Elasticsearch Serviceにデータを投入する方法
Elasticsearchは、データの検索にも、分析にも使える万能選手です。開発者やコミュニティは、Elasticsearchを広範なユースケースに活用しています。アプリ検索からWebサイト検索、ロギング、インフラ監視、APM、セキュリティ分析にもElasticsearchを使っています。こうしたユースケースではゼロから構築する必要がなく、すでにあるソリューションを自在に活用できます。それでも、はじめにデータをElasticsearchに入れるプロセスが必要であることは変わりません。
本ブログ記事では、Elasticsearch Serviceにデータを投入する際の最も一般的な方法をいくつかご紹介します。本記事でご説明する方法は、マネージドのElastic Cloudと、オンプレミス版であるElastic Cloud Enterpriseのクラスターに適用することができます。ご紹介するのはマネージドのサービス向けのデータ投入手法ですが、一見すると、セルフマネージドのElasticsearchクラスターの場合とあまり大きな違いはありません。ただ1つ、クラスターを処理する方法だけが異なります。
さて、詳しい説明に入る前に、コミュニティについてもご案内します。本記事に記載された手順に関して質問や問題がおありの場合は、ぜひdiscuss.elastic.coをご活用ください。活発なコミュニティがあり、質問への回答も頻繁に行われています。
それではさっそく、次のメソッドを使用するデータ投入について説明します。
- Elastic Beats
- Logstash
- 言語クライアント
- Kibana開発ツール
Elasticsearch Serviceに投入する
Elasticsearchは、クライアントアプリと通信するためのフレキシブルでRESTfulなAPIを提供します。クラスターとそのインデックスの管理だけでなく、データの投入や、検索の実行、データ分析にもRESTコールが使用されます。つまり、Elasticsearchにデータを投入する際、上述のすべてのメソッドはこのAPIに依存します。
本記事は、Elasticsearch Serviceのクラスターを作成する段階までは完了していることを前提としています。まだ作成されていない場合は、Elastic Cloudの無料トライアルに登録してご利用ください。クラスターを作成すると、ElasticのスーパーユーザーアカウントにCloud IDとパスワードが届きます。Cloud IDはcluster_name:ZXVy...Q2Zg==のようなフォーマットになっています。そのクラスターのURLがエンコードされており、この後詳しく説明しますが、このURLを使うことでデータ投入がシンプルになります。
Elastic Beats
Beatsは軽量なデータシッパーファミリーの総称です。Beatsを使うと、Elasticsearch Serviceに手軽にデータを送ることができます。Beatsは軽量なため、デバイスに余計な負荷を与えることなく、リソースに制約のあるハードウェア(IoTデバイスやエッジデバイス、埋め込みデバイスなど)でデータを収集することができます。Beatsは、「リソースを多く消費するデータコレクターを実行したくないが、データを収集したい」という場合に最適な選択肢です。普及しつつあるこのタイプのデータ収集は、たとえばネットワーク上のデバイスで実施すると、システム全体の問題やセキュリティインシデントをすばやく検知でき、早期に問題に対応することができます。
もちろん、リソースに制約のあるシステム以外でも活躍します。多くのハードウェアリソースを利用できるシステムに使用することも可能です。
Beatsファミリーの概要
Beatsには、収集するデータの種類に応じた幅広いバリエーションがあります。
- Filebeatは、ファイル形式のソースからデータを読み取り、事前処理、送信を行います。多くのケースでFilebeatはログファイルの読み取りに使用されていますが、実はあらゆるノンバイナリファイル形式をサポートしています。FilebeatはTCP/UDP、コンテナー、Redis、Syslogを含む多数のデータソースに対応します。また多彩な各種のモジュールを併用することで、Apache、MySQL、Kafkaといった一般的なアプリのログ形式の収集とパースが簡単になります。
- Metricbeatはシステムとサービスのメトリックを収集し、事前処理を実施します。システムのメトリックには、CPUやメモリー、ディスク、ネットワークの使用状況といった値のほか、実行中のプロセスに関する情報も含まれます。各種のモジュールと併用することで、Kafka、Palo Alto Networks、Redisをはじめとする多数のサービスからデータを収集できます。
- Packetbeatはネットワーキングデータを収集し、また事前処理をします。したがって、セキュリティやネットワークパフォーマンスの分析だけでなく、アプリケーションの監視に使うことも可能です。PacketbeatはDHCP、DNS、HTTP、MongoDB、NFS、TLSのプロトコルをサポートします。
- WinlogbeatはWindowsオペレーティングシステムからイベントログを収集します。収集するイベントには、アプリイベント、ハードウェアイベント、セキュリティとシステムのイベントを含みます。Windowsイベントログから取得できる情報は、多くのユースケースで非常に価値あるデータです。
- AuditbeatはLinux Audit Frameworkで重要ファイルへの変更を検知し、イベントを収集します。各種のモジュールを活用することで、主にセキュリティ分析のユースケースのデプロイを簡易化できます。
- Heartbeatは、プロービングを使用してシステムとサービスの可用性を監視します。インフラ監視やセキュリティ分析など、多数のシナリオに役立てることができ、ICMP、TCP、HTTPの各プロトコルをサポートします。
- Functionbeatは、AWS Lambdaなどのサーバーレス環境内でログとメトリックを収集します。
ご自身のシナリオで使用するBeatsを決めたら、次のセクションの説明に沿って簡単に手順を進めることができます。
Beatsを使いはじめる
このセクションはBeatsのセットアップ方法をご紹介します。事例として、Metricbeatを使用します。他の種類のBeatsの手順も、Metricbeatの手順にかなり似ています。使用するにあたっては、各Beatのドキュメントと、ドキュメントに記載された、該当オペレーティングシステムでの使用手順もご参照ください。
- 使用するBeatをダウンロードしてインストールします。Beatsには多数のインストール手段がありますが、よく使われる方法は次の2通りです。1つは、オペレーティングシステムのパッケージマネージャー(DEB/RPM)向けにElasticが提供したレポジトリを使用する方法。もう1つは、ダウンロードしたtgz/zipパッケージを解凍する方法です。
- Beatを設定して、お好みのモジュールを有効化します。
- たとえば、システム上で稼働するDockerコンテナーについてメトリックを収集するシナリオで、パッケージマネージャーを使ってインストールを済ませている場合は、
sudo metricbeat modules enable dockerでDockerモジュールを有効化します。tgz/zipパッケージを解凍した場合は、/metricbeat modules enable dockerを使用します。 - 収集したデータを送るElasticsearch Serviceを特定するために、Cloud IDを使うことができます。とても便利な方法です。Metricbeatの設定ファイル(metricbeat.yml)にCloud IDと認証情報を追加します:
cloud.id: cluster_name:ZXVy...Q2Zg==
cloud.auth: "elastic:YOUR_PASSWORD"
- 前述の通り、
cloud.idは、クラスターの作成時に提供されています。cloud.authは、ユーザー名とパスワードをつなげて、コロンで区切ったものです。ユーザー名とパスワードは、Elasticsearchクラスターを設定するために必要な権限を持ちます。 - ここでは手早く開始するため、Elasticのスーパーユーザーと、クラスター作成時に提供されたパスワードを使用します。設定ファイルは、パッケージマネージャーを使ってインストールしている場合は
/etc/metricbeatディレクトリに、tgz/zipパッケージを解凍している場合は解凍済みディレクトリで見つけることができます。
- Kibanaでパッケージ化されたダッシュボードを読み込みます。大多数のBeatsとモジュールには、事前定義済みのKibanaダッシュボードがあります。パッケージマネージャーを使ってインストールした場合は
sudo metricbeat setupで、tgz/zipパッケージを解凍した場合は、回答済みディレクトリの./metricbeat setupで、Kibanaにダッシュボードを読み込みます。
- Beatを実行します。システムベースのLinuxシステムでパッケージマネージャーを使ってインストールした場合は
sudo systemctl start metricbeatで、tgz/zipパッケージを解凍した場合は./metricbeat -eを使用して実行します。
正常に動作していれば、以上の手順でElasticsearch Serviceにデータが流入しはじめます。
パッケージ済みダッシュボードで探索する
Elasticsearch ServiceのKibanaで、データを詳しく調べることができます。
- Kibanaの[Discover]で
metricbeat-*インデックスパターンを選択すると、投入した個々のドキュメントが表示されます。 - Kibanaの[Infrastructure]タブでは、システムのリソース使用状況(CPUやメモリー、ネットワーク)のさまざまなグラフを表示して、システムやDockerのメトリックを視覚的に確認することができます。
- Kibanaのダッシュボードで、[Metricbeat System]でプリフィクスされたダッシュボードを選び、インタラクティブにデータを探索することもできます。
Logstash
Logstashは、あらゆる種類のデータの読み取り、処理、送信を実施できるパワフルでフレキシブルなツールです。Beatsでは実施できない、あるいはコストがかさんでしまう広範な作業を、Logstashを使って行うことができます。たとえば外部データソースを参照してドキュメントをエンリッチする、といったことです。しかし、Logstashの高い機能性や柔軟性と引き換えに、デメリットとなる点もあります。また、Logstashの実行に必要となるハードウェア要件は、Beatsよりはるかに高くなります。したがって、一般的にLogstashは少リソースのデバイスにデプロイされることはありません。LogstashはBeatsの代替手段として、Beatsの機能では不十分となる特定のユースケースに使うことができます。
典型的なアーキテクチャーのパターンでは、BeatsとLogstashを組み合わせて使用します。Beatsでデータを収集し、Beatsでは実施できないデータ処理をLogstashで行う、というアーキテクチャーです。
Logstashの概要
Logstashはイベント処理パイプラインを実行することで動作します。各パイプラインは次の1つ以上の要素から構成されます。
- インプット:ソースからデータを読み取ります。各種ファイルやHTTP、IMAP、JDBC、Kafka、Syslog、TCP、UDPを含む多くのデータソースがオフィシャルにサポートされています。
- フィルター:さまざまな方法でデータを処理、およびエンリッチします。多くのケースで、構造化されていないログは、はじめにパースし、より構造化されたフォーマットに換える必要があります。そのため、Logstashは正規表現に基づいて、CSV、JSON、キー/バリューペア、非構造化区切りデータ、複雑な非構造化データをパースするフィルター(grokフィルター)を提供します。さらにLogstashはDNSルックアップを実施する、あるいはIPアドレスの地理情報を追加する、カスタムディレクトリやElasticsearchインデックスに対してルックアップを実施するといった挙動でデータをエンリッチする、各種フィルターも提供します。この他にもたとえば、データフィールドとデータ値をリネーム/削除/コピーするフィルター(mutateフィルター)など、さまざまな追加のデータ変換フィルターがあります。
- アウトプット:Logstashの処理パイプラインの最終段階で、パースおよびエンリッチしたデータをデータ受信側に書き出します。多くのアウトプットプラグインがありますが、今回はElasticsearch Serviceへの投入なので、elasticsearch outputを使用します。
Logstashサンプルパイプライン
世界に1つとして「まったく同じユースケース」は存在しません。ある要件下で特定のデータインプットを行う場合、大抵は、そのケースに合うLogstashパイプラインを開発する必要が生じます。
ここでは事例として、次のようなLogstashパイプラインを構築します。
- Elasticブログ記事のRSSフィードを読み込む
- フィールドのコピー/リネームと、特殊文字およびHTMLタグ除去という、簡単な事前処理を行う
- Elasticsearchにドキュメントを投入する
手順は次の通りです。
- パッケージマネージャーを使用するか、tgz/zipファイルをダウンロード・解凍してLogstashをインストールします。
- Logstash rss input pluginをインストールします。これでRSSデータソース:
./bin/logstash-plugin install logstash-input-rssの読み取りが可能になります。 - 次のLogstashパイプライン定義を~/elastic-rss.confなど、新しいファイルにコピーします。
input {
rss {
url => "/blog/feed"
interval => 120
}
}
filter {
mutate {
rename => [ "message", "blog_html" ]
copy => { "blog_html" => "blog_text" }
copy => { "published" => "@timestamp" }
}
mutate {
gsub => [
"blog_text", "<.*?>", "",
"blog_text", "[\n\t]", " "
]
remove_field => [ "published", "author" ]
}
}
output {
stdout {
codec => dots
}
elasticsearch {
hosts => [ "https://<your-elsaticsearch-url>" ]
index => "elastic_blog"
user => "elastic"
password => "<your-elasticsearch-password>"
}
}
- 上のファイルで、使用するElasticsearch Serviceのエンドポイントと、Elasticユーザーのパスワードに合致するよう、パラメーターホストとパスワードを修正します。Elastic Cloudでは、デプロイページの詳細情報からElasticsearchエンドポイントURLを取得できます(エンドポイントURLをコピーします)。
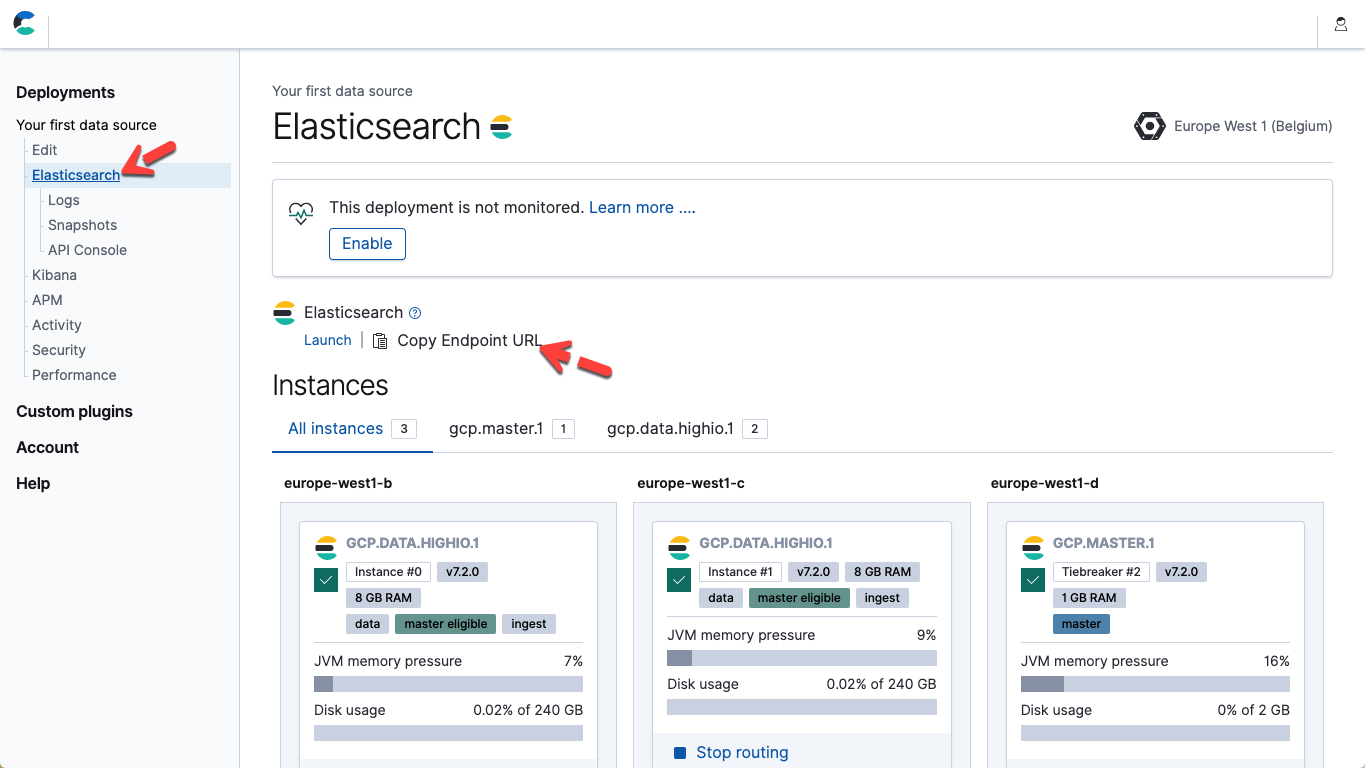
- Logstashを起動してパイプラインを実行します:./bin/logstash -f ~/elastic-rss.conf
Logstashの起動には数秒ほどかかります。その後、コンソールに、"....."(点々)の表示が現れはじめます。各点は、Elasticsearchに投入されたドキュメントを表しています。
- Kibanaを開きます。Kibanaの[開発ツールコンソール]で次のコマンドを実行し、20のドキュメントが投入されたことを確認します:POST elastic_blog/_search
クライアントプログラミング言語
時に、データ投入をカスタムアプリケーションコードに統合することが望ましい場合があります。そのような場合、Elasticではオフィシャルサポートされている各種のElasticsearchクライアントの使用を推奨しています。これらのオフィシャルクライアントでは、ライブラリがデータ投入における低レベルな詳細を除外し、アプリに固有の実体ある作業にフォーカスすることができます。現在、Java、JavaScript、Go、.NET、PHP、Perl、Python、Ruby向けのオフィシャルクライアントが存在します。詳細と、コードの記述例については各言語クライアントのドキュメントをご覧ください。アプリの記述言語が前出のリストにない場合でも、コミュニティのコントリビューションによるクライアントが存在することがあります。Kibanaの開発ツール(Dev Tool)
Kibana開発ツールコンソールは、Elasticsearchリクエストの開発とデバッグにElasticが推奨するツールです。開発ツールは、汎用のElasticsearch REST APIが持つ能力と柔軟性を損うことなく、背後のHTTPリクエストに伴う専門的な作業を除外します。開発ツールコンソールを使用して、生のJSONドキュメントをElasticsearchに送ることができます。PUT my_first_index/_doc/1
{
"title" :"How to Ingest Into Elasticsearch Service",
"date" :"2019-08-15T14:12:12",
"description" :"This is an overview article about the various ways to ingest into Elasticsearch Service"
}