La Suite Elastic et l'observabilité
Je suis responsable de produit pour l’observabilité chez Elastic. En général, quand j’emploie le terme « observabilité », j’obtiens différentes réactions. La plus courante, c’est qu’on me demande ce qu’est l’observabilité. Néanmoins, j’entends de plus en plus de gens me répondre qu’ils viennent de mettre en place une initiative d’observabilité, mais qu’ils ne savent pas exactement comment procéder. Enfin, j’ai eu aussi le plaisir de travailler avec des organisations pour qui l’observabilité fait partie intégrante de leur façon de concevoir et de fabriquer leurs produits et services.
Étant donné que ce concept prend de plus en plus d’ampleur, je me suis dit qu’il serait utile d’expliquer comment nous concevons l’observabilité chez Elastic, ce que nous avons appris de nos clients avant-gardistes, et comment nous l’envisageons du point de vue du produit lorsque nous faisons évoluer notre suite avec de nouveaux cas d'utilisation opérationnels.
L’observabilité, qu’est-ce que c’est ?
Ce n’est pas nous qui avons inventé le terme « observabilité ». Nous avons commencé à l’entendre dans la bouche de nos clients, principalement de ceux exerçant dans l’ingénierie de fiabilité des sites (SRE). D’après plusieurs sources, ce terme aurait été utilisé pour la première fois par des géants SRE de la Silicon Valley, comme Twitter. Et même si le livre précurseur de Google sur la SRE ne mentionne pas ce terme, il établit bon nombre de principes associés à l’observabilité aujourd’hui.
L’observabilité n’est pas un composant qu’on livre dans un paquet. C’est un attribut d’un système que vous construisez, au même titre que la facilité d’utilisation, la haute disponibilité et la stabilité. Lorsqu’on conçoit et qu’on fabrique un système « observable », l’objectif est de s’assurer que, lorsqu’il est mis en production, les opérateurs soient capables de détecter les comportements indésirables (p. ex. indisponibilité du service, erreurs, réponses lentes) et qu’ils disposent d’informations exploitables pour déterminer la cause du problème avec efficacité (p. ex. logs d’événements détaillés, informations granulaires sur l’utilisation des ressources, traces d’applications). Seulement, les entreprises se retrouvent parfois confrontées à des obstacles courants qui les empêchent d’atteindre cet objectif, parmi lesquels le manque d’informations, l’excédent d’informations non converties en renseignements exploitables, ou encore la fragmentation de l’accès à ces informations.
Le premier aspect que nous avons cité, à savoir la détection des comportements indésirables, démarre généralement par la configuration d’indicateurs et d’objectifs de niveau de service. Il s’agit de mesures de réussite mises en place en interne qui permettent de jauger les systèmes de production. Si une obligation contractuelle impose de respecter ces indicateurs et objectifs de niveau de service, un accord de niveau de service est alors mis en place. Parmi les exemples courants d’indicateurs de niveau de service, citons la disponibilité d’un système, pour laquelle vous pouvez définir un objectif de niveau de service de 99,999 %. La disponibilité d’un système représente aussi l’accord de niveau de service que l’on présente le plus souvent aux clients externes. Néanmoins, en interne, vos indicateurs et objectifs de niveau de service peuvent s’avérer bien plus granulaires, et ces facteurs critiques du comportement des systèmes de production sont soumis au monitoring et à l’alerting, lesquels constituent la base de toute initiative d’observabilité. Cet aspect de l’observabilité est également connu sous le nom de « monitoring ».
Le second aspect que nous avons évoqué, à savoir le fait de fournir des informations granulaires aux opérateurs pour déboguer les problèmes de production avec rapidité et efficacité, est un domaine qui est en constante évolution et qui donne naissance à de nombreuses innovations. Les « trois piliers de l’observabilité », c.-à-d. les indicateurs, les logs et les traces d’application, sont un vaste sujet sur lequel il y a beaucoup de choses à dire. Il est également avéré que le fait de collecter toutes ces données granulaires à l’aide d’outils divers et variés n’est pas forcément rentable, aussi bien d’un point de vue analytique que financier.
Les « piliers » de l’observabilité
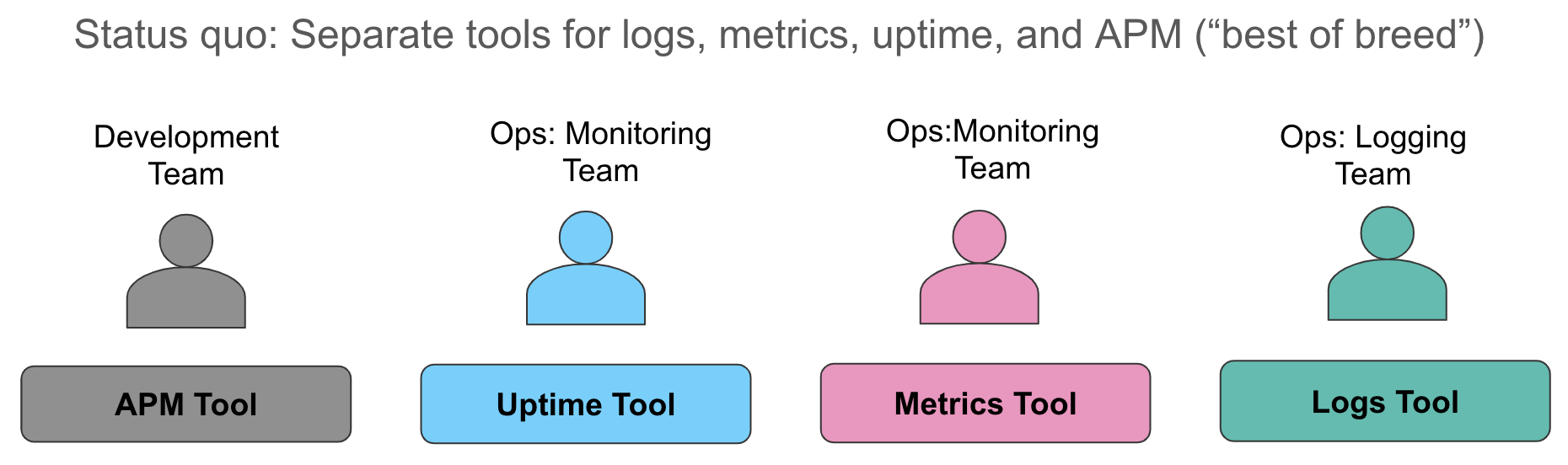
Étudions ces aspects de la collecte de données plus en détail. Voici comment nous avons tendance à procéder aujourd’hui : on collecte des indicateurs dans un premier système (en général une base de données temporelles ou un service SaaS pour le monitoring des ressources), on collecte les logs dans un deuxième système (sans surprise, la Suite ELK habituellement), puis on utilise encore un troisième outil pour instrumenter les applications, et ainsi, effectuer le traçage au niveau des requêtes. Lorsqu’une alerte se déclenche et révèle une violation d’un niveau de service, c’est un véritable branle-bas de combat ! Les opérateurs se ruent sur leurs systèmes et font du mieux qu’ils peuvent en jonglant entre les fenêtres : ils étudient les indicateurs dans l’une, les mettent en corrélation avec les logs manuellement dans une autre, et suivent les traces (au besoin) dans une troisième.
Cette approche comprend plusieurs inconvénients. Tout d’abord, la mise en corrélation manuelle de différentes sources de données racontant toutes la même histoire fait perdre un temps précieux lors de la dégradation ou de la panne du service. Ensuite, les frais engendrés par la gestion de trois datastores opérationnels sont élevés : coûts de licence, effectifs distincts pour les administrateurs d’outils opérationnels disparates, capacités de Machine Learning incohérentes dans chaque datastore, capacité de réflexion « éparpillée » concernant l’alerting... Chaque entreprise avec laquelle nous nous sommes entretenus lutte pour faire face à ces problématiques.
De plus en plus, les entreprises se rendent compte qu’il est important de disposer de toutes ces informations dans un magasin opérationnel unique, avec la possibilité de mettre automatiquement ces données en corrélation dans une interface utilisateur intuitive. L’idéal serait que les opérateurs puissent accéder à chaque donnée qui concerne leur service de façon unifiée, qu’il s’agisse d’une ligne de log émise par l’application, les données de trace résultant de l’instrumentation, ou l’utilisation d’une ressource représentée au moyen d’indicateurs dans une série temporelle. Le souhait qu’expriment régulièrement les utilisateurs serait de pouvoir disposer d’un accès ad-hoc uniforme à ces données, qu’elles proviennent d’une recherche avec filtrage, d’une agrégation ou encore d’une visualisation. Démarrer avec des indicateurs, explorer les logs et les traces en quelques clics sans que le contexte ne change, voilà ce qui permettrait d’accélérer l’investigation. De la même façon, on peut considérer les valeurs numériques extraites de logs structurés comme des indicateurs. Et le fait de comparer ces valeurs aux indicateurs est particulièrement intéressant d’un point de vue opérationnel.
Comme évoqué précédemment, si on se contente de collecter des données, on risque de se retrouver avec un volume trop important d’informations sur le disque, et pas assez de données exploitables lorsqu’un incident se produit. À côté de cela, on compte de plus en plus sur le système qui collecte les données opérationnelles pour détecter automatiquement des événements « intéressants », des traces et des anomalies dans le schéma d’une série temporelle. Cela permet aux opérateurs d’enquêter sur un problème en se concentrant sur sa cause plus rapidement. Cette capacité de détection des anomalies est parfois désignée comme le « quatrième pilier de l’observabilité ». La détection des anomalies dans les données de disponibilité, dans l’utilisation de ressources, dans les schémas de logging et dans la plupart des traces pertinentes fait partie des exigences émergentes mises en avant par les équipes d’observabilité.
Observabilité... et la Suite ELK ?
En quoi l’observabilité concerne-t-elle la Suite Elastic (ou la Suite ELK, comme on l’appelle dans les cercles opérationnels) ?
La Suite ELK est réputée pour être la solution incontournable pour centraliser les logs issus des systèmes opérationnels. On part du principe qu’Elasticsearch (un « moteur de recherche ») est l’outil idéal dans lequel importer des logs texte afin d’effectuer une recherche de texte libre. Et effectivement, rien que le fait de rechercher le mot « error » dans les logs texte ou de filtrer les logs en fonction d’un ensemble de balises bien connu donne déjà des résultats très pertinents. C’est d’ailleurs par là que commencent généralement les utilisateurs.
L’utilisation d’Elasticsearch en tant que datastore permet de bénéficier d’un index inversé proposant des capacités efficaces de recherche de texte intégral et de filtrage simple. Mais comme la plupart des utilisateurs de la Suite ELK le savent, ses avantages vont bien au-delà. Il contient également une structure en colonnes optimisée pour le stockage et qui fonctionne dans une série temporelle numérique dense. Cette structure en colonnes sert à stocker les données structurelles venant des logs analysés, qu’il s’agisse de chaînes ou de valeurs numériques. Pour tout vous dire, ce qui nous a incités à la base à optimiser Elasticsearch en vue d’un stockage efficace et de l’extraction des valeurs numériques, c’est le cas d'utilisation qui impliquait de convertir les logs en indicateurs.
Au fil du temps, les utilisateurs ont commencé à importer des séries temporelles numériques directement dans Elasticsearch, venant remplacer les bases de données existantes des séries temporelles. Guidé par ce besoin, Elastic a récemment introduit Metricbeat pour la collecte automatisée d’indicateurs, le concept de cumuls automatiques et d’autres fonctionnalités spécifiques aux indicateurs, aussi bien dans le datastore que dans l’interface utilisateur. Résultat : un nombre croissant d’utilisateurs qui avaient adopté la Suite ELK pour les logs ont également commencé à importer des données d’indicateurs, comme l’utilisation de ressource, dans la Suite Elastic. En plus des économies opérationnelles déjà mentionnées ci-dessus, une autre raison poussant les utilisateurs à se tourner vers Elasticsearch est le manque de restrictions que cette solution applique à la cardinalité des champs éligibles aux agrégations numériques (un souci courant lorsque l’on évoque la plupart des bases de données temporelles existantes).
À l’instar des indicateurs, les données de disponibilité représentent un type de données extrêmement important avec les logs, fournissant une source conséquente d’alertes relatives aux indicateurs et objectifs de niveau de service depuis un moniteur. Les données de disponibilité peuvent fournir des informations sur la dégradation des services, des API et des sites web, souvent avant que les utilisateurs n’en ressentent l’impact. Autre avantage : les données de disponibilité prennent très peu de place en termes de stockage. Elles présentent donc une grande valeur pour un coût supplémentaire minime.
L’année dernière, Elastic a aussi introduit Elastic APM, une solution qui ajoute le traçage d’applications et le traçage distribué à la suite. Pour nous, il s’agissait d’une évolution naturelle, étant donné que plusieurs projets open source et fournisseurs APM réputés se servaient déjà d’Elasticsearch pour stocker et rechercher les données de trace. En général, les outils APM traditionnels séparent les données de trace APM des logs et des indicateurs, ce qui crée des silos de données opérationnelles. Elastic APM propose un ensemble d’agents pour collecter des données de trace à partir de langages et de frameworks pris en charge, ainsi que pour prendre en charge OpenTracing. Les données de trace recueillies sont automatiquement mises en corrélation avec les indicateurs et les logs.
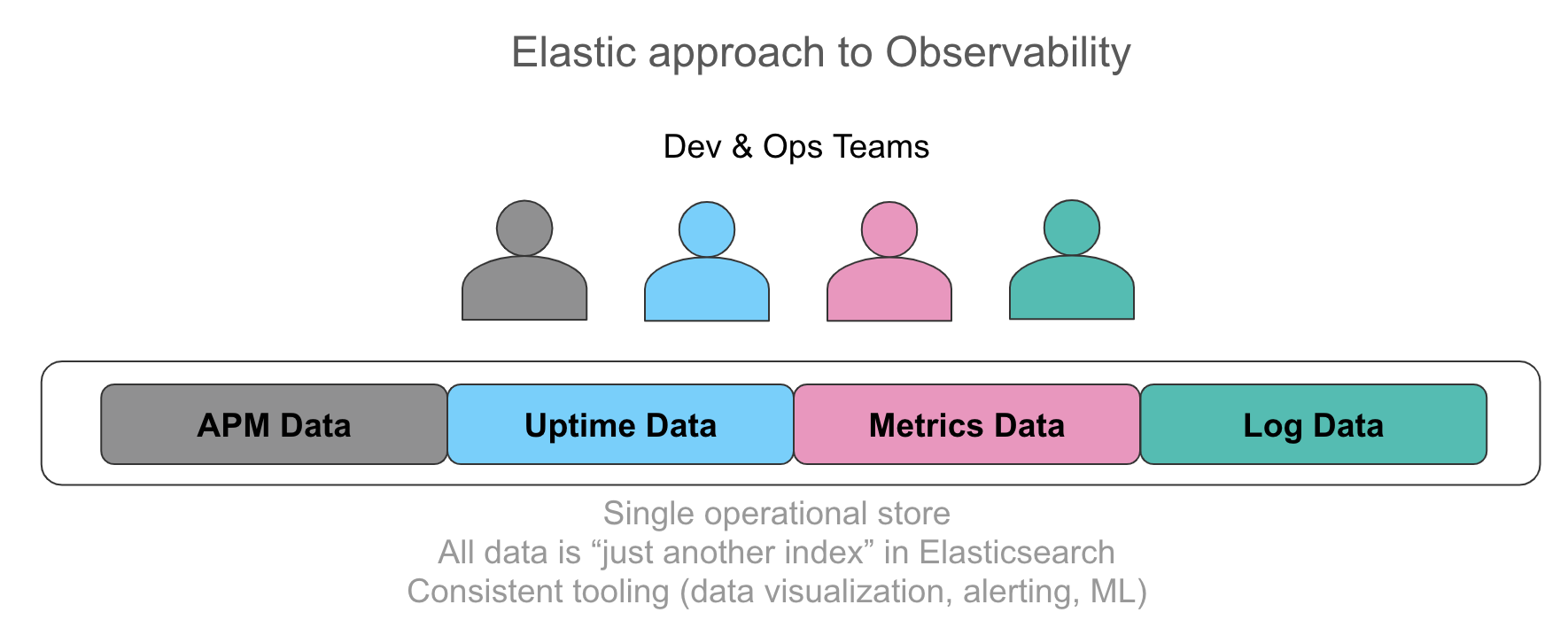
Le fil conducteur qui relie ces entrées de données est que chacune d’elles constitue un index d’Elasticsearch. Il n’y a aucune restriction sur les agrégations que vous exécutez sur ces données, sur la façon dont vous les visualisez dans Kibana et sur la manière dans l’alerting et le Machine Learning s’appliquent à chaque source de données. Pour en voir une démonstration, regardez cette vidéo.
Kubernetes observable et la Suite Elastic
L’une des communautés dans laquelle le concept d’observabilité est un sujet récurrent de conversation, c’est celle des utilisateurs qui adoptent Kubernetes pour l’orchestration des conteneurs. Ces utilisateurs « cloud native », terme popularisé par la Cloud Native Computing Foundation (ou CNCF), font face à des défis uniques. Ils se retrouvent confrontés à une centralisation massive d’applications et de services s’appuyant sur, ou ayant migrés vers, une plate-forme d’orchestration de conteneurs propulsée par Kubernetes. Ils constatent également qu’il existe une tendance à diviser les applications monolithiques en « microservices ». Les outils et méthodes qui donnaient auparavant la visibilité nécessaire sur les applications exécutées sur cette infrastructure sont désormais obsolètes.
L’observabilité sur Kubernetes mériterait de faire l’objet d’un article à part entière. De ce fait, nous vous invitons à consulter le webinar sur le Kubernetes observable et l’article sur le traçage distribué avec Elastic APM pour en savoir plus.
Et ensuite ?
Pour approfondir un sujet comme celui abordé ici, il nous semble essentiel de vous donner quelques clés pour poursuivre.
Pour en savoir davantage sur les bonnes pratiques de l’observabilité, nous vous recommandons de commencer par lire le livre dont nous avons parlé précédemment, le livre de Google sur la SRE. Ensuite, nous vous invitons à vous pencher sur les articles rédigés par des entreprises pour lesquelles il est essentiel que les applications critiques fonctionnent en continu pour la production. Ces articles donnent généralement matière à réflexion. Par exemple, cet article de l’équipe d’ingénierie Salesforce fait office de guide pragmatique et pratique pour améliorer l’état de l’observabilité de façon itérative.
Pour tester les capacités de la Suite Elastic dans le cadre de vos initiatives d’observabilité, tournez-vous vers la dernière version de notre suite sur Elasticsearch Service sur Elastic Cloud (un sandbox idéal même si vous effectuez un déploiement auto-géré au final) ou téléchargez et installez les composants de la Suite Elastic en local. Pensez à consulter les nouvelles interfaces utilisateur pour les logs, le monitoring d’infrastructure, APM et la disponibilité (prochainement dans la version 6.7) dans Kibana; qui sont conçues spécialement pour les workflows d’observabilité courants. Et n’hésitez pas à nous solliciter sur les forums de discussion si vous avez des questions. Nous sommes là pour vous aider !