Surveillance des métriques basée sur la fiabilité de la plateforme Elasticsearch, reconnue par les SRE
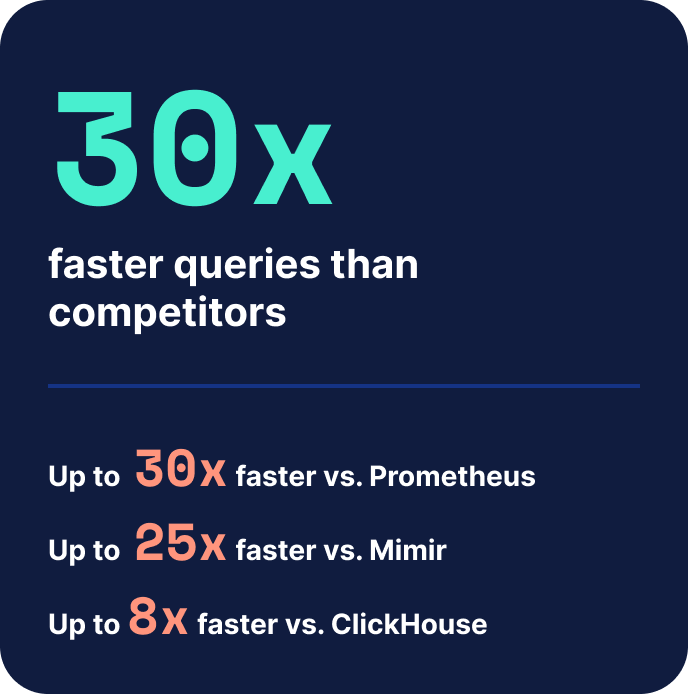
Elastic associe une efficacité de pointe en matière de métriques à la solution d'analyse de logs la plus complète du marché. Des requêtes jusqu'à 30 fois plus rapides que les bases de données de logs concurrentes, grâce à une architecture de datastore en colonnes conçue pour les charges de travail à forte cardinalité et évolutives à moindre coût. Avec PromQL natif, vous conservez vos workflows préférés.
Découvrez le moteur de métriques en colonnes qui est le meilleur de sa catégorie
Le datastore en colonnes Elasticsearch surpasse les concurrents en termes d’ingestion, de stockage et de rapidité de requête à n’importe quelle échelle.


Scaler sans perdre de données
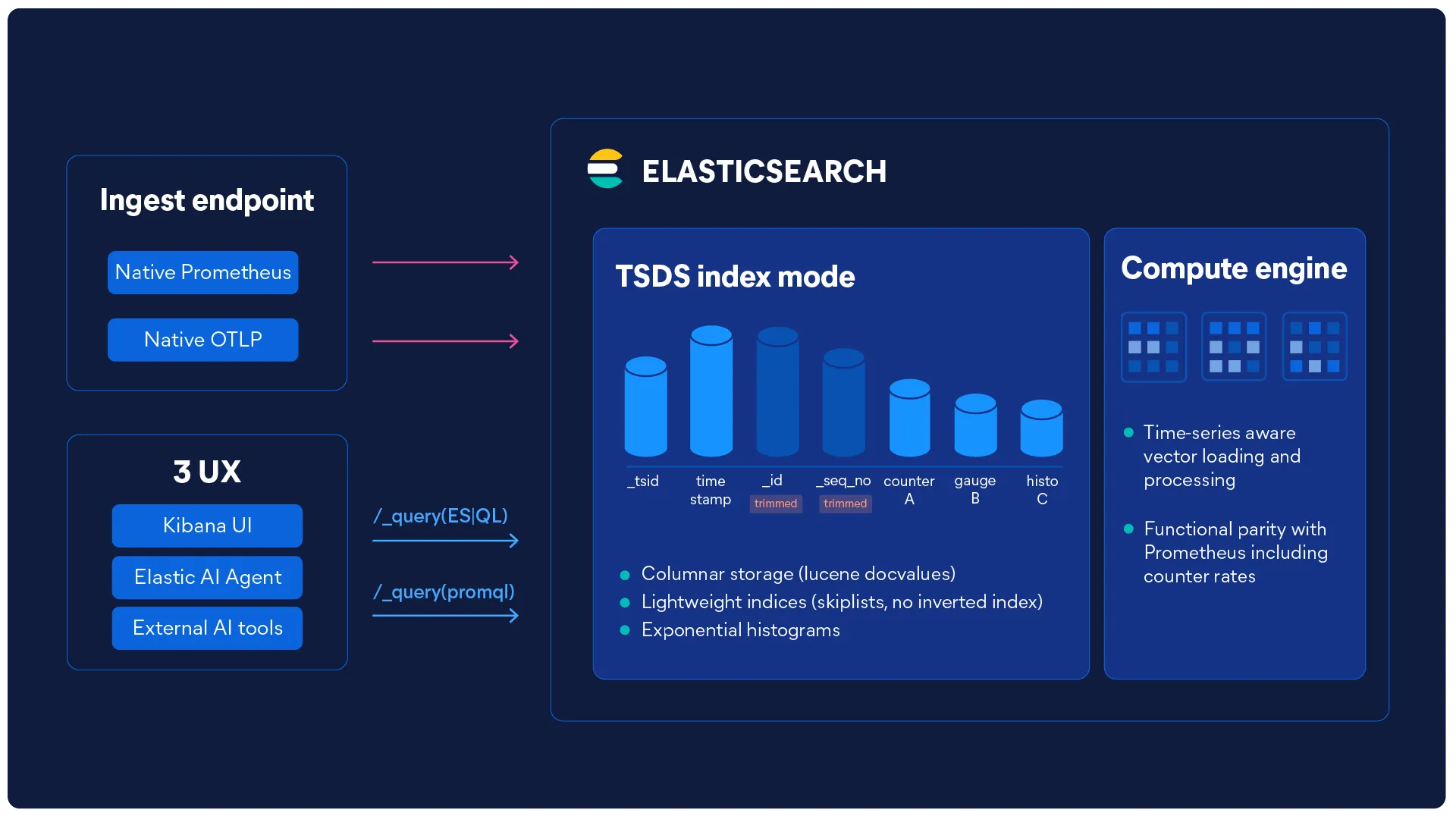
L’expertise technique qui a établi la norme en matière d’ingestion, de stockage et de performances des requêtes de log est précisément celle que nous avons mise en œuvre pour concevoir une base de données temporelles (TSDB) plus performante pour les métriques à forte cardinalité. Même équipe, même rigueur, nouveau type de données : une solution conçue pour conserver chaque métrique avec une résolution optimale, sans surcoût.




Elasticsearch n’analyse pas les lignes. Il lit les colonnes.
Le stockage par segments d'Elasticsearch est orienté colonnes par conception, garantissant des réponses sous la seconde pour des millions de séries temporelles avec chargement et traitement vectoriels.
BENCHMARKS ELASTICSEARCH 9.4
Ingénierie qui se manifeste dans les chiffres
Comparaison directe sur les trois indicateurs qui définissent une base de données de séries temporelles (TSDB) de qualité production : vitesse des requêtes, densité de stockage et débit d’ingestion
| Dimension | Elasticsearch 9.4 | Prometheus | Mimir | ClickHouse |
|---|---|---|---|---|
| Vitesse de requêteSéries chronologiques à haute cardinalité | Le plus rapide Référence |
Jusqu'à 30 fois plus lent | Jusqu'à 30 fois plus lent | Jusqu'à 8 fois plus lent |
| Densité de stockageOctets/échantillon | Meilleur 3,74 B |
~9,42 B | ~3,95 B | ~6,8 Md |
| Débit d'ingestionÉchantillons/seconde | Le plus rapide 428 K/s |
402K/s | 404K/s | ~300K/s |
| PromQL natif.Aucun adaptateur requis. | Natif | ✓ Natif | ✓ Natif | Nécessite un adaptateur |
| OTel natifAucune conversion de schéma | OTel-first | Via les exportateurs | Via les exportateurs | Mapping manuel |
L'INNOVATION AU CŒUR DU PROJET
Construction du moteur de métriques en colonnes Elasticsearch
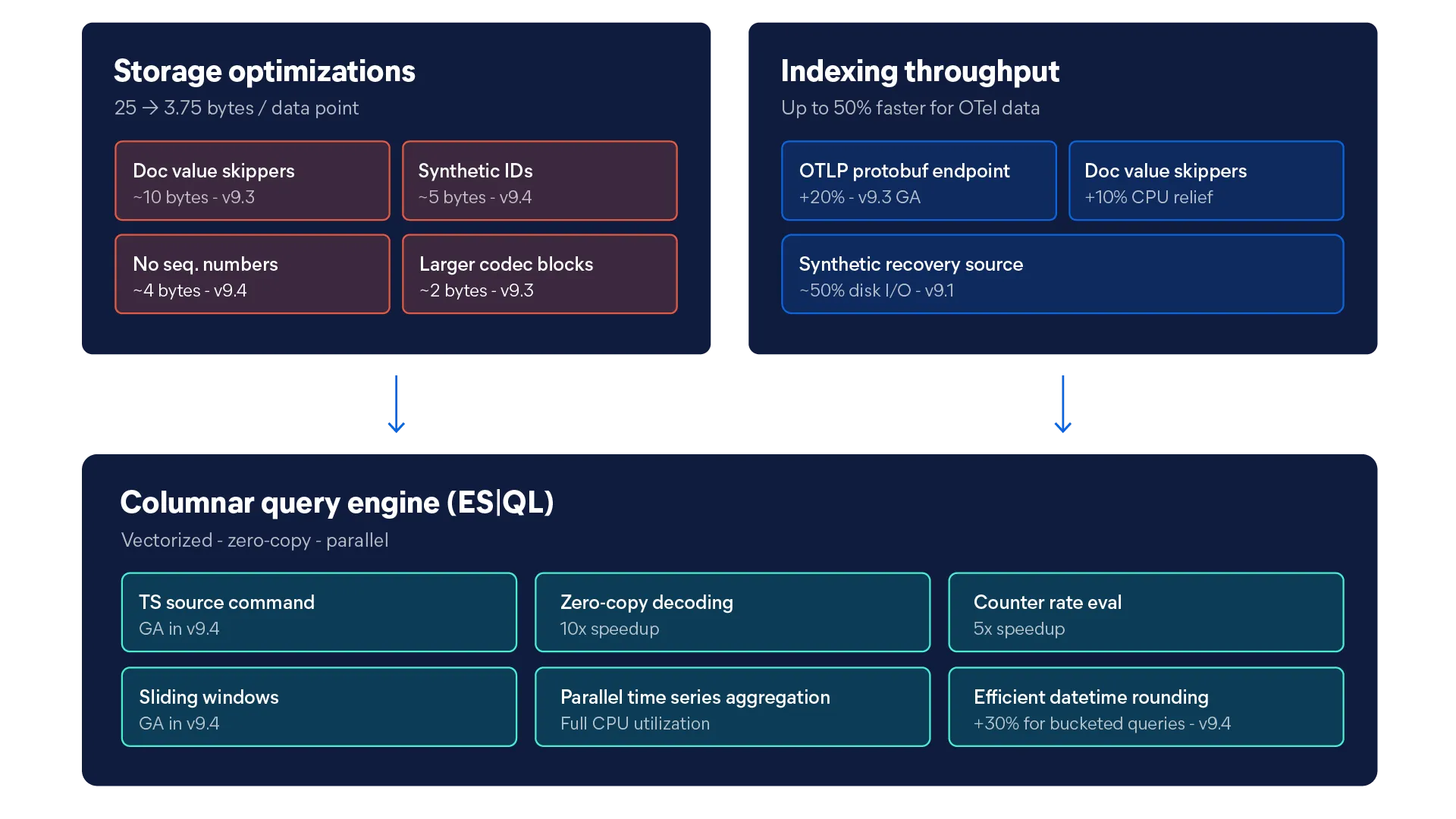
De l’architecture de stockage à l’exécution des requêtes, chaque partie de notre plateforme a été construite dans un but précis. Voici l’ingénierie qui en a fait une réalité.
Outil de migration – préversion technique
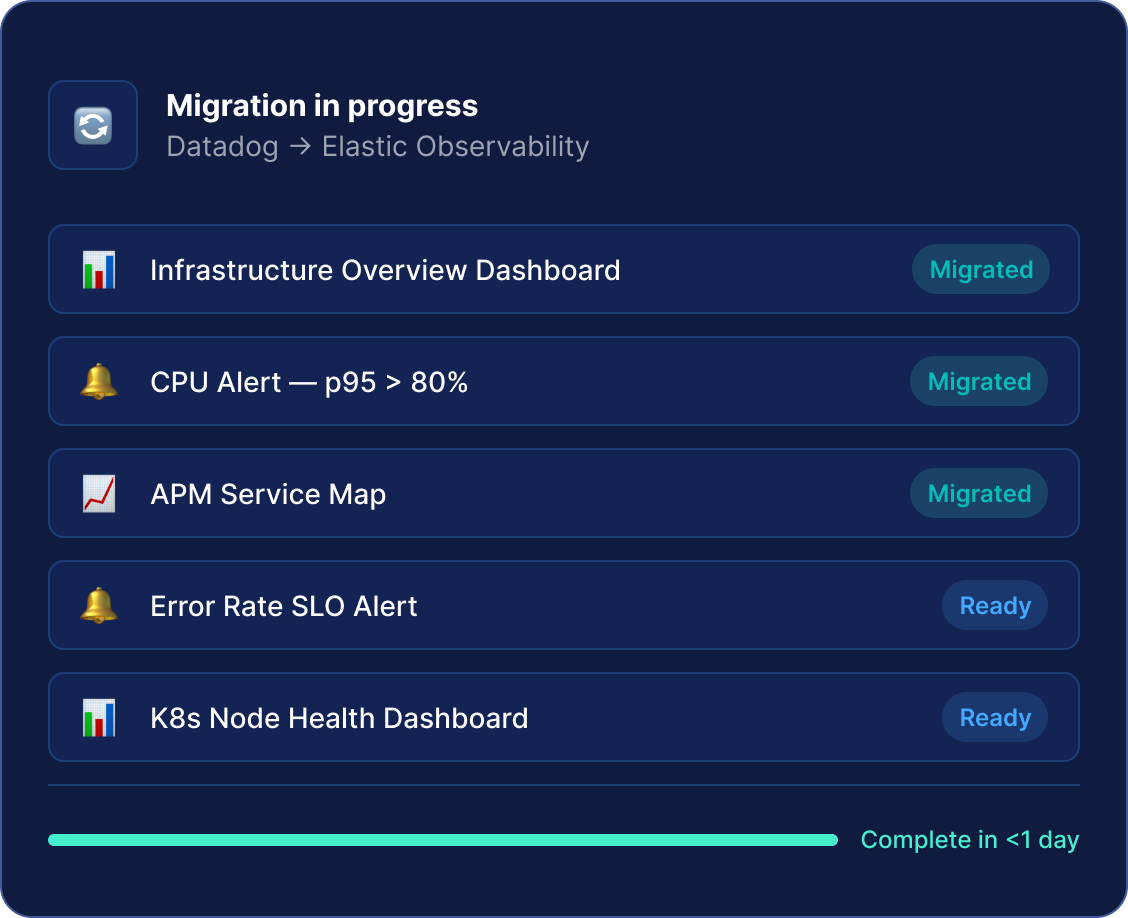
Migrez depuis Datadog ou Grafana du jour au lendemain
Convertissez automatiquement les tableaux de bord et les règles d’alerting de Datadog et Grafana en Elastic, réduisant considérablement le coût et la complexité du changement de plateforme.
Prêt à changer et à économiser 50 % sur votre facture de métriques Datadog ?
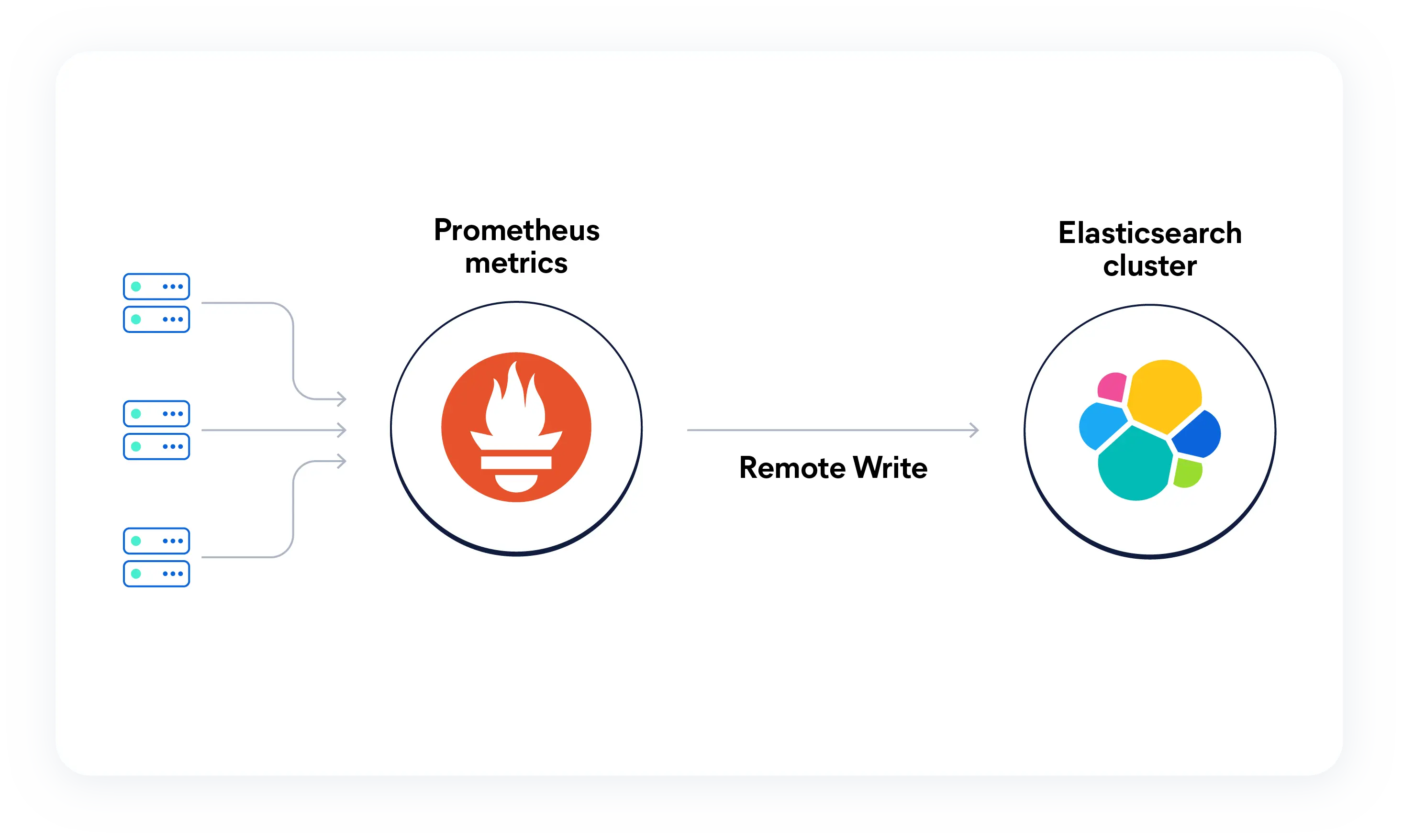
Transférez vos métriques Prometheus vers Elastic
Le point de terminaison Remote Write de Prometheus ne nécessite aucune configuration supplémentaire. Une fois les métriques transmises, vous pouvez les interroger avec ES|QL en utilisant la fonction PROMQL intégrée pour la compatibilité PromQL, ou écrire des requêtes ES|QL natives pour associer les métriques aux logs et aux traces dans le même espace de stockage.
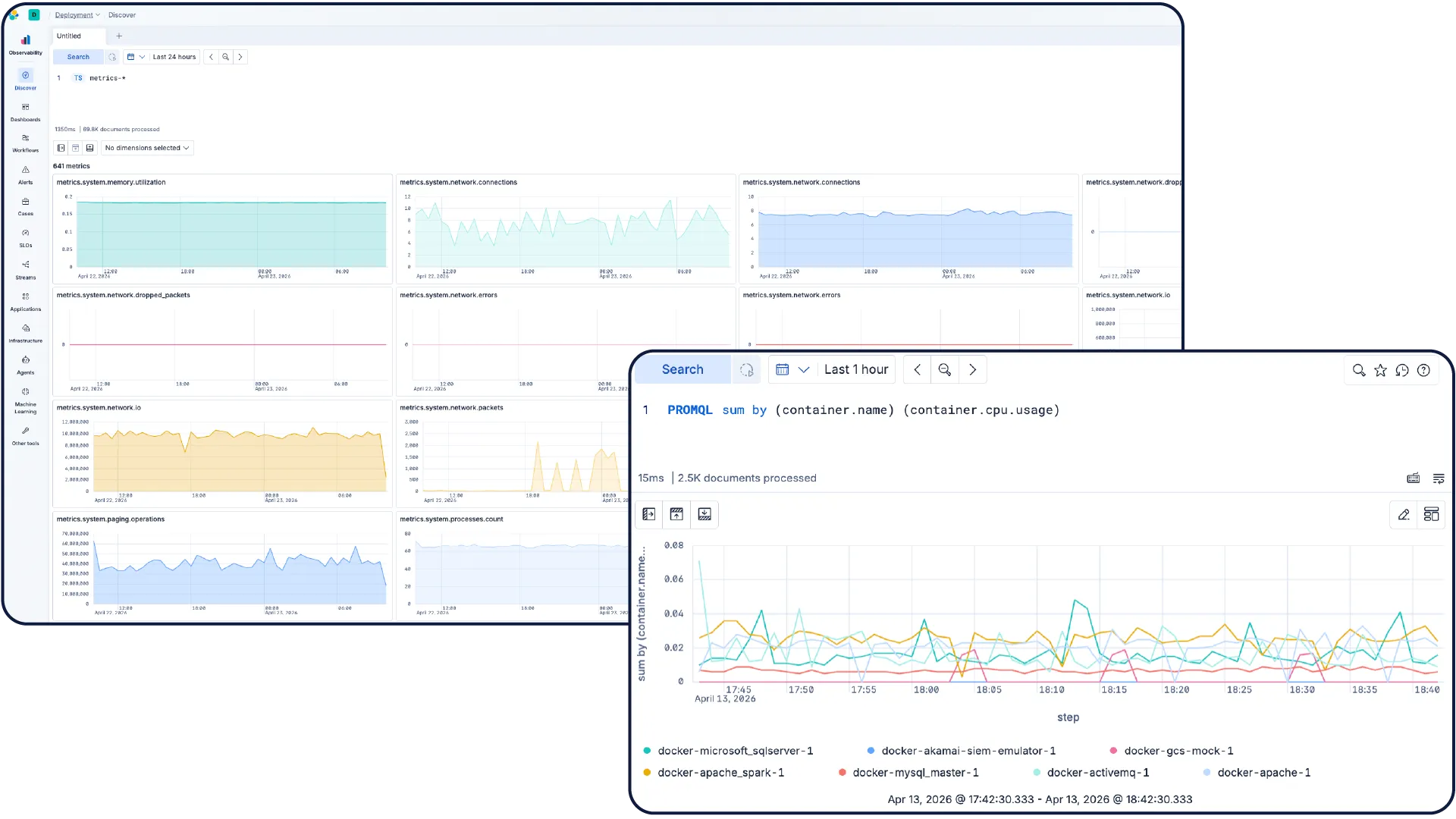
Convertissez les métriques en action
Surveillez votre infrastructure à grande échelle Explorez les métriques dans Discover, créez des tableaux de bord sous forme de code et laissez les enquêtes basées sur l’IA mettre en évidence les anomalies, découvrir les tendances et automatiser la correction, ce qui vous permet de planifier la capacité et de résoudre les problèmes plus rapidement.
Questions fréquentes
Elasticsearch peut-il remplacer Prometheus pour la surveillance des métriques ?
Elasticsearch peut-il remplacer Prometheus pour la surveillance des métriques ?
Oui. Elasticsearch inclut un point de terminaison Prometheus Remote Write natif, la prise en charge de PromQL via la fonction PROMQL intégrée dans ES|QL, ainsi qu'un moteur de métriques en colonnes conçu pour des séries temporelles à forte cardinalité. Les équipes peuvent migrer depuis Prometheus en une journée en convertissant automatiquement leurs tableaux de bord et règles d'alerte Grafana existants.
Comment Elasticsearch se situe-t-il par rapport à Prometheus en termes de vitesse de requête ?
Comment Elasticsearch se situe-t-il par rapport à Prometheus en termes de vitesse de requête ?
Dans les benchmarks Elasticsearch 9.4, Elasticsearch interroge des séries temporelles à forte cardinalité jusqu'à 30 fois plus rapidement que Prometheus. L'efficacité du stockage est également supérieure : Elasticsearch stocke les métriques à 3,74 octets par échantillon, contre environ 9,42 octets pour Prometheus.
Elasticsearch offre-t-il une prise en charge native des métriques OpenTelemetry (OTel) ?
Elasticsearch offre-t-il une prise en charge native des métriques OpenTelemetry (OTel) ?
Oui. Elasticsearch est OTel-first et intègre les métriques dans leur format OpenTelemetry natif sans conversion de schéma. Les formats Prometheus et Beats sont pris en charge nativement, chacun étant stocké en l'état sans couche de traduction.
Combien de temps faut-il pour migrer de Datadog ou Grafana vers Elasticsearch ?
Combien de temps faut-il pour migrer de Datadog ou Grafana vers Elasticsearch ?
Elastic propose un outil de migration (actuellement en préversion technique) qui convertit automatiquement les tableaux de bord et les règles d'alerting Datadog et Grafana au format Elastic/Kibana. Pour la migration Prometheus, la connexion de Prometheus Remote Write à Elasticsearch ne nécessite qu'une modification de configuration.
Qu'est-ce qu'une TSDB et pourquoi est-ce important pour la surveillance des métriques ?
Qu'est-ce qu'une TSDB et pourquoi est-ce important pour la surveillance des métriques ?
Une TSDB (base de données de séries temporelles) est une base de données optimisée pour stocker et interroger des données indexées dans le temps, comme les métriques d'infrastructure. Les flux de données de séries temporelles (TSDS) d'Elasticsearch utilisent un moteur de stockage en colonnes qui traite les données par lots et applique la suppression des identifiants synthétiques et le saut de valeurs doc afin de réduire la taille du stockage, ce qui la rend plus rapide et moins coûteuse que les alternatives traditionnelles basées sur les lignes.
Pourquoi le stockage en colonnes est-il plus rapide pour les requêtes de métriques ?
Pourquoi le stockage en colonnes est-il plus rapide pour les requêtes de métriques ?
Le stockage en colonnes accélère les requêtes de métriques car il ne lit que les colonnes de données pertinentes, au lieu d'analyser des lignes entières. Dans le cas de séries temporelles, la base de données peut ainsi extraire uniquement les valeurs nécessaires (par exemple, l'utilisation du processeur sur 24 heures) sans toucher aux champs non pertinents. Elasticsearch va plus loin grâce à un moteur de requêtes vectorisé qui traite les données par lots, permettant des temps de réponse inférieurs à la seconde, même pour des millions de séries temporelles à forte cardinalité.