Monitorer Prometheus à grande échelle avec la Suite Elastic
Ah, les outils ! En tant qu'ingénieurs, nous adorons tous les supers outils qui permettent à nos équipes de gagner en productivité, d'accélérer la résolution des problèmes et de s'améliorer. Le souci, c'est qu'ils sont sans cesse plus nombreux, qu'ils font exploser les tâches de maintenance et surtout, qu'ils ont tendance à générer des silos. Chaque équipe a ses responsabilités et recherche continuellement des outils qui pourront répondre au mieux à ses besoins spécifiques. Résultat :en tant qu'unités distinctes, les équipes gagnent en efficacité, mais cette autonomie, aussi performante soit-elle, entraîne aussi un manque de visibilité sur les autres entités de l'entreprise. Multiplié par le nombre d'équipes, cela engendre rapidement des clusters isolés : adieu, la vision holistique du fonctionnement de l'entreprise !
Prometheus illustre très bien ce type d'outils. Il s'est développé à une vitesse fulgurante, pour devenir l'outil de monitoring et d'alerting par excellence pour les systèmes de conteneurs. Son plus grand atout réside dans l'efficacité du monitoring et du stockage des indicateurs côté serveur. 100 % open source, Prometheus est soutenu par une communauté dynamique, qui étend ses capacités à de nombreux systèmes tiers via des exportateurs. Comme la plupart des outils spécialisés, Prometheus est conçu pour une simplicité d'utilisation optimale. Cette simplicité implique quelques compromis, notamment pour les grands déploiements et la collaboration entre équipes. Dans cet article de blog, nous examinerons certains de ces compromis et verrons comment la Suite Elastic peut contribuer à les résoudre.
Conservation des données à long terme
Prometheus stocke les données localement dans l'instance. Lorsque les capacités de calcul et le stockage des données sont regroupés sur un même nœud, cela peut, certes, simplifier les opérations, mais en revanche, cela complique la montée en charge et le maintien d'une haute disponibilité. Par conséquence, Prometheus n'est pas optimisé pour le stockage d'indicateurs à long terme. Selon la taille de votre environnement, le taux optimal de conservation des séries temporelles dans Prometheus peut aller de quelques jours à quelques heures à peine.
Pour conserver les données Prometheus à des fins d'analyse approfondie (saisonnalité des séries temporelles, par exemple), tout en assurant leur scalabilité et leur durabilité, vous devez compléter Prometheus par une solution de stockage à long terme. Et ce ne sont pas les solutions qui manquent – depuis les bases de données de séries temporelles (TSDB) spécialisées jusqu'aux bases de données en colonnes optimisées pour les séries temporelles. Mais bien qu'elles soient efficaces pour le stockage d'indicateurs, ces solutions présentent toutes un inconvénient : elles sont spécialisées pour un seul type d'indicateurs. Or, si les indicateurs jouent un rôle primordial pour vous éclairer sur le comportement de vos systèmes, ils ne sont néanmoins qu'un des éléments qui rendent vos systèmes observables.
Lorsqu'on pense "observabilité", on tente en général d'associer aux indicateurs d'autres types de données opérationnelles, telles que les logs ou les traces. Dans un article de blog consacré à l'observabilité dans la Suite Elastic, nous nous sommes penchés sur le nombre croissant de cas d'utilisation où les utilisateurs qui ont adopté la Suite Elastic pour les logs se mettent aussi à envoyer des indicateurs, des traces et des données de disponibilité vers Elasticsearch. Et ce n'est pas étonnant, puisque Elasticsearch traite tous ces types de données comme des index supplémentaires et vous permet d'agréger, de corréler, d'analyser et de visualiser l'ensemble de vos données opérationnelles comme bon vous semble. De plus, des fonctionnalités Elastic telles que le cumul de données vous permettent de stocker des données temporelles d'historique à un coût bien inférieur à celui des données brutes.
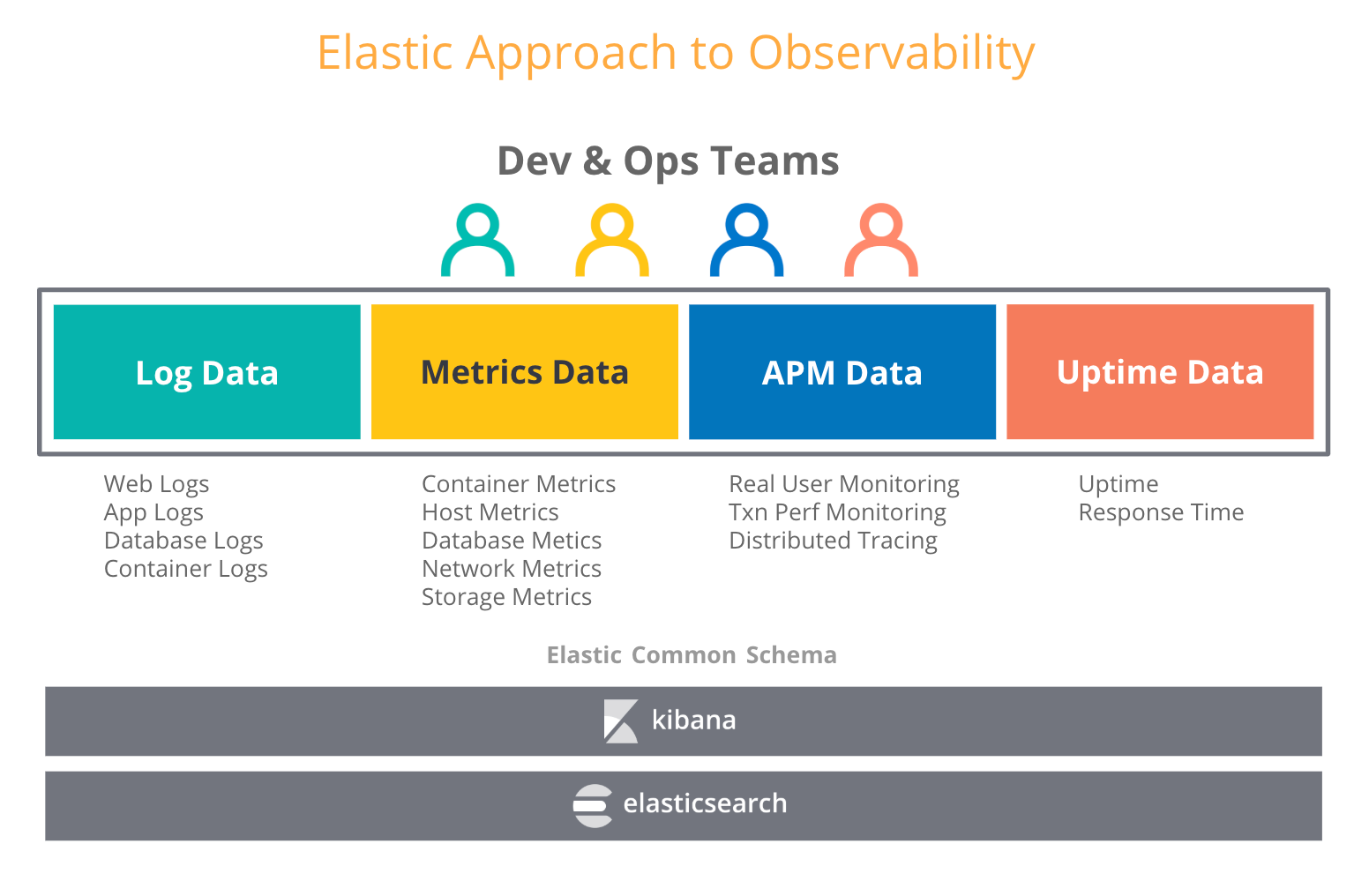
En quoi ces informations peuvent être utiles dans le choix d'une solution de stockage à long terme pour Prometheus ? Vous pouvez opter pour un stockage dédié aux indicateurs, qui vous permettra de conserver vos indicateurs Prometheus plus longtemps, tout en sachant que cela risque de générer un silo de plus. Mais vous pouvez aussi miser sur la Suite Elastic et associer le meilleur des deux mondes : exécuter Prometheus en périphérie, et conserver vos indicateurs pour la durée de votre choix avec d'autres données opérationnelles, dans un déploiement Elasticsearch scalable et centralisé. Autrement dit, vous faites le choix d'un stockage à long terme et d'une observabilité accrue.
Une vue globale et centralisée de vos données Prometheus
Dans une configuration de production, vous gérez probablement plusieurs clusters Kubernetes. Chacun des ces clusters s'exécute sur une ou plusieurs instances Prometheus qui peuvent connaître l'intégrité des nœuds, des pods et des points de terminaison.
Une instance Prometheus peut couvrir un sous-ensemble de ressources de votre environnement. Si votre question nécessite la recherche d'indicateurs provenant de différents clusters, Prometheus ne vous permet pas de le faire directement.

Lorsque vous utilisez Elastic pour le stockage centralisé de vos données, vous êtes en mesure de consolider les données provenant de centaines d'instances Prometheus, et vous avez une vue globale des données fournies par l'ensemble des ressources. Le module Prometheus de Metricbeat peut scraper automatiquement les indicateurs provenant des instances, des passerelles push, des exportateurs Prometheus et d'à peu près n'importe quel autre service compatible avec le format d'exposition Prometheus. Mieux encore : vous n'avez rien à modifier dans votre environnement de production. Vous êtes immédiatement opérationnel.
Dimensions à cardinalité élevée
Pourquoi la "haute cardinalité" est-elle importante ? Une cardinalité élevée vous permet d'ajouter à vos indicateurs un contexte arbitraire, comme des balises ou des libellés. La plupart du temps, vous avez besoin de conserver ces métadonnées, car elles peuvent s'avérer extrêmement utiles lorsque vous déboguez vos services. Tous ces identifiants de trace, de requête, de conteneur, ou ces numéros de version sont autant d'indices qui vous permettent de savoir ce qui se passe dans vos systèmes.

Les véritables bases de données de séries temporelles sont bien adaptées aux dimensions à faible cardinalité. L'efficacité de stockage annoncée par les bases de données de séries temporelles spécialisées sur Elasticsearch dépend en très grande partie des dimensions à faible cardinalité. Ainsi, la documentation Prometheus décourage vivement l'utilisation de données à cardinalité élevée :
"ATTENTION : N'oubliez pas que chaque combinaison unique de paires de libellés clé-valeur représente une nouvelle série temporelle, ce qui peut faire exploser le volume des données stockées. N'utilisez pas les libellés pour le stockage de dimensions à cardinalité élevée (qui implique grand nombre de valeurs de libellés différentes), comme les identifiants utilisateur, les adresses e-mail ou encore les ensembles de valeurs illimités."
Est-ce vraiment là un bon conseil ? Dans un environnement distribué, le débogage est une tâche très complexe. Autrefois, avec les monolithes, c'était un processus simple qui consistait à parcourir le code applicatif. Il suffisait de consulter quelques tableaux de bord pour identifier le module monolithique qui était à l'origine du problème. Mais tout cela a changé. Nous assistons à une évolution radicale des logiciels d'infrastructure. Conteneurs, orchestrateurs, microservices, maillage de services, informatique sans serveur, expressions lambda... Toutes ces technologies incroyablement prometteuses changent notre façon de développer et d'exploiter les logiciels. Par conséquent, ceux-ci deviennent de plus en plus distribués, et les déboguer revient à chercher une aiguille dans une meule de foin : savoir dans quelle partie du système se trouve le code défectueux n'est pas une mince affaire.
La haute cardinalité n'est pas un problème pour Elastic. Rien ne doit empêcher les utilisateurs d'ajouter du contexte pertinent à leurs données. Grâce à ses capacités d'indexation, Elasticsearch vous permet d'annoter les indicateurs comme bon vous semble, avec toutes les métadonnées nécessaires à la recherche des facteurs contributifs et à l'identification de la cause première. Le tout, aussi rapidement que possible.
La sécurité. Partout.
Ce qu'on attend d'un bon outil, c'est – a minima – qu'ils n'introduise pas de risques de sécurité dans notre environnement. La sécurité de tout déploiement distribué s'appuie sur deux composantes essentielles : le chiffrement des communications et le contrôle d'accès.
Au moment où nous rédigeons cet article, l'outil Alertmanager, le serveur, ainsi que les exportateurs officiels de Prometheus ne sont pas compatibles avec le chiffrement TLS des points de terminaison HTTP. Pour déployer ces composants de manière sécurisée, vous devez utiliser un proxy inverse tel que nginx et appliquer le chiffrement TLS au niveau du proxy. Le contrôle d'accès aux indicateurs basé sur les rôles doit aussi être géré en externe, et non directement par le serveur Prometheus. La bonne nouvelle, c'est que TLS et RBAC ne posent aucun problème si vous exécutez Prometheus dans un cluster Kubernetes, ce dernier proposant les deux. Mais dans tous les autres cas (comme l'exécution de centaines de serveurs Prometheus dans des déploiements géographiquement distribués ou hybrides), répondre à ces questions de sécurité au moyen d'outils tiers n'est pas une tâche aisée.
Chez Elastic, nous prenons de tels risques très au sérieux : la sécurité fait partie intégrante de notre Suite. Notre distribution par défaut intègre gratuitement des options de sécurité de base, et Elasticsearch propose de nombreuses façons de sécuriser l'accès aux données hébergées dans votre cluster, mais aussi de chiffrer le trafic entre le cluster et les agents de transfert de données. Outre le contrôle d'accès basé sur les rôles (RBAC), Elasticsearch prend aussi en charge un mécanisme de contrôle d'accès basé sur les attributs (ABAC) qui vous permet de limiter l'accès aux documents dans les requêtes de recherche et les agrégations. Grâce aux paramètres de configuration SSL de Metricbeat, vous êtes sûr que vos données opérationnelles transitent de manière sécurisée, quels que soient la taille et le degré de distribution de vos environnements.
Envoyer des flux d'indicateurs Prometheus vers Elasticsearch
Avec Metricbeat, vous pouvez immédiatement commencer à envoyer des flux d'indicateurs Prometheus vers Elasticsearch. Le module Prometheus vous permet de scraper des indicateurs depuis les serveurs, les exportateurs ou les passerelles push Prometheus, et ce, de différentes façons :
- Si vous exécutez déjà un serveur Prometheus et que vous voulez directement interroger ces indicateurs, vous pouvez commencer par vous connecter au serveur Prometheus et extraire les indicateurs déjà collectés via le point de terminaison
/metricsou l'API Prometheus Federation.
- Si vous n'avez pas de serveur Prometheus ou que vous préférez scraper vos exportateurs et vos passerelles push en parallèle via différents outils, vous pouvez vous y connecter directement.

Exécutez Metricbeat le plus près possible de votre serveur Prometheus. Pour choisir la configuration qui répond le mieux à vos besoins, vous pouvez consulter l'article de blog consacré à Prometheus et aux standards ouverts.
Surveiller l'intégrité de vos serveurs Prometheus
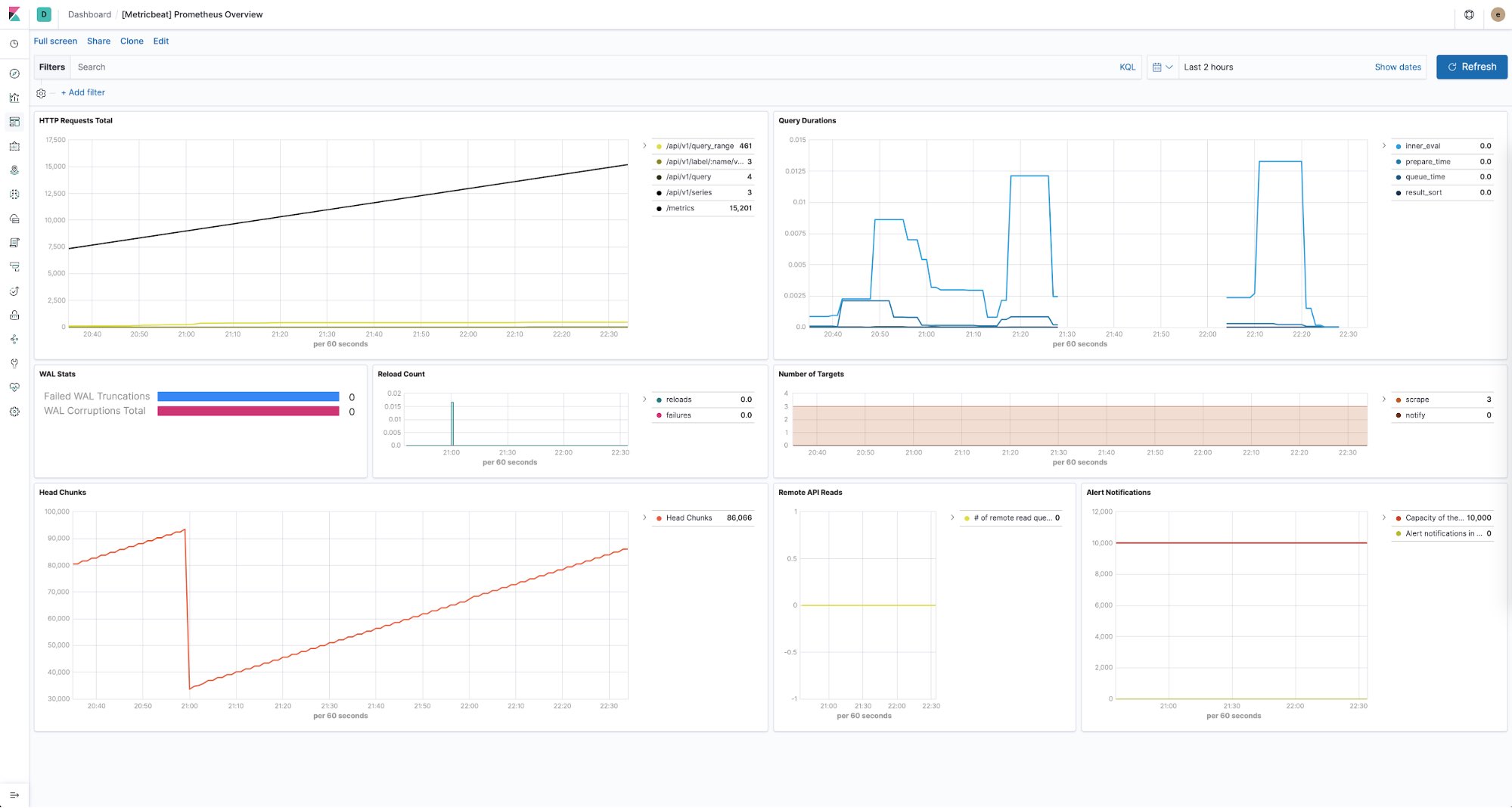
La Suite Elastic vous permet aussi de garder un œil sur l'intégrité de toutes vos instances Prometheus. En effet, vous pouvez utiliser Metricbeat pour collecter et stocker les indicateurs de performance fournis par chacun des serveurs Prometheus de vos environnements. Et grâce à des tableaux de bord prédéfinis immédiatement exploitables, vous affichez facilement des informations telles que le nombre de requêtes HTTP par point de terminaison, la durée des requêtes, le nombre de cibles découvertes, et plus encore.
Pour conclure
Au bout du compte, l'objectif (le vôtre, celui de votre équipe et de toute l'entreprise) est de réussir. Tous les outils ne sont qu'un moyen d'atteindre cette fin. Et chaque équipe doit être libre de choisir l'outil qui lui permettra d'exprimer tout son potentiel. Pour venir à bout des silos opérationnels, nous pensons que la Suite Elastic peut vous aider créer une plateforme d'observabilité incomparable, qui permet à tous vos collaborateurs d'accéder aux données opérationnelles de manière sécurisée, d'interagir avec elles, et de refaire équipe.
Pour en savoir plus sur nos méthodes de travail avec les données temporelles, n'hésitez pas à consultez la page web consacrée à Elastic Metrics. Vous pouvez aussi essayer d'envoyer des flux d'indicateurs vers Elasticsearch Service : c'est le moyen le plus simple et le plus rapide de se lancer. Et si vous avez des questions, vous pouvez nous faire signe sur nos forums de discussion.