Surveillance des infrastructures conçues pour une efficacité à haute cardinalité à grande échelle
Elastic vous offre une observabilité complète de votre infrastructure, identifie les anomalies, enquête sur les causes profondes et automatise la remédiation — le tout alimenté par l’IA — pour que vous puissiez planifier la capacité et résoudre les problèmes plus rapidement. Le stockage en colonnes maintient des performances élevées et des coûts bas.

Blog
Une solution d'observabilité des infrastructures deux fois moins chère que Datadog


Une technologie d'IA intégrée à tous les outils que vous utilisez déjà au quotidien
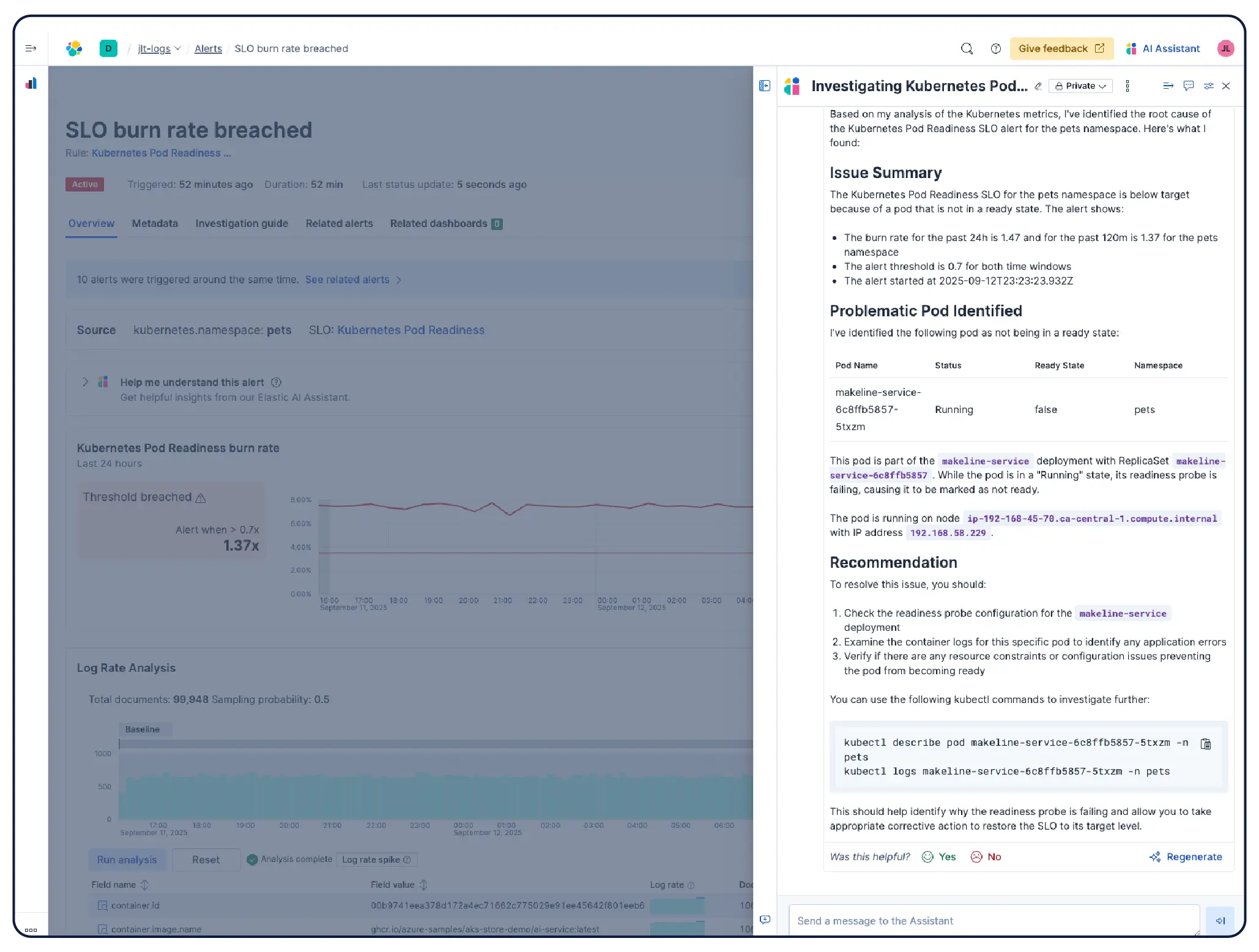
Profitez d'un environnement opérationnel dès votre connexion. La solution de monitoring Kubernetes d'Elastic est prête à l'emploi avec des tableaux de bord, alertes, objectifs de niveau de service (SLO) et tâches de Machine Learning préconfigurés. Elle inclut également des compétences d'agent et une application MCP pour surveiller l'état de vos systèmes, détecter les anomalies, enquêter sur les incidents et accélérer leur résolution.

Efficacité hors pair
Bénéficiez d'une visibilité complète de votre infrastructure et d'une analyse détaillée des log sans compromettre les performances ni perdre de données. Le moteur de métriques en colonnes d'Elasticsearch surpasse les autres solutions en termes de vitesse d'ingestion, de stockage et d'interrogation, quelle que soit la scaler.
Découvrez comment nous avons reconstruit Elasticsearch pour en faire un datastore de métriques en colonnes de premier plan. Voir les benchmarks.
COMPATIBLE AVEC TOUS LES SCHÉMAS
Un seul datastore, tous les formats, pas de changement de contexte
La plupart des piles de surveillance d’infrastructure normalisent tout, en un seul schéma, ou vous obligent à naviguer entre plusieurs systèmes back-end et langages de requête. Nous ne le faisons pas. Que vous nous transmettiez des données au format OpenTelemetry, Prometheus, Beats, ou tout autre format, Elasticsearch stocke chacune d'entre elles de manière native dans un datastore unifié et les interroge telles quelles. Pas de couche de traduction, pas de perte d'informations, pas d'enquêtes en mode 'swivel-chair'.
Mettez votre infrastructure au premier plan
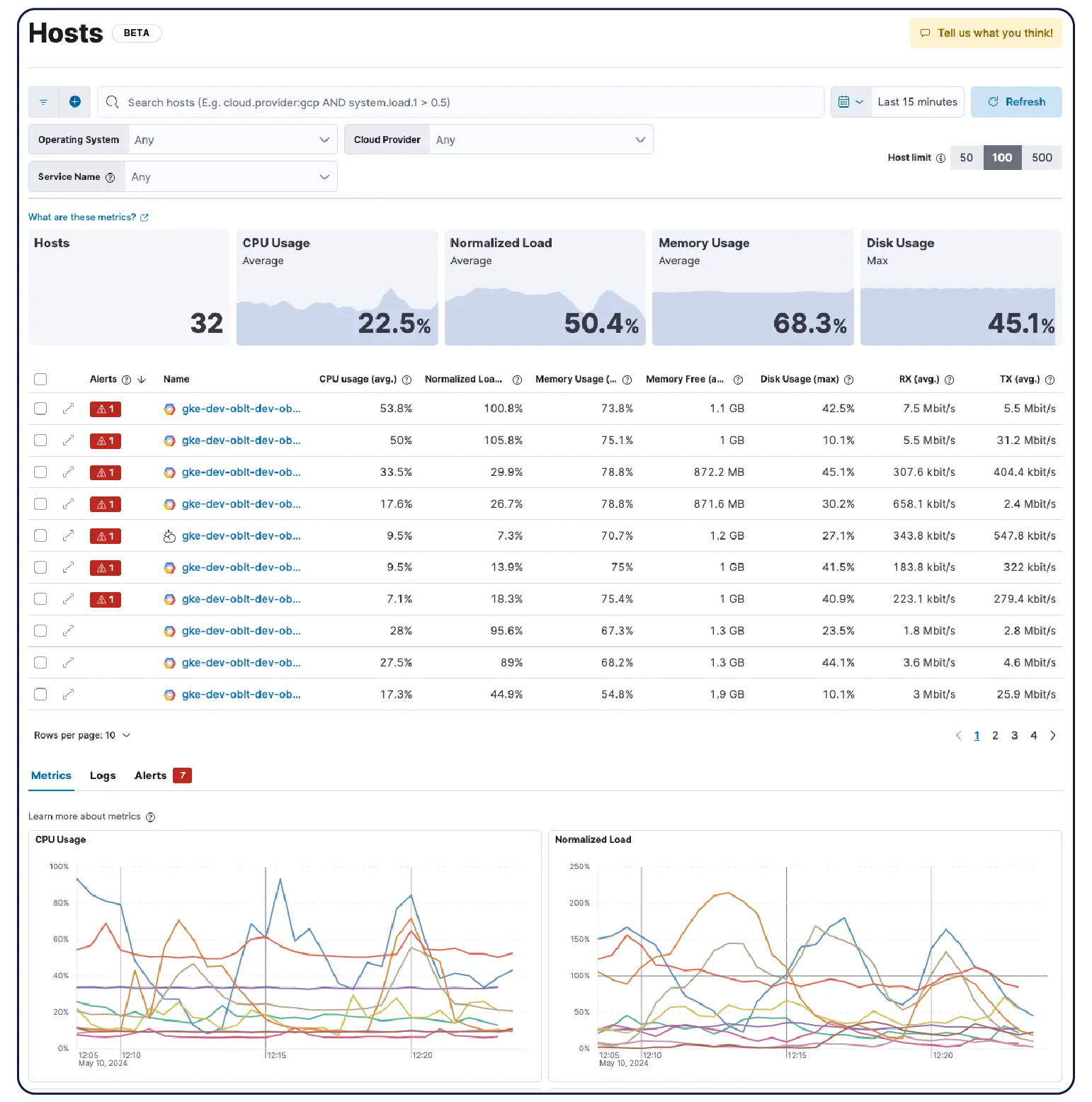
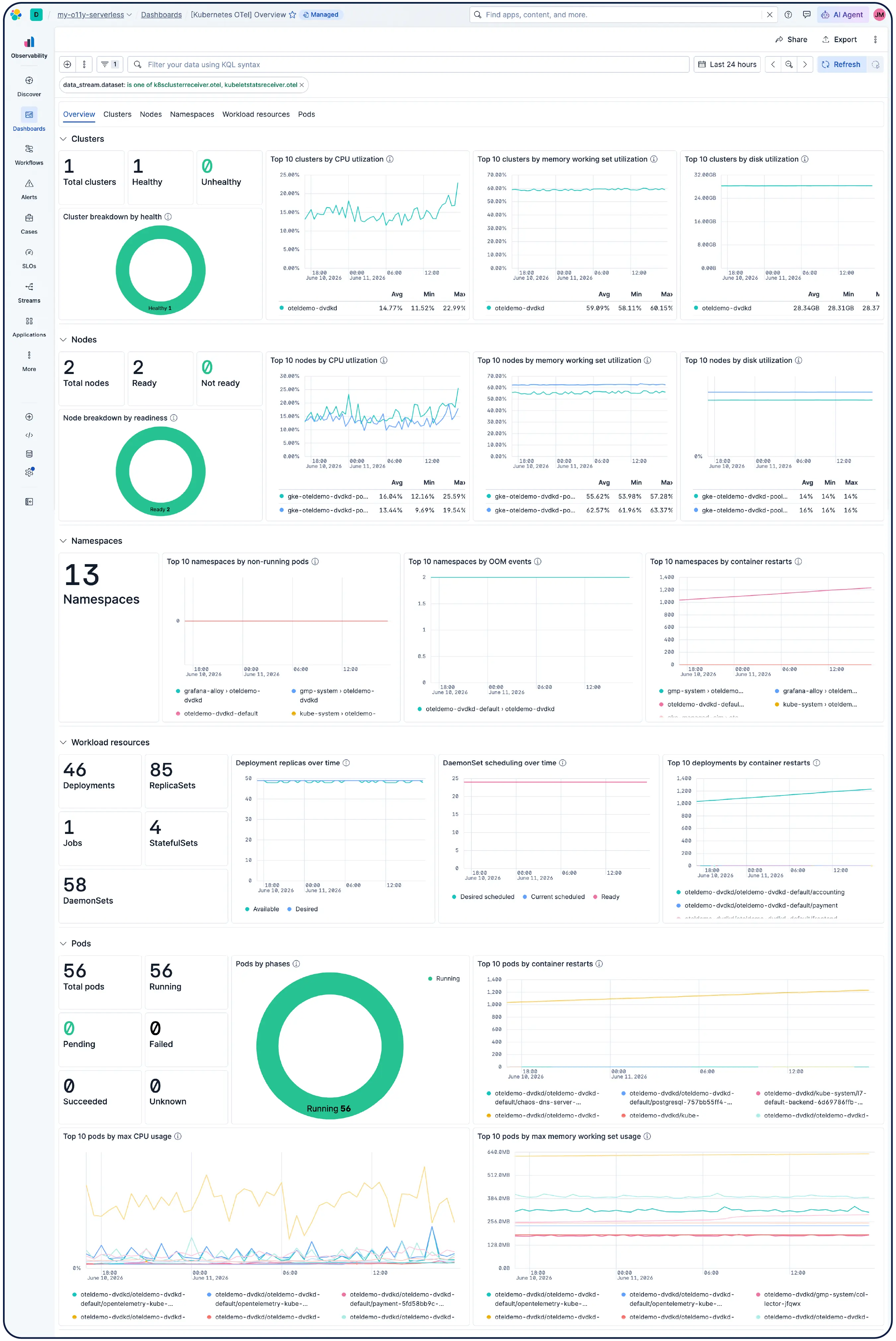
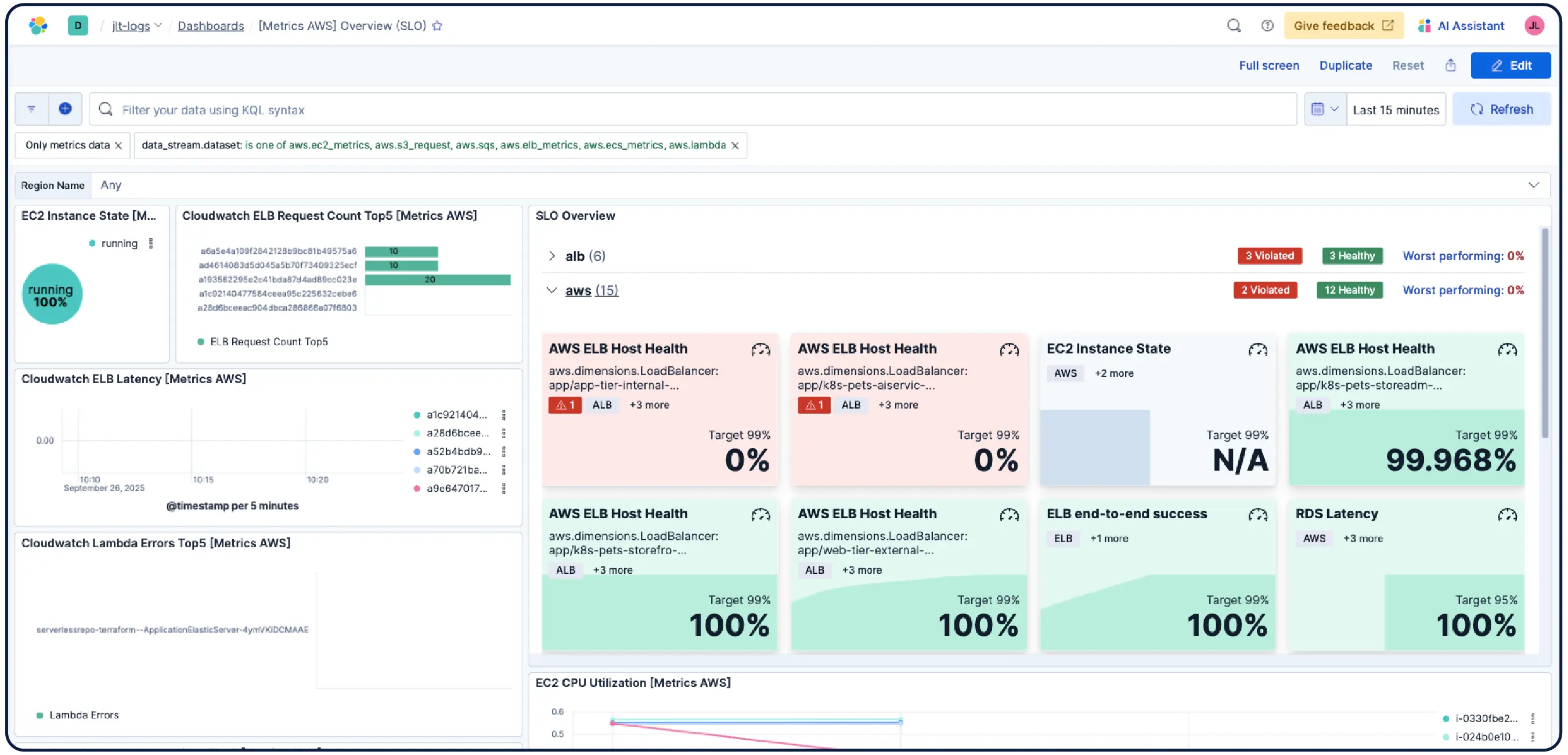
Que vous utilisiez des clusters Kubernetes, des machines virtuelles, un cloud ou des serveurs sur site, nos 550+ intégrations préconstruites, nos agents de transfert légers et nos collecteurs sans agent pour AWS, Azure et GCP rendent l’ingestion indolore.
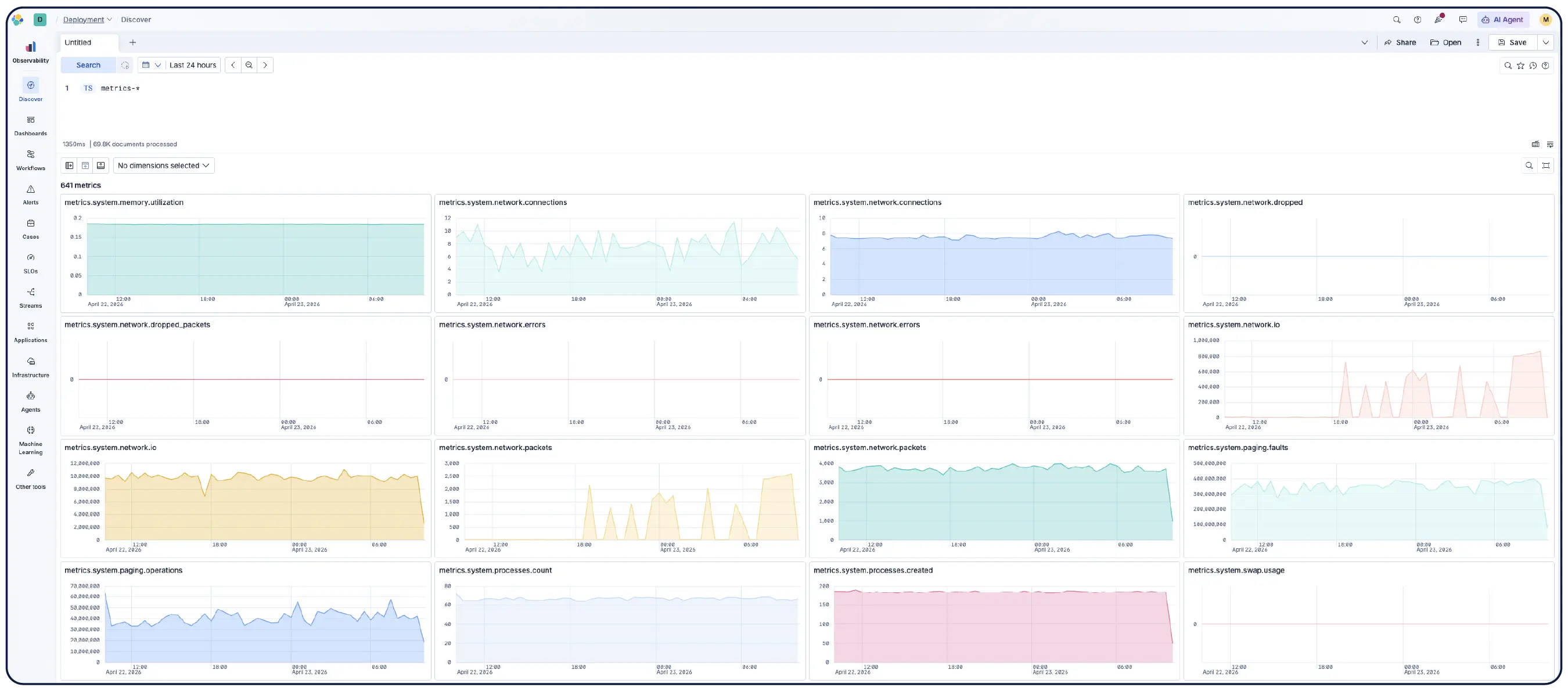
Recherchez, filtrez, agrégez et visualisez des données dans Discover. Enregistrez des sessions dans des tableaux de bord, définissez des alertes et exécutez des requêtes ES|QL sur n'importe quelles données pour une analyse unifiée. Filtrez selon n'importe quelle métrique sur n'importe quelle dimension et exécutez du PromQL directement dans Kibana.
Découvrez pourquoi des entreprises comme la vôtre choisissent Elastic Observability
Témoignage client

Comcast effectue l'ingestion de 400 téraoctets de données par jour avec Elastic pour monitorer les services et accélérer l'analyse des causes premières, garantissant ainsi une expérience client de premier ordre.
Témoignage client

Zooplus utilise Elastic pour monitorer 2 500 microservices, 20 000 conteneurs, 600 comptes AWS avec 70 services AWS et 40 clusters Kubernetes.
Témoignage client

Informatica a réduit ses coûts et son MTTR en migrant l'intégralité de sa charge de travail de logging vers Elastic pour plus de 100 applications et plus de 300 clusters Kubernetes.
Rejoignez la discussion
Connectez-vous à la communauté mondiale d'Elastic et participez à des conversations ouvertes et à la collaboration.

Posez des questions, obtenez des réponses et faites entendre votre voix sur notre forum ouvert.

.jpg)

Questions fréquentes
Qu'est-ce que la surveillance des infrastructures ?
Qu'est-ce que la surveillance des infrastructures ?
La surveillance de l'infrastructure permet de suivre l'état et les performances des systèmes sur lesquels vos applications s'exécutent : serveurs web, conteneurs, instances cloud, périphériques réseau, caches, files d'attente, bases de données, stockage, etc. Elle collecte des indicateurs tels que l'utilisation du processeur, la consommation de mémoire, les E/S disque et les redémarrages de pods, afin que les équipes puissent détecter la saturation des ressources, intercepter les pannes avant qu'elles ne s'aggravent et comprendre l'impact de l'état de l'infrastructure sur le comportement des applications. Une surveillance efficace de l'infrastructure met en corrélation ces indicateurs avec les logs et les traces, permettant ainsi aux ingénieurs de passer d'une simple surchauffe du système à l'identification de la cause première d'un problème, sans changer d'outil.
Comment Elastic monitore-t-il l'infrastructure ?
Comment Elastic monitore-t-il l'infrastructure ?
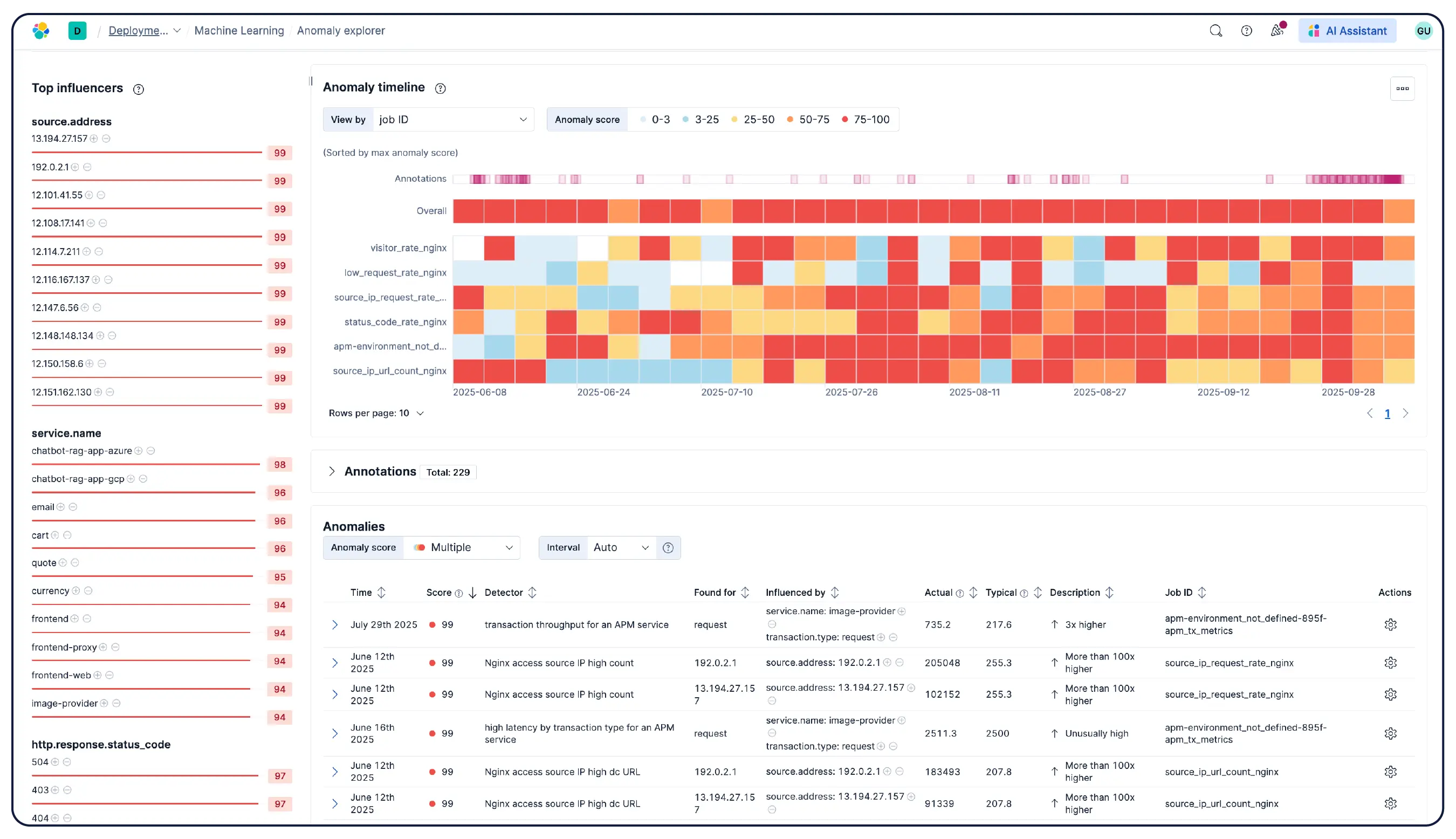
Elastic observabilité collecte des métriques, des logs et des traces depuis les hôtes, les conteneurs, les services cloud et les clusters Kubernetes et les corrèle dans Elasticsearch afin que les équipes puissent enquêter sur les signaux en un seul endroit. Elastic offre une visibilité sur le cloud, sur site, Kubernetes, serverless et les hôtes avec 550+ intégrations prêtes à l'emploi et une prise en charge native d'OpenTelemetry. Elastic Agent gère la collecte de manière centralisée via Fleet — aucune configuration d'agent par hôte n'est requise. La détection des anomalies basée sur le Machine Learning met automatiquement en évidence les modèles d'utilisation inhabituels, et comme les métriques d'infrastructure se trouvent aux côtés des traces et des logs des applications, les ingénieurs peuvent passer directement d'une alerte au contexte corrélé sans quitter la Platform.
Est-ce qu’Elastic prend en charge la surveillance Kubernetes ?
Est-ce qu’Elastic prend en charge la surveillance Kubernetes ?
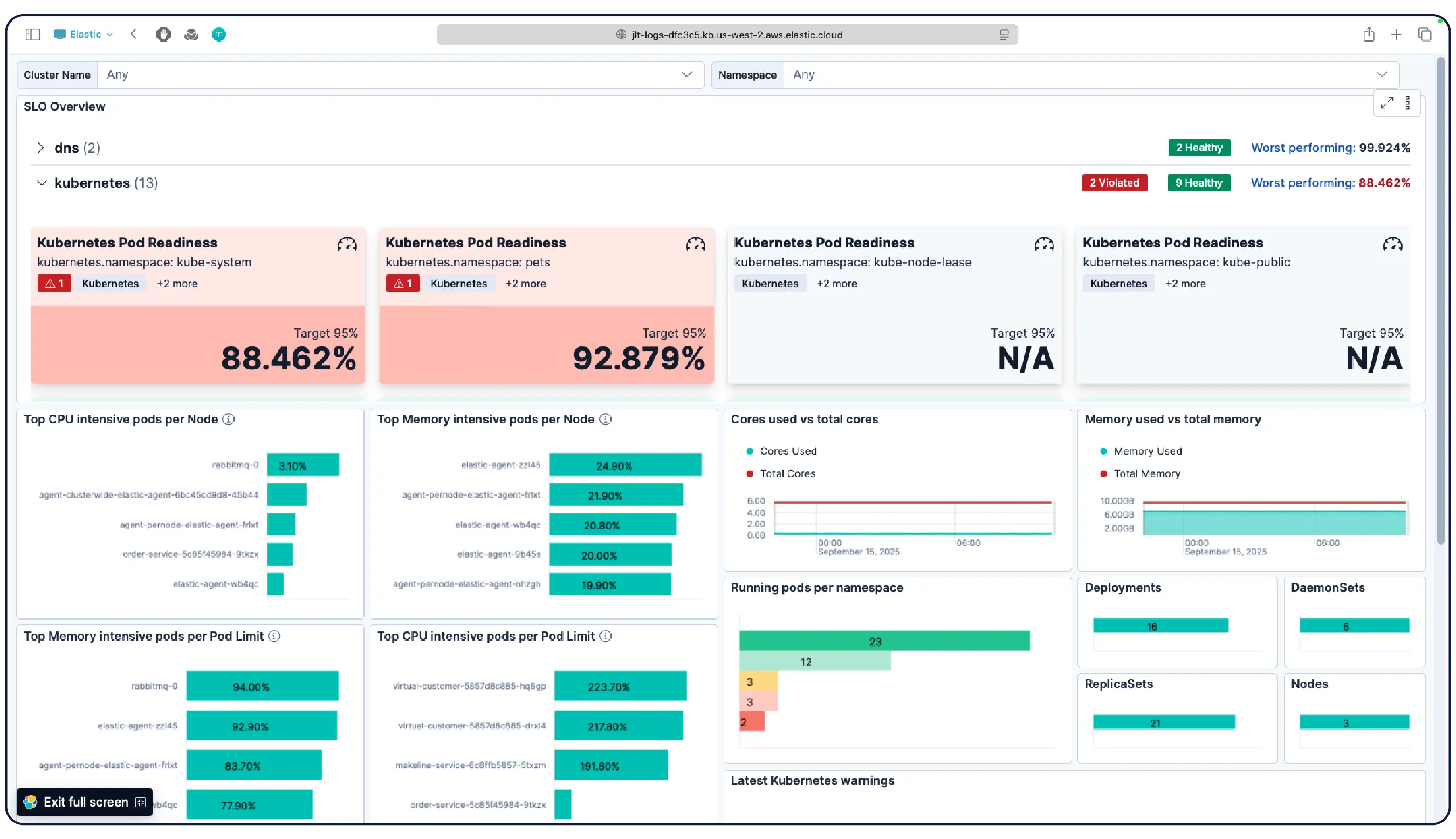
Oui. Elastic Observabilité est conçu pour monitorer les environnements Kubernetes, y compris les clusters gérés sur EKS, AKS et GKE, ainsi que les clusters autogérés. Elastic détecte automatiquement les changements dans les charges de travail dynamiques Kubernetes et monitore les services et composants partout où ils sont en cours d'exécution, avec un enrichissement des métadonnées à l'ingestion afin que vous puissiez filtrer, suivre et identifier les attributs communs à travers votre système. Au fur et à mesure que les pods montent et descendent, Elastic suit le rythme sans reconfiguration manuelle. L’utilisation des ressources du cluster, les logs au niveau des pods, les traces applicatives et les métriques d’infrastructure sont tous collectés à partir d’un seul déploiement et corrélés dans Kibana, avec détection des anomalies et catégorisation des logs pour faire apparaître les problèmes que vous ne saviez pas rechercher.
Quels formats de données Elastic prend-il en charge ?
Quels formats de données Elastic prend-il en charge ?
Elastic Observabilité est construit autour de standards ouverts. Il réalise l'ingestion native du protocole OpenTelemetry (OTLP) — logs, métriques et traces — sans conversion de schéma ni traduction propriétaire. EDOT, les Distributions Elastic d'OpenTelemetry, vous offre un écosystème OTel natif prêt pour la production : installez le Collecteur EDOT, activez l'auto-instrumentation avec les SDK de langage, et vos données affluent dans Elasticsearch avec le schéma OTel intact. Les métriques Prometheus et PromQL sont pris en charge nativement, et plus de 450 intégrations en un clic couvrent les fournisseurs cloud, les bases de données, les files d'attente de messages, les appareils réseau et les frameworks d'application. Elastic Agent et Beats gèrent les formats de logs structurés et non structurés de pratiquement toutes les sources courantes.
Comment Elastic réduit-il les coûts de surveillance des infrastructures ?
Comment Elastic réduit-il les coûts de surveillance des infrastructures ?
Elastic aborde le coût de l'observabilité à la fois au niveau du stockage et de l'architecture. Le mode d'index logsdb peut réduire les besoins de stockage des logs jusqu'à 65 % en optimisant l'ordre des données, en éliminant les doublons avec la synthetic _source et en améliorant la compression. Pour les métriques, les flux de données temporelles (TSDS) utilisent le stockage en colonnes et des codecs spécifiques aux données temporelles – delta des deltas, encodage par exécution, encodage XOR – réduisant l'espace disque des métriques jusqu'à 70 % à travers des intégrations comme Kubernetes, AWS et Nginx. Pour les équipes utilisant Elastic Cloud Serverless, le stockage d'objets natif du cloud est le système de référence, donc toutes les données sont stockées selon l'économie du stockage d'objets sans nécessiter de niveaux ou de planification de capacité.
Comment la tarification des métriques d’Elastic se compare-t-elle à celle de ses concurrents ?
Comment la tarification des métriques d’Elastic se compare-t-elle à celle de ses concurrents ?
Elastic Observability utilise une tarification basée sur la consommation, sans frais par hôte et sans facturation maximale. La tarification par hôte de Datadog facture les événements de dimensionnement automatique au maximum du nombre de Node pendant tout le mois, et non la moyenne d'utilisation. Les métriques personnalisées coûtent plus cher et peuvent représenter jusqu’à 52 % de la facture moyenne. Le modèle d’Elastic signifie que les charges de travail éphémères et les environnements Prometheus à haute cardinalité ne réservent pas de surprises en fin de mois.