AI-scale observability at a fraction of the cost
Elastic Observability doesn't just collect data — it understands your systems, discovers what is important, and takes action. Faster and cheaper than the alternatives.
Trusted by 50% of the Fortune 500 to drive innovation
Observability that knows your system
Elastic turns your logs, metrics, and traces into a live system model that AI can reason on in real time. Available on demand from any AI interface of your choice.
One platform for everything
All signals, one source of truth — with logs as the center of investigations.
450+ one-click integrations across clouds, CI/CD, databases, and more.
The innovation behind the claims
Best-in-class efficiency
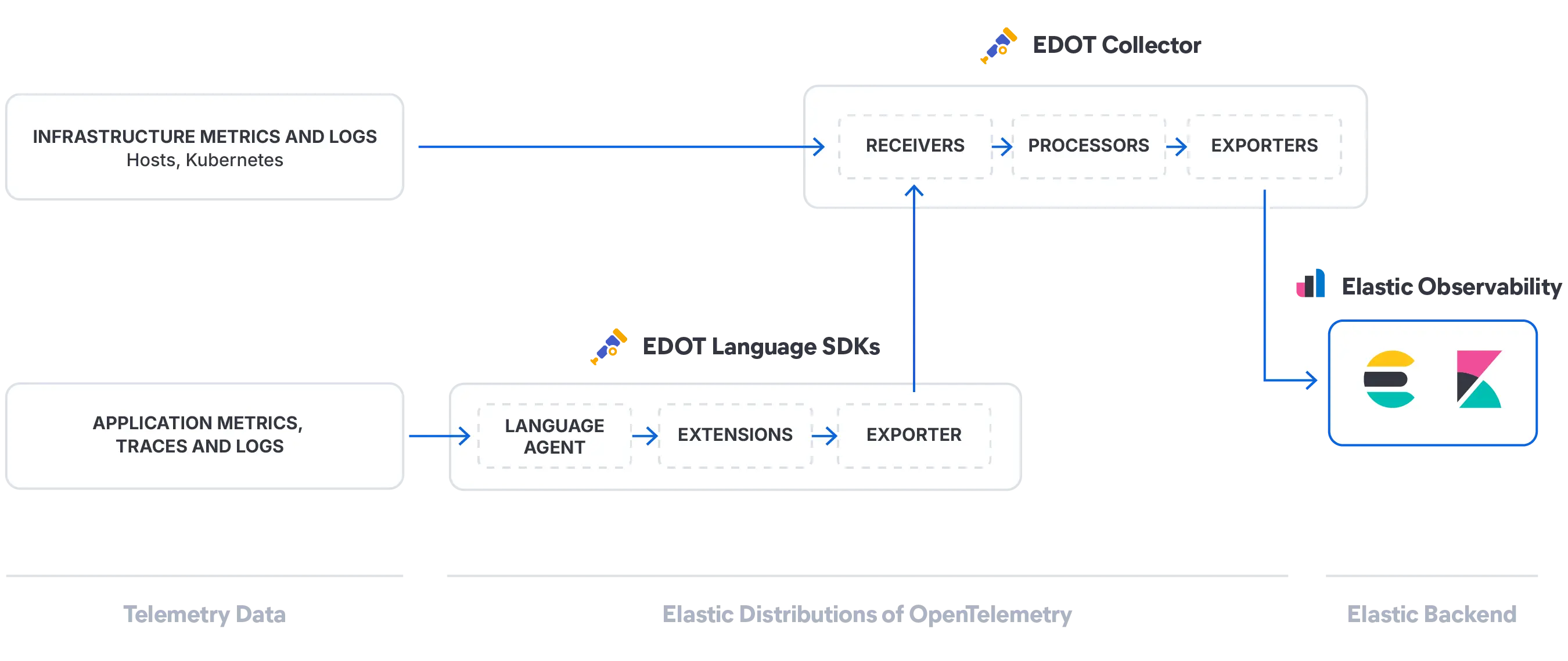
AI is only as good as the data platform powering it. From storage architecture to query performance, each piece of Elasticsearch was built with purpose.
A purpose-built index mode for log data. Smart sorting by host.name and @timestamp places similar records adjacent, dramatically improving compression. Synthetic _source reconstructs fields on demand. Read the deep dive →
long-term log retention up to 50%
smart index sorting up to 30%
Four targeted query engine optimizations have compounded across 9.x, delivering 40% better latency since January 2026.
Shipping later this year, doc-values-only mode skips inverted indices and BKD trees entirely and uses compressed binary doc-values to deliver near-columnar storage density.
Ready to switch?
Migrate from Datadog and save 50% of your metrics bill.
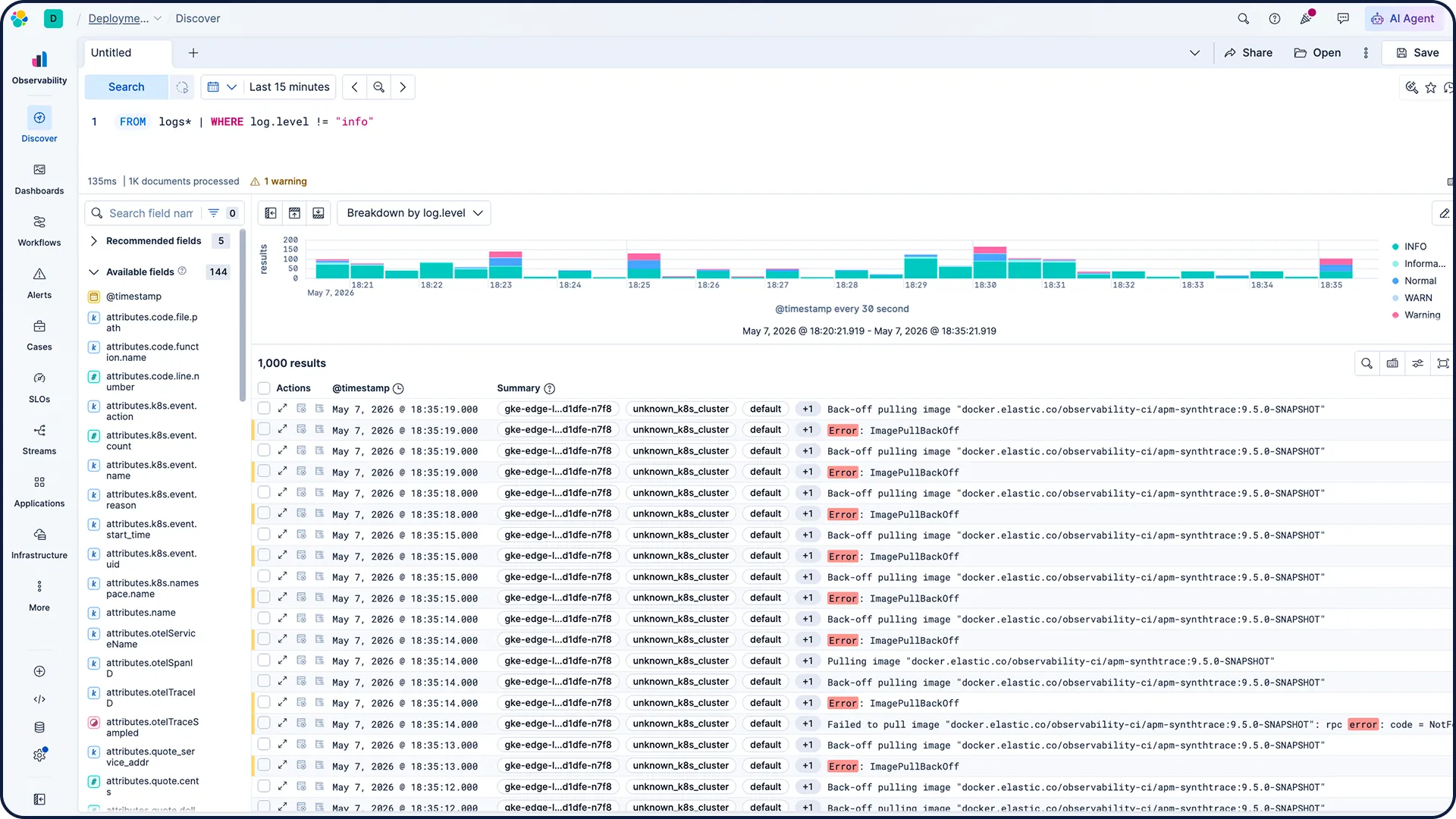
The investigation context your AI needs
Elastic automatically extracts Knowledge Indicators (KIs) from your telemetry — entities, dependencies, live state, and context — building a continuously updated model of your entire system. No configuration or tagging required.
Learn more →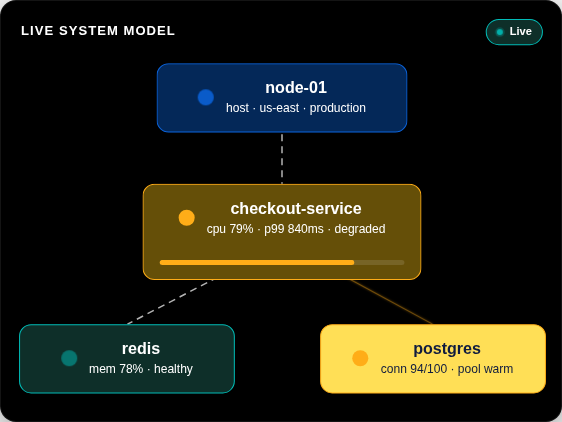
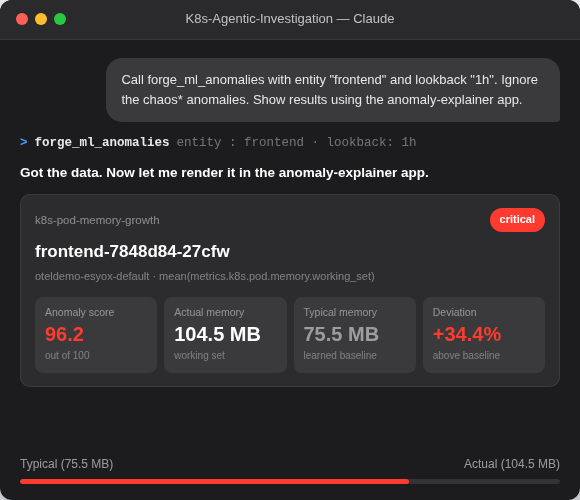
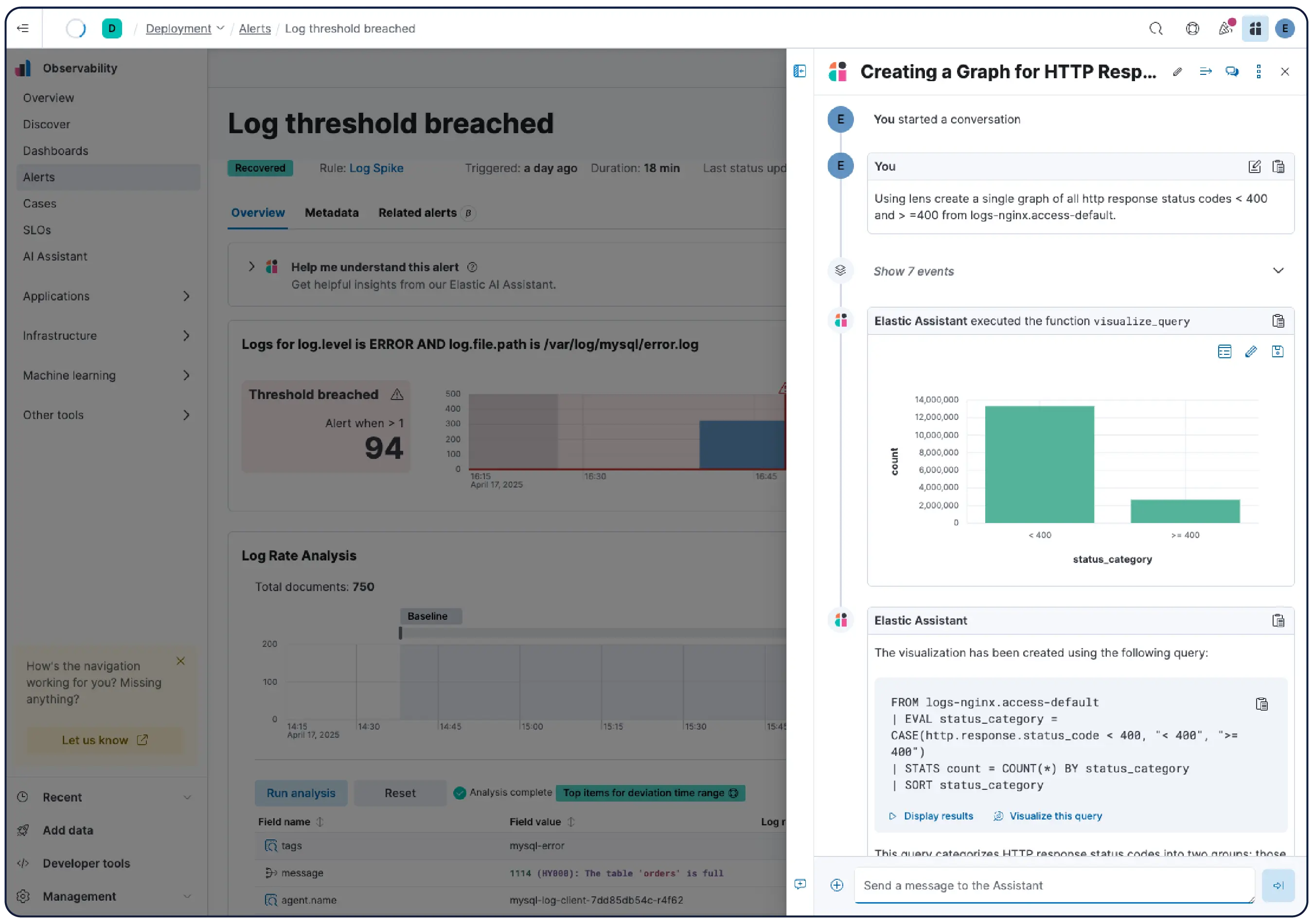
Observability everywhere you already work
The same intelligence — KIs, Significant Events, and remediations — rendered on any surface. Kibana for your SRE team. Claude for your on-call engineer. CLI for your automation pipeline.
Get the MCP server →-
 Native MCP server
Native MCP server
-
Skills loaded automatically
-
Surface-aware rendering
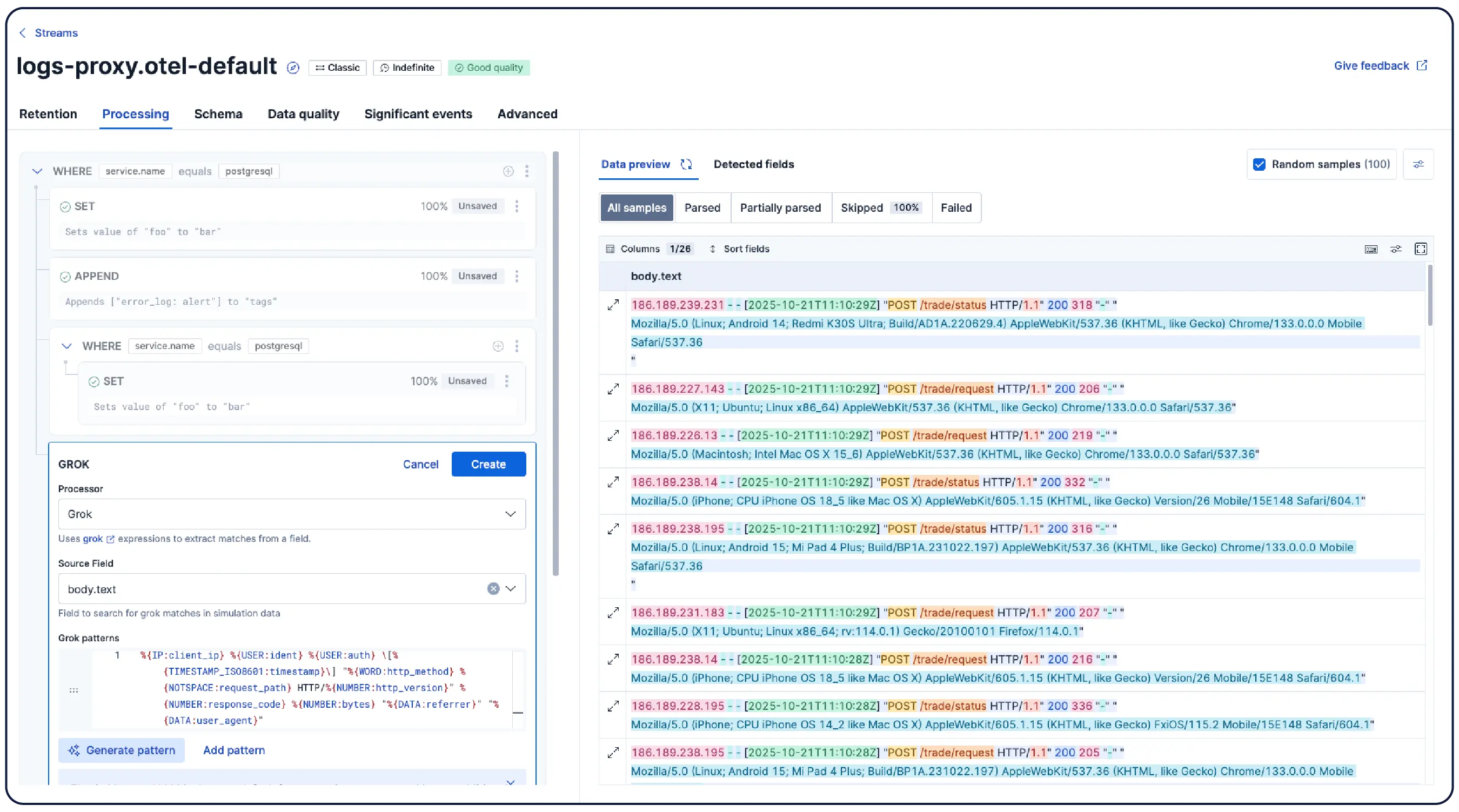
From data to answers. No digging required.
From log exploration to agentic investigations — built around how on-call SREs actually think and work.
Join the chat
Connect to Elastic's global community and participate in open conversations and collaboration.
Frequently asked questions
Full-stack observability refers to the ability of an observability solution to monitor the entire application stack — from the end user to the application code and infrastructure. A full-stack observability solution typically consists of several capabilities, including log monitoring and analytics, cloud and infrastructure monitoring, application performance monitoring, digital experience monitoring, continuous profiling, and AIOps. Take our self-assessment to understand how you stack up on your maturity journey toward a unified full-stack observability platform, so you can analyze telemetry holistically and achieve faster mean time to resolution.
Agentic observability is an approach where AI agents actively investigate incidents rather than waiting for engineers to interpret dashboards and alerts. Instead of surfacing data and leaving humans to connect the dots, AI agents reason over your telemetry in real time — identifying root cause, correlating signals across services, and recommending or executing remediation steps.
AI-driven observability enables organizations to achieve business and operational excellence. By implementing full-stack observability powered by agentic AI, SRE teams can proactively detect and resolve issues faster with contextual root cause analysis, cross-signal correlation, and effective collaboration across siloed teams. Businesses can deliver on SLAs and improve time to market, operational efficiency, and customer satisfaction. Learn more about the benefits of AI-driven observability.
Businesses everywhere are facing a challenging environment: increased cost pressures coupled with high volumes of data generated by complex, distributed, cloud-native environments. As a result, teams need smarter analytics, with data access and retention across all their data — instantly and from anywhere — in order to resolve issues, make decisions, and ensure resiliency. Many companies that have adopted Splunk Enterprise have a choice to make, since Splunk offers fragmented observability with Splunk Enterprise, Splunk Cloud, and Splunk Observability with different pricing models. By contrast, Elastic offers a fast, simple solution that positions companies for the future.
The most common reason: cost. Datadog's per-host and per-metric pricing grows quickly as infrastructure scales, and many teams find themselves making painful tradeoffs about what data to keep and what to drop. Elastic's model gives teams more control over what they store, how long they keep it, and what they pay — often resulting in savings of up to 4x.
Observability can be thought of as the evolution of monitoring for modern applications. Fundamentally, it is the ability of applications and infrastructure to expose their internal state through actionable logs, published metrics, and distributed traces. As an approach, observability is better suited than traditional monitoring to manage the complexity and scale of cloud-native environments through the collection, transformation, correlation, analysis, and visualization of these signals. Observability continues to evolve with new trends and technologies.
Leading the future of observability
See why Elastic was named a Leader in the 2025 Gartner® Magic Quadrant™ for Observability Platforms.