Traçage distribué, OpenTracing et Elastic APM
L’univers des microservices
C’est un fait : les entreprises se tournent de plus en plus vers des architectures de microservices, qu’elles développent et déploient davantage chaque jour. Souvent, ces services sont développés dans différents langages de programmation, déployés dans des conteneurs d’exécution distincts et gérés par plusieurs équipes et organisations. Les grandes entreprises comme Twitter disposent de dizaines de milliers de microservices, œuvrant tous dans un même but : atteindre les objectifs de l’entreprise. Comme l’explique cet article de blog de Twitter, pour pouvoir déterminer rapidement la cause d’un problème, il est extrêmement important d’avoir de la visibilité sur l’état et les performances des différents services au sein de la topologie. Cela contribuera également à améliorer la fiabilité et l’efficacité globales de Twitter.
C’est là que le traçage distribué peut apporter une aide véritablement précieuse, en prenant en charge deux problématiques fondamentales auxquelles les microservices sont confrontés :
- Suivi de la latence
Une demande ou transaction utilisateur peut passer par plusieurs services dans différents environnements d’exécution. Il est nécessaire de comprendre la latence de chacun de ces services pour comprendre les caractéristiques de performances globales du système dans son ensemble. De là, vous pourrez également déterminer où apporter des améliorations. - Analyse de la cause d’un problème
L’analyse de la cause d’un problème est une tâche ardue, en particulier pour les applications soutenues par de grands écosystèmes de microservices. Un service peut à tout moment présenter une défaillance. Le traçage distribué joue un rôle crucial pour déboguer les problèmes dans une telle situation.
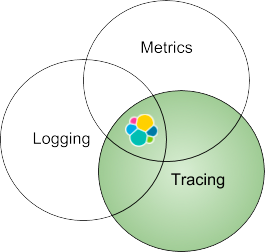
Mais revenons un peu en arrière. Le traçage est l’un des éléments des trois piliers de l’observabilité, avec le logging et les indicateurs. Comme nous l’avons déjà évoqué, la Suite Elastic est une plate-forme unifiée regroupant les trois piliers de l’observabilité. Lorsque les logs, les indicateurs et les données APM sont stockés dans le même référentiel, puis analysés et mis en corrélation, vous obtenez des informations contextuelles optimales sur vos applications et systèmes métier. Dans cet article, nous nous intéresserons uniquement au traçage.
Traçage distribué avec Elastic APM
Elastic APM est un système de monitoring des performances applicatives basé sur la Suite Elastic. Il vous permet de monitorer les applications et les services logiciels en temps réel, en recueillant des informations de performances détaillées sur le temps de réponse des demandes entrantes, les requêtes de bases de données, les appels de caches, les requêtes HTTP externes, etc. Les agents Elastic APM proposent une instrumentation automatisée enrichie prête à l’emploi (p. ex. temporisation des requêtes db etc.) pour les frameworks et les technologies pris en charge. Vous pouvez également utiliser une instrumentation personnalisée pour remplir des objectifs bien précis. Ainsi, il sera bien plus facile de détecter les problèmes de performances et de les résoudre rapidement.
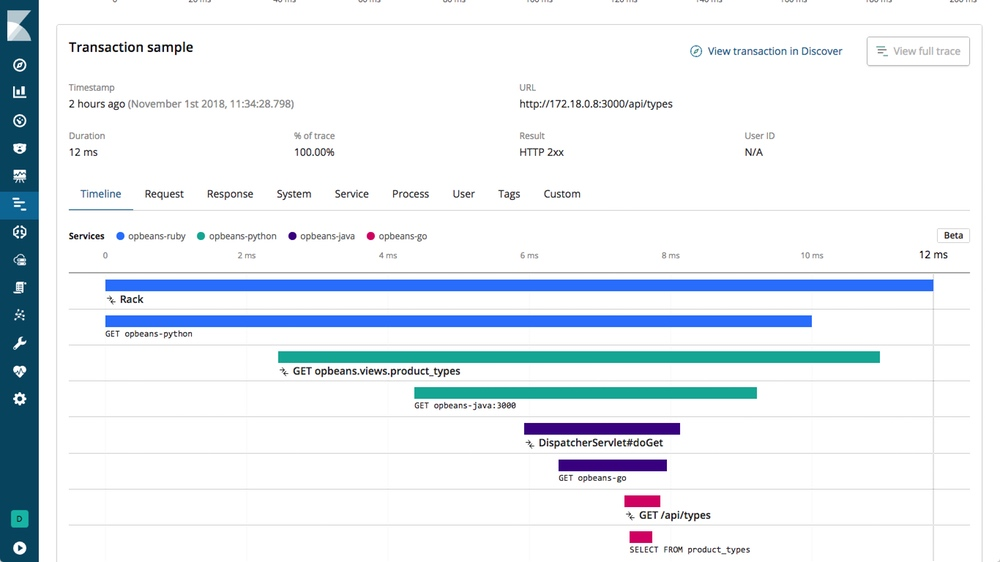
Elastic APM prend en charge le traçage distribué et est compatible avec OpenTracing. Cette solution vous permet d’analyser les performances de l’ensemble de votre architecture de microservices, le tout dans une seule vue. Pour cela, Elastic APM trace toutes les requêtes, depuis la requête Web initiale vers votre service front-end, jusqu’aux requêtes envoyées à vos services de back-end. Ainsi, vous repérez les goulots d’étranglement potentiels dans votre application avec plus de facilité et de rapidité. Dans l’interface utilisateur d’APM, les transactions effectuées dans le cadre de services connectés sont affichées sous forme de cascade chronologique dans une trace :
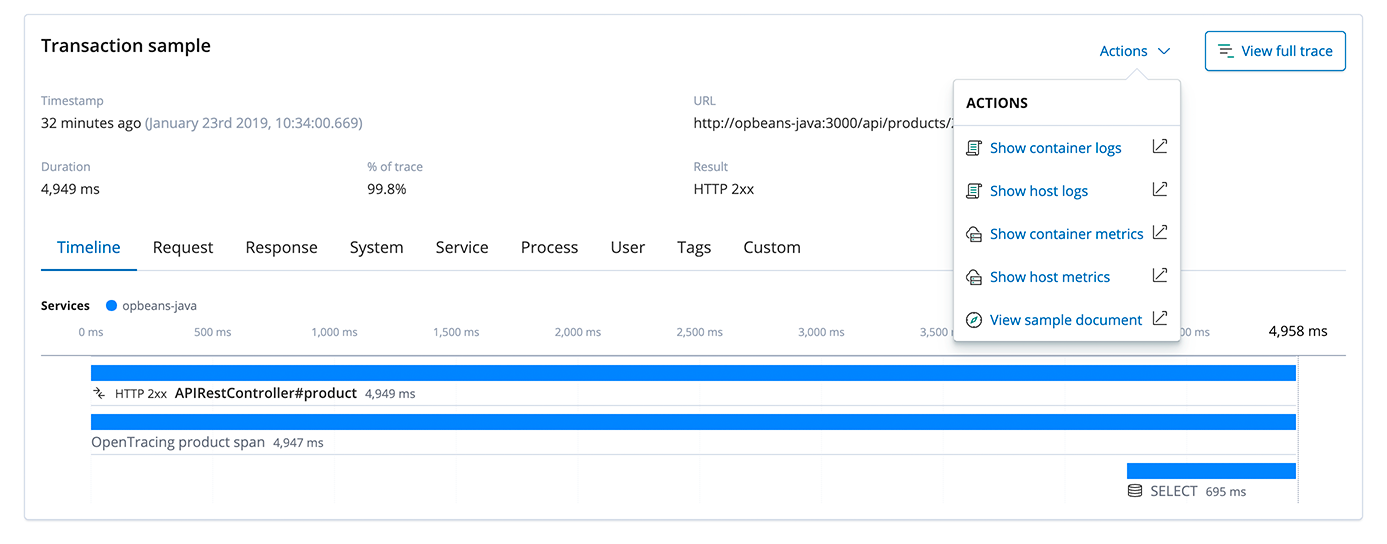
La Suite Elastic est également une plate-forme idéale pour l’agrégation de logs et l’analyse d’indicateurs. Elasticsearch stocke et indexe tous les logs, indicateurs et traces APM. Pour vous, c’est un atout indéniable. Vous pouvez mettre rapidement en corrélation les sources de données, telles que les indicateurs d’infrastructure, les logs et les traces, ce qui vous permet de déboguer la cause d’un problème bien plus rapidement. Dans l’interface utilisateur APM, lorsque vous étudiez une trace, vous pouvez rapidement passer aux indicateurs de l’hôte ou du conteneur, ainsi qu’aux logs, en cliquant sur le menu Actions (si ces indicateurs et ces logs sont aussi recueillis).
L’idéal, ce serait que tous les utilisateurs se servent d’Elastic APM pour instrumenter leurs applications et leurs services. Néanmoins, Elastic APM n’est pas la seule solution de traçage distribué commercialisée sur le marché. Il existe d’autres solutions de traçage open source très prisées, comme Zipkin et Jaeger. Certains concepts, comme la programmation multilangage et la persistance polyglotte, sont bien connus et largement acceptés dans l’univers des microservices. De manière similaire, le « traçage polyglotte » va se démocratiser. En raison du côté indépendant et « découplé » des microservices, les personnes en charge des différents services utiliseront probablement des systèmes de traçage distincts.
Problématiques pour les développeurs
Vu la diversité des systèmes de traçage disponibles, les développeurs sont confrontés à de véritables problématiques. Au final, les systèmes de traçage résident dans le code d’application. Voici quelques-unes des problématiques courantes rencontrées :
- Quel système de traçage utiliser ?
- Que faire si je souhaite changer de système de traçage ? Je ne veux pas modifier l’intégralité de mon code source.
- Comment procéder avec des bibliothèques partagées qui utilisent des systèmes de traçage différents ?
- Que se passe-t-il si mes services tiers utilisent différents systèmes de traçage ?
Sans surprise, pour répondre à ces problématiques, il est nécessaire de normaliser le traçage. Avant d’aborder la normalisation, étudions tout d’abord le traçage distribué d’un point de vue architectural. Notre but : comprendre les éléments nécessaires pour atteindre le « paradis » du traçage distribué.
Composants architecturaux du traçage distribué
Les systèmes logiciels modernes peuvent être dissociés en composants de haut niveau, généralement conçus et développés par différentes entreprises et exécutés dans des environnements distincts.
- Votre propre code d’application et vos propres services
- Bibliothèques et services partagés
- Services externes
Pour monitorer un tel système de façon holistique et intégrée avec le traçage distribué, quatre composants architecturaux sont nécessaires :
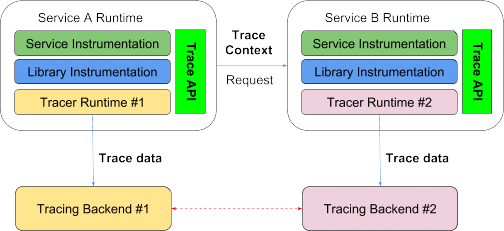
- API normalisée de traçage distribué. Avec une API de traçage ouverte et normalisée, les développeurs peuvent instrumenter leur code de manière normalisée. Peu importe le système de traçage qu’ils utiliseront par la suite lors de l’exécution. C’est un premier pas ouvrant de nombreuses possibilités.
- Définition normalisée du contexte de traçage et propagation. Pour qu’une trace soit transmise d’un environnement d’exécution à l’autre, il est nécessaire que son contexte soit compris des deux côtés. Le contexte doit donc être propagé de façon normalisée. Il doit être associé à un ID de trace au minimum.
- Définition normalisée des données de traçage. Pour que les données d’un système de traçage soient comprises et utilisées par un autre système de traçage, elles doivent être mises sous un format normalisé et extensible.
- Systèmes de traçage interopérables. Enfin, pour bénéficier d’une compatibilité d’exécution totale, les systèmes de traçage doivent disposer de mécanismes d’exportation et d’importation de données de trace venant d’autres systèmes de façon ouverte. Dans l’idéal, une bibliothèque ou un service partagé instrumenté par un système comme Jaeger devrait pouvoir transmettre ses données de traçage directement à Elastic APM ou à tout autre système de traçage par l’intermédiaire de l’agent Jaeger grâce à une modification de configuration.
Maintenant, ouvrez OpenTracing.
La spécification OpenTracing
La spécification OpenTracing définit une API ouverte pour le traçage distribué. Les utilisateurs n’ont donc pas à se cantonner à un fournisseur spécifique car ils ont la possibilité de changer de système de mise en œuvre OpenTracing quand ils le souhaitent. Cela permet également aux développeurs de frameworks et de bibliothèques partagées de fournir une fonctionnalité de traçage prête à l’emploi et normalisée, pour que les informations en découlant soient plus pertinentes. Les entreprises à l’échelle du Web, comme Uber et Yelp, utilisent OpenTracing pour bénéficier d’une meilleure visibilité sur les applications hautement distribuées et dynamiques.
Le modèle de données OpenTracing
Les concepts de base d’OpenTracing et le modèle de données fondamental sont tirés de l’article sur le système Dapper de Google. Parmi les concepts clés, on trouve la trace et l’intervalle.
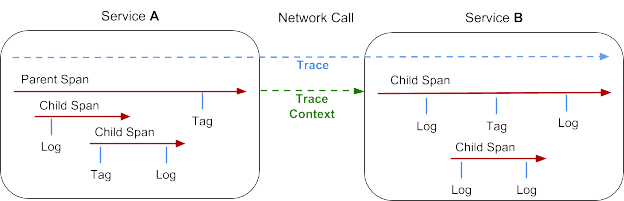
- Une trace représente une transaction au fur et à mesure qu’elle se déplace dans un système distribué. On peut la considérer comme un graphe acyclique dirigé d’intervalles.
- Un intervalle représente une unité logique de travail, qui possède un nom, une heure de début et une durée. Les intervalles peuvent être imbriqués et mis en ordre pour modeler des relations. Les intervalles acceptent les balises key:value, ainsi que les logs structurés, précis et horodatés associés à une instance d’intervalle donnée.
- Le contexte d’une trace représente les informations qui accompagnent la transaction distribuée lorsqu’elle passe de service en service sur le réseau ou via un bus de messagerie. Le contexte indique l’identificateur de la trace, l’identificateur de l’intervalle et toute autre donnée que le système de traçage doit propager vers le service en aval.
Comment tout cela s’articule ?
Dans l’idéal, avec la normalisation, les informations de traçage issues du code d’application personnalisé, des bibliothèques partagées et des services partagés mis au point et exécutés par différentes organisations sont échangeables et compatibles au niveau de l’exécution, et ce, quel que soit le système de traçage utilisé par ces composants.
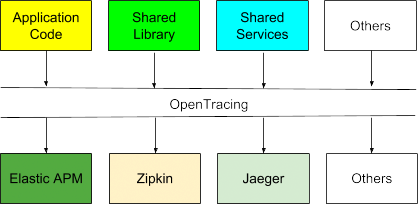
Néanmoins, OpenTracing prend en charge uniquement le premier des quatre composants architecturaux que nous avons abordés ci-dessus. Aussi, où en sommes-nous aujourd’hui avec les autres composants et qu’est-ce que le futur peut nous apporter ?
Où en sommes-nous aujourd’hui ?
Comme nous l’avons vu, OpenTracing définit un ensemble standard d’API de traçage pouvant être mises en œuvre par différents systèmes. C’est un début véritablement prometteur ! Toutefois, nous devons encore normaliser le contexte et les données de traçage pour qu’elles puissent être compatibles et interchangeables.
- OpenTracing fournit un ensemble standard d’API. C’est pratiquement la seule normalisation dont nous disposons aujourd’hui. Il faut toutefois noter qu’il existe une limitation à la spécification. Par exemple, elle ne prend pas en charge certains langages de programmation. Quoi qu’il en soit, c’est déjà un premier pas. Le premier pas d’une longue série.
- Aucune définition normalisée de contexte de traçage pour l’instant. Le groupe de travail sur le traçage distribué W3C s’est attaqué à la normalisation de la définition du contexte de traçage : la spécification du contexte d’une trace W3C. La spécification définit une approche unifiée par rapport à la corrélation existant entre un contexte et un événement au sein des systèmes distribués. Elle permettra de tracer une transaction de bout en bout au sein des applications distribuées à l’aide de différents outils de monitoring. Elastic APM aide ce groupe de travail à normaliser le format d’en-tête HTTP pour le traçage distribué. Nos mises en œuvre d’agents respectent rigoureusement la version préliminaire de la spécification du contexte de trace, et nous prévoyons de prendre entièrement en charge la spécification finale.
Ci-dessous, vous trouverez un exemple de l’incompatibilité qui existe au niveau du traçage du contexte actuellement, avec l’en-tête HTTP utilisé par Elastic APM et celui utilisé par Jaeger pour tracer l’ID. Comme vous pouvez le constater, le nom et l’encodage de l’ID sont différents. Lorsque différents en-têtes de traçage sont utilisés, les traces se rompent lorsqu’elles passent les frontières de leurs outils de traçage respectifs.
Jaeger :
uber-trace-id: 118c6c15301b9b3b3:56e66177e6e55a91:18c6c15301b9b3b3:1
Elastic APM :
elastic-apm-traceparent : 00-f109f092a7d869fb4615784bacefcfd7-5bf936f4fcde3af0-01
La définition en tant que telle n’est pas la seule problématique. Par exemple, certains en-têtes HTTP ne sont pas automatiquement transférés par l’infrastructure de service, les routeurs etc. Lorsque les en-têtes sont abandonnés, les traces se rompent. - Aucune définition normalisée des données de traçage pour l’instant. Comme indiqué par le groupe de travail sur le traçage distribué W3C, le deuxième élément nécessaire à l’interopérabilité d’une trace est « un format normalisé et extensible pour partager les données de trace, en intégralité ou en partie, sur les différents outils pour une meilleure interprétation ». Seul problème : il existe de nombreuses solutions open source et de solutions vendues dans le commerce. La définition d’un format standard est donc une tâche épineuse. Nous espérons y parvenir prochainement.
- Les systèmes de traçage ne sont pas compatibles au niveau de l’exécution. Pour toutes les raisons citées ci-dessus et à cause de l’incompatibilité des systèmes, les systèmes de traçage ne sont donc pas compatibles les uns avec les autres lors de l’exécution. Nous pouvons avancer avec certitude que ce problème persistera malheureusement à l’avenir.
Fonctionnement d’Elastic APM avec d’autres systèmes de traçage aujourd’hui
Même si nous sommes encore loin d’une compatibilité totale entre les systèmes de traçage aujourd’hui, restons optimistes. La Suite Elastic peut fonctionner avec d’autres systèmes de traçage de différentes façons.
- Elasticsearch en tant que magasin de données back-end évolutif pour d’autres systèmes de traçage.
Sans surprise, Elasticsearch a servi de magasin de données back-end pour d’autres systèmes de traçage comme Zipkin et Jaeger. Ses atouts : des capacités d’évolutivité et d’analyse puissantes. Pour transférer des données de traçage de Zipkin ou de Jaeger dans Elasticsearch, il suffit simplement de paramétrer la configuration de ces systèmes en ce sens. Dès que les données de traçage ont été transférées dans Elasticsearch, utilisez la capacité d’analyse et de visualisation puissante de Kibana pour analyser vos informations de traçage et créer des visualisations attrayantes qui illustrent bien les performances de vos applications. - Pont Elastic OpenTracing
Le pont Elastic APM OpenTracing vous permet de créer des transactions et des intervalles Elastic APM, à l’aide de l’API OpenTracing. En d’autres termes, il convertit les appels de l’API OpenTracing vers Elastic APM, puis permet de réutiliser l’instrumentation existante. Par exemple, une instrumentation existante réalisée par Jaeger peut être tout simplement remplacée par Elastic APM en changeant quelques lignes de code.
Instrumentation d’origine par Jaeger :
import io.opentracing.Scope; import io.opentracing.Tracer; import io.jaegertracing.Configuration; import io.jaegertracing.internal.JaegerTracer; ... private void sayHello(String helloTo) { Configuration config = ... Tracer tracer = config.getTracer(); try (Scope scope = tracer.buildSpan("say-hello").startActive(true)) { scope.span().setTag("hello-to", helloTo); } ... }Remplacez Jaeger avec le pont Elastic OpenTracing :
import io.opentracing.Scope; import io.opentracing.Tracer; import co.elastic.apm.opentracing.ElasticApmTracer; ... private void sayHello(String helloTo) { Tracer tracer = new ElasticApmTracer(); try (Scope scope = tracer.buildSpan("say-hello").startActive(true)) { scope.span().setTag("hello-to", helloTo); } ... }
Avec ce simple changement, les données de traçage circuleront joyeusement dans Elastic APM, sans que vous ayez à intervenir davantage sur le code de traçage. C’est là toute la puissance d’OpenTracing !
Elastic APM Real User Monitoring
Même si nous parlons essentiellement des services back-end lorsque nous abordons le sujet du traçage et de la propagation du contexte, il faut tout de même indiquer qu’il est très intéressant de démarrer la trace côté client dans le navigateur. En procédant ainsi, vous obtenez des données de trace dès le moment où un utilisateur clique sur quelque chose dans le navigateur. Ces données de trace représentent « l’expérience des utilisateurs réels » de vos applications du point de vue des performances. Malheureusement, là encore, il n’existe pas de procédure normalisée pour transférer ces données actuellement. Le groupe W3C a l’intention d’étendre le contexte de trace depuis le navigateur. C’est l’un de ses objectifs pour l’avenir.
Elastic APM Real User Monitoring (RUM) assure cette fonctionnalité aujourd’hui. L’agent RUM JS monitore l’expérience des utilisateurs réels au sein de votre application côté client. Vous pourrez mesurer des indicateurs tels que « Délai jusqu’au premier octet », domInteractive, et domComplete, qui aident à détecter les problèmes de performance dans votre application côté client ainsi que les problèmes de latence de votre application côté serveur. Notre agent RUM JS est compatible avec tous les frameworks. Il peut donc être utilisé avec n’importe quelle application front-end basée sur JavaScript.
<p?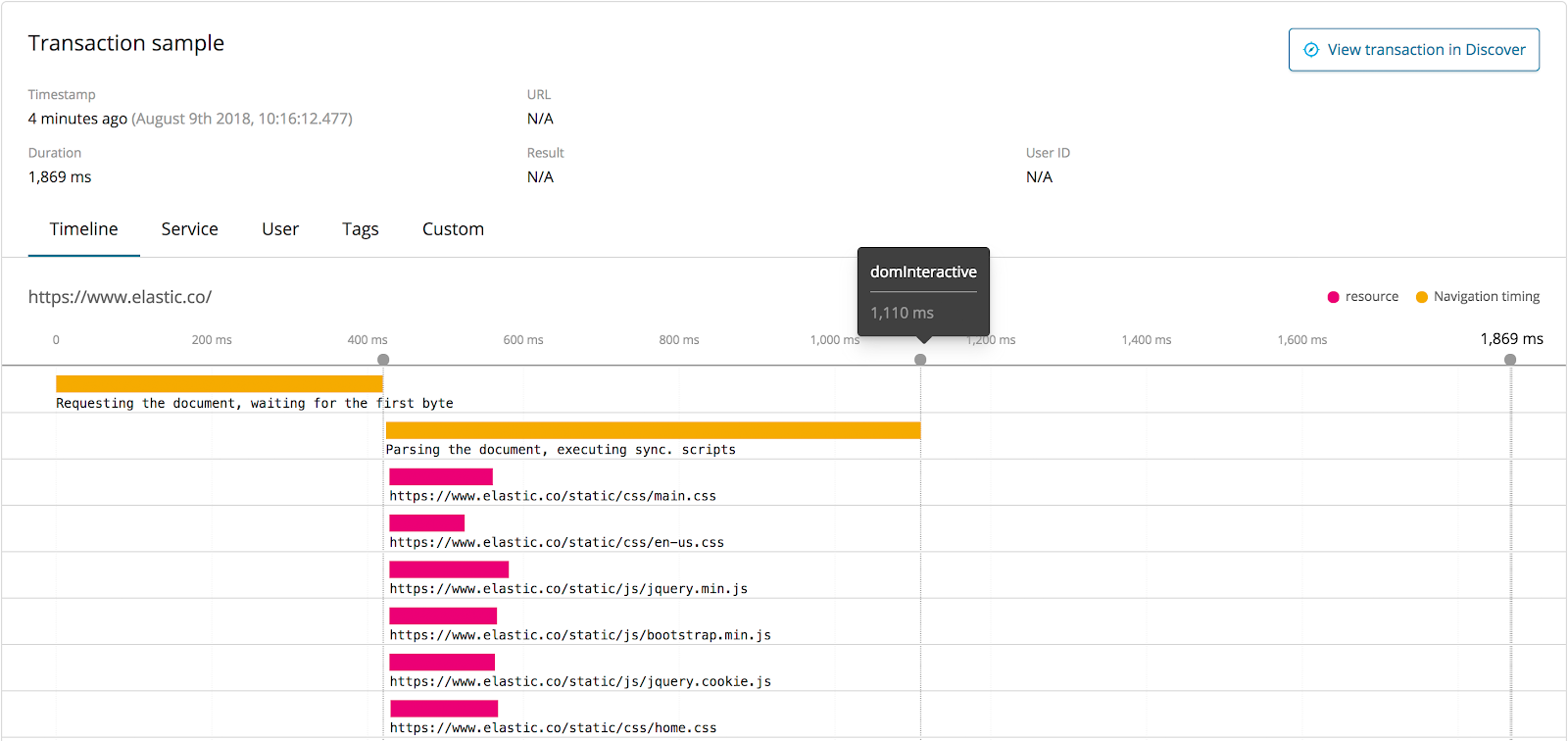
Résumé
Nous espérons que cet article de blog vous a aidé à mieux comprendre l’environnement du traçage distribué et qu’il a clarifié certains points concernant le statut d’OpenTracing aujourd’hui. Voici quelques points à retenir :
- Le traçage distribué fournit des informations précieuses concernant les performances des microservices.
- OpenTracing représente une première étape vers la normalisation du traçage distribué dans le secteur. Il reste encore un long chemin à parcourir pour atteindre une compatibilité totale.
- Elastic APM est compatible avec OpenTracing.
- Le pont Elastic OpenTracing permet de réutiliser une instrumentation existante.
- La Suite Elastic représente une solution de stockage à long terme évolutive idéale pour d’autres systèmes de traçage comme ZipKin et Jaeger, même si la compatibilité d’exécution n’est pas encore totale aujourd’hui.
- Il est possible d’analyser les données de traçage avec Elastic, même si ces données ne proviennent pas d’Elastic. Pour transférer des données de traçage de Zipkin ou de Jaeger dans Elasticsearch, il suffit simplement de paramétrer la configuration.
- Elastic APM Real User Monitoring (RUM) monitore l’expérience des utilisateurs réels au sein de votre application côté client.
- Pour résumer, Elastic est une plate-forme d’analyse unifiée et évolutive, équipée de nombreuses fonctionnalités, pour les trois piliers de l’observabilité : le logging, les indicateurs et le traçage.
Comme toujours, rendez-vous sur leforum Elastic APM si vous souhaitez ouvrir un fil de discussion ou si vous avez des questions. Nous vous souhaitons un bon traçage !