Surveillance Prometheus
Scaler Prometheus sans la dette opérationnelle – 30 fois plus rapide, 2,5 fois moins de stockage
Ingérez nativement les métriques Prometheus dans Elasticsearch et exécutez les requêtes PromQL directement dans Kibana. Unifiez les données temporelles à forte cardinalité avec des journaux et des traces pour une observabilité complète, pilotée par l'IA, évolutive et ouverte par conception.
Elasticsearch : une efficacité de premier ordre pour les métriques
Notre TSDB dépasse Prometheus en termes d'ingestion et de rapidité de requête à n'importe quelle échelle.
Prometheus + Elasticsearch
Elastic associe vos métriques Prometheus à la solution d'analyse de logs la plus performante du marché. Conservez vos workflows PromQL préférés et optimisez-les grâce à la corrélation des logs et à l'IA. Éliminez la navigation fastidieuse dans les tableaux de bord : l'IA analyse vos métriques et vos logs pour vous fournir des réponses en quelques secondes.
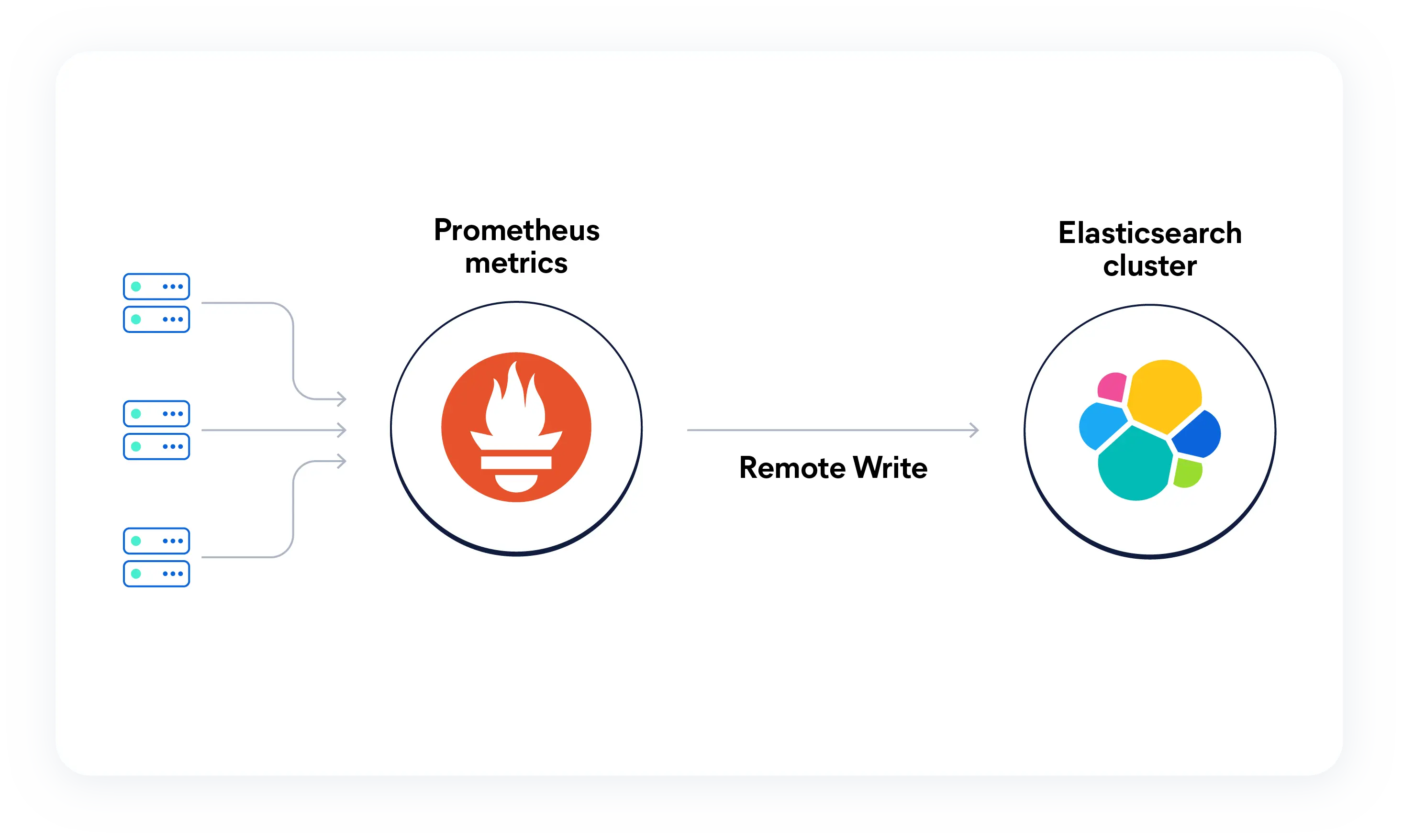
Arrêtez de bricoler votre pile d'observabilité
Les ingénieurs SRE sont lassés des contraintes opérationnelles liées au scaling de Prometheus et des changements de contexte nécessaires pour résoudre les incidents à partir de signaux cloisonnés. Elastic centralise tout cela dans une plateforme unique et performante.



La taxe Prometheus est officiellement facultative
La gestion et le scaling de Prometheus ne devraient pas générer du travail en plus. Le datastore unifié d'Elastic permet une conservation à long terme sans compromis sur les performances et les coûts.
Elasticsearch
Prometheus / Mimir / ClickHouse
L'utilisation native de Prometheus et de PromQL signifie l'absence de dépendance propriétaire, de réécritures ou de projets de migration qui durent des mois.
Le stockage à long terme et le scaling pour Prometheus nécessitent souvent des backends supplémentaires comme Mimir et Clickhouse.
Bien que Mimir prenne en charge PromQL, ClickHouse nécessite une couche de traduction.
Stocke nativement Prometheus et OTel dans un datastore unique de séries temporelles haute performance. Aucun changement sémantique, aucune couche propriétaire.
Prometheus nécessite un collecteur OTel avec conversion explicite.
ClickHouse prend en charge OTel, mais nécessite un travail de schéma personnalisé et une configuration de pipeline.
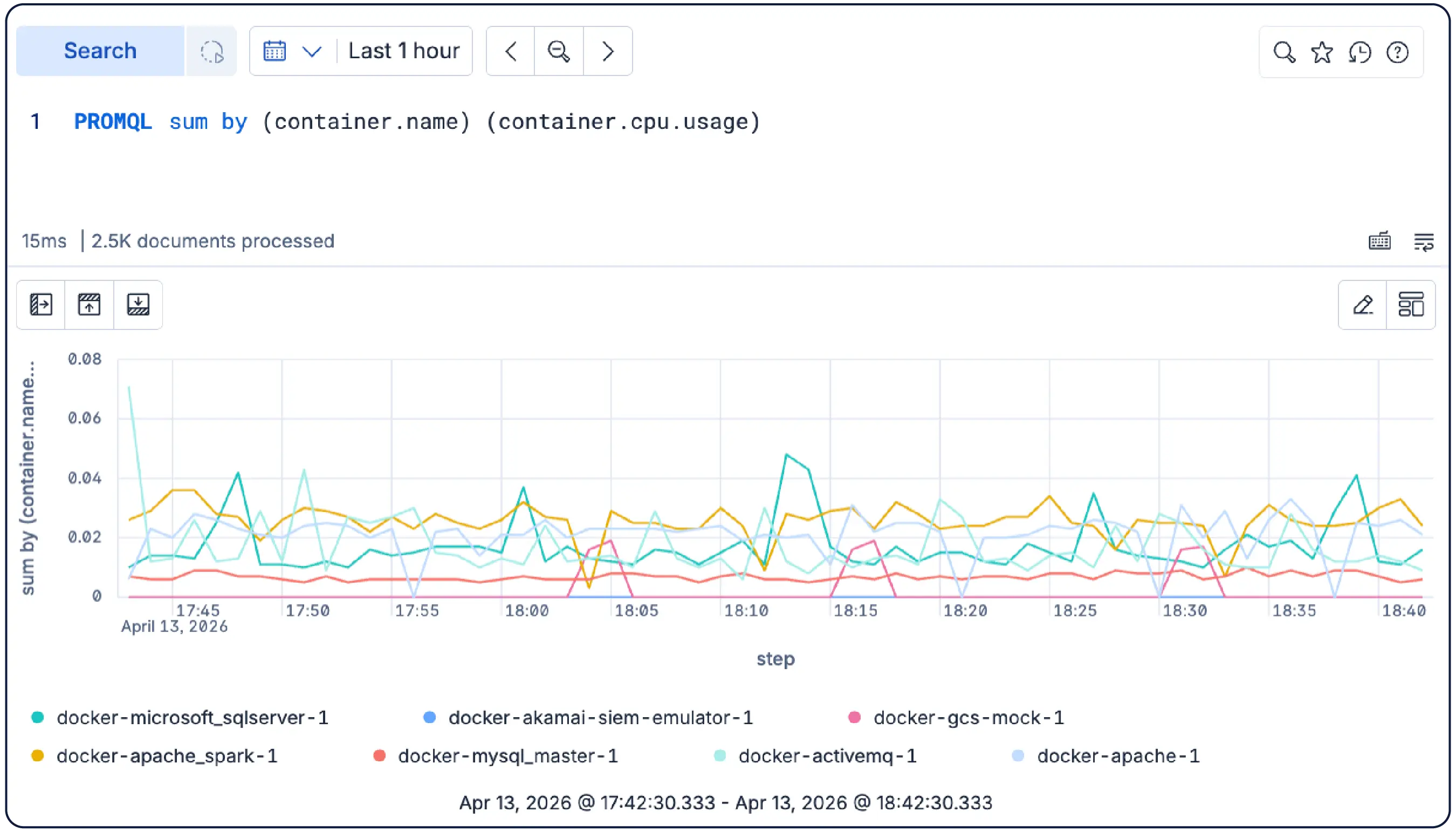
Corrélez les mesures, les logs et les traces dans une seule et même plateforme avec un seul langage de requête (ES|QL), sans changer d'onglet ni de contexte. Les instructions PromQL peuvent être incluses dans le cadre des requêtes ES|QL.
Les métriques et les logs résident dans des backends distincts, nécessitant un changement de contexte entre les outils et les langages de requête lors des incidents.
ClickHouse peut stocker les trois types de signaux, mais nécessite un schéma personnalisé important et un travail sur le pipeline pour y parvenir.
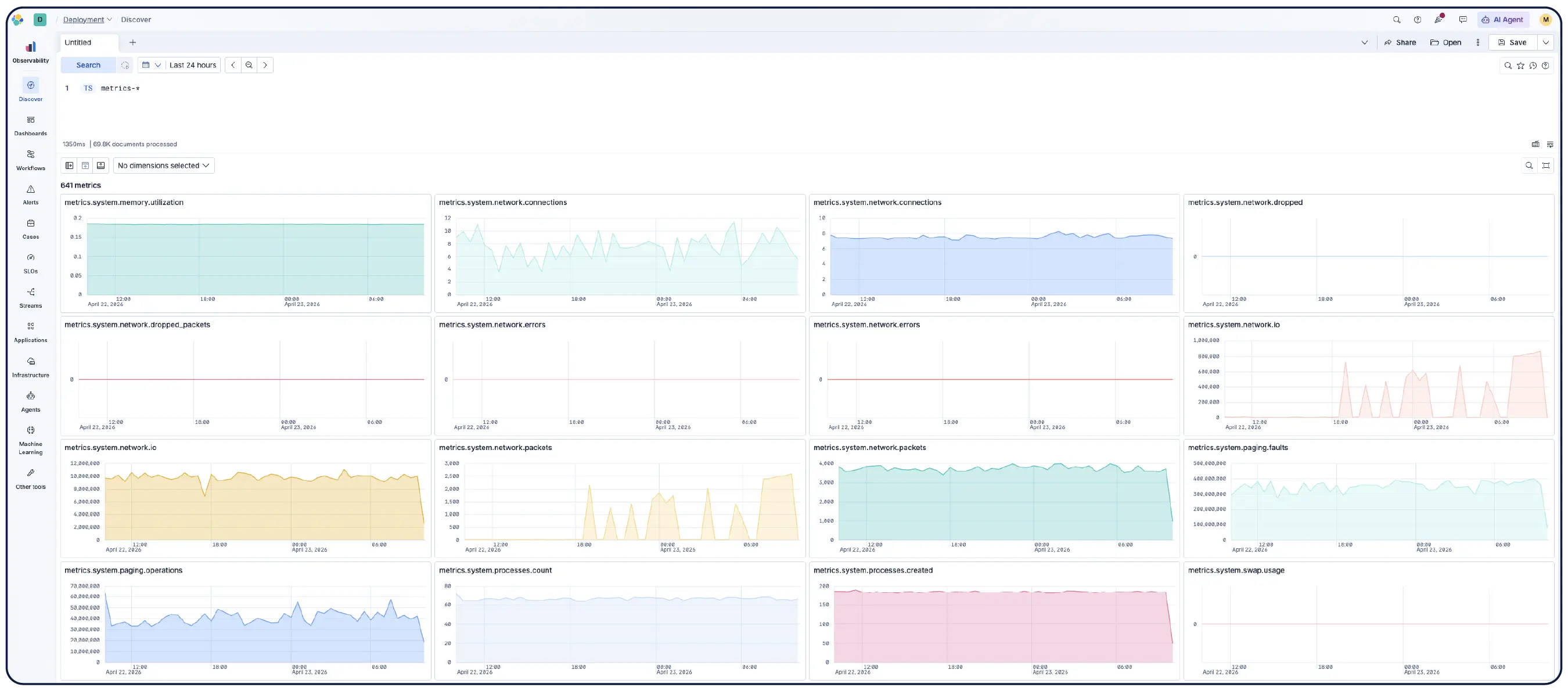
Le stockage en colonnes sur disque élimine toute limite de cardinalité en mémoire. Passez à l'échelle supérieure pour les environnements Kubernetes et cloud à cardinalité élevée sans risque de saturation de la mémoire.
Prometheus et Mimir utilisent un index inversé en mémoire — les pics de cardinalité provoquent des plantages OOM au pire moment possible.
Surpasse Prometheus et Mimir de 10 à 25 fois, voire plus, sur la plupart des types de requêtes à cardinalité faible comme élevée.
ClickHouse gère mieux la cardinalité mais nécessite un réglage important à grande échelle.
Sous-échantillonnage automatique intégré. Les données en pleine résolution restent consultables. La compression supérieure réduit votre espace de stockage sans opérations manuelles ni perte de données.
Mimir ne comporte pas de sous-échantillonnage intégré. La gestion de la conservation à long terme nécessite des règles d'enregistrement manuelles qui détruisent définitivement la granularité.
ClickHouse nécessite des pipelines TTL et d'agrégation personnalisés.
Tarification prévisible avec conservation à long terme en pleine résolution : aucune pénalité de cardinalité, pas de regroupements forcés.
Le scaling de Prometheus et de Mimir implique un compromis entre coût et performance : payez plus pour conserver les données plus longtemps, ou réduisez l'échantillonnage et perdez en granularité.
ClickHouse nécessite un réglage constant pour équilibrer la vitesse des requêtes et le coût du stockage.
Capacité complète sur Elastic Cloud, les déploiements autogérés et hybrides.
Prometheus et Mimir sont uniquement autogérés, avec une surcharge opérationnelle importante lors du scaling.
Le fonctionnement de ClickHouse nécessite une expertise approfondie en matière d'infrastructure.
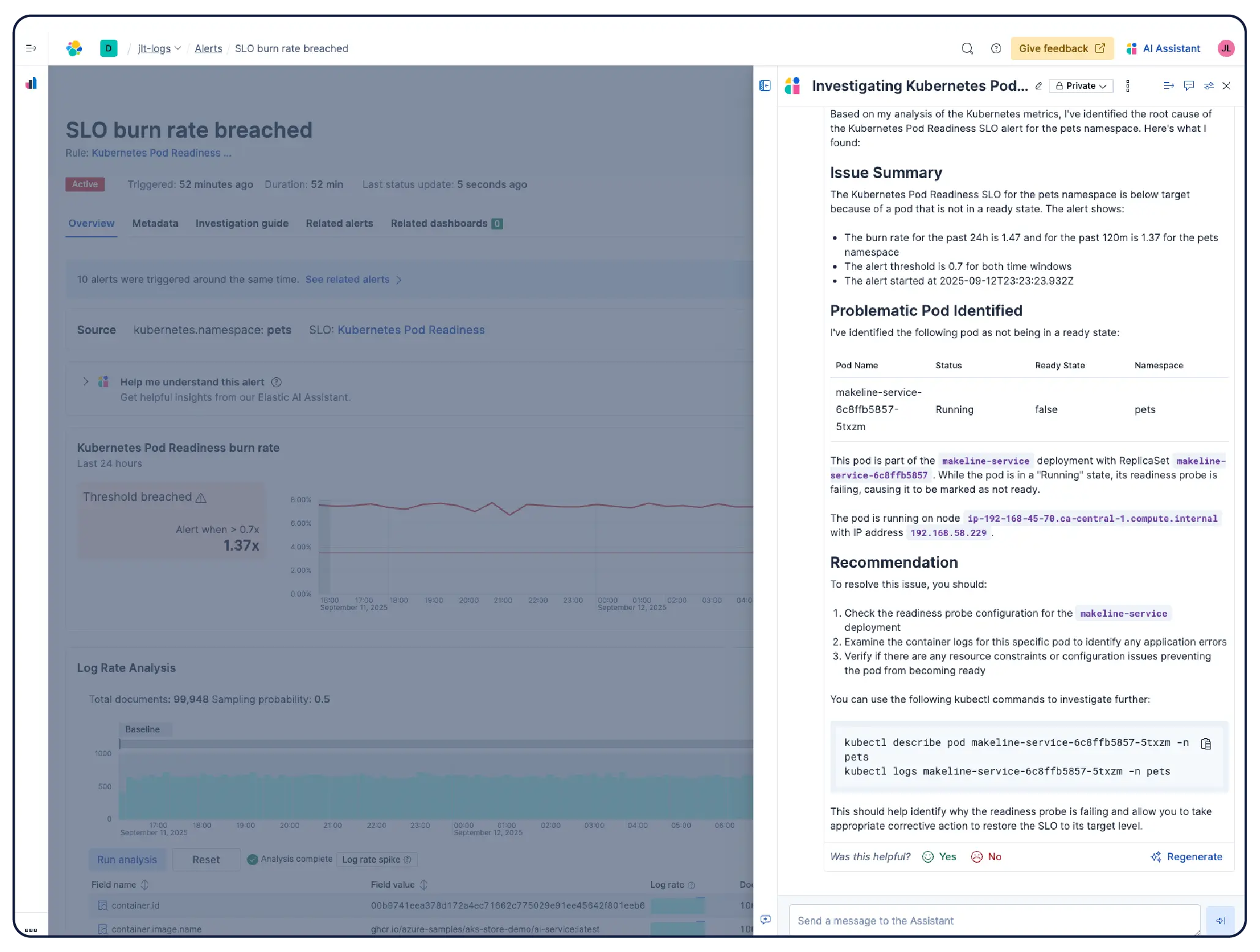
L'IA analyse vos métriques, logs et traces pour révéler rapidement les causes profondes et guider la correction ; aucune exploration manuelle des tableaux de bord n'est nécessaire.
L'assistant IA de Grafana fonctionne sur des backends fragmentés, plutôt que sur un datastore unifié.
ClickHouse ne possède pas d'IA agentique native. L'investigation dépend de la corrélation entre des outils déconnectés et des données cloisonnées.
Convertissez les données d'infrastructure en action
Monitorez votre infrastructure à grande échelle. Les enquêtes basées sur l'IA mettent en évidence les anomalies, découvrent les tendances et automatisent la correction, ce qui vous permet de planifier la capacité et de résoudre les problèmes plus rapidement.
Exécutez des requêtes PromQL directement dans Kibana : aucune couche de traduction ni réécritures ne sont nécessaires. Les fonctions `rate`, `sum by`, `max_over_time` courantes sont opérationnelles sans modification, en parallèle avec ES|QL.
Outil de migration – préversion technique
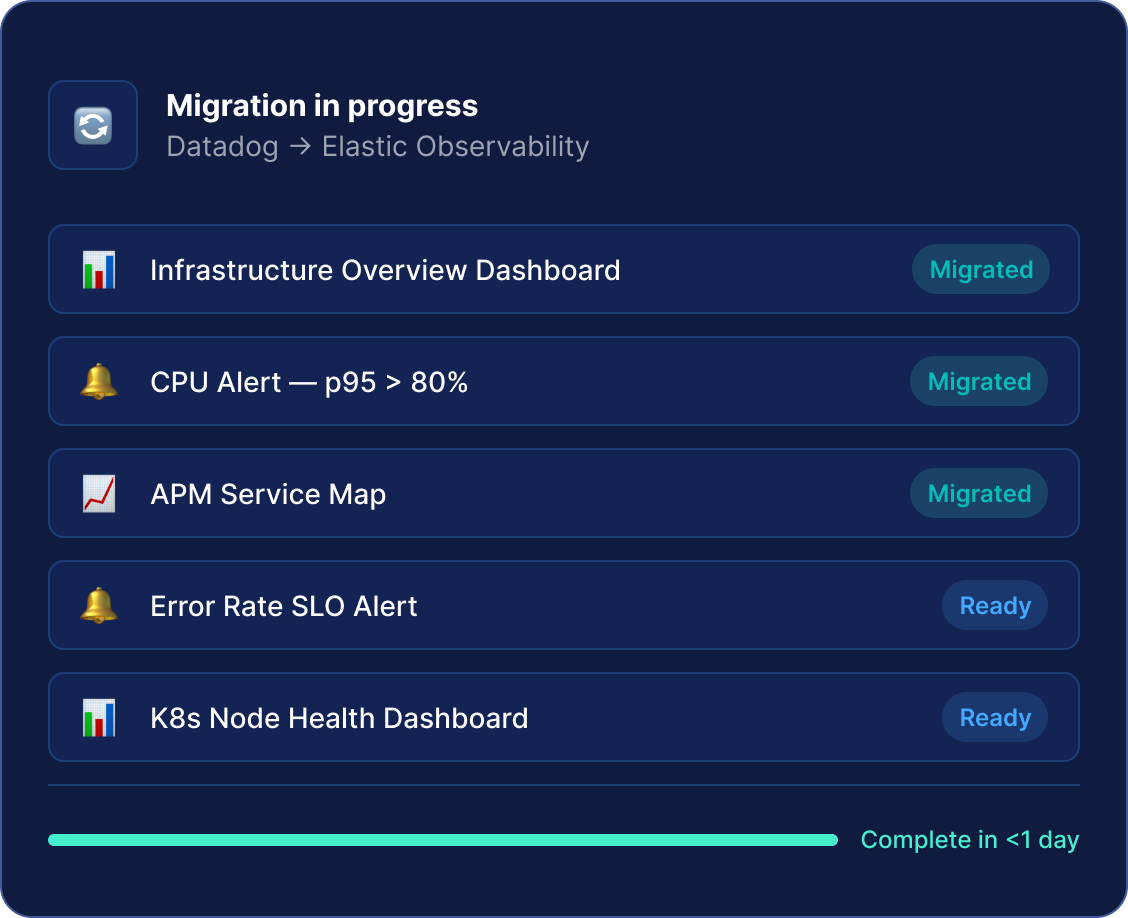
Migrez depuis Grafana pendant la nuit
Convertissez automatiquement les tableaux de bord et les règles d'alerting de Grafana en Elastic, réduisant considérablement le coût et la complexité du changement de plateforme.
Questions fréquentes
Qu'est-ce que Prometheus et la surveillance Prometheus ?
Qu'est-ce que Prometheus et la surveillance Prometheus ?
Prometheus est un outil de surveillance open source. Largement adopté dans les environnements cloud natifs et conteneurisés, Prometheus est un outil populaire pour collecter des données temporelles à partir de tâches instrumentées, en utilisant un format d'exposition textuel ouvert et indépendant du fournisseur.
Pourquoi devriez-vous abandonner Prometheus autogéré ?
Pourquoi devriez-vous abandonner Prometheus autogéré ?
Le scaling de Prometheus engendre des coûts opérationnels qui s'accumulent avec le temps. La gestion de backends comme Mimir complexifie les choses sans résoudre le problème de fond. Elastic prend en charge le scaling automatiquement. De plus, notre stockage en colonnes et notre traitement vectorisé offrent des vitesses de requête 10 à 25 fois supérieures à celles de Prometheus et Mimir, et ce pour la plupart des types de requêtes.
Pourquoi stocker les métriques Prometheus dans Elasticsearch ?
Pourquoi stocker les métriques Prometheus dans Elasticsearch ?
Le stockage local de Prometheus est conçu pour une courte durée de conservation, généralement de 15 à 30 jours. La TSBD d'Elasticsearch offre un stockage à long terme performant (2,5 fois plus performant que Prometheus) avec rotation, compression et sous-échantillonnage automatiques des données. Vos configurations de scraping existantes restent inchangées.
Mes tableaux de bord, alertes et requêtes existants natifs de Prometheus fonctionnent-ils toujours ?
Mes tableaux de bord, alertes et requêtes existants natifs de Prometheus fonctionnent-ils toujours ?
Oui. La prise en charge native PromQL permet de transférer facilement vos workflows Prometheus existants. Aucune réécriture de requête ni longue migration de projet n'est nécessaire.
Comment Elastic réduit-il les coûts de stockage ?
Comment Elastic réduit-il les coûts de stockage ?
Un sous-échantillonnage et une compression de niveau supérieur réduisent votre empreinte de stockage. Une tarification prévisible, basée sur les ressources, vous garantit une facture stable même en cas d'augmentation de la cardinalité ou d'ajout de nouvelles étiquettes. Conservez toutes les métriques nécessaires, en pleine résolution, aussi longtemps que vous le souhaitez.
Comment fonctionne la corrélation des logs avec mes métriques ?
Comment fonctionne la corrélation des logs avec mes métriques ?
Elastic stocke les métriques et les logs dans la même plateforme, de sorte que vous pouvez les interroger ensemble avec ES|QL, sans passer d'un outil ou d'un onglet à l'autre.
Comment l'IA Agentic aide-t-elle à résoudre les incidents ?
Comment l'IA Agentic aide-t-elle à résoudre les incidents ?
Plutôt que de parcourir manuellement les tableaux de bord, l'IA agentique d'Elastic analyse vos données d'observabilité pour guider les investigations, faire ressortir les causes profondes et exécuter des workflows de correction.
À quoi ressemble concrètement une migration ?
À quoi ressemble concrètement une migration ?
Les projets de migration ne s'étalent plus sur plusieurs mois. La prise en charge native de PromQL et d'OTel signifie que votre architecture d'ingestion existante, vos tableaux de bord et vos requêtes peuvent être migrés du jour au lendemain. Apprenez-en davantage sur nos outils de migration (actuellement en préversion technique).
Rejoignez la discussion
Connectez-vous à la communauté mondiale d'Elastic et participez à des conversations ouvertes et à la collaboration.

Posez des questions, obtenez des réponses et faites entendre votre voix sur notre forum ouvert.

.jpg)
