Plages numériques et temporelles dans Elasticsearch
Vous aimez cet article ? Vous aimez les chiffres et Elasticsearch ? Je serai à Elastic{ON} pour rencontrer les participants en personne et répondre à toutes vos questions. Pensez à participer à cet événement. En espérant vous y rencontrer !
Imaginez pouvoir indexer votre calendrier pour identifier rapidement tous les événements dont les créneaux entrent en conflit avec un nouvel événement que l'on vous propose. Ou encore, pouvoir créer un programme télé mondial pour trouver toutes les émissions, films ou événements sportifs diffusés à certains créneaux. Vous recherchez quelque chose de plus futuriste encore ? Imaginez pouvoir créer un catalogue des signatures spectrales pour toutes les cellules cancéreuses connues afin d'identifier, de classer et de diagnostiquer plus rapidement des activités potentiellement malignes.
Des données discrètes aux données continues
Jusqu'à présent, ces cas d'utilisation étaient très difficiles, voire impossibles, à résoudre à grande échelle à l'aide des champs de données discrètes, numériques ou temporelles. Bien que les requêtes sur des plages de points de données discrètes soient la fonctionnalité la plus courante et la plus utilisée, il est rapidement devenu évident que nous devions ajouter une fonctionnalité permettant d'indexer et de faire des recherches parmi des plages continues. Grâce à de nouvelles avancées sur Apache Lucene, ce rêve est désormais réalité dans Elasticsearch.
Elasticsearch présente de nouveaux types de données : Numeric Range et Date Range
Nous avons le plaisir de vous annoncer que les types de plages suivants sont inclus dans la version 5.2 d'Elasticsearch :
integer_rangefloat_rangelong_rangedouble_rangedate_range
La définition du mapping pour ces nouveaux types de plages est similaire à celle de leurs homologues de données discrètes. Vous trouverez ci-dessous la définition du mapping d'un document (nommé « conférence ») contenant à la fois une plage de nombres entiers et de une plage de dates :
PUT events/
{
"mappings" : {
"conference" : {
"properties" : {
"expected_attendees" : {
"type" : "integer_range"
},
"time" : {
"type" : "date_range",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
Pour indexer un document à l'aide du mapping ci-dessus, il suffit de définir les champs de plage de la même façon que vous le feriez dans une requête Numeric ou Date. Comme les requêtes sur des plages de dates, l'indexation d'une plage de dates utilise la même définition au format Date Math. L'exemple suivant illustre l'indexation d'un document contenant les champs integer_range et date_range :
PUT events/conference/1
{
"title" : "Pink Floyd / Wizard of Oz Halloween Trip",
"expected_attendees" : {
"gte" : 100000,
"lt" : 200001
},
"time" : {
"gte" : "2015-10-31 12:00",
"lt" : "2015-11-01"
}
}
Pour interroger des champs de plages numériques et de dates, on utilise la même définition de Range Query selon le langage dédié (Domain Specific Language ou DSL) qu'avant, à l'exception d'un nouveau paramètre de relation facultatif. Ce paramètre permet à l'utilisateur de définir le type de requête désiré sur la plage. Il peut prendre les valeurs suivantes : INTERSECTS (par défaut), CONTAINS ou WITHIN et peut être combiné à d'autres requêtes booléennes pour obtenir des résultats différents (par ex. DISJOINT). L'exemple suivant illustre une requête WITHIN effectuée sur l'index des événements :
GET events/_search
{
"query" : {
"range" : {
"time" : {
"gte" : "2015-10-01",
"lte" : "2015-12-31",
"relation" : "within"
}
}
}
}
Comme les champs discrets numériques et de dates, leurs homologues sous forme de plages sont limités à une seule dimension. Nous prévoyons à l'avenir de lever cette restriction et d'autoriser 8 et 4 dimensions respectivement pour ces champs.
Implémentation dans Lucene
Le 18 octobre dernier, nous avons publié un article de blog décrivant l'évolution des filtres de plages numériques dans Apache Lucene. Il présente l'évolution de Lucene jusqu'à devenir un moteur de recherche numérique et détaillait les avancées technologiques de l'indexation et de la recherche numérique, avec pour point culminant la structure de données Bkd-Tree. Plutôt que de continuer à représenter les données numériques à l'aide d'une structure conçue spécialement pour du texte, l'implémentation de Bkd présentait pour la première fois une structure d'arbre flexible conçue spécifiquement pour l'indexation de points numériques discrets. Vous pouvez désormais faire des recherches dans ces données discrètes dans Elasticsearch à l'aide de la définition DSL numeric range query. Conçu d'après la théorie et les concepts d'un arbre k-d (k-d tree), le nouveau format de codec Points a aussi ouvert la voie pour la prise en charge de plusieurs dimensions qui pourrait convenir à des cas d'utilisation scientifiques plus avancés. Il fournit également la fondation permettant d'intégrer cette fonctionnalité de plages à Lucene et au bout du compte, à Elasticsearch.
Indexation
La solution était plutôt simple : pour chaque dimension, il suffisait de représenter la plage numérique dimensionnelle comme point à 2 dimensions dans lequel l'encodage était stocké comme suite de valeurs minimum : d (pour chaque dimension), suivie d'une suite de valeurs maximum : D. Cela signifie que pour la restriction de Bkd de 8 dimensions, les champs de plages numériques fournis par Lucene ne prennent en charge l'indexation que de 4 plages dimensionnelles maximum. L'image ci-dessous illustre simplement l'encodage des plages dimensionnelles dans Lucene.
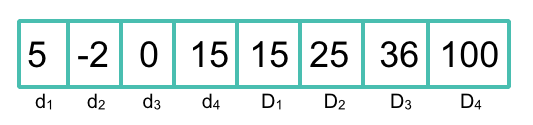
Plus simplement, dans Lucene, une plage à 1 dimension ressemble à un point à 2 dimensions. Cet encodage est ensuite transmis à l'outil d'indexation de Bkd qui construit alors l'arbre hiérarchique de d*2 points, où d est la dimension dans la plage (4 dans l'exemple ci-dessus).
Recherche
Pour effectuer des recherches sur des plages dimensionnelles, il fallait pouvoir définir et calculer la relation dans l'espace entre la plage de recherche fournie par l'utilisateur (la cible) et les plages indexées (ou plages minimum à chaque niveau de l'arbre). Pour cela, nous avons implémenté un comparateur de plage dimensionnelle qui évalue la relation de chaque plage pour chaque dimension. Les relations spatiales du comparateur, et donc implémentées dans les requêtes de plage numériques de Lucene sont les suivantes : INTERSECTS, CONTAINS et WITHIN. Les requêtes DISJOINT sont obtenues en utilisant une requête INTERSECTS contenue dans une requête booléenne avec une clause MUST_NOT. Pour les champs à plusieurs valeurs, un document n'est considéré comme DISJOINT que si toutes les valeurs sont disjointes. Les relations CROSSES sont actuellement en cours de développement et prévues pour une prochaine version. L'image suivante illustre les relations calculées entre deux plages à une dimension.
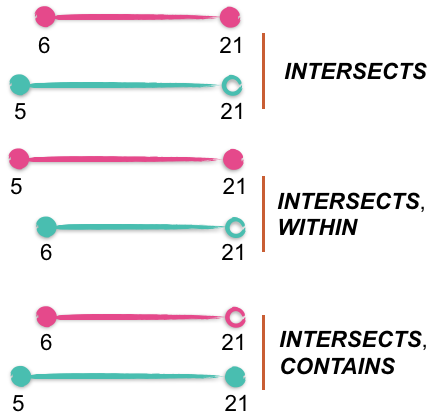
Cet exemple suit la convention selon laquelle un point creux représente une plage qui n'inclut pas cette valeur spécifique. Les plages en rose représentent ici la cible (requête) et les plages turquoise représentent une plage indexée.
A vous de jouer !
Nous avons hâte de savoir de quelles façons vous allez utiliser l'indexation et la recherche sur ces plages numériques et de dates. Comme toujours, nous vous encourageons à nous donner votre avis, vos suggestions et à contribuer sur notre page GitHub et nous espérons que ces nouveaux types de champs vous seront utiles !
Sur ce, nous avons terminé, amusez-vous bien avec Elasticsearch !