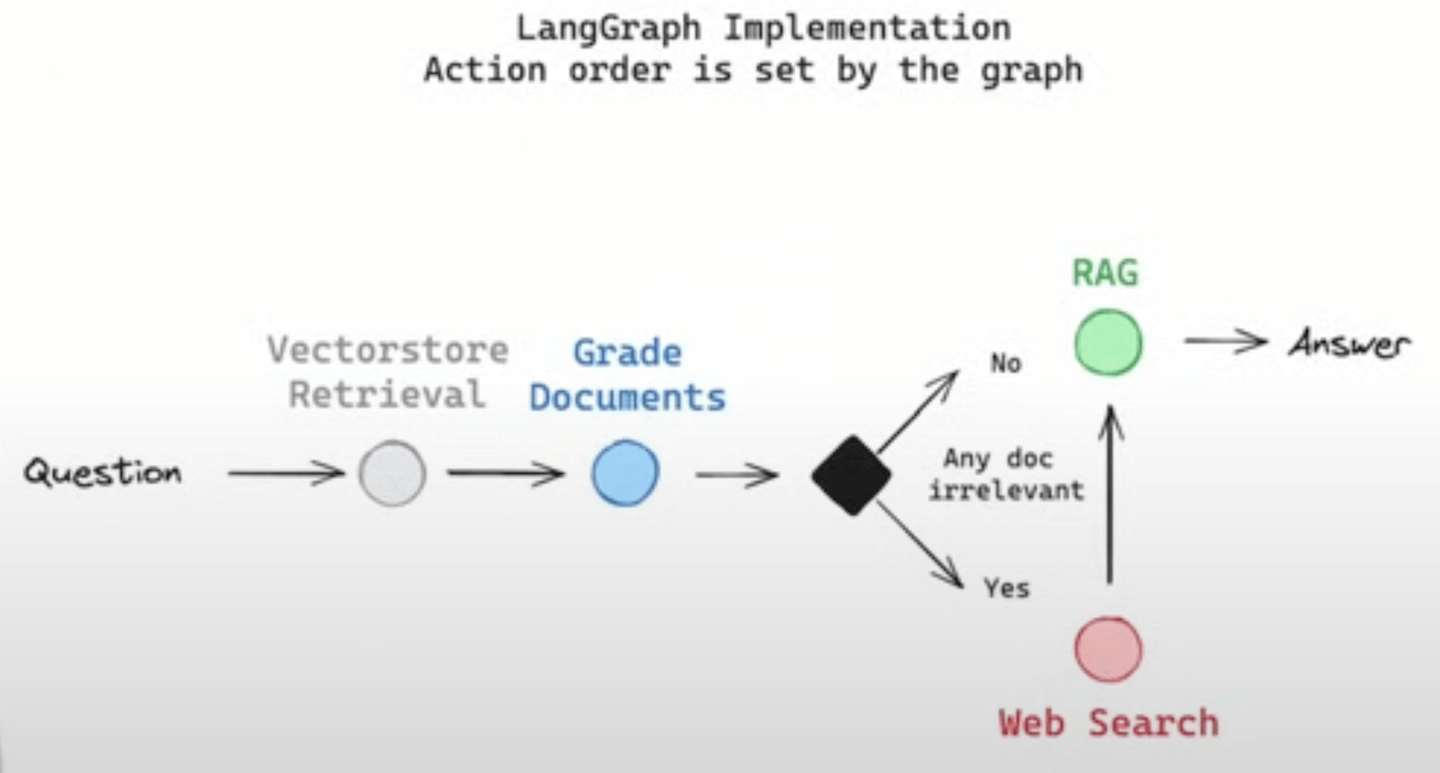
This method simplifies decision-making for the LLM, making the system more reliable, especially when using smaller LLMs.
Prerequisites
Before diving into the code, we need to set up the necessary tools:
Elasticsearch: In this tutorial, we’ll use Elasticsearch as our data store because it offers more than just a vector database for a superior search experience. Elasticsearch provides a complete vector database, multiple retrieval methods (text, sparse and dense vector, hybrid), and the flexibility to choose your machine learning model architectures. There’s a reason it’s the world’s most downloaded database! To follow along, you’ll need to deploy an Elasticsearch Cluster, which can be done in under 3 minutes as part of our 14-day free trial (no credit card required). Get started by clicking here.
Ollama: Ollama is a platform that simplifies local development with open-source large language models (LLMs). It packages everything you need to run an LLM—model weights and configurations—into a single Modelfile, similar to how Docker works for containers. You can download Ollama for your machine by clicking here. Just one small thing here to note is that the llama3 comes with a particular prompt format, that one needs to pay attention to.
After installation, verify it by running the following command:
% ollama --version
ollama version is 0.3.4Next, install the llama3 model, which will serve as our local LLM for this tutorial:
% ollama pull llama3Tavily search: Tavily's Search API is a specialized search engine designed for AI agents (LLMs), providing real-time, accurate, and factual results with impressive speed. To use this API in your tutorial, you'll need to sign up on the Tavily platform and obtain an API key. The good news is that this powerful tool is free to use. You can get started by clicking here.
Great!! So now that your environment is ready, we can move on to the fun part—writing our Python code!
Python code
1. Install required packages: To begin, install all the necessary packages by running the following command:
%pip install langchain-nomic langchain_community tiktoken langchainhub langchain-elasticsearch langchain langgraph tavily-python gpt4all langchain-text-splitters2. Set up the local LLM and the Tavily search API: After the installation is complete, set the variable local_llm to "llama3". This will define the local LLM you’ll be using in this tutorial. Feel free to change this parameter later if you want to experiment with other local LLMs on your system, and also define the Tavily Search API key obtained in the Prerequisites in your environment variable like below:
import os
os.environ["TAVILY_API_KEY"] = "xxx"
# LLM
local_llm = "llama3"1. Indexing
First we will need to load, process, and index our targetted data into our Vector Store. In this tutorial we will be indexing documents from these respective Blog posts:
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
Into our vector store, which will then add as a data source for our RAG implementation, as the index is the key component of our RAG flow without which we won't be able to retrive the documents.
# Index
from langchain_community.document_loaders import WebBaseLoader
from langchain_nomic.embeddings import NomicEmbeddings
from langchain_elasticsearch import ElasticsearchStore
from langchain_text_splitters import RecursiveCharacterTextSplitter
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)
documents=doc_splits
embeddings=NomicEmbeddings(model="nomic-embed-text-v1.5", inference_mode="local")
db = ElasticsearchStore.from_documents(
documents,
embeddings,
es_url="https://pratikrana23.es.us-central1.gcp.cloud.es.io",
es_user="elastic",
es_password="9Y9Xwz0J65gPCbJeUoSPdzHO",
index_name="rag-elastic",
)
retriever = db.as_retriever()Code description:
A list of URLs is defined, pointing to three different blog posts on Lilian Weng's website.
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]The content from each URL is loaded using
WebBaseLoader, and the result is stored in thedocslist.
docs = [WebBaseLoader(url).load() for url in urls]The loaded documents are stored as a list of lists (each containing one or more documents). These lists are flattened into a single list using a list comprehension.
docs_list = [item for sublist in docs for item in sublist]The
RecursiveCharacterTextSplitteris initialized with a specific chunk size (250 characters) and no overlap. This is used to split the documents into smaller chunks.
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=0
)
doc_splits = text_splitter.split_documents(docs_list)The split chunks are stored in the
documentsvariable.
An instance of
NomicEmbeddingsis created to generate embeddings for the document chunks. The model used is specified as"nomic-embed-text-v1.5", and inference is done locally.
embeddings=NomicEmbeddings(model="nomic-embed-text-v1.5", inference_mode="local")The documents, along with their embeddings, are stored in an Elasticsearch database. The connection details (URL, username, password) and the index name are provided.
db = ElasticsearchStore.from_documents(
documents,
embeddings,
es_url="url",
es_user="username",
es_password="password",
index_name="rag-elastic",
)Finally, a retriever object is created from the Elasticsearch database, which can be used to query and retrieve documents based on their embeddings.
retriever = db.as_retriever()2. Retrieval grader
Once we index our respective documents into the data store will need to create a grader that evaluates the relevance of our retrieved document to a given user question. Now this is where llama3 comes in, I set my local_llm to llama3 and llama has "json" mode which confirm the output from LLM is also json, so my prompt basically says grade a document and return a json with score yes/no
# Retrieval Grader
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing relevance
of a retrieved document to a user question. If the document contains keywords related to the user question,
grade it as relevant. It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n <|eot_id|><|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["question", "document"],
)
retrieval_grader = prompt | llm | JsonOutputParser()
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))Code description:
LLM initialization: The
ChatOllamamodel is instantiated with a specific configuration. The model is set to output responses in JSON format with a temperature of 0, meaning the output is deterministic (no randomness).
llm = ChatOllama(model=local_llm, format="json", temperature=0)Prompt template:
A
PromptTemplateis defined, which sets up the instructions that will be sent to the LLM. This prompt instructs the LLM to act as a grader that assesses whether a retrieved document is relevant to a user’s question.The grader’s task is simple: if the document contains keywords related to the user question, it should return a binary score (
yesorno) indicating relevance.The response is expected in a JSON format with a single key
score.
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing relevance
of a retrieved document to a user question. If the document contains keywords related to the user question,
grade it as relevant. It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n <|eot_id|><|start_header_id|>assistant<|end_header_id|>
""",
input_variables=["question", "document"],
)Retrieval grader pipeline: The
retrieval_graderis created by chaining theprompt,llm, andJsonOutputParsertogether. This forms a pipeline where the user’s question and the document are first formatted by thePromptTemplate, then processed by the LLM, and finally, the output is parsed byJsonOutputParser.
retrieval_grader = prompt | llm | JsonOutputParser()Example usage:
A sample question ("agent memory") is defined.
The
retriever.invoke(question)method is used to fetch documents related to the question.The content of the second retrieved document (
docs[1]) is extracted.The
retrieval_graderpipeline is then invoked with the question and document as inputs. The output is the JSON-formatted binary score indicating whether the document is relevant.
question = "agent memory"
docs = retriever.invoke(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))3. Generator
Moving on we need to script a code that can generate a concise answer to user's question using context from retrieved documents.
# Generate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# Prompt
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise <|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question}
Context: {context}
Answer: <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "document"],
)
llm = ChatOllama(model=local_llm, temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
question = "agent memory"
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)Code description:
prompt: This is aPromptTemplateobject that defines the structure of the prompt sent to the language model (LLM). The prompt instructs the LLM to act as an assistant for answering questions. The LLM is provided with a question and context (retrieved documents) and is instructed to generate a concise answer in three sentences or fewer. If the LLM doesn't know the answer, it is told to simply say that it doesn't know.
prompt = PromptTemplate(
template="""...""",
input_variables=["question", "context"],
)llm: This initializes the LLM using theChatOllamamodel with a temperature of 0, which ensures that the output is more deterministic and less random.
llm = ChatOllama(model=local_llm, temperature=0)format_docs(docs): This function takes a list of document objects and concatenates their content (page_content) into a single string, with each document's content separated by a double newline (\n\n). This formatted string is then used as thecontextin the prompt.
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)rag_chain: This creates a processing chain that combines theprompt, the LLM (llm), and theStrOutputParser. Thepromptis filled with thequestionandcontext, sent to the LLM for processing, and the output is parsed into a string usingStrOutputParser.
rag_chain = prompt | llm | StrOutputParser()Running the chain:
question = "agent memory"
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": format_docs(docs), "question": question})
print(generation)question: The user's question, in this case, "agent memory."docs: A list of documents retrieved using theretriever.invoke(question)function, which retrieves documents relevant to thequestion.format_docs(docs): Formats the retrieved documents into a single string of context, separated by double newlines.rag_chain.invoke({"context": format_docs(docs), "question": question}): This line executes the chain. It passes the formatted context and question into therag_chain, which processes the input through the LLM and returns the generated answer.print(generation): Outputs the generated answer to the console.
4. Hallucination grader and answer grader
This code snippet defines two separate graders—one for assessing hallucination in a generated answer and another for evaluating the usefulness of the answer in resolving a question. Both graders use a language model (LLM) to provide binary scores ("yes" or "no") based on specific criteria
# Hallucination Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template=""" <|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation. <|eot_id|><|start_header_id|>user<|end_header_id|>
Here are the facts:
\n ------- \n
{documents}
\n ------- \n
Here is the answer: {generation} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
### Answer Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are a grader assessing whether an
answer is useful to resolve a question. Give a binary score 'yes' or 'no' to indicate whether the answer is
useful to resolve a question. Provide the binary score as a JSON with a single key 'score' and no preamble or explanation.
<|eot_id|><|start_header_id|>user<|end_header_id|> Here is the answer:
\n ------- \n
{generation}
\n ------- \n
Here is the question: {question} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["generation", "question"],
)
answer_grader = prompt | llm | JsonOutputParser()
answer_grader.invoke({"question": question, "generation": generation})Hallucination grader
Code description:
LLM Initialization:
llm = ChatOllama(model=local_llm, format="json", temperature=0)llm: Initializes theChatOllamalanguage model with a JSON output format and a temperature of 0, making the model's output deterministic.
Prompt Creation:
prompt = PromptTemplate(
template="""...""",
input_variables=["generation", "documents"],
)prompt: APromptTemplateis created to define the structure of the prompt sent to the LLM. The prompt instructs the LLM to assess whether a given answer (generation) is grounded in or supported by a set of facts (documents). The model is instructed to output a binary score ("yes"or"no") in JSON format, indicating whether the answer is factual according to the provided documents.
Hallucination grader setup:
hallucination_grader = prompt | llm | JsonOutputParser()hallucination_grader: This is a pipeline combining theprompt, the LLM, and theJsonOutputParser. Thepromptis filled with the input variables (generationanddocuments), processed by the LLM, and the output is parsed into a JSON format byJsonOutputParser.
Running the hallucination grader:
hallucination_grader.invoke({"documents": docs, "generation": generation})hallucination_grader.invoke(...): Executes the hallucination grader by passing in thedocuments(facts) and thegeneration(the answer being assessed). The LLM then evaluates whether the answer is grounded in the provided facts and returns a binary score in JSON format.
Answer grader
Code description:
LLM initialization:
llm = ChatOllama(model=local_llm, format="json", temperature=0)llm: Similar to the hallucination grader, this initializes theChatOllamamodel with the same settings for deterministic output.
Prompt creation:
prompt = PromptTemplate(
template="""...""",
input_variables=["generation", "question"],
)prompt: APromptTemplateis created for evaluating the usefulness of an answer. This prompt instructs the LLM to assess whether a given answer (generation) is useful in resolving a specific question (question). Again, the LLM outputs a binary score ("yes"or"no") in JSON format, indicating whether the answer is useful.
Answer grader setup:
answer_grader = prompt | llm | JsonOutputParser()answer_grader: This pipeline combines theprompt, the LLM, and theJsonOutputParser, similar to the hallucination grader.
Running the answer grader:
answer_grader.invoke({"question": question, "generation": generation})answer_grader.invoke(...): Executes the answer grader by passing in thequestionandgeneration(the answer being evaluated). The LLM assesses whether the answer is useful in resolving the question and returns a binary score in JSON format.
5. Router
This code snippet defines a "Router" system designed to determine whether a user’s question should be directed to a vectorstore or a web search for further information retrieval. Here’s a detailed explanation of each par:
# Router
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|> You are an expert at routing a
user question to a vectorstore or web search. Use the vectorstore for questions on LLM agents,
prompt engineering, and adversarial attacks. You do not need to be stringent with the keywords
in the question related to these topics. Otherwise, use web-search. Give a binary choice 'web_search'
or 'vectorstore' based on the question. Return the a JSON with a single key 'datasource' and
no premable or explanation. Question to route: {question} <|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question"],
)
question_router = prompt | llm | JsonOutputParser()
question = "llm agent memory"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
print(question_router.invoke({"question": question}))Code description:
LLM initialization:
llm = ChatOllama(model=local_llm, format="json", temperature=0)llm: Initializes theChatOllamalanguage model with a JSON output format and a temperature of 0, ensuring deterministic (non-random) results from the model.
Prompt creation:
prompt = PromptTemplate(
template="""...""",
input_variables=["question"],
)prompt: APromptTemplateis created to define the structure of the input prompt sent to the LLM. This prompt instructs the LLM to act as an expert in routing user questions to the appropriate datasource: either a vectorstore or a web search. The decision is based on the content of the question:If the question relates to topics like "LLM agents," "prompt engineering," or "adversarial attacks," it should be routed to a vectorstore.
Otherwise, the question should be routed to a web search.
The LLM is instructed to return a binary choice: either "vectorstore" or "web_search". The response should be in JSON format with a single key "datasource".
Router setup:
question_router = prompt | llm | JsonOutputParser()question_router: This is a processing chain that combines theprompt, the LLM, and theJsonOutputParser. The prompt is populated with the question, processed by the LLM to make the routing decision, and the output is parsed into JSON format by theJsonOutputParser.
Running the Router:
question = "llm agent memory"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
print(question_router.invoke({"question": question}))question: The user's query, in this case, "llm agent memory."docs: A list of documents retrieved using theretriever.get_relevant_documents(question)function, which fetches documents relevant to the question. This part of the code appears to retrieve documents but is not directly involved in the routing decision.question_router.invoke({"question": question}): This line executes the router. The question is passed to thequestion_router, which processes it through the LLM and returns a JSON object with a key"datasource"indicating whether the question should be routed to a"vectorstore"or"web_search".print(question_router.invoke(...)): Outputs the routing decision (either"vectorstore"or"web_search") to the console.
6. Web search
The code sets up a web search tool that can be used to query the web and retrieve a limited number of search results (in this case, 3). This is useful in scenarios where you want to integrate external web search capabilities into a system, enabling it to fetch information from the internet and use that information for further processing or decision-making.
# Search
from langchain_community.tools.tavily_search import TavilySearchResults
web_search_tool = TavilySearchResults(k=3)Code description:
Imports:
from langchain_community.tools.tavily_search import TavilySearchResultsTavilySearchResults: This is a class imported from thelangchain_community.tools.tavily_searchmodule. It is used to perform web searches and retrieve search results.
Web Search Tool Initialization:
web_search_tool = TavilySearchResults(k=3)web_search_tool: This variable is an instance of theTavilySearchResultsclass. It represents a tool configured to perform web searches.k=3: This parameter specifies that the tool should return the top 3 search results for any given query. Thekvalue determines how many results are fetched and processed by the search tool.
7. Control flow
This code defines a stateful, graph-based workflow for processing user queries. It retrieves documents, generates answers, grades relevance, and routes the process based on the current state. This system is highly modular, allowing each step in the process to be independently defined and controlled, making it flexible and scalable for various use cases involving document retrieval, question answering, and ensuring the quality and relevance of generated content.
from pprint import pprint
from typing import List
import time
from langchain_core.documents import Document
from typing_extensions import TypedDict
from langgraph.graph import END, StateGraph
# State
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
web_search: whether to add search
documents: list of documents
"""
question: str
generation: str
web_search: str
documents: List[str]
# Nodes
def retrieve(state):
"""
Retrieve documents from vectorstore
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer using RAG on retrieved documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question
If any document is not relevant, we will set a flag to run web search
Args:
state (dict): The current graph state
Returns:
state (dict): Filtered out irrelevant documents and updated web_search state
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score["score"]
# Document relevant
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
# Document not relevant
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
# We do not include the document in filtered_docs
# We set a flag to indicate that we want to run web search
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def web_search(state):
"""
Web search based based on the question
Args:
state (dict): The current graph state
Returns:
state (dict): Appended web results to documents
"""
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}
# Conditional edge
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
print("---ROUTE QUESTION---")
question = state["question"]
print(question)
source = question_router.invoke({"question": question})
print(source)
print(source["datasource"])
if source["datasource"] == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "websearch"
elif source["datasource"] == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"
def decide_to_generate(state):
"""
Determines whether to generate an answer, or add web search
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
web_search = state["web_search"]
state["documents"]
if web_search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---"
)
return "websearch"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
# Conditional edge
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score["score"]
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("websearch", web_search) # web search
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generataeState definition
class GraphState(TypedDict):
question: str
generation: str
web_search: str
documents: List[str]GraphState: ATypedDictthat defines the structure of the state that the graph will manage. It includes:question: The user's query.generation: The answer generated by the LLM.web_search: A flag indicating whether a web search should be added.documents: A list of documents retrieved during the process.
Node functions
Each of the following functions represents a node in the graph, performing a specific task within the workflow.
retrieve(state)
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}Purpose: Retrieves documents from a vectorstore based on the user's question.
Returns: Updates the state with the retrieved documents.
generate(state)
def generate(state):
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}Purpose: Generates an answer using a Retrieval-Augmented Generation (RAG) model on the retrieved documents.
Returns: Updates the state with the generated answer.
grade_documents(state)
def grade_documents(state):
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke({"question": question, "document": d.page_content})
grade = score["score"]
if grade.lower() == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
web_search = "Yes"
continue
return {"documents": filtered_docs, "question": question, "web_search": web_search}Purpose: Grades the relevance of each retrieved document to the question and filters out irrelevant documents. If any document is irrelevant, it sets a flag to indicate that a web search is needed.
Returns: Updates the state with the filtered documents and the web search flag.
web_search(state)
def web_search(state):
print("---WEB SEARCH---")
question = state["question"]
documents = state["documents"]
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
if documents is not None:
documents.append(web_results)
else:
documents = [web_results]
return {"documents": documents, "question": question}Purpose: Conducts a web search based on the user's question and appends the results to the list of documents.
Returns: Updates the state with the web search results.
Conditional edges
These functions determine the next step in the workflow based on the current state.
route_question(state)
def route_question(state):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source["datasource"] == "web_search":
print("---ROUTE QUESTION TO WEB SEARCH---")
return "websearch"
elif source["datasource"] == "vectorstore":
print("---ROUTE QUESTION TO RAG---")
return "vectorstore"Purpose: Routes the question to either a web search or vectorstore retrieval based on its content.
Returns: The next node to execute, either
"websearch"or"vectorstore".
decide_to_generate(state)
def decide_to_generate(state):
print("---ASSESS GRADED DOCUMENTS---")
web_search = state["web_search"]
if web_search == "Yes":
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, INCLUDE WEB SEARCH---")
return "websearch"
else:
print("---DECISION: GENERATE---")
return "generate"Purpose: Decides whether to generate an answer or perform a web search based on the relevance of the graded documents.
Returns: The next node to execute, either
"websearch"or"generate".
grade_generation_v_documents_and_question(state)
def grade_generation_v_documents_and_question(state):
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score["score"]
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"Purpose: Grades the generated answer for hallucinations (whether it is grounded in the provided documents) and checks if the answer addresses the user's question.
Returns: The next node to execute, based on whether the answer is grounded and useful.
Workflow definition
workflow = StateGraph(GraphState)
workflow.add_node("websearch", web_search)
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)StateGraph: Initializes a graph that will manage the state transitions.add_node: Adds the nodes (functions) to the graph, associating each node with a name that can be used to call it in the workflow.
8. Build graph
This code builds the logic and flow of the stateful workflow using a state graph. It determines how the process should move from one node (operation) to the next based on the conditions and results at each step.
The workflow starts by deciding whether to retrieve documents from a vectorstore or perform a web search based on the user's question.
It then assesses the relevance of the retrieved documents, deciding whether to generate an answer or conduct further web searches if the documents aren't relevant.
Finally, it generates an answer and checks whether it is well-supported and useful, repeating steps or ending the workflow based on the outcome.
This structure ensures that the workflow is dynamic, able to adjust based on the results at each stage, and ultimately aims to produce a well-supported and relevant answer to the user's question.
# Build graph
workflow.set_conditional_entry_point(
route_question,
{
"websearch": "websearch",
"vectorstore": "retrieve",
},
)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"websearch": "websearch",
"generate": "generate",
},
)
workflow.add_edge("websearch", "generate")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "websearch",
},
)Code description:
Set the Conditional Entry Point
workflow.set_conditional_entry_point(
route_question,
{
"websearch": "websearch",
"vectorstore": "retrieve",
},
)set_conditional_entry_point: This method sets the starting point of the workflow based on a conditional decision.route_question: The function that determines whether the question should be routed to a web search or a vectorstore retrieval."websearch": "websearch": Ifroute_questiondecides that the question should be routed to a web search, the workflow starts with thewebsearchnode."vectorstore": "retrieve": Ifroute_questiondecides that the question should be routed to the vectorstore, the workflow starts with theretrievenode.
Add an Edge Between Nodes
workflow.add_edge("retrieve", "grade_documents")add_edge: This method creates a direct transition from one node to another in the workflow."retrieve" -> "grade_documents": After the documents are retrieved in theretrievenode, the workflow moves to thegrade_documentsnode, where the retrieved documents are assessed for relevance.
Add conditional edges
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"websearch": "websearch",
"generate": "generate",
},
)add_conditional_edges: This method creates conditional transitions between nodes based on the result of a decision function."grade_documents": The node where the relevance of retrieved documents is assessed.decide_to_generate: The function that decides the next step based on the relevance of the documents."websearch": "websearch": Ifdecide_to_generatedetermines that a web search is necessary (because the documents are not relevant), the workflow transitions to thewebsearchnode."generate": "generate": If the documents are relevant, the workflow transitions to thegeneratenode, where an answer is generated using the documents.
Add an edge between nodes
workflow.add_edge("websearch", "generate")"websearch" -> "generate": After performing a web search, the workflow moves to thegeneratenode to generate an answer using the results from the web search.
Add conditional edges for final decision
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "websearch",
},
)"generate": The node where an answer is generated using the documents (retrieved or from the web search).grade_generation_v_documents_and_question: The function that checks whether the generated answer is grounded in the documents and relevant to the question."not supported": "generate": If the generated answer is not well-supported by the documents, the workflow loops back to thegeneratenode to attempt generating a better answer."useful": END: If the generated answer is both grounded in the documents and addresses the question, the workflow ends (END)."not useful": "websearch": If the generated answer is grounded in the documents but does not address the question adequately, the workflow transitions back to thewebsearchnode to gather more information and try again.
All done !!
Now that our implementation is complete, let's test the graph by compiling and executing it as a whole, the good thins is this will also print out the steps as we go:
Test 1 : Lets write a question which is relevant to the Blog Posts with respect to which we created our index in the data store?
from pprint import pprint
# Compile
app = workflow.compile()
inputs = {"question": "What is agent memory?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])Test 2 : Lets write another question related to current affairs i.e completely out of context to the data that we indexed from the blog posts ?
from pprint import pprint
# Compile
app = workflow.compile()
inputs = {"question": "Who are the LA Lakers expected to draft first in the NBA draft?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: {key}:")
pprint(value["generation"])What do you see in the output of both these tests?
For Test 1
The output shows the step-by-step execution of the workflow and the decisions made at each stage:
---ROUTE QUESTION---
What is agent memory?
{'datasource': 'vectorstore'}
vectorstore
---ROUTE QUESTION TO RAG---
---RETRIEVE---
'Finished running: retrieve:'
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
'Finished running: grade_documents:'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
{'score': 'yes'}
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('Based on the provided context, Agent Memory refers to a long-term memory '
"module that records a comprehensive list of agents' experiences in natural "
'language. This allows the agent to retain and recall information over '
'extended periods, leveraging an external vector store and fast retrieval.')Routing the question:
Output:
---ROUTE QUESTION---Question:
"What is agent memory?"Decision: The workflow determines that the question should be routed to the
vectorstorebased on the question's content.Result:
{'datasource': 'vectorstore'}and---ROUTE QUESTION TO RAG---.
Retrieving documents:
Output:
---RETRIEVE---The workflow retrieves documents related to the question from the vectorstore.
Grading document relevance:
Output:
---CHECK DOCUMENT RELEVANCE TO QUESTION---The workflow grades each retrieved document to determine if it is relevant to the question.
Results: All retrieved documents are graded as relevant (
---GRADE: DOCUMENT RELEVANT---repeated four times).
Deciding to generate an answer:
Output:
---ASSESS GRADED DOCUMENTS---Since the documents are relevant, the workflow decides to proceed with generating an answer (
---DECISION: GENERATE---).
Generating the answer:
Output:
---GENERATE---The workflow generates an answer using the relevant documents.
Checking for hallucinations:
Output:
---CHECK HALLUCINATIONS---The workflow checks if the generated answer is grounded in the documents.
Result: The answer is grounded (
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---).
Grading the answer against the question:
Output:
---GRADE GENERATION vs QUESTION---The workflow evaluates whether the generated answer addresses the question.
Result: The answer is useful (
{'score': 'yes'}and---DECISION: GENERATION ADDRESSES QUESTION---).
Final output:
Output:
'Finished running: generate:'Generated answer:
'Based on the provided context, Agent Memory refers to a long-term memory '
"module that records a comprehensive list of agents' experiences in natural "
'language. This allows the agent to retain and recall information over '
'extended periods, leveraging an external vector store and fast retrieval.'For Test 2
This output follows the same workflow as the previous example but with a different question related to the NBA draft and the LA Lakers. Here's a breakdown of what happened during this run:
---ROUTE QUESTION---
Who are the LA Lakers expected to draft first in the NBA draft?
{'datasource': 'web_search'}
web_search
---ROUTE QUESTION TO WEB SEARCH---
---WEB SEARCH---
'Finished running: websearch:'
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
{'score': 'yes'}
---DECISION: GENERATION ADDRESSES QUESTION---
'Finished running: generate:'
('According to the provided context, the LA Lakers are expected to draft '
'Dalton Knecht at number 17 overall in the first round of the NBA draft.')Routing the question:
Output:
---ROUTE QUESTION---Question:
"Who are the LA Lakers expected to draft first in the NBA draft?"Decision: The workflow determines that the question should be routed to a web search (
'datasource': 'web_search'), as it likely requires up-to-date information that isn't stored in the vectorstore.Result:
web_searchand---ROUTE QUESTION TO WEB SEARCH---.
Web search:
Output:
---WEB SEARCH---The workflow performs a web search to gather the most current and relevant information regarding the Laker's draft picks.
Result:
'Finished running: websearch:'indicates that the web search step is complete.
Generating the answer:
Output:
---GENERATE---Using the information retrieved from the web search, the workflow generates an answer to the question.
Checking for hallucinations:
Output:
---CHECK HALLUCINATIONS---The workflow checks if the generated answer is grounded in the retrieved web search documents.
Result: The answer is well-supported (
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---).
Grading the answer against the question:
Output:
---GRADE GENERATION vs QUESTION---The workflow evaluates whether the generated answer directly addresses the question.
Result: The answer is useful and relevant (
{'score': 'yes'}and---DECISION: GENERATION ADDRESSES QUESTION---).
Final output:
Output:
'Finished running: generate:'Generated Answer:
'According to the provided context, the LA Lakers are expected to draft '
'Dalton Knecht at number 17 overall in the first round of the NBA draft.'Key points of the workflow for test 1 vs test 2
Routing to web search: The workflow correctly identified that the question needed current information, so it directed the query to a web search rather than a vectorstore.
Answer generation: The workflow successfully used the latest information from the web to generate a coherent and relevant response about the Lakers' expected draft pick.
Grounded and useful nswer: The workflow validated that the generated answer was both grounded in the search results and directly addressed the question.
Conclusion
In a relatively short amount of time, we've managed to build a sophisticated Retrieval-Augmented Generation (RAG) workflow that includes routing, retrieval, grading, and various decision points such as fallback to web search and dual-criteria grading of generated content. What’s particularly impressive is that this complex RAG flow, incorporating concepts from multiple research papers, can run reliably on a local machine. The key to achieving this lies in the well-defined control flow, which ensures that the local agent operates smoothly and effectively.
We encourage you to experiment with different queries and implementations, as this approach provides a powerful foundation for creating more advanced RAG agents. Hopefully, this serves as a useful guide for developing your own RAG workflows.
Frequently Asked Questions
What is an LLM Agent?
A system that leverages a Large Language Model (LLM) to reason through problems, devise plans to solve them, and execute these plans using a set of tools. In essence, these agents possess complex reasoning abilities, memory, and the means to carry out tasks.
What are the types of LLM agents?
Types of LLM agents include: conversational agents, task-oriented agents, creative agents, and collaborative agents.
Related Content


Retrieval Augmented Generation (RAG) using Cohere Command model through Amazon Bedrock and domain data in Elasticsearch