Observabilité à l'échelle de l'IA pour une fraction du coût
Elastic Observability ne se contente pas de collecter des données : il comprend vos systèmes, découvre ce qui est important et prend des mesures. Plus rapide et moins cher que les alternatives.
50 % des entreprises classées au Fortune 500 lui font confiance pour stimuler l'innovation
Observability that knows your system
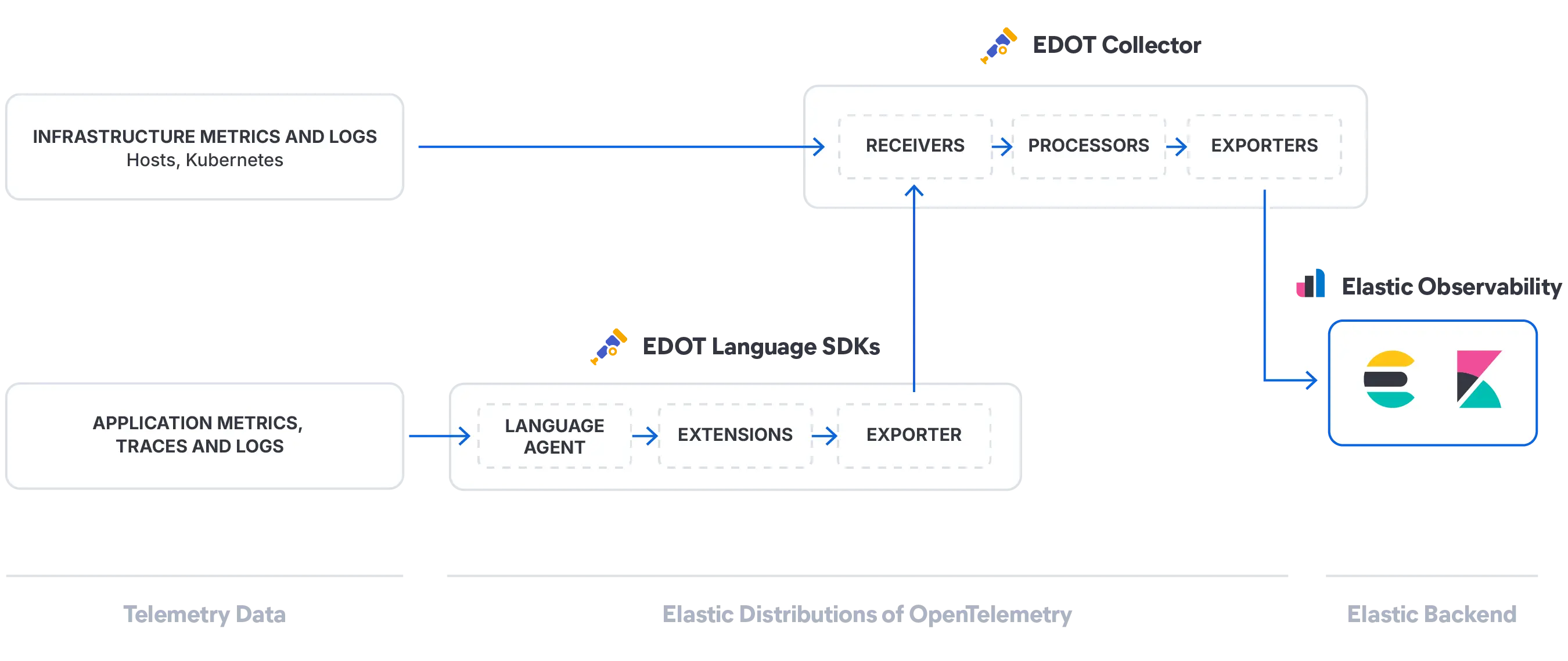
Elastic transforme vos logs, métriques et traces en un modèle de système en direct sur lequel l'IA peut raisonner en temps réel. Disponible à la demande depuis l'interface IA de votre choix.
Une seule et même plateforme pour tout
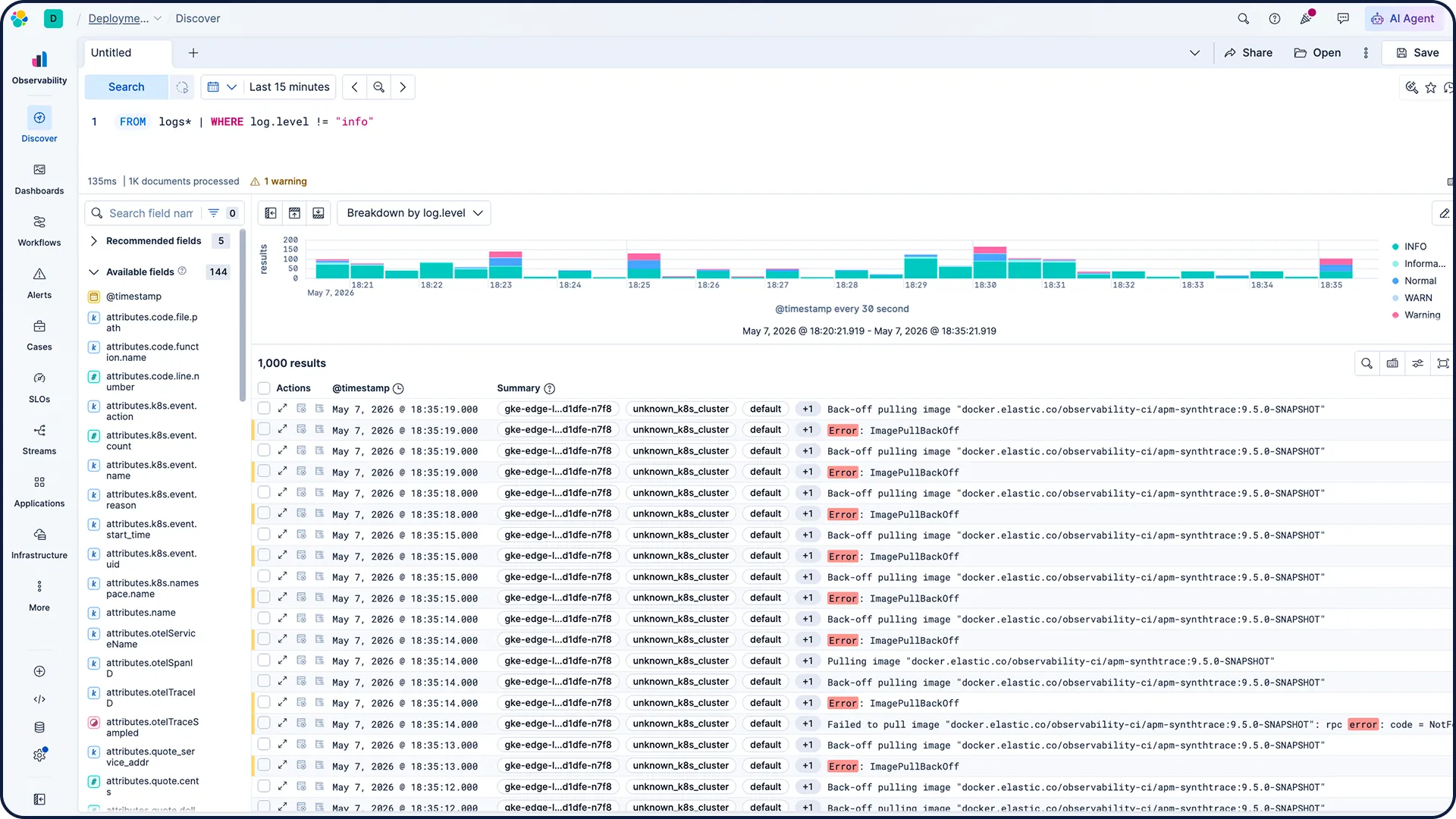
Tous les signaux, une seule source de référence — avec les logs au centre des investigations.
Plus de 450 intégrations en un clic dans les clouds, le CI/CD, les bases de données et bien plus.
L'innovation derrière les allégations
Efficacité hors pair
La qualité de l'IA dépend de la plateforme de données qui la soutient. De l'architecture de stockage aux performances des requêtes, chaque élément d'Elasticsearch a été conçu dans un but précis.
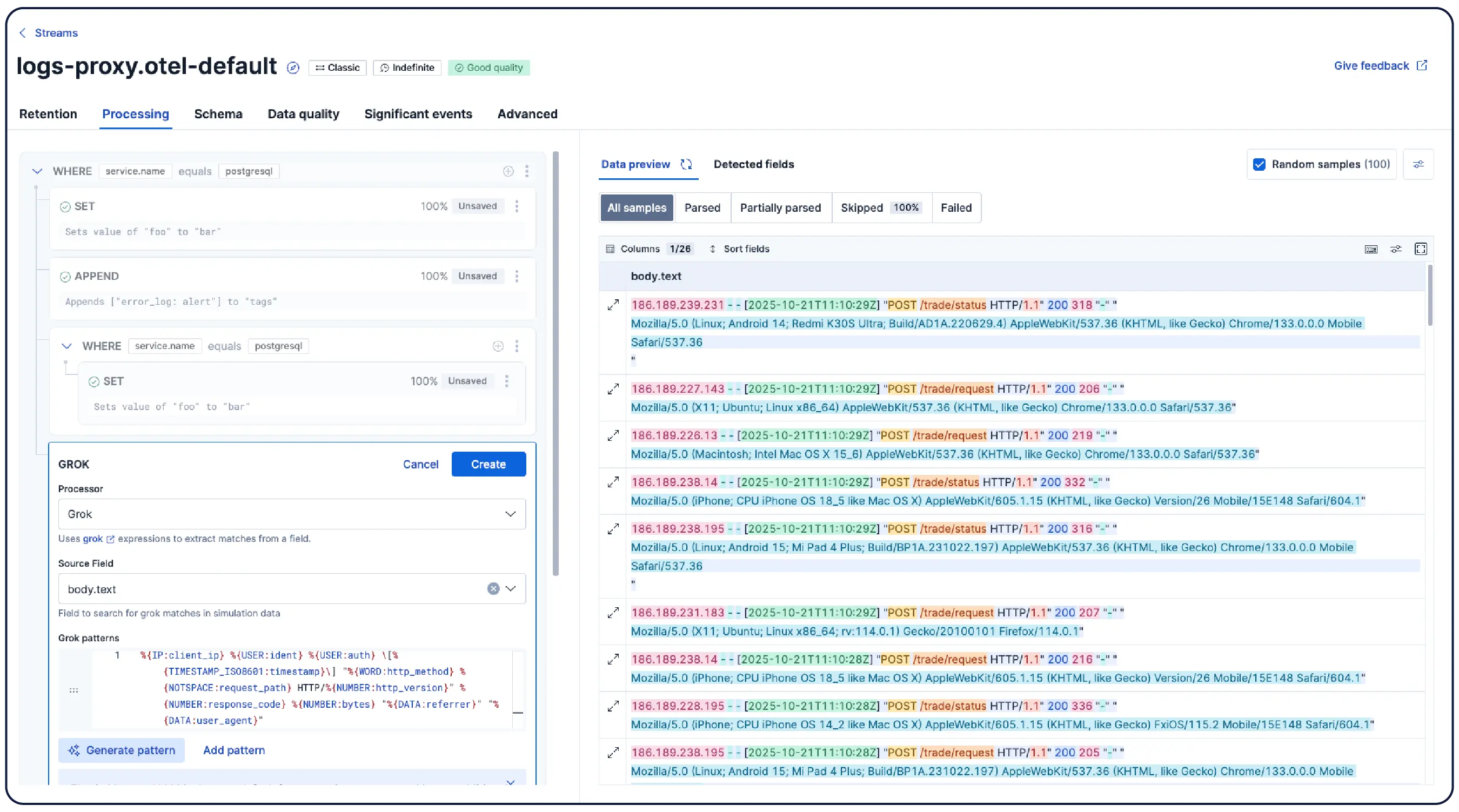
Un mode d'indexation spécialement conçu pour les données de log. Un tri intelligent par host.name et @timestamp place des enregistrements similaires à côté, améliorant considérablement la compression. Synthetic _source reconstruit les champs à la demande. Consulter les détails →
Rétention des logs à long terme jusqu'à 50 %
tri d'index intelligent jusqu'à 30 %
Quatre optimisations ciblées pour les moteurs de requêtes ont été intégrées à la version 9.x, offrant une latence réduite de 40 % depuis janvier 2026.
Disponible plus tard cette année, le mode valeurs doc uniquement ignore entièrement les index inversés et les arbres BKD et utilise des valeurs doc binaires compressées pour offrir une densité de stockage quasi-colonnaire.
Prêt à sauter le pas ?
Migrez depuis Datadog et économisez 50 % sur votre facture de métriques.
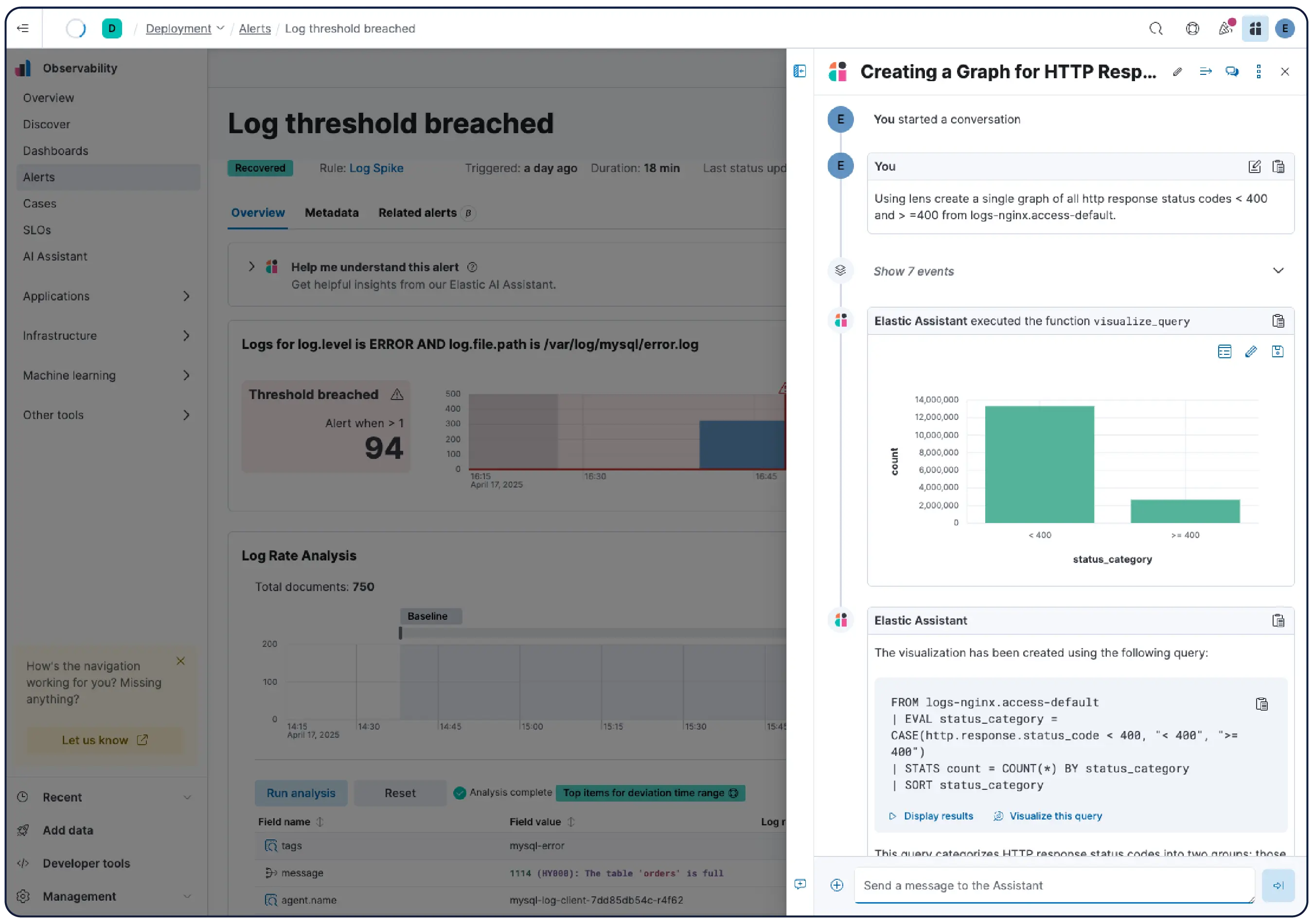
Le contexte d'investigation dont votre IA a besoin
Elastic extrait automatiquement les indicateurs de connaissances (KI) de votre télémétrie – entités, dépendances, état réel et contexte – pour créer un modèle mis à jour en continu de l'ensemble de votre système. Aucune configuration ni étiquetage nécessaire.
En savoir plus →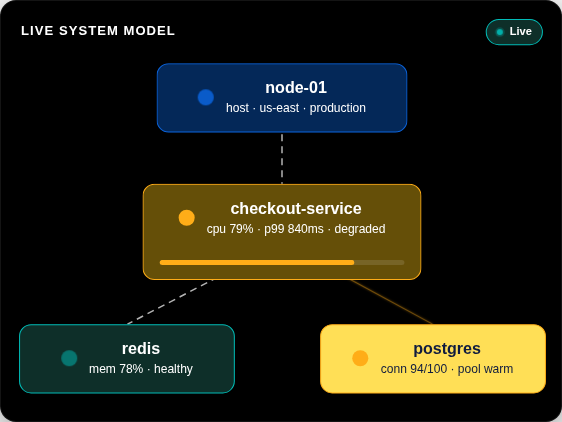
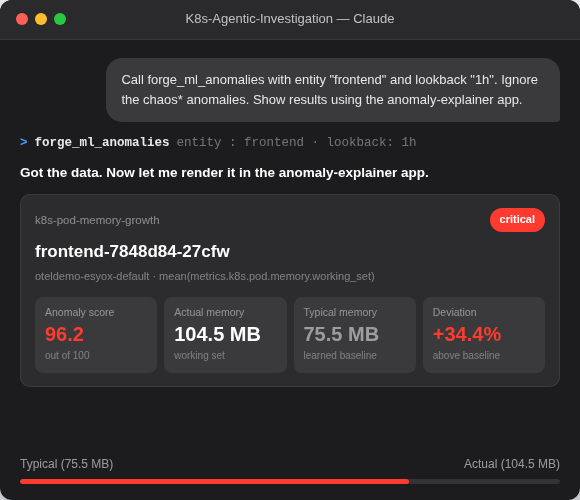
L’observabilité partout où vous travaillez déjà
Les mêmes renseignements (indicateurs de sécurité, événements importants et mesures correctives) sont fournis sur n'importe quelle surface. Kibana pour votre équipe SRE. Claude pour votre ingénieur de permanence. CLI pour votre pipeline d'automatisation.
Accéder au serveur MCP →-
 Serveur MCP natif
Serveur MCP natif
-
Les compétences se chargent automatiquement
-
Rendu sensible à la surface
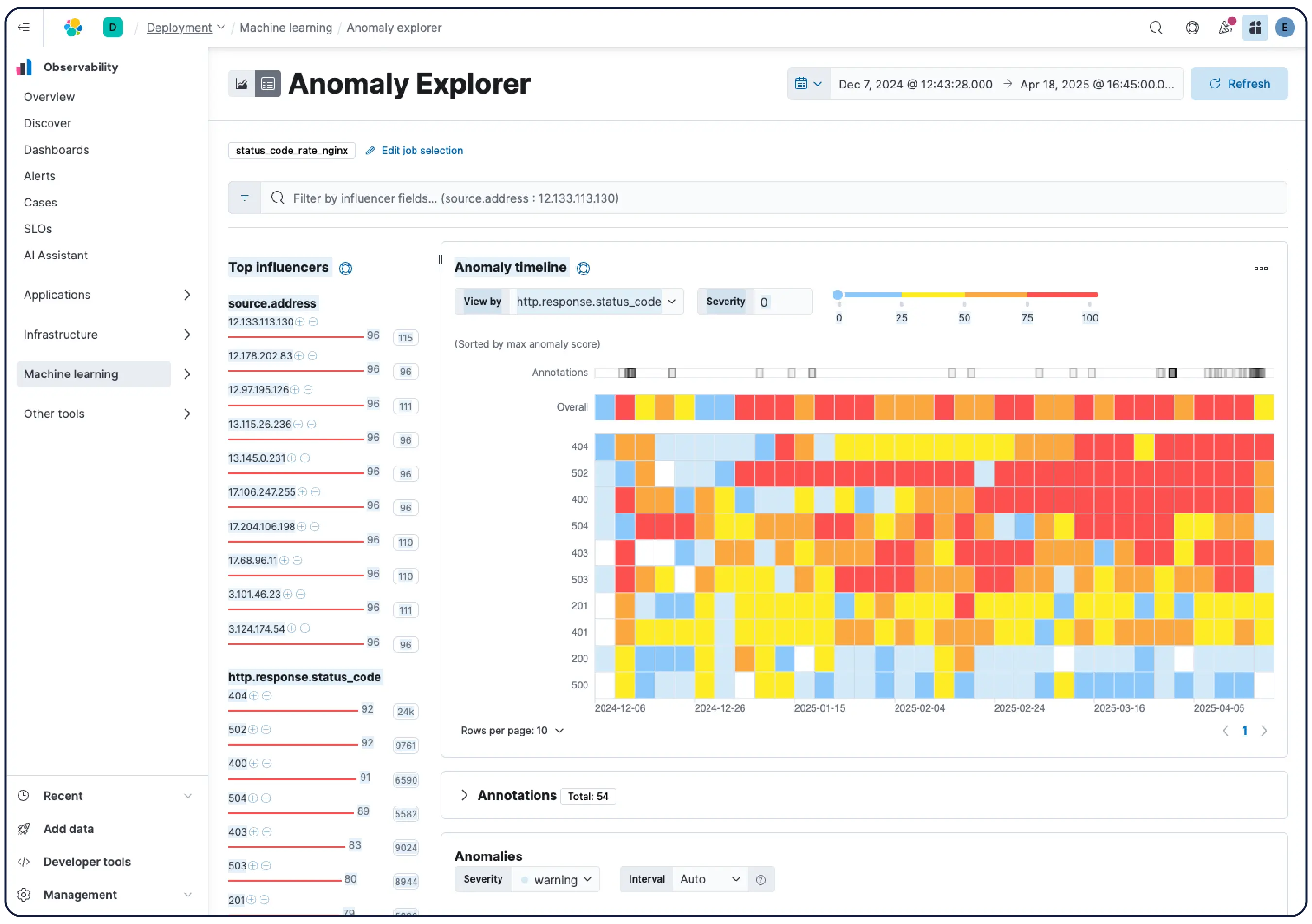
Des données aux réponses. Sans autre recherche.
De l'exploration des logs aux investigations agentiques, construit autour de la façon dont les SRE de permanence pensent et travaillent réellement.
Rejoignez la discussion
Connectez-vous à la communauté mondiale d'Elastic et participez à des conversations ouvertes et à la collaboration.
Discussion
Posez des questions, obtenez des réponses et faites-vous entendre sur notre forum ouvert.
Publier sur notre forum →Slack
Parlez technique. Échangez des notes. Façonnez l'avenir d'Elastic Observability.
Rejoignez notre Slack →Rencontre
Découvrez Elastic. Apprenez, explorez et entrez en contact avec vos pairs.
Participez à un meetup →Questions fréquentes
L'observabilité full-stack désigne la capacité d'une solution d'observabilité à monitorer l'intégralité d'une suite d'applications, depuis l'utilisateur final jusqu'au code et jusqu'à l'infrastructure des applications. Une solution d'observabilité full-stack se compose généralement de plusieurs fonctionnalités, parmi lesquelles le monitoring et l'analyse des logs, le monitoring du cloud et de l'infrastructure, le suivi des performances applicatives, le monitoring de l'expérience numérique, le profilage continu et l'AIOps. Faites notre autoévaluation pour découvrir où vous vous situez sur votre parcours de maturité vers une plateforme d'observabilité unifiée full-stack, afin d'analyser la télémétrie de manière holistique et d'accélérer le temps moyen de résolution.
L'observabilité agentique est une approche dans laquelle des agents IA enquêtent activement sur les incidents plutôt que d'attendre que les ingénieurs interprètent les tableaux de bord et les alertes. Au lieu de simplement présenter des données en laissant aux humains le soin d'établir les liens, les agents IA raisonnent sur votre télémétrie en temps réel : ils identifient la cause première, mettent en corrélation les signaux entre les services et recommandent ou exécutent des mesures de correction.
L'observabilité pilotée par l'IA permet aux entreprises d'atteindre l'excellence commerciale et opérationnelle. En mettant en œuvre une observabilité full-stack alimentée par une IA agentique, les équipes SRE peuvent détecter et résoudre les problèmes plus rapidement grâce à une analyse contextuelle des causes premières, une corrélation entre les signaux et une collaboration efficace entre des équipes cloisonnées. Les entreprises peuvent ainsi respecter leurs engagements de niveau de service (SLA) tout en améliorant les délais de mise sur le marché, l'efficacité opérationnelle et la satisfaction client. Découvrez les avantages de l'observabilité pilotée par l'IA.
Les entreprises du monde entier évoluent dans un milieu difficile où des pressions accrues s'exercent sur les prix tandis que d'importants volumes de données sont générés par des environnements cloud-native distribués complexes. Par conséquent, les équipes ont besoin de fonctionnalités plus intelligentes d'analyse, d'accès et de conservation pour l'ensemble de leurs données, qui sont accessibles instantanément et partout, afin de résoudre les problèmes, de prendre des décisions et de garantir la résilience. De nombreuses d'entreprises qui ont adopté Splunk Enterprise doivent aujourd'hui prendre une décision. En effet, Splunk propose une solution d'observabilité fragmentée avec Splunk Enterprise, Splunk Cloud et Splunk Observability, qui ont des modèles de tarification différents. A contrario, Elastic offre une solution rapide et simple qui aide les entreprises à se préparer pour l'avenir.
La raison la plus fréquente est le coût. La tarification de Datadog, basée sur le nombre d'hôtes et de métriques, augmente rapidement à mesure que l'infrastructure se développe ; de nombreuses équipes se retrouvent alors contraintes à mener des arbitrages difficiles quant aux données à conserver ou à abandonner. Le modèle d'Elastic offre aux équipes une plus grande maîtrise de ce qu'elles stockent, de la durée de conservation et des coûts associés, permettant souvent de réaliser jusqu'à quatre fois plus d'économies.
On peut considérer l'observabilité comme une évolution du monitoring pour les applications modernes. Par essence, il s'agit de la capacité des applications et de l'infrastructure à brosser une vue d'ensemble de leur état interne au moyen de logs exploitables, d'indicateurs publiés et de traces distribuées. L'observabilité présente une approche plus adaptée que le monitoring traditionnel pour gérer la complexité et l'envergure des environnements cloud-native grâce à la collecte, la transformation, la mise en corrélation, l'analyse et la visualisation de ces signaux. L'observabilité continue d'évoluer avec les nouvelles tendances et les nouvelles technologies.
L'avenir de l'observabilité
Découvrez pourquoi Elastic a été nommé Leader dans le Magic Quadrant™ 2025 de Gartner® pour les plateformes d'observabilité.