Monitoring Kubernetes scaler
Obtenez une visibilité en temps réel sur votre écosystème Kubernetes dans les environnements EKS, GKE, AKS, sur site et en environnement air gap. Elastic associe la surveillance de Kubernetes au moteur d'analyse de logs le plus complet du secteur et au moteur de métriques le plus rapide, avec une observabilité complète, pilotée par l'IA, scalabilité et ouverte par conception.

Surveillance de Kubernetes partout où vous travaillez déjà
Des tableaux de bord, des alertes, des SLOs, des tâches de machine learning, les compétences des agents pour les enquêtes et les mesures correctives pilotées par l’IA — et une application MCP, prêtes dès que vous vous connectez. L'IA pilotée par agent identifie les anomalies, enquête sur les incidents et automatise les mesures correctives afin que vous puissiez planifier la capacité et résoudre les problèmes plus rapidement.

Des performances à haute cardinalité pour une fraction du coût
Elastic Observability élimine les deux raisons pour lesquelles les ingénieurs SRE recherchent une meilleure solution de surveillance d'infrastructure : la facturation personnalisée des métriques de Datadog et le travail de corrélation manuelle imposé par la pile fragmentée de Grafana lors de chaque incident. Grâce à notre architecture basée sur OpenTelemetryet nativement compatible avec Prometheus, vous conservez vos flux de travail préférés sans sacrifier les performances ni la conservation des données.




Surveillance de Kubernetes en action
Surveillez votre infrastructure à grande échelle Les analyses menées par l'IA établissent des corrélations entre les signaux provenant des couches application, Kubernetes et cloud afin d'identifier la cause première et de proposer des mesures correctives, sans qu'il soit nécessaire de procéder à une analyse manuelle.
Elastic construit automatiquement un modèle continuellement mis à jour de votre environnement Kubernetes — Node, pods, services et dépendances. Suivez les SLO et les budgets d’erreur, et utilisez une IA agente pour naviguer du symptôme à la cause profonde sans avoir à fouiller dans les tableaux de bord.
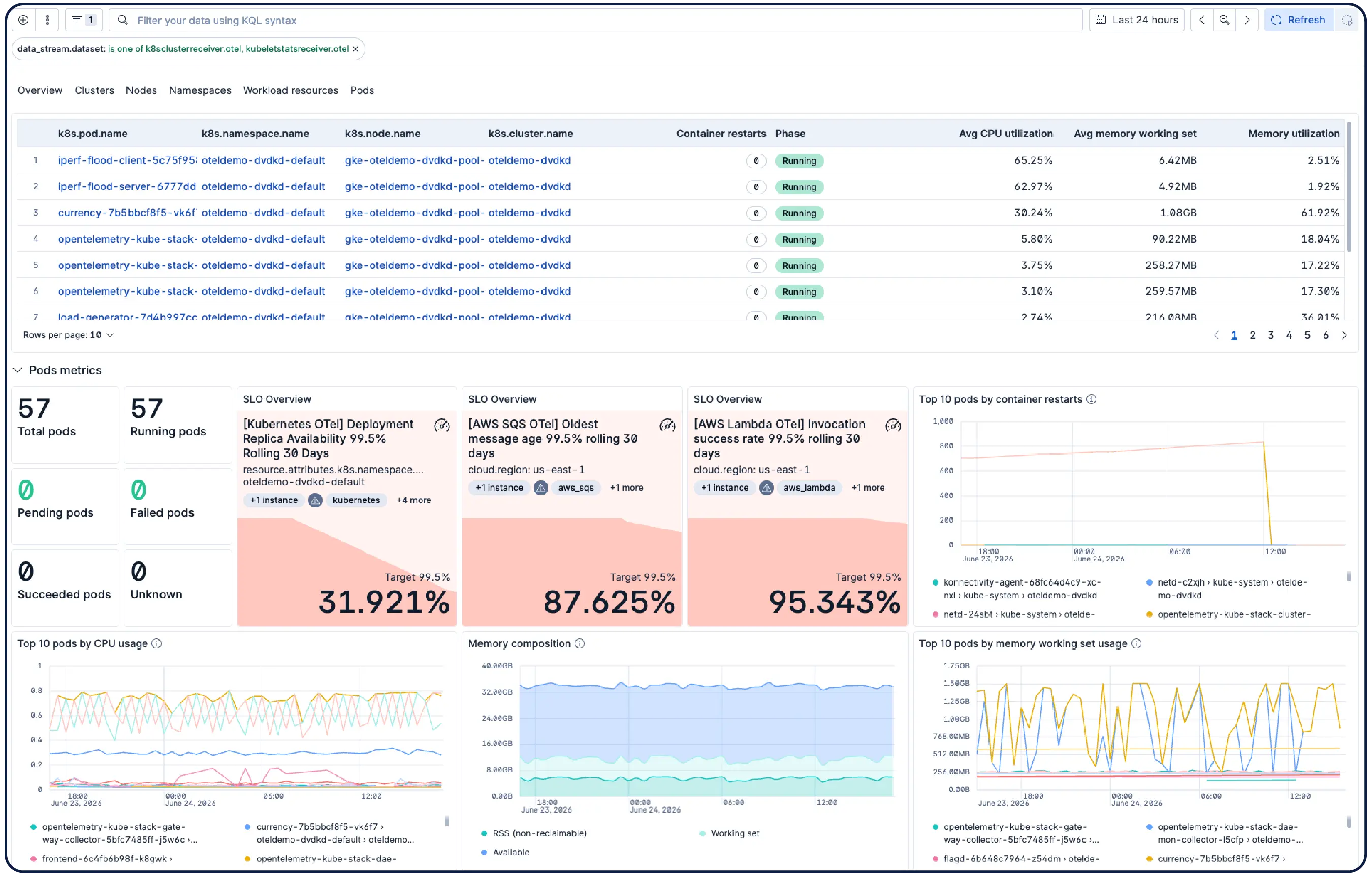
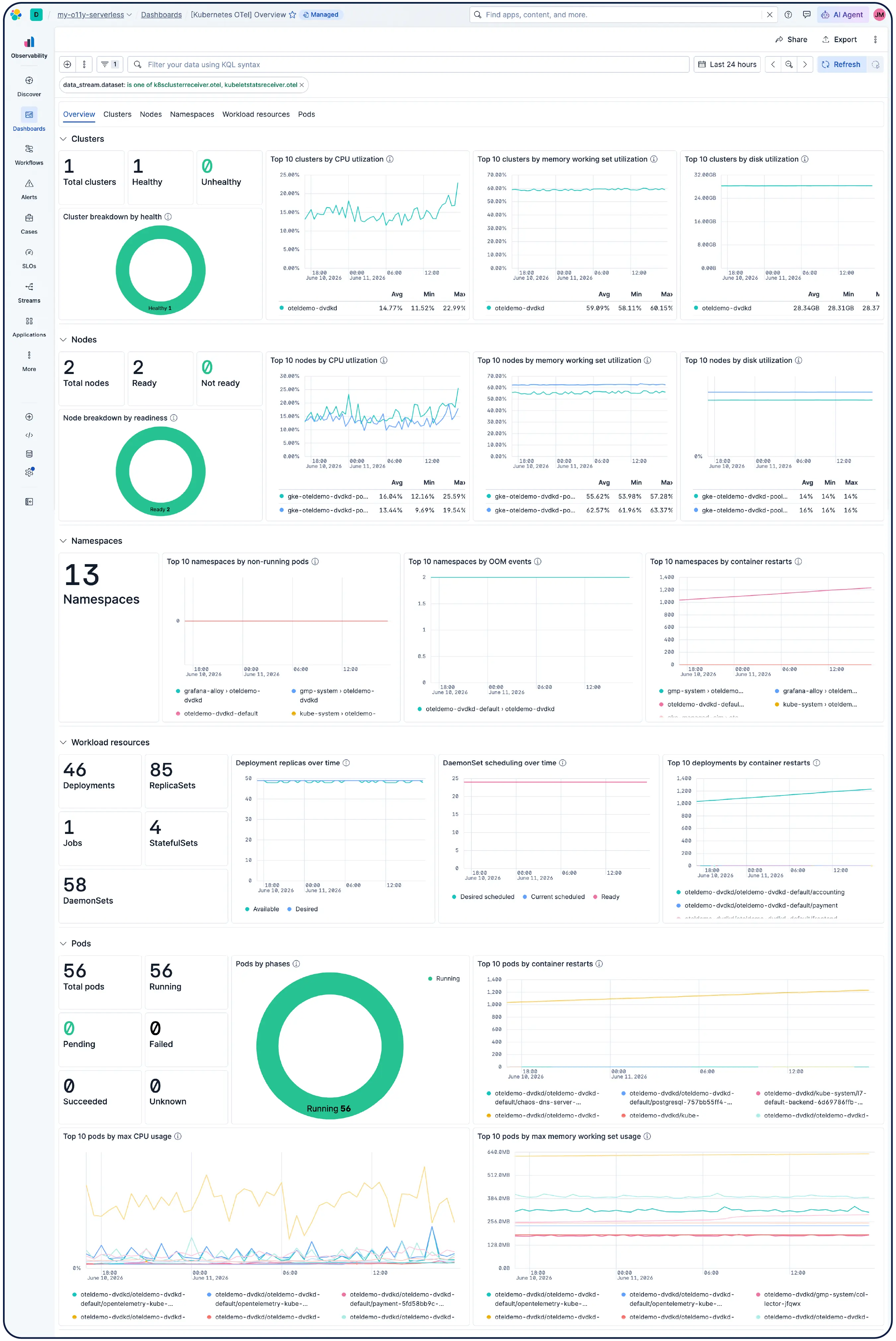
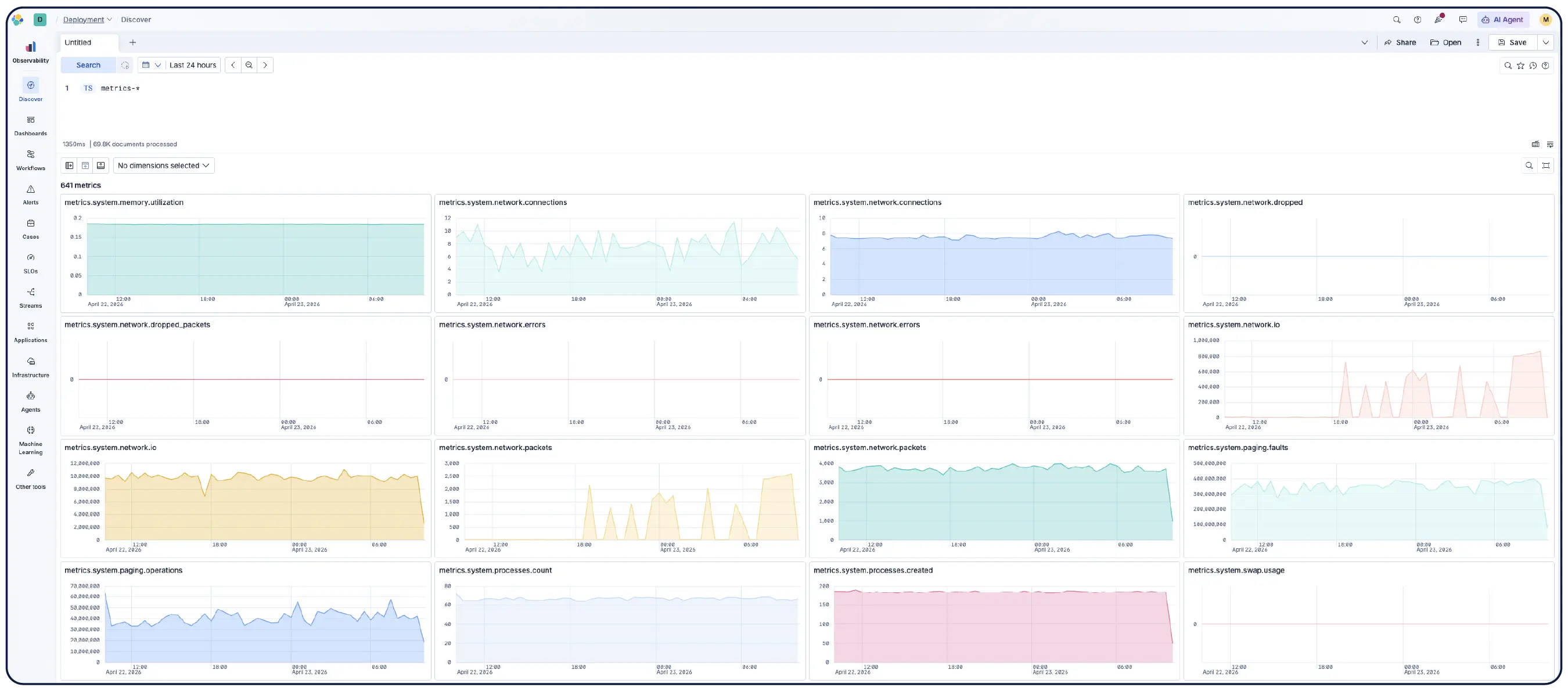
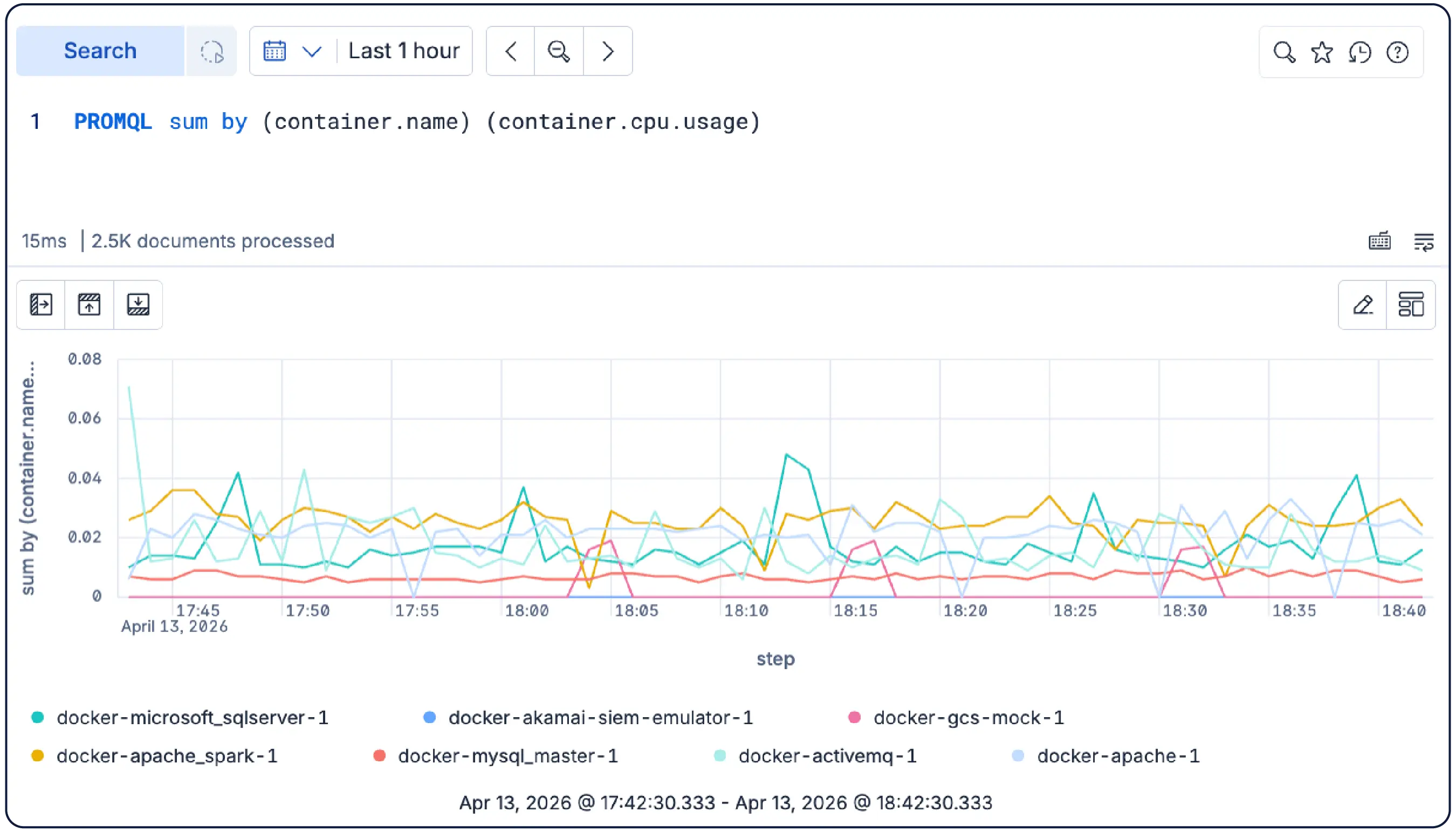
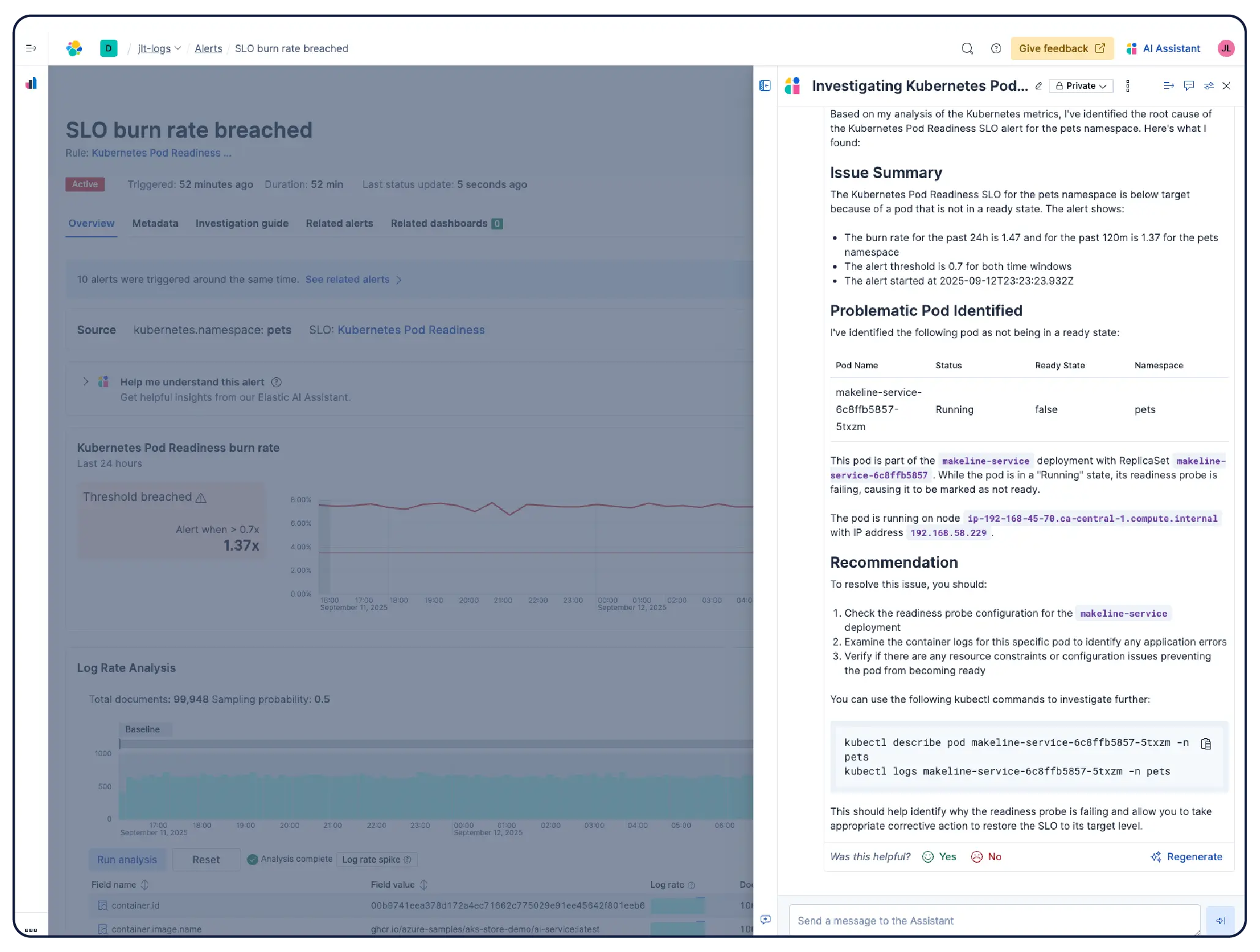
Scaler Kubernetes sans difficulté
D'autres plateformes de surveillance vous obligent à choisir entre les données dont vous avez besoin et le coût que vous pouvez vous permettre. Elastic vous offre les deux. Obtenez une visibilité complète sur chaque couche de votre cluster Kubernetes — Node, plan de contrôle et charges de travail — sans les frais opérationnels ou les compromis.
Elastic
Autres fournisseurs
Tarification prévisible avec conservation à long terme en pleine résolution : aucune pénalité de cardinalité, pas de regroupements forcés.
La facturation par hôte est standard. Chaque événement d'ajustement automatique est facturé sur la base du nombre maximal de Node pour l'ensemble du mois, et non sur la base de l'utilisation moyenne.
Le stockage en colonnes sur disque élimine toute limite de cardinalité en mémoire. Passez à l'échelle supérieure pour les environnements Kubernetes et cloud à cardinalité élevée sans risque de saturation de la mémoire.
L'indexation en mémoire signifie que les pics de cardinalité atteignent les limites de facturation ou de performances exactement au mauvais moment.
Recherche full-text sur tous les logs de pod et de Node. Recherchez n'importe quelle chaîne dans n'importe quel log, à n'importe quelle échelle — aucune étiquette prédéfinie n'est requise.
La plupart des fournisseurs indexent uniquement les étiquettes de logs. Si vous n'avez pas défini le libellé avant l'incident, vous ne pourrez pas le rechercher pendant celui-ci.
ES|QL interroge les logs, les mesures et les traces dans une seule requête. Corrélez un pic dans le processeur du pod avec la ligne de log qui l'a causé — sans changer d'outils ni de langages.
Le fait d'avoir des langages de requête distincts selon le type de signal — un pour les logs, un autre pour les métriques, un autre encore pour les traces — implique un changement de contexte au moment même où vous ne pouvez pas vous le permettre.
Les logs, les métriques et les traces font l'objet d'une ingestion native au format OpenTelemetry. Conservez votre instrumentation existante ou utilisez la distribution d'Elastic entièrement intégrée en amont pour un support de niveau production.
Les données d'instrumentation d'OTel sont acheminées via des back-ends propriétaires ou facturées en tant que métriques personnalisées au-delà d'un quota de base, ce qui pénalise la norme ouverte que votre équipe a déjà adoptée.
Plus de 100 tâches ML s'exécutent automatiquement sur les indicateurs et les logs Kubernetes. Facile à utiliser pour les débutants, entièrement personnalisable pour les experts.
La détection des anomalies nécessite une configuration manuelle du monitorage ou est limitée à des modèles prédéfinis.
Elastic Cloud, en autogestion ou en mode hybride — EKS, GKE, AKS, sur site, en environnement isolé. Une seule et même plateforme, quel que soit l'emplacement de vos clusters.
De nombreux fournisseurs proposent exclusivement des solutions SaaS. Si vos clusters sont en exécution sur site ou dans un environnement réglementé, vous n'avez aucune option avant le début de l'évaluation.
Indépendant du schéma, open source, et basé sur des standards ouverts — OTel en priorité, Prometheus natif, PromQL pris en charge. Stockez vos données dans le format de votre choix et interrogez-les telles quelles. Pas de traduction, pas d'enfermement.
Les agents propriétaires et les back-end sont la norme. Changer de fournisseur implique de réimplémenter l'ensemble de votre infrastructure.
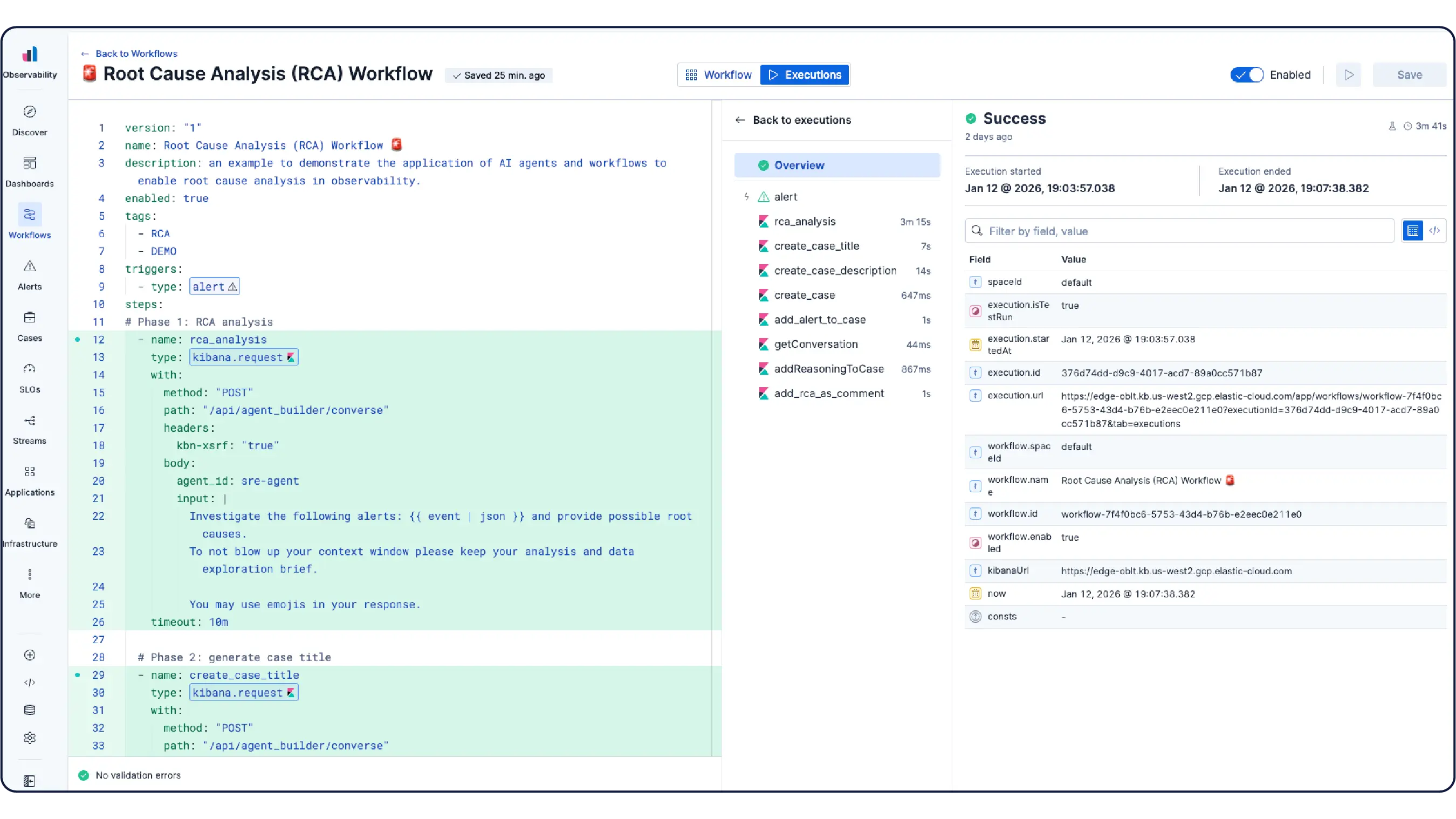
L'IA analyse vos métriques, logs et traces pour révéler rapidement les causes profondes et guider la correction ; aucune exploration manuelle des tableaux de bord n'est nécessaire.
L'IA fonctionne souvent sur des infrastructures back-end fragmentées plutôt que sur un datastore unifié et hautement performant, ce qui limite les corrélations qu'elle peut établir et la rapidité avec laquelle elle peut agir.
Découvrez pourquoi des entreprises comme la vôtre choisissent Elastic Observability
Témoignage client

Comcast effectue l'ingestion de 400 téraoctets de données par jour avec Elastic pour monitorer les services et accélérer l'analyse des causes premières, garantissant ainsi une expérience client de premier ordre.
Témoignage client

Zooplus utilise Elastic pour monitorer 2 500 microservices, 20 000 conteneurs, 600 comptes AWS avec 70 services AWS et 40 clusters Kubernetes.
Témoignage client

Informatica a réduit ses coûts et son MTTR en migrant l'intégralité de sa charge de travail de logging vers Elastic pour plus de 100 applications et plus de 300 clusters Kubernetes.
Rejoignez la discussion
Connectez-vous à la communauté mondiale d'Elastic et participez à des conversations ouvertes et à la collaboration.

Posez des questions, obtenez des réponses et faites entendre votre voix sur notre forum ouvert.

.jpg)

Questions fréquentes
Qu'est-ce que le monitoring de Kubernetes ?
Qu'est-ce que le monitoring de Kubernetes ?
La supervision Kubernetes permet de surveiller l'état et les performances de votre cluster – nœuds, pods, espaces de noms et charges de travail qui s'y exécutent – grâce aux métriques, aux logs et aux traces. En cas de problème, il est crucial d'en identifier rapidement la cause dans un environnement dynamique et éphémère où les services sont constamment mis en service ou supprimés.
Quelles distributions Kubernetes sont prises en charge par support technique Elastic ?
Quelles distributions Kubernetes sont prises en charge par support technique Elastic ?
Elastic prend en charge KS, AKS, GKE, et les clusters autogérés avec une auto-découverte dynamique sur l'ensemble d'entre eux.
Pourquoi l'intégration de surveillance Elastic Kubernetes transfère-t-elle autant de contenu inclus ?
Pourquoi l'intégration de surveillance Elastic Kubernetes transfère-t-elle autant de contenu inclus ?
Car le plus difficile dans la supervision de Kubernetes, ce n’est pas la connexion du cluster, mais le temps passé à créer des tableaux de bord, à rédiger des règles d’alerte, à configurer des tâches de ML et à assurer la maintenance de l’ensemble du système au fil des modifications apportées au cluster. Elastic transfère tout cela dès le départ : votre supervision est opérationnelle dès le premier jour, et non plus après trente jours.
En quoi l'IA autonome facilite-t-elle la gestion des incidents sur Kubernetes ?
En quoi l'IA autonome facilite-t-elle la gestion des incidents sur Kubernetes ?
Au lieu de corréler manuellement les tableaux de bord entre les pods, services, et couches cloud, les agents IA d’Elastic analysent automatiquement votre télémétrie pour enquêter sur les problèmes, faire émerger la cause profonde et exécuter des actions de remédiation — s’appuyant sur des modèles de ML et le contexte de vos runbooks et bases de connaissances.
Comment Elastic gère-t-il les indicateurs Kubernetes à haute cardinalité ?
Comment Elastic gère-t-il les indicateurs Kubernetes à haute cardinalité ?
Elastic gère les indicateurs Kubernetes à forte cardinalité grâce à son architecture Time Series Data Stream (TSDS), qui utilise un stockage sur disque organisé en colonnes plutôt qu'un index inversé en mémoire. Contrairement aux backends basés sur Prometheus qui génèrent des erreurs de mémoire insuffisante (OOM) lorsque la cardinalité des pods et des labels d'espace de nom augmente brusquement, Elastic n'impose aucune limite à la cardinalité en mémoire. L'ingestion des métriques s'effectue nativement via l'écriture distante Prometheus ou OpenTelemetry sans conversion de schéma, et le sous-échantillonnage automatique permet de maîtriser les coûts de stockage à long terme sans compromettre la précision des requêtes.
Elastic prend-il en charge kube-state-metrics ?
Elastic prend-il en charge kube-state-metrics ?
Le collecteur natif OpenTelemetry d’Elastic gère les métriques d’état Kubernetes clé en main, donc les kube-state-metrics ne sont pas nécessaires.
Comment la tarification de la surveillance Kubernetes d'Elastic se compare-t-elle à celle des concurrents ?
Comment la tarification de la surveillance Kubernetes d'Elastic se compare-t-elle à celle des concurrents ?
Elastic Observability utilise une tarification à la consommation, sans frais par hôte ni facturation au plafond. La tarification par hôte de Datadog facture les événements d'autoscaling au nombre maximal de node pour l'ensemble du mois, et non sur la base de l'utilisation moyenne. Les métriques personnalisées sont facturées en supplément et peuvent représenter jusqu'à 52 % de la facture moyenne. Le modèle d'Elastic permet d'éviter les mauvaises surprises de fin de mois, même pour les charges de travail éphémères et les environnements Prometheus à forte cardinalité.
À quoi ressemble la migration depuis Datadog ou Grafana ?
À quoi ressemble la migration depuis Datadog ou Grafana ?
La migration est facile grâce à notre outil de migration (actuellement en version préliminaire), qui convertit automatiquement vos tableaux de bord et vos règles d'alerte. La prise en charge native de PromQL et d'OTel signifie que votre architecture d'ingestion existante est conservée. La plupart des équipes seront pleinement opérationnelles le lendemain.
La surveillance Elastic Kubernetes inclut-elle la sécurité ?
La surveillance Elastic Kubernetes inclut-elle la sécurité ?
Oui. L’intégration Kubernetes Security Posture Management (KSPM) d’Elastic évalue la configuration de votre cluster selon les directives CIS Benchmarks et génère des résultats à l’aide d’instructions de remise en état étape par étape. Elle prend en charge EKS et les clusters autogérés, s’évalue automatiquement toutes les quatre heures, et est disponible pour tous les utilisateurs d’Elastic Cloud, donc la même plateforme qui surveille vos performances vérifie également votre posture de sécurité. De plus, l’intégration Elastic Defend for Containers (D4C) offre une protection d’exécution native cloud pour les environnements Kubernetes, utilisant eBPF pour surveiller l’activité des processus et des fichiers à l’intérieur des conteneurs en cours d’exécution.