Monitorer l'infrastructure et les microservices avec Elastic Observability
Les tendances de l'espace de l'infrastructure et des logiciels ont fait évoluer la façon dont nous concevons et exécutons des logiciels. Ainsi, nous avons commencé à traiter notre infrastructure en tant que code, ce qui nous a aidés à réduire les coûts et à mettre nos produits sur le marché plus rapidement. Ces nouvelles architectures nous permettent aussi de tester nos logiciels plus rapidement dans des déploiements semblables à la production, et, en général, de fournir des déploiements plus stables et reproductibles. Le revers de la médaille de ces améliorations est un renforcement de la complexité de nos environnements, en particulier pour ce qui est de monitorer efficacement nos nouvelles infrastructures.
Dans cet article, nous aborderons les éléments essentiels pour monitorer votre pile d'applications complète, y compris les applications personnalisées, les services et l'infrastructure sur laquelle ils s'exécutent. Nous montrerons aussi comment la solution Elastic Observability et la Suite Elastic peuvent aider à répondre à ces besoins et vous aider à construire la plateforme de monitoring idéale pour améliorer l'observabilité et réduire les temps d'indisponibilité. Lorsque vous serez prêts, vous pourrez démarrer un essai gratuit dans Elastic Cloud ou télécharger la version la plus récente sur notre site web pour vous lancer.
L'évolution des architectures : vers les conteneurs et microservices
Comment en sommes-nous arrivés là ? L'espace logiciel de l'infrastructure évolue très rapidement. Du point de vue matériel, nous sommes passés de machines physiques à divers outils de virtualisation (ou hyperviseurs), puis nous avons assisté à l'émergence d'infrastructures de cloud public qui nous ont permis d'externaliser la maintenance et le provisionnement des serveurs et des réseaux, ce qui nous a aidés à réduire le délai de rentabilisation. Je me souviens encore de l'époque où il fallait attendre des semaines avant qu'un nouveau serveur soit provisionné pour que nous puissions continuer nos projets. C'est peut-être encore le cas pour certains aujourd'hui, mais c'est un problème déjà résolu. Actuellement, les orchestrateurs de conteneurs, tels que Docker et Kubernetes, deviennent les plateformes de conteneurs préférées de nombreuses organisations. Bien sûr, beaucoup de ces organisations utilisent également la virtualisation sur des serveurs hôtes physiques.
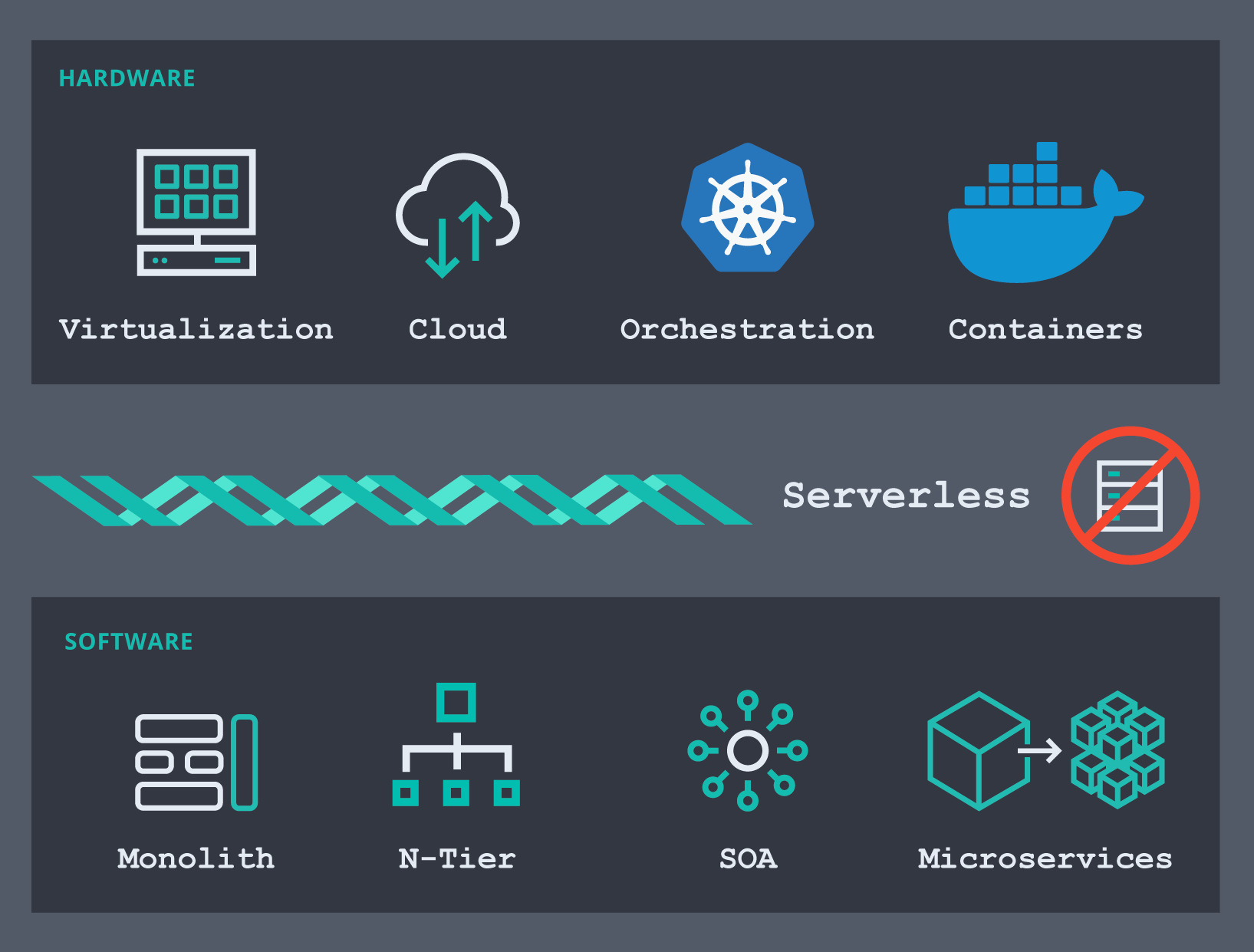
Pour ce qui est de la partie logicielle de cette chronologie, nous sommes passés de la construction de monolithes à leur séparation en plusieurs couches (présentation, application, données, etc.). Les architectures orientées services (SOA) sont ensuite devenues le modèle de conception dominant. Elles ont évolué à leur tour en différentes déclinaisons : services web, architectures pilotées par les événements, et bien sûr leur dernière incarnation : les microservices. Aujourd'hui, si vous souhaitez développer une nouvelle application, elle sera probablement basée sur des microservices qui s'exécutent dans des pods sur Kubernetes, quelque part dans le cloud. Il est probable que votre organisation dispose actuellement d'une ou de plusieurs initiatives pour décomposer les anciens monolithes en microservices et utiliser un orchestrateur pour les déployer.
Par conséquent, nos piles comportent désormais plus de composants à monitorer, et nos outils de monitoring doivent suivre des applications qui se déplacent en permanence, avec des conteneurs qui apparaissent et disparaissent rapidement. Le monitoring des environnements modernes a créé la nécessité d'une approche entièrement nouvelle.
Monitoring d'infrastructure : exigences pour les complexités modernes
Il faut tenir compte d'un certain nombre d'éléments lorsque l'on parle des environnements de déploiement actuels. Il y a l'infrastructure sur laquelle les éléments s'exécutent, que ce soit des centres de données sur site, une infrastructure de cloud public ou un mélange hybride. Tout environnement typique d'aujourd'hui dispose d'une couche d'orchestration (par exemple, Kubernetes) qui automatise le déploiement et la montée en charge des applications. Il y a les éléments sur ou dans lesquels nos applications s'exécutent, comme les conteneurs, les MV ou les serveurs physiques. Lorsque l'on développe des applications, on introduit des dépendances à des systèmes tiers tels que des services, bases de données ou composants externes créés par d'autres équipes de l'organisation. Et bien sûr, les applications en elles-mêmes, à la fois les composants internes et l'expérience utilisateur finale.
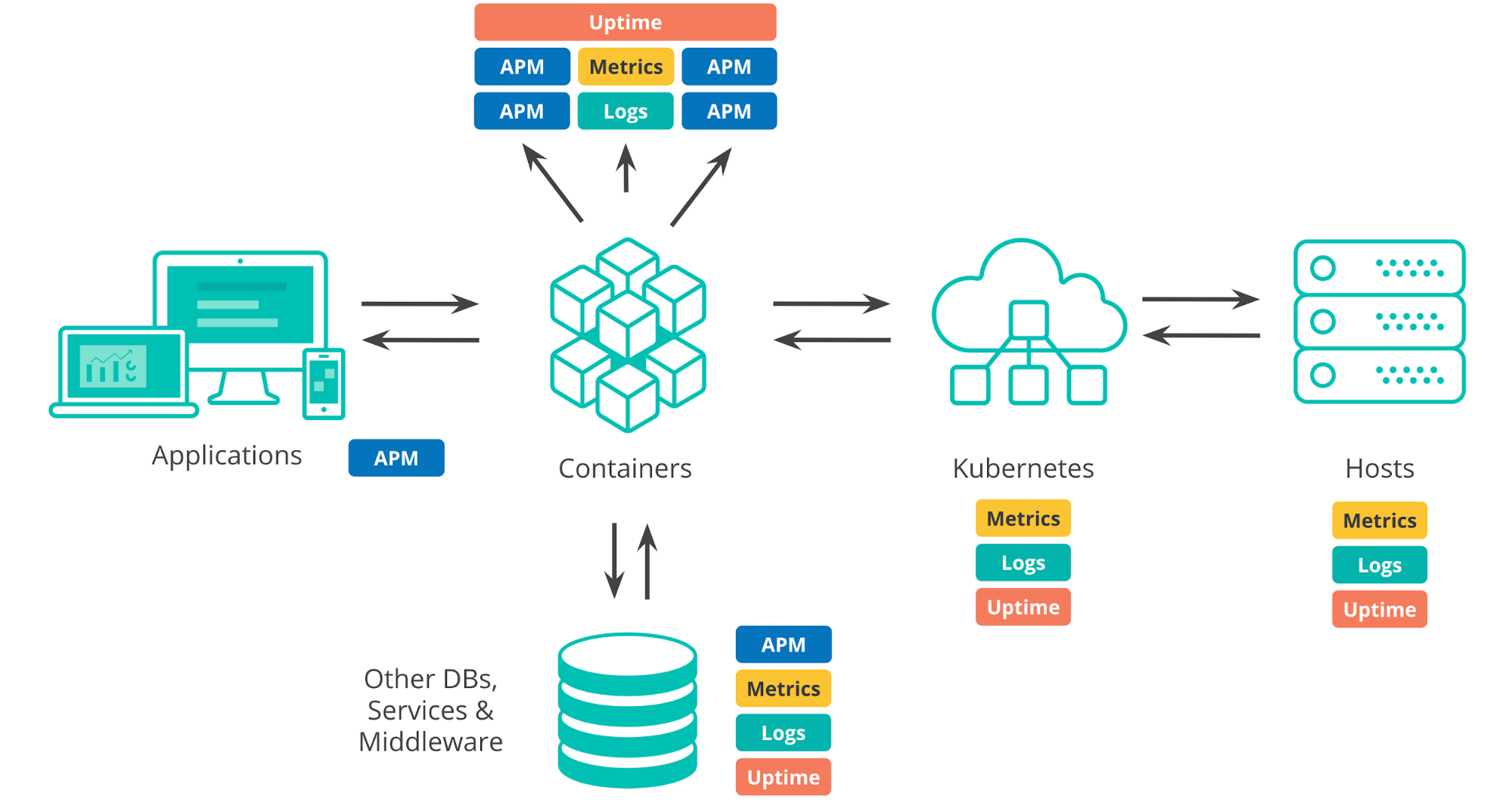
Pour nous assurer que nos applications fonctionnent correctement, nous devons monitorer tous ces composants qui, ensemble, produisent une grande quantité de données de monitoring : non seulement des logs et des indicateurs, mais aussi des données d'APM et de disponibilité.
Pour obtenir une visibilité totale sur ces déploiements, nous avons besoin d'une solution de monitoring capable de :
- supporter la totalité de l'infrastructure et de la pile applicative, des hôtes aux applications ;
- ingérer facilement des données provenant de différentes sources, telles que des MV, des conteneurs, des orchestrateurs, des plateformes cloud, des bases de données et bien plus encore (cela est généralement caractérisé par les intégrations avec d'autres systèmes fournis par une solution de monitoring) ;
- gérer la transition de plus en plus dynamique de déploiements en tant qu'environnements d'infrastructure vers des conteneurs, et, dans le même temps, gérer les parties de notre infrastructure traditionnelle plus ancienne ;
- nous fournir des moyens puissants pour interagir avec ces données opérationnelles et construire des aperçus optimisés pour chaque membre de l'organisation, des équipes DevOps aux détenteurs de produits et aux entrepreneurs ;
- nous informer si quelque chose ne va pas. L'alerting est l'un des blocs fondateurs de toute solution de monitoring et doit entièrement couvrir l'infrastructure ;
- permettre un stockage à long terme fiable pour les logs et les indicateurs aux fins d'analyse historique ou des exigences réglementaires. Cette solution de stockage doit également permettre de gérer le cycle de vie des données avec des taux de conservation et de granularité entièrement contrôlables ;
- être adaptée à l'observabilité des applications et de toute l'infrastructure. La plupart des outils de monitoring se spécialisent souvent dans un type de données : par exemple, de nombreuses bases de données chronologiques populaires (TSDB) ne fonctionnent qu'avec les indicateurs. Mais un environnement de déploiement typique produit toutes sortes de données : des logs, des indicateurs, des données d'APM et de disponibilité. Ces flux de données offrent des perspectives différentes sur la performance de nos environnements. Pourquoi traiter ces données séparément et maintenir différents outils ayant des courbes d'apprentissage, modèles de licence ou niveaux de support différents ?
- rassembler toutes les fonctionnalités précédentes en une seule solution de monitoring.
| Cette liste peut être résumée à deux exigences essentielles : une solution de monitoring d'infrastructure doit pouvoir obtenir les données opérationnelles à partir de tous les composants de l'infrastructure et elle doit les rendre exploitables. |
La Suite Elastic (Suite ELK) pour le monitoring d'infrastructure
L'évolution continue et l'augmentation de la puissance de monitoring requise pour observer efficacement les infrastructures actuelles nécessitent une solution rapide, scalable et flexible. Voyons comment Elastic répond à ces exigences.
Ingestion de logs et d'indicateurs
Elastic fournit des intégrations pour ingérer les données des logs et des indicateurs provenant de centaines de plateformes et de services. Non seulement ces intégrations permettent d'ajouter facilement de nouvelles sources de données, mais elles sont également fournies dès le départ avec des ressources telles que des tableaux de bord, plusieurs visualisations et des pipelines prédéfinis capables, par exemple, d'extraire des champs spécifiques dans les logs. Elastic fournit Metricbeat et Filebeat pour transférer les données des logs et des indicateurs dans la Suite Elastic. Toutes les intégrations compatibles avec Metricbeat et Filebeat comportent des instructions faciles à suivre directement dans Kibana.
Au fil de votre développement dans d'autres domaines de l'observabilité (et peut-être de la sécurité), vous devrez gérer encore plus d'agents de transfert et d'agents. La configuration et la gestion d'une flotte d'agents peuvent être compliquées, surtout dans les grands environnements d'entreprise : vous devrez gérer le déploiement des agents, mettre à jour les fichiers de configuration et gérer les données (ce que font déjà de nombreuses équipes aujourd'hui). Nous avons voulu améliorer cela. Dans la version 7.8, nous avons ajouté deux composants : Elastic Agent et Fleet, qui offrent une amélioration majeure pour l'envoi de données opérationnelles dans Elastic.
- Elastic Agent est un agent simple pour la collecte de logs, d'indicateurs et d'autres types de données. Il est beaucoup plus facile de l'installer et de le gérer que d'assurer manuellement la maintenance d'intégrations discrètes.
- Fleet est une nouvelle application Kibana qui vous aide à activer rapidement les intégrations pour les plateformes et services de votre choix et à gérer de manière centrale toute une flotte d'Elastic Agents.
Et vos outils de monitoring existants ? Si vous utilisez des services de monitoring cloud natifs comme Stackdriver, Azure Monitor, ou des outils tels que Prometheus ou statsd, et décidez de consolider vos indicateurs avec des logs et d'autres données, Elastic fournit également des intégrations dédiées pour ces outils de monitoring de haut niveau, ce qui vous permet de conserver votre instrumentation existante (par exemple, les exportateurs Prometheus) tout en stockant vos indicateurs avec vos autres données opérationnelles pour une meilleure observabilité.
J'ai mentionné plus haut que le passage aux déploiements conteneurisés nécessite de repenser la manière dont nous monitorons nos systèmes en général. Cela est particulièrement vrai pour les outils de monitoring traditionnels conçus pour gérer des hôtes physiques ou des machines virtuelles et des infrastructures statiques. Dans le monde des conteneurs, cette approche ne suffit plus, car tout est toujours en mouvement : les conteneurs montent et descendent, les services sont déployés plus fréquemment, et leurs adresses IP sont instables et peu fiables. De nombreux outils de monitoring ne sont pas conçus pour faire face à tout cela. Lorsque nous exécutons nos applications dans des conteneurs, elles deviennent des cibles mobiles pour un système de monitoring, ce qui génère une nécessité de détecter automatiquement les changements dans ces environnements, comme de nouveaux déploiements de services, des montées en charge des instances, ou des mises à niveau. La bonne nouvelle, c'est que Metricbeat et Filebeat sont dotés de capacités de découverte automatique capables de suivre vos déploiements, de détecter les changements et d'adapter la configuration pour monitorer les services dès le début de leur exécution.
Toutes les données collectées avec les intégrations d'Elastic sont conformes à l'Elastic Common Schema (ECS), qui sert de référence sur toutes les solutions Observability et Security d'Elastic. En quoi ECS est-il différent des autres modèles de données existants ? De par sa conception, ECS est optimisé pour être utilisé dans Elasticsearch. Il est open source et a été créé à partir de contributions de notre communauté mondiale. Et il tient compte de nombreux cas d'utilisation depuis le début, comme les indicateurs d'infrastructure et les logs, les APM, la sécurité et bien d'autres. Imaginez ECS comme le tissu conjonctif utilisé dans toutes les solutions d'Elastic pour relier, visualiser et analyser les différents flux de données de manière unifiée.
ECS n'est pas utilisé que par Elastic : de plus en plus d'entreprises adoptent ECS et l'enrichissent avec des schémas propres à leurs domaines pour leurs cas d'utilisation. Certaines organisations utilisent même ECS comme modèle de données commun dans leurs projets transversaux. Nous sommes ravis de voir ces exemples dans lesquels les solutions Elastic sont utilisées pour éliminer les silos organisationnels et rapprocher les équipes.
Stockage de logs et d'indicateurs
Pour ce qui est du stockage de données, Elasticsearch est surtout connu comme système de stockage pour les logs. Cela n'a rien de surprenant : le logging était pratiquement le premier cas d'utilisation d'Elasticsearch. Mais au fil du temps, nous avons constaté que de nombreux utilisateurs stockent des données temporelles avec leurs logs, ce qui est sensé. Si vous stockez des logs d'infrastructure et d'application, pourquoi ne pas aussi stocker des indicateurs qui vous disent quand consulter vos logs ?
Très tôt, nous avons commencé à investir dans Elasticsearch comme structure de stockage de données temporelles afin de permettre ces cas d'utilisation en ajoutant une structure en colonnes. Nous avons ensuite ajouté le cadre d'agrégations, qui permet de regrouper et de filtrer les indicateurs selon différentes dimensions. Pour améliorer notre capacité à gérer les données numériques et géographiques, nous avons lancé l'arborescence BKD et plusieurs autres fonctionnalités permettant de gérer efficacement les données temporelles. Ces fonctionnalités comprennent par exemple le cumul de données qui vous permet de réduire la granularité des données historiques (c'est-à-dire, procéder au sous-échantillonnage), ainsi que la gestion du cycle de vie des index grâce à laquelle vous pouvez contrôler différentes périodes de conservation pour différentes phases des données (hot, warm, cold et suppression, par exemple).
Transformation en données de monitoring exploitables
Visualisations
Imaginons que l'ingestion fonctionne et que les logs et indicateurs sont maintenant diffusés vers Elastic. La première chose à faire consiste à afficher ces données d'une manière pertinente. Certains outils de monitoring confient la création ou la recherche de visualisations de données à l'utilisateur, mais nous pensons que ces vues sont essentielles. C'est pourquoi Elastic fournit des visualisations et des tableaux de bord prédéfinis avec chaque intégration compatible. Cela signifie que dès que vous commencez à obtenir des logs ou des indicateurs, vous pouvez afficher rapidement un tableau de bord et voir immédiatement ce qui se passe sur vos systèmes et vos services.
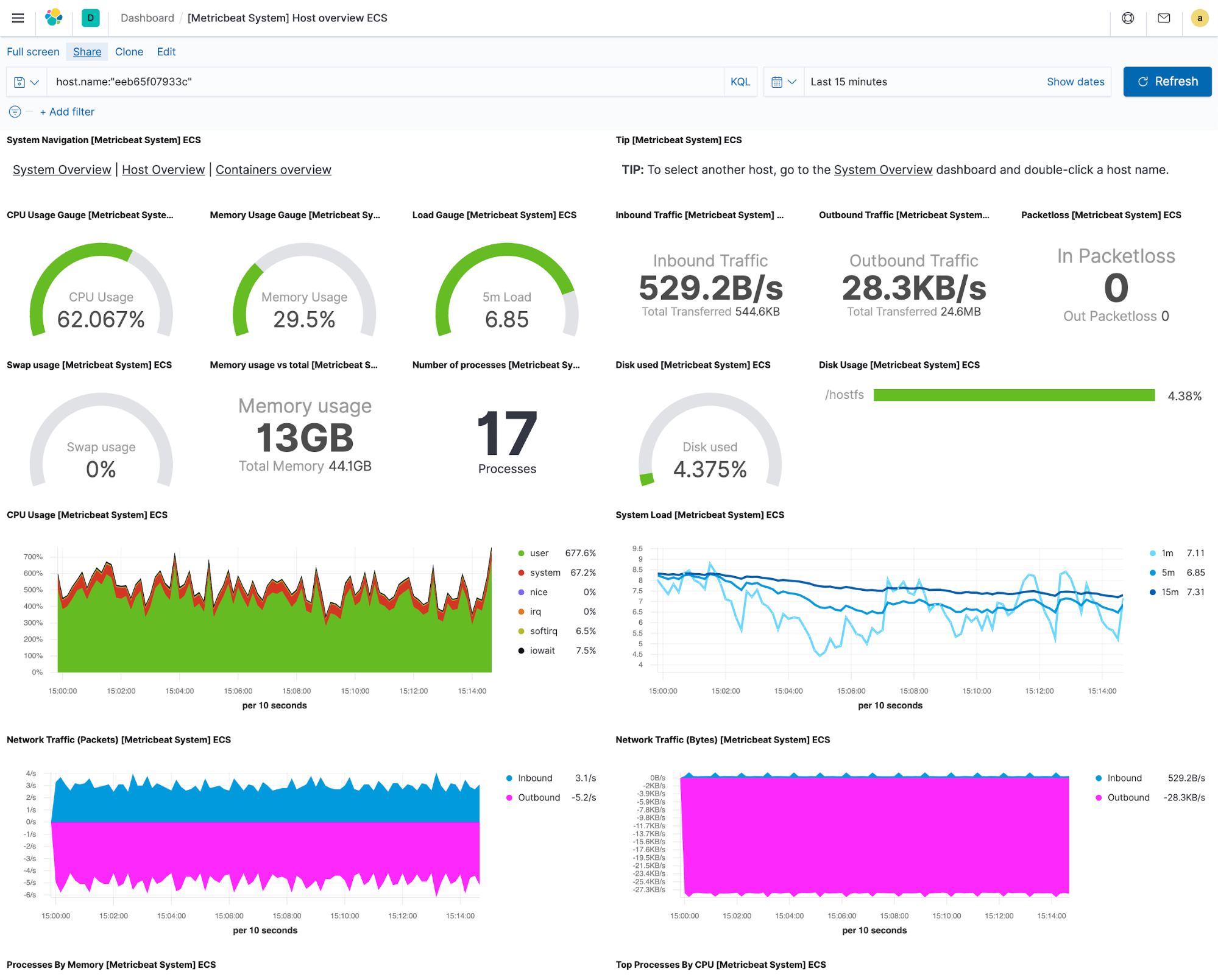
Toutes les visualisations qui composent le tableau de bord prédéfini sont réutilisables, ce qui signifie que vous pouvez choisir celles que vous trouvez particulièrement utiles et construire des tableaux de bord personnalisés répondant à vos besoins précis, en associant les éléments de différentes intégrations pour répondre aux questions que vous vous posez. De plus, vous pouvez également créer des menus déroulants personnalisés pour filtrer, ou des recherches pour naviguer d'un tableau de bord à l'autre sans perdre le contexte, ce qui est très pratique, car cela permet de rationaliser les workflows de résolution des problèmes.
En plus des tableaux de bord et des visualisations, Elastic offre des applications pertinentes pour les logs, les indicateurs et la disponibilité. Toutes sont conçues pour améliorer la visibilité de votre infrastructure.
L'application Metrics vous permet de visualiser toute votre infrastructure à un seul endroit. Peu importe que vous possédiez des centres de données distribués géographiquement, que vous exécutiez Kubernetes sur plusieurs clouds, ou que vous utilisiez une configuration mélangeant plusieurs éléments. Elle offre un point de surveillance unique pour toutes vos ressources, vous permettant de les regrouper par fournisseurs d'infrastructure, par zones géographiques, ou selon les champs de balises personnalisées que vous souhaitez utiliser pour distinguer vos environnements de mise en service de vos environnements de production. À partir de cette vue, vous pouvez accéder à des indicateurs plus détaillés et consulter les logs, la performance des applications ou les informations de disponibilité de n'importe quelle ressource. Tout cela est possible parce que la solution Elastic est utilisée comme datastore unique pour toutes les données opérationnelles, ce qui nous permet d'élaborer des vues pertinentes, de les relier entre elles pour simplifier la navigation, et de rationaliser l'expérience de monitoring de l'infrastructure.
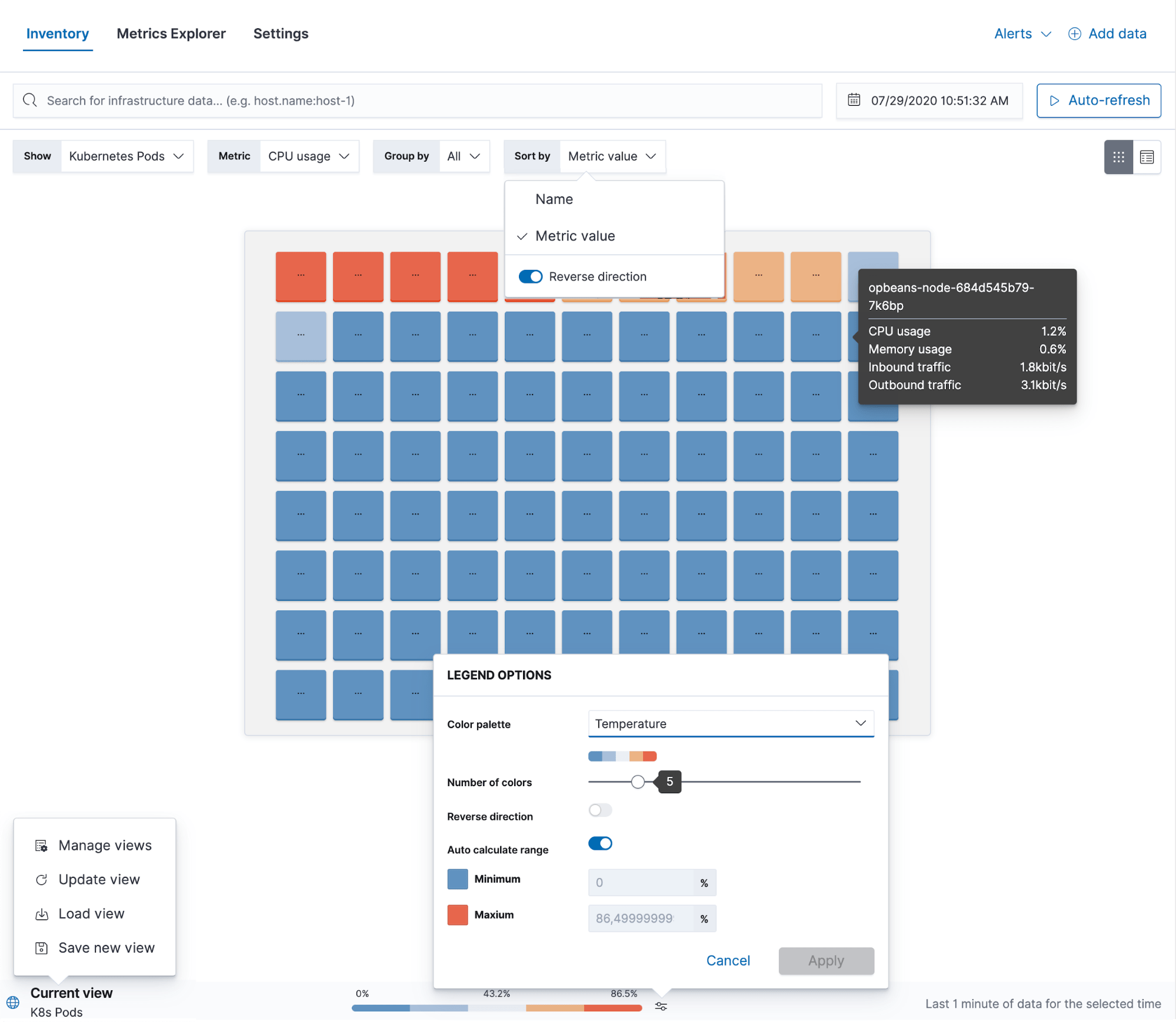
L'application Metrics comporte également un explorateur, Metrics Explorer, qui est particulièrement utile pour la résolution des problèmes : il vous permet de superposer plusieurs indicateurs pour déceler toute corrélation entre eux. Vous pouvez également y créer de nouvelles visualisations ou de nouveaux seuils d'alerte.
L'application Logs est une sorte de tail -f pour toute votre infrastructure : elle consolide tous les flux de logs et affiche les logs historiques et en temps réel sur une seule vue. En arrière-plan, les logs sont mis en corrélation avec les indicateurs, ce qui permet de suivre la piste beaucoup plus facilement lors de l'enquête sur les problèmes. Dans cette application, vous pouvez afficher les détails pour chaque ligne de log et voir ce qui s'est passé juste avant et juste après la rédaction de cette ligne. Comme pour toutes les autres applications d'observabilité dans Kibana, elle ne s'arrête pas aux vues en lecture seule et vous permet d'analyser et de prendre des mesures en cas d'événement suspect, grâce à la puissance de l'alerting et du machine learning.
Alerting
L'alerting est l'un des blocs fondateurs de pratiquement tous les cas d'utilisation de monitoring, car il aide à détecter et à répondre aux problèmes sur toute l'infrastructure. Grâce au nouveau cadre d'alerting dans Elastic, nous fournissons désormais plusieurs types d'alertes optimisés pour différents flux de données.
- Vous pouvez configurer facilement les alertes des indicateurs pour tous les types de déploiements, qu'ils soient physiques ou conteneurisés, ce qui signifie que ces alertes peuvent couvrir automatiquement les ressources qui viennent d'être créées. Grâce aux filtres, vous pouvez contrôler les parties de votre infrastructure qu'une alerte doit couvrir. Vous pouvez également configurer une alerte une fois, et faire en sorte qu'elle se divise automatiquement selon le champ de votre choix, par exemple, pour déclencher une alerte pour chaque hôte, ou pour chaque disque sur chaque hôte.
- Les alertes des logs sont optimisées pour les données de logs et vous permettent de créer des alertes basées sur des champs correspondant à une expression, ou sur la fréquence à laquelle un certain champ est enregistré dans un log.
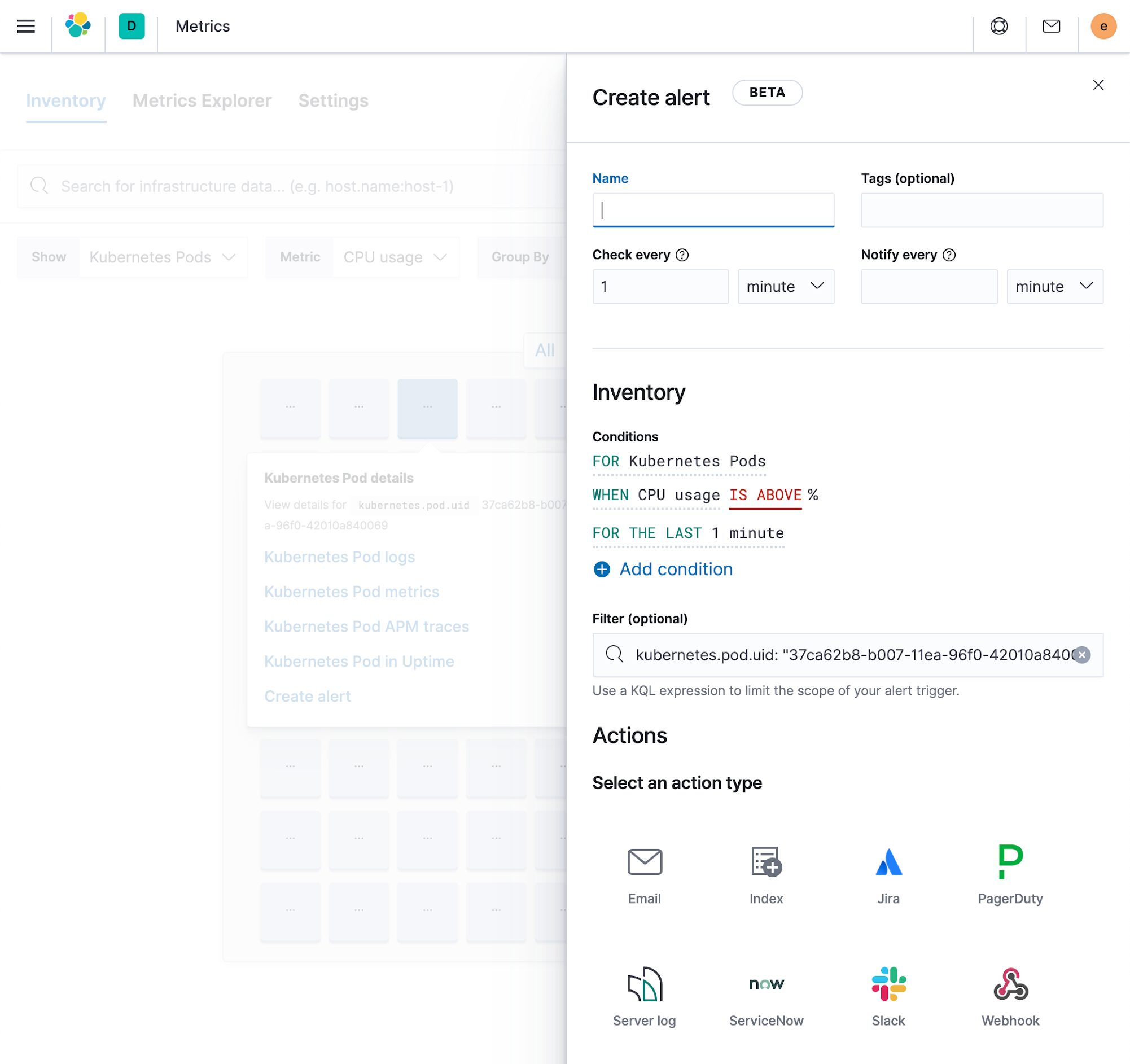
Toutes les alertes peuvent être créées et gérées depuis un point central dans Kibana, mais elles sont également intégrées aux applications respectives, ce qui facilite grandement leur utilisation au quotidien.
Machine learning et détection des anomalies
Les infrastructures actuelles produisent beaucoup de données opérationnelles qui ne cessent de croître, ce qui fait qu'il est pratiquement impossible d'analyser manuellement différents flux de données. Cela commence à poser problème aux organisations qui recherchent des moyens d'automatiser la détection des problèmes. Un élément important d'une solution de monitoring moderne est donc sa capacité à détecter automatiquement tout comportement anormal dans les environnements de déploiements avant qu'un problème se produise.
La bonne nouvelle, c'est qu'une fois que vos données opérationnelles sont dans Elasticsearch, elles sont prêtes à être analysées. Les tâches de machine learning prédéfinies pour la détection des anomalies sont déjà optimisées pour les logs et les indicateurs et intégrées avec les applications Kibana là où vous en avez besoin. Par exemple, elles peuvent détecter automatiquement la présence d'anomalies concernant la fréquence de génération des logs d'infrastructure, ou détecter les modèles et regrouper automatiquement vos logs en catégories.
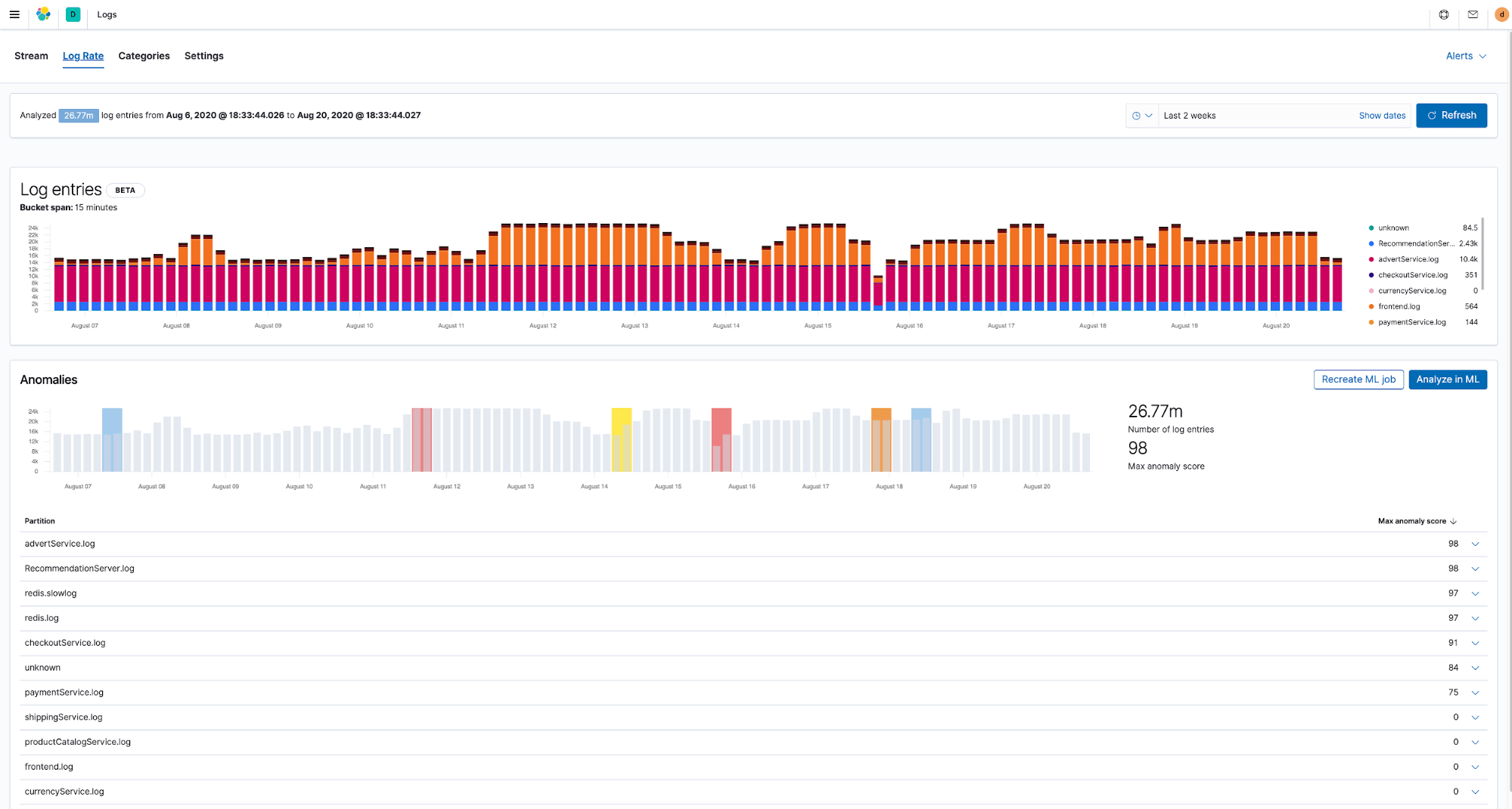
Les capacités de machine learning d'Elastic ne se limitent pas à la détection des anomalies. Vous pouvez utiliser d'autres algorithmes comme la classification, la détection des aberrations, et bien plus, sur une large gamme de cas d'utilisation impliquant des données d'infrastructure.
Multiplication de la valeur avec la Suite Elastic
Toutes les informations ne sont finalement qu'un autre index dans Elastic, et vous pouvez donc utiliser toutes les fonctionnalités d'Elastic avec vos données de monitoring. Avec les différentes visualisations dans Kibana, vous pouvez construire des vues pertinentes pour tous les membres de votre organisation, comme des tableaux de bord denses et flexibles construits avec Lens et TSVB (anciennement Constructeur visuel Time Series Visual Builder, un outil puissant pour élaborer des visualisations marquables d'histogrammes et d'indicateurs) que vos équipes d'ingénieurs trouvent utiles, ou des infographies en temps réel avec Canvas pour traduire les données complexes en tendances exploitables par les entrepreneurs.
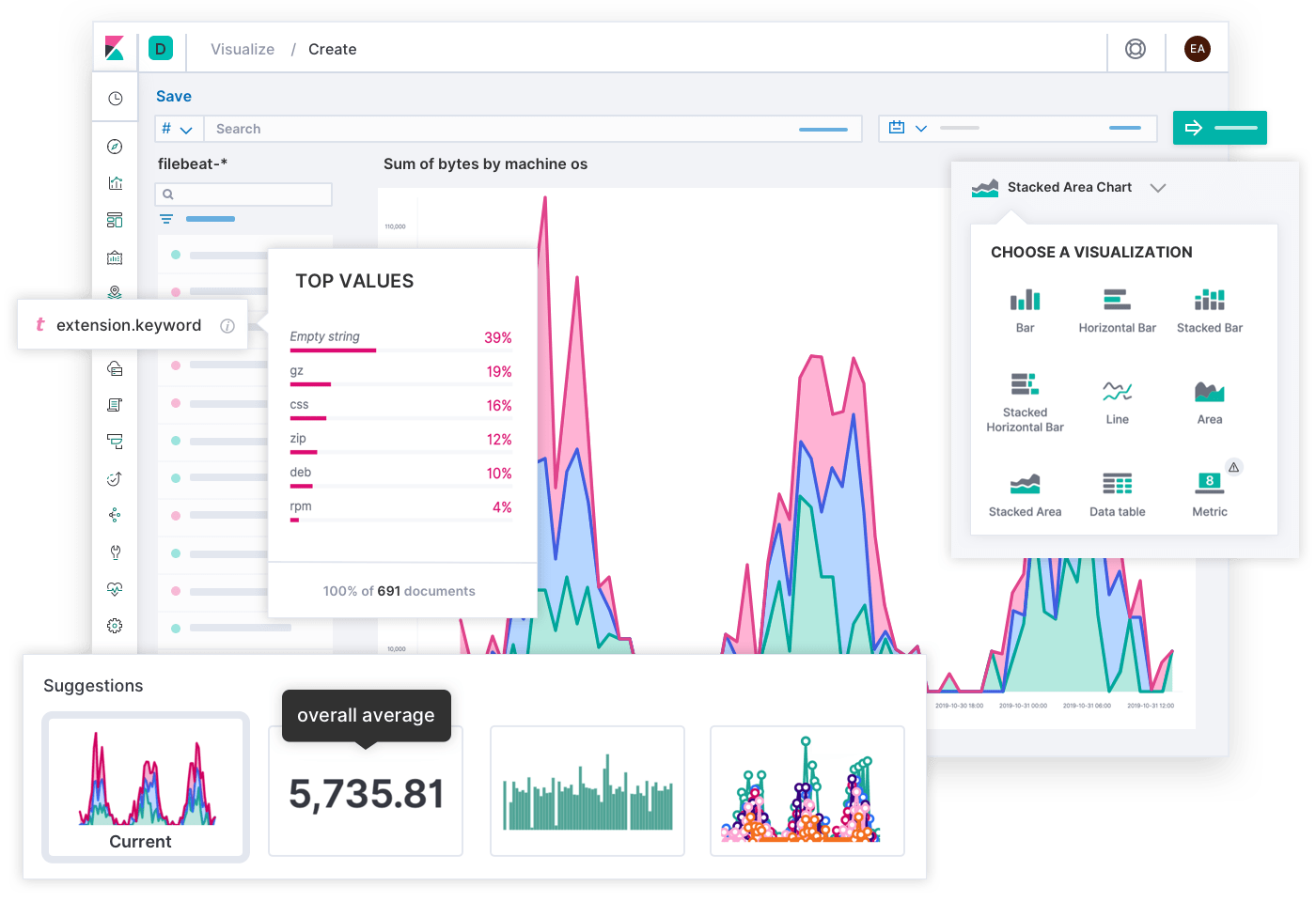
Tout ce que vous stockez dans Elastic est accessible à partir de l'interface utilisateur ou d'une API avec un langage de requête que vous connaissez, comme SQL ou PromQL. PromQL gagne en popularité et grâce à notre intégration de Prometheus, vous pouvez enregistrer les résultats de vos requêtes PromQL dans Elastic. Cela est particulièrement utile si vous ne souhaitez pas stocker d'indicateurs bruts et vous intéressez uniquement aux données déjà traitées.
Vous pouvez également combiner le monitoring d'infrastructure à la sécurité. La frontière entre l'observabilité et la sécurité est en train de disparaître, car nous utilisons finalement les mêmes données pour monitorer nos infrastructures et pour les sécuriser. La solution Elastic Security, tout comme Observability, repose au sommet de la Suite Elastic et vous permet de détecter et de prévenir facilement les menaces de sécurité sur vos infrastructures.
Conclusion
Dans cet article, nous avons énoncé les besoins en solutions de monitoring modernes et montré comment Elastic peut y répondre. La solution Elastic Observability et la Suite Elastic peuvent vous aider à mettre au point la plateforme de monitoring idéale, sur laquelle vous et vos équipes pouvez ingérer toutes vos données opérationnelles en toute sécurité, interagir avec elles, et atteindre la réussite.
Mais ne vous contentez pas de nous croire sur parole, jugez-en par vous-même. Déployez un cluster dans une version d'essai gratuite d'Elastic Cloud ou téléchargez la version la plus récente sur notre site web et dites-nous ce que vous en pensez.